【C++】哈希(2万字)
2301_79585944 2024-06-27 17:35:03 阅读 60
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
unordered系列关联式容器
unordered_map
unordered_map的文档介绍
unordered_map的接口说明
unordered_set
底层结构
哈希概念
哈希冲突
哈希函数
哈希冲突解决
闭散列
线性探测的实现并改造
二次探测
开散列
开散列概念
开散列实现并改造 + 迭代器的实现
开散列增容
开散列与闭散列比较
不同的类型转换成整型的操作
MyOrderedMap.h
MyOrderedSet.h
哈希的应用
位图
位图概念
位图的实现
位图应用
布隆过滤器
布隆过滤器提出
布隆过滤器概念
布隆过滤器的插入
布隆过滤器的查找
布隆过滤器删除
布隆过滤器优点
布隆过滤器缺陷
布隆过滤器的面试题
哈希切割
总结
前言
世上有两种耀眼的光芒,一种是正在升起的太阳,一种是正在努力学习编程的你!一个爱学编程的人。各位看官,我衷心的希望这篇博客能对你们有所帮助,同时也希望各位看官能对我的文章给与点评,希望我们能够携手共同促进进步,在编程的道路上越走越远!
提示:以下是本篇文章正文内容,下面案例可供参考
unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到$log_2 N$,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好 的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个 unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同,本文中只对unordered_map和unordered_set进行介绍, unordered_multimap和unordered_multiset学生可查看文档介绍。
unordered_map
unordered_map的文档介绍
unordered_map文档介绍
unordered_map是存储键值对的关联式容器,其允许通过keys快速的索引到与其对应的value。在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。在内部,unordered_map没有对按照任何特定的顺序排序,为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭 代方面效率较低。unordered_maps实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问 value。它的迭代器至少是前向迭代器。
unordered_map的接口说明
1. unordered_map的构造
| 函数声明 | 功能介绍 |
| unordered_map | 构造不同格式的unordered_map对象 |
2. unordered_map的容量
| 函数声明 | 功能介绍 |
| bool empty() const | 检测unordered_map是否为空 |
| size_t size() const | 获取unordered_map的有效元素个数 |
3. unordered_map的迭代器
| 函数声明 | 功能介绍 |
| begin | 返回unordered_map第一个元素的迭代器 |
| end | 返回unordered_map最后一个元素下一个位置的迭代器 |
| cbegin | 返回unordered_map第一个元素的const迭代器 |
| cend | 返回unordered_map最后一个元素下一个位置的const迭代器 |
4. unordered_map的元素访问
| 函数声明 | 功能介绍 |
| operator[] | 返回与key对应的value,没有一个默认值 |
注意:该函数中实际调用哈希桶的插入操作,用参数key与V()构造一个默认值往底层哈希桶中插入,如果key不在哈希桶中,插入成功,返回V(),插入失败,说明key已经在哈希桶中, 将key对应的value返回。
5. unordered_map的查询
| 函数声明 | 功能介绍 |
| iterator find(const K& key) | 返回key在哈希桶中的位置 |
| size_t count(const K& key) | 返回哈希桶中关键码为key的键值对的个数 |
注意:unordered_map中key是不能重复的,因此count函数的返回值最大为1
6. unordered_map的修改操作
| 函数声明 | 功能介绍 |
| insert | 向容器中插入键值对 |
| erase | 删除容器中的键值对 |
| void clear() | 清空容器中有效元素个数 |
| void swap(unordered_map&) | 交换两个容器中的元素 |
7. unordered_map的桶操作
| 函数声明 | 功能介绍 |
| size_t bucket count()const | 返回哈希桶中桶的总个数 |
| size_t bucket size(size_t n) const | 返回n号桶中有效元素的总个数 |
| size_t bucket(const K& key) | 返回元素key所在的桶号 |
unordered_set
unordered_set文档介绍
底层结构
unordered系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构。
哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素 时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即 O($log_2 N$),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立 一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
插入元素:根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放搜索元素:对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称 为哈希表(Hash Table)(或者称散列表)
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity;capacity为存储元素底层空间总的大小。
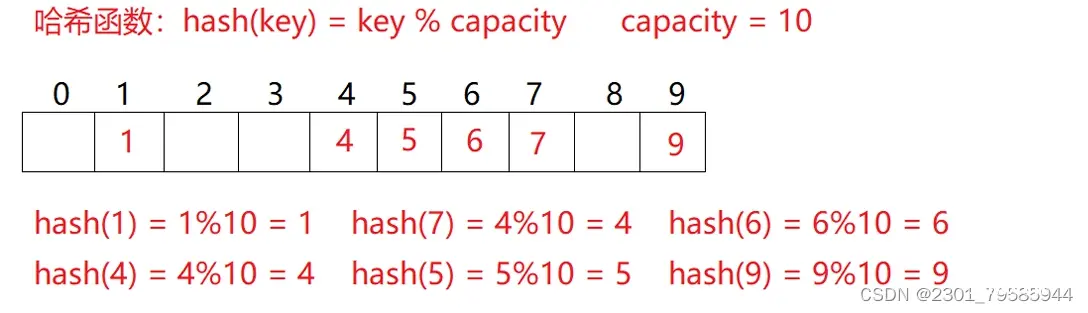
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快。
哈希冲突
对于两个数据元素的关键字$k_i$和 $k_j$(i != j),有$k_i$ != $k_j$,但有:Hash($k_i$) == Hash($k_j$),即:不同关键字通过相同哈希函数计算出相同的哈希地址,该种现象称为哈希冲突 或哈希碰撞。
比如:5、25、45分别去%20,映射的位置都是5。
哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:
哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间哈希函数计算出来的地址能均匀分布在整个空间中哈希函数应该比较简单
常见哈希函数:
1. 直接定址法--(常用)一一映射
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B优点:简单、均匀缺点:需要事先知道关键字的分布情况使用场景:适合查找比较小且连续的情况
2. 除留余数法--(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数, 按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
3. 平方取中法--(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况
4. 折叠法--(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这 几部分叠加求和,并按散列表表长,取后几位作为散列地址。折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况
5. 随机数法--(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中 random为随机数函数。通常应用于关键字长度不等时采用此法
6. 数学分析法--(了解)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定 相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只 有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散 列地址。例如:

注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突
哈希冲突解决
解决哈希冲突两种常见的方法是:闭散列和开散列
闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有 空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
1. 线性探测
比如下图中的场景,现在需要插入元素44,先通过哈希函数计算哈希地址,hashAddr为4, 因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
插入
通过哈希函数获取待插入元素在哈希表中的位置 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突, 使用线性探测找到下一个空位置,插入新元素

查找
i = key % 表的大小 如果i为不是要查找的key值,就线性往后查找,直到找到或者遇到空,如果找到表的结尾位置,还没有找到key值,要往头回绕。
删除
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素 会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影 响。因此线性探测采用标记的伪删除法来删除一个元素。
// 哈希表每个空间给个标记
// EMPTY此位置空, EXIST此位置已经有元素, DELETE元素已经删除
enum State{EMPTY, EXIST, DELETE};
线性探测的实现并改造
// 开放定址法
namespace open_address
{
// 状态
enum State
{
EMPTY,
EXIST,
DELETE
};
template<class K, class V>
struct HashData // 类模板名:哈希表的数据是结构体的变量(数据和状态)
{
pair<K, V> _kv;
State _state = EMPTY;
// 标记默认初始化为空,一旦存进去值,标记为存在,删除值之后,标记位删除
};
template<class K>
struct HashFunc // 仿函数:将key转换成整型
{
size_t operator()(const K& key)
{
return (size_t)key;// 不传参数三,默认将key强转成整型
}
};
// 特化 ---> 在实践当中string经常做key,所以做特化
template<>
struct HashFunc<string>
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto e : s)
{
hash += e;
hash *= 131;
}
return hash;
}
};
// stoi:只有阿拉伯的字符串数字"1224546"才能用stoi;像"比特"就不能用stoi
// 将字符串强制转换成整型
//struct HashFuncString
//{
//size_t operator()(const string& s)
//{
//// "abcd"
//// "bcad"
//// "aadd"
//size_t hash = 0;
//for (auto e : s)
//{
// // 将字符串中的每个字符ascll码值加起来
//hash += e;
//hash *= 131;// 这样可以避免ascll码值相加相等的情况
//}
//
//return hash;
//}
//};
// 参数三:默认缺省的仿函数Hash,没有传确定的仿函数,就用缺省的发仿函数HashFunc<K>
template<class K, class V, class Hash = HashFunc<K>>
class HashTable // 类模板名:哈希表
{
public:
HashTable(size_t size = 10)
{
_tables.resize(size);// 使用resize的话,size和capcacity就相等了
}
HashData<K, V>* Find(const K& key)
{
Hash hs; // 仿函数的对象
// 线性探测
size_t hashi = hs(key) % _tables.size();
while (_tables[hashi]._state != EMPTY)
{
if (key == _tables[hashi]._kv.first
&& _tables[hashi]._state == EXIST)
{
return &_tables[hashi];
}
++hashi;// 如果++超出size,则取模从头再来
hashi %= _tables.size();
}
return nullptr;
}
bool Insert(const pair<K, V>& kv)
{
// 如果已经有了,就返回false
if (Find(kv.first))
return false;
// 扩容的问题 不强制类型转换成double的话,会有7/10==0的情况
//if ((double)_n / (double)_tables.size() >= 0.7)
if (_n * 10 / _tables.size() >= 7)
{
// 方法一:
//size_t newSize = _tables.size() * 2;
// 不能在原表的空间上扩容空间,因为这样会使映射关系混乱
//vector<HashData> newTables(newSize); // 需要重新开辟一块新空间
遍历旧表,重新映射到新表,那么就得此处再次写一遍线性探测的代码,再让两个表交换一下
....
//_tables.swap(newTables);
// 方法二:
HashTable<K, V, Hash> newHT(_tables.size() * 2);
// 遍历旧表,插入到新表
for (auto& e : _tables)
{
if (e._state == EXIST)
{
newHT.Insert(e._kv);
// 这里新表调用Insert()函数,并不会陷入死循环,因为空间*2倍之后,不会再次进入if判断条件了
// 直接复用线性探测的代码
}
}
_tables.swap(newHT._tables);// 交换两表,那么旧表出了作用域就会调用析构函数,旧表数据会被释放
}
Hash hs;
// 线性探测
size_t hashi = hs(kv.first) % _tables.size(); // 除和取模都不能除或取模0
// 这里要模取的是size,而不是capacity;假设表中的capacity和size是不一样的,
// 放值是需要[]的,[]会检查i < size,如果值放在模capacity的那块区间,超出size会越界;
// 所以只能放值在size区间处,放在size和capacity区间,则越界。
while (_tables[hashi]._state == EXIST) // 此位置状态为存在
{
++hashi;
hashi %= _tables.size();// 模上一个size,走到尾之后,从头再来
}
// 此位置状态为空或被删除
_tables[hashi]._kv = kv;
_tables[hashi]._state = EXIST;
++_n; // 实际数据个数+1
return true;
}
bool Erase(const K& key)
{
HashData<K, V>* ret = Find(key);
if (ret)
{
_n--;
ret->_state = DELETE; // 直接改状态就相当于删除了
return true;
}
else
{
return false;
}
}
private:
vector<HashData<K, V>> _tables;
size_t _n = 0; // 实际存储的数据个数
};
思考:哈希表什么情况下进行扩容?如何扩容?
哈希冲突越多,效率就越低。负载因子/载荷因子 = 实际存进去数据个数/表的大小。闭散列(开放定址法):负载因子一般会控制在0.7左右。
线性探测优点:实现非常简单。
线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。
二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法 为:$H_i$ = ($H_0$ + $i^2$ )% m, 或者:$H_i$ = ($H_0$ - $i^2$ )% m。其中:i = 1,2,3…, $H_0$是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表 的大小。
对于下图中如果要插入44,产生冲突,使用解决后的情况为:

研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任 何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在 搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
因此:闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
开散列
开散列概念
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。

从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
开散列实现并改造 + 迭代器的实现
template<class K>
struct HashFunc // 仿函数:将key转换成整型
{
size_t operator()(const K& key)
{
return (size_t)key;// 不传参数三,默认将key强转成整型
}
};
// 特化 ---> 在实践当中string经常做key,所以做特化
template<>
struct HashFunc<string>
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto e : s)
{
hash += e;
hash *= 131;
}
return hash;
}
};
// 哈希桶
namespace hash_bucket
{
// T -> K
// T -> pair<K, V>
template<class T>
struct HashNode
{
HashNode<T>* _next;
T _data;
HashNode(const T& data)
:_next(nullptr)
, _data(data)
{}
};
// 编译器有一个原则:先定义或先声明,再使用。
// 在使用一个变量、类型、函数,要先定义或先声明,再使用。因为编译器为了提高编译速度,有一个原则,
// 比如:在使用一个变量、类型或函数时,编译器只会向上找,不会向下找,只向上找,编译速度会快很多。
// 下面__HTIterator类模板中使用了HashTable<K, T, KeyOfT, Hash>,在上面没有HashTable的定义,
// 所以编译器会报错,因为编译器不认识HashTable。
// 类里面是不受影响的,因为类里面的规则,是在整个类域里面进行查找,编译器把类域当成一个整体。
// 那我们如果把整个HashTable类模板放在__HTIterator类模板之前,也会有问题,
// 因为HashTable类模板中也使用了__HTIterator类型,这个地方就是一个经典的互相引用。
// 那么这时候就只能增加一个前置声明
// 前置声明(声明中不能有缺省值)
template<class K, class T, class KeyOfT, class Hash>
class HashTable;
template<class K, class T, class KeyOfT, class Hash>
struct __HTIterator
{
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyOfT, Hash> HT;
typedef __HTIterator<K, T, KeyOfT, Hash> Self;
Node* _node;
HT* _ht;
__HTIterator(Node* node, HT* ht)
:_node(node)
, _ht(ht)
{}
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
// 返回的是哈希表中对应的元素
Self& operator++()
{
// 当前哈希表所在位置的桶没有走完
if (_node->_next)
{
// 当前桶还是节点
_node = _node->_next;
}
else
{
// 当前桶走完了,找下一个桶
KeyOfT kot;
Hash hs;
// _tables是HashTable的私有,所以_tables无法使用。我们可以采用友元的方法
size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();
// 找下一个桶
hashi++;
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];
break;
}
hashi++;
}
// 后面没有桶了
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
};
// 参数三:仿函数,对于set来说,返回key;对于map来说,返回pair<key,value>中的key
// 参数四:转换成整型的仿函数
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
// 迭代器想要使用哈希表,就得把迭代器变成哈希表的友元
template<class K, class T, class KeyOfT, class Hash>
friend struct __HTIterator;// 普通类的友元,只有这一行代码;类模板的友元,得把模板参数声明一下
typedef HashNode<T> Node;
public:
typedef __HTIterator<K, T, KeyOfT, Hash> iterator;
iterator begin()
{
for (size_t i = 0; i < _tables.size(); i++)
{
// 找到第一个桶的第一个节点
if (_tables[i])
{
// this就是哈希表对象的地址
return iterator(_tables[i], this);
}
}
// 找不到返回空
return end();
}
iterator end()
{
return iterator(nullptr, this);// 调用的是__HTIterator的构造函数
}
HashTable()
{
_tables.resize(10, nullptr);
_n = 0;
}
// 这里析构的是表中所挂的哈希桶中的节点;vector出了作用域之后会自己调用析构函数
// 哪怕我们自己显示写了析构函数,自定义类型出了作用域也会显示调用析构
~HashTable()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
pair<iterator, bool> Insert(const T& data)
{
KeyOfT kot;
// 此时Find()函数返回的是迭代器,不能转换成bool值,所以要拿迭代器进行比较
// 之前Find()函数返回的是节点的指针,可以隐式类型转换成bool值
/*if (Find(kot(data)) != end())
return false;*/
iterator it = Find(kot(data));
if (it != end())
return make_pair(it, false);
Hash hs;
// 负载因子到1就扩容
if (_n == _tables.size())
{
// 创建一个新表
vector<Node*> newTables(_tables.size() * 2, nullptr);// 调用HashTable的构造函数
for (size_t i = 0; i < _tables.size(); i++)
{
// 取出旧表中节点,重新计算挂到新表桶中
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;// 保存下一个节点
// 头插到新表
size_t hashi = hs(kot(cur->_data)) % newTables.size();
cur->_next = newTables[hashi];
newTables[hashi] = cur;
cur = next;// 查看下一个节点应该挂到那个桶中
}
_tables[i] = nullptr;// 将旧表置空
}
_tables.swap(newTables);// 交换两表之后,旧表出了作用域就被释放掉
}
size_t hashi = hs(kot(data)) % _tables.size();
Node* newnode = new Node(data);
// 头插
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return make_pair(iterator(newnode, this), true);
}
iterator Find(const K& key)
{
KeyOfT kot;
Hash hs;
size_t hashi = hs(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur, this);
}
cur = cur->_next;
}
return iterator(nullptr, this);
}
bool Erase(const K& key)
{
KeyOfT kot;
Hash hs;
size_t hashi = hs(key) % _tables.size();
Node* prev = nullptr;
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
// 删除
if (prev) // 不是桶中的第一个节点
{
prev->_next = cur->_next;
}
else // 是桶中的第一个节点
{
_tables[hashi] = cur->_next;
}
delete cur;
--_n;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
private:
vector<Node*> _tables; // 指针数组
size_t _n;
};
}
开散列增容
桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希表进行增容,那该条件怎么确认呢?开散列最好的情况是:每个哈希桶中刚好挂一个节点, 再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可 以给哈希表增容。
开散列与闭散列比较
应用链地址法处理溢出,需要增设链接指针,似乎增加了存储开销。事实上: 由于开地址法必须保持大量的空闲空间以确保搜索效率,如二次探查法要求装载因子a <= 0.7,而表项所占空间又比指针大的多,所以使用链地址法反而比开地址法节省存储空间。
不同的类型转换成整型的操作
struct Date
{
int _year;
int _month;
int _day;
};
// 将日期类转换成整型
struct HashFuncDate
{
// 2024/6/3
// 2024/3/6
size_t operator()(const Date& d)
{
size_t hash = 0;
hash += d._year;
hash *= 131;
hash += d._month;
hash *= 131;
hash += d._day;
hash *= 131;
return hash;
}
};
struct Person
{
string _name;
string _id; // 身份证号码
string _tel;
int _age;
string _class;
string _address; //
//...
};
struct HashFuncPerson
{
// 2024/6/3
// 2024/3/6
size_t operator()(const Person& p)
{
size_t hash = 0;
for (auto e : p._id)
{
hash += e;
hash *= 131;
}
return hash;
}
};
MyOrderedMap.h
#include"HashTable.h"
namespace bit
{
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
// Map要把[]实现出来,就得解决insert(),[]的本质就是insert()
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key, V()));
return ret.first->second;
}
iterator find(const K& key)
{
return _ht.Find(key);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
private:
hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;
};
void test_map1()
{
unordered_map<string, string> dict;
dict.insert(make_pair("sort", ""));
dict.insert(make_pair("left", ""));
dict.insert(make_pair("right", "?"));
for (auto& kv : dict)
{
//kv.first += 'x';
kv.second += 'y';
cout << kv.first << ":" << kv.second << endl;
}
}
}
MyOrderedSet.h
#include"HashTable.h"
namespace bit
{
template<class K, class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT, Hash>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
bool insert(const K& key)
{
return _ht.Insert(key);
}
pair<iterator, bool> find(const K& key)
{
return _ht.Find(key);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
private:
hash_bucket::HashTable<K, const K, SetKeyOfT, Hash> _ht;
};
void test_set1()
{
unordered_set<int> us;
us.insert(3);
us.insert(1);
us.insert(5);
us.insert(15);
us.insert(45);
us.insert(7);
unordered_set<int>::iterator it = us.begin();
while (it != us.end())
{
//*it += 100;
cout << *it << " ";
++it;
}
cout << endl;
int x = 0;
cin >> x;
if (us.find(x) != us.end())
{
cout << "找到了" << endl;
}
else
{
cout << "没有找到" << endl;
}
for (auto e : us)
{
cout << e << " ";
}
cout << endl;
}
}
int a[10];// 静态数组
// 动态数组:malloc或new出来的数组是动态数组
哈希的应用
位图
位图概念
面试题
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。【腾讯】
遍历,时间复杂度O(N)排序(O(NlogN)),利用二分查找: logN位图解决 数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0 代表不存在。比如:
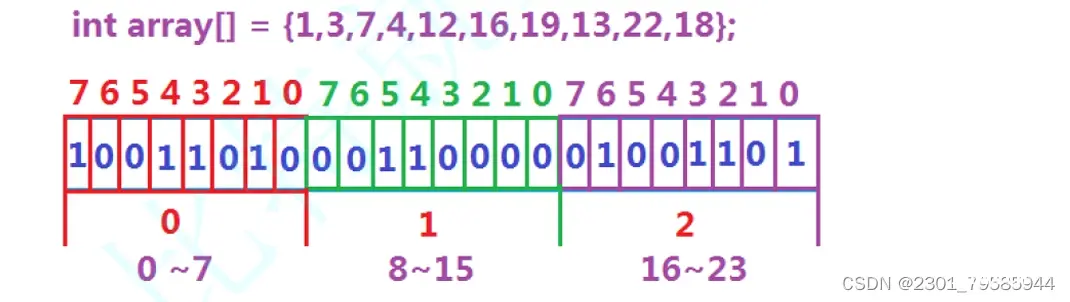
位图概念
所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用 来判断某个数据存不存在的。
位图的实现
namespace bit
{
// 用一个非类型模板参数来控制位图要开多大(位图是存在于数组里面的)
template<size_t N>
class bitset
{
public:
bitset()
{
// 假如:N是50个比特位,50除以32是1个整型,还有18个比特位没有开出来,所以要向上取整
// 多开一个整型
_bits.resize(N / 32 + 1, 0);
//cout << N << endl;
}
// 把x映射的位标记成1
void set(size_t x)
{
assert(x <= N);// x不能超出N
size_t i = x / 32;// 计算x在第几个整型上
size_t j = x % 32;// 计算x在这个整型的第几个位上
_bits[i] |= (1 << j);
}
// 把x映射的位标记成0
void reset(size_t x)
{
assert(x <= N);
size_t i = x / 32;
size_t j = x % 32;
_bits[i] &= ~(1 << j);
}
// 检测x映射的标记位是1还是0
bool test(size_t x)
{
assert(x <= N);
size_t i = x / 32;
size_t j = x % 32;
return _bits[i] & (1 << j);
}
private:
vector<int> _bits;
};
void test_bitset()
{
bitset<100> bs1;
bs1.set(50);
bs1.set(30);
bs1.set(90);
for (size_t i = 0; i < 100; i++)
{
if (bs1.test(i))
{
cout << i << "->" << "在" << endl;
}
else
{
cout << i << "->" << "不在" << endl;
}
}
bs1.reset(90);
bs1.set(91);
cout << endl << endl;
for (size_t i = 0; i < 100; i++)
{
if (bs1.test(i))
{
cout << i << "->" << "在" << endl;
}
else
{
cout << i << "->" << "不在" << endl;
}
}
// 这三种方式都可以开42亿9千万个位图大小的空间
bitset<-1> bs2;
bitset<UINT_MAX> bs3;
bitset<0xffffffff> bs4;
}



位图应用
快速查找某个数据是否在一个集合中排序 + 去重求两个集合的交集、并集等操作系统中磁盘块标记
给定100亿个整数,设计算法找到只出现一次的整数?
思路:出现1次和1次以上的整数需要两个比特位:00 ---> 0次;01 ---> 1次;10 ---> 2次及以上。
代码展示:
template<size_t N>
class two_bit_set
{
public:
void set(size_t x)
{
// 00 -> 01
if (_bs1.test(x) == false
&& _bs2.test(x) == false)
{
_bs2.set(x);
}
// 01 -> 10
else if (_bs1.test(x) == false
&& _bs2.test(x) == true)
{
_bs1.set(x);
_bs2.reset(x);
}
}
//int test(size_t x)
//{
//if (_bs1.test(x) == false
//&& _bs2.test(x) == false)
//{
//return 0;
//}
//else if (_bs1.test(x) == false
//&& _bs2.test(x) == true)
//{
//return 1;
//}
//else
//{
//return 2; // 2次及以上
//}
//}
bool test(size_t x)
{
if (_bs1.test(x) == false
&& _bs2.test(x) == true)
{
return true;
}
return false;
}
private:
bitset<N> _bs1;// 自定义类型的对象会去调用它的构造函数
bitset<N> _bs2;
};
void test_bitset2()
{
int a[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6 };
two_bit_set<100> bs;
for (auto e : a)
{
bs.set(e);
}
for (size_t i = 0; i < 100; i++)
{
//cout << i << "->" << bs.test(i) << endl;
if (bs.test(i))
{
cout << i << endl;
}
}
}
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
思路:分别set到两个位图,同时为1的就是交集。
1G内存是够的,100亿个整数,并不需要100亿个比特位,因为整数最多42亿9千万个,所以说映射的位图只需要42亿9千万个位,42亿9千万个比特位换算成1G,两个0.5G就是1G。
1GB是2的30次方,是10亿字节,100亿字节是10G,那么100亿个整型是40G。
代码展示:
void test_bitset3()
{
int a1[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6 };
int a2[] = { 5,3,5,99,6,99,33,66 };
bitset<100> bs1;
bitset<100> bs2;
for (auto e : a1)
{
bs1.set(e);
}
for (auto e : a2)
{
bs2.set(e);
}
for (size_t i = 0; i < 100; i++)
{
// 寻找交集
if (bs1.test(i) && bs2.test(i))
{
cout << i << endl;
}
}
}
位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
内存当中一般是存不下这些值,这些值都是存在文件里面的。位图不是开40亿,而是按照范围来开的(42亿9千万),因为它的范围是无符号的整数,(0~2^32-1)。
采用两个比特位:00 ---> 0次;01 ---> 1次;10 ---> 2次;11 ---> 3次及以上
给定100亿个整数,只有512M,需要在512M内存中设计算法找到只出现一次的整数?

因为1G是10亿字节,1G是2^30,1G是42亿9千万个比特位,整数的范围最大才到42亿9千万,所以100亿个整数中有大量是重复的数字,所以要在512M内存中查找只出现一次的整数,可以让42亿9千万个整数分成两份,因为512M是是42亿9千万个比特位的一半。
先查找前一半,再查找后一半,映射的过程中就是去重的过程。
布隆过滤器
布隆过滤器提出
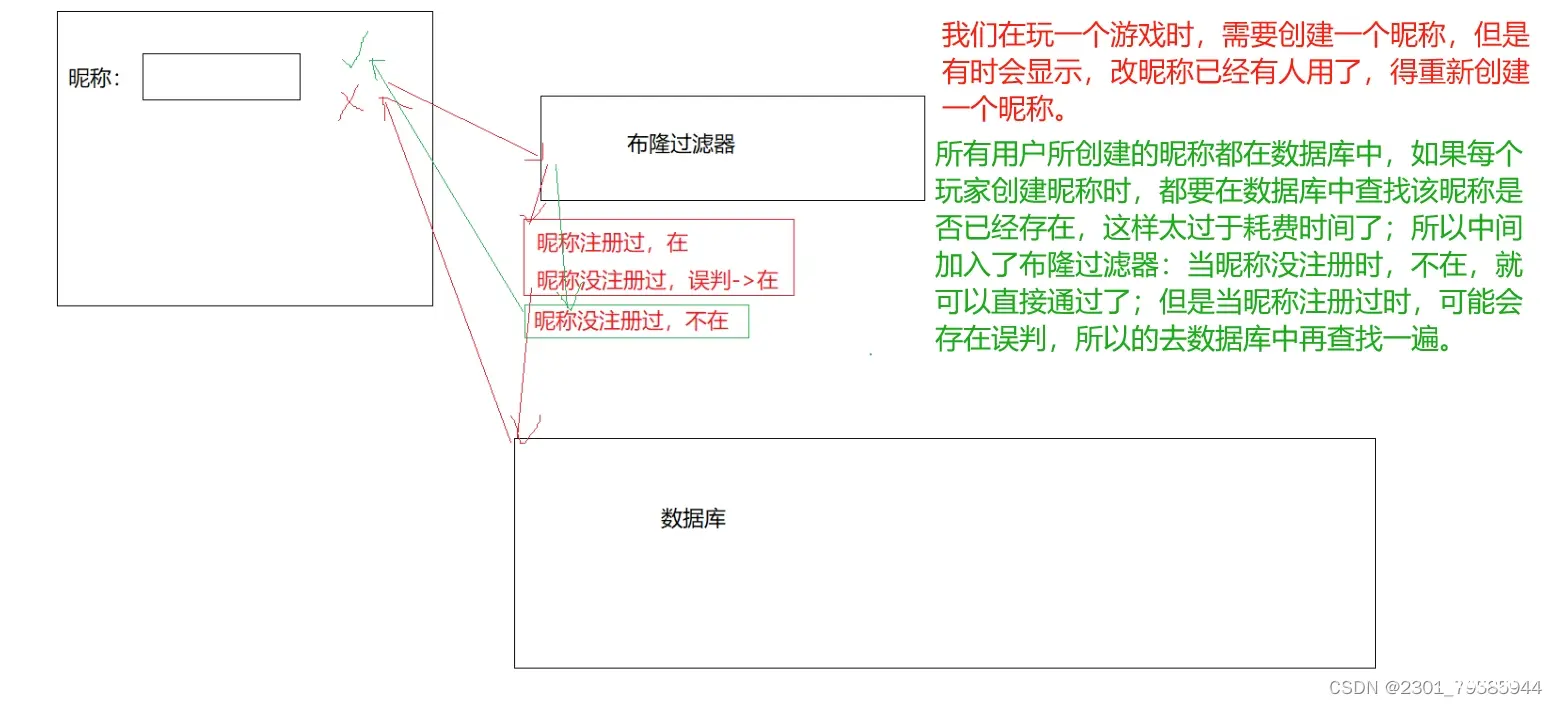
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉 那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用 户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那 些已经存在的记录。 如何快速查找呢?
用哈希表存储用户记录,缺点:浪费空间用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理 了。将哈希与位图结合,即布隆过滤器
布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
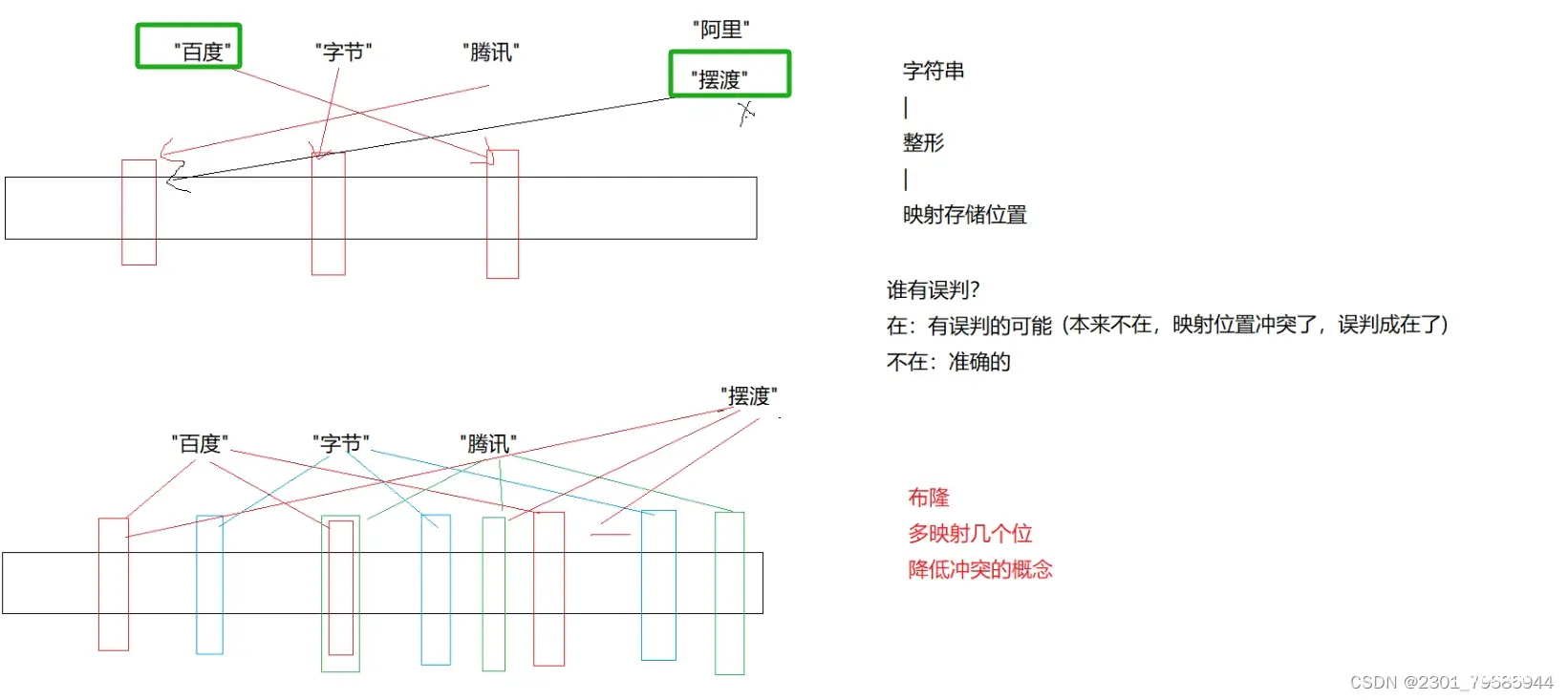
布隆过滤器的插入
#pragma once
#include<bitset>
#include<string>
struct HashFuncBKDR
{
// BKDR
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash *= 131;
hash += ch;
}
return hash;
}
};
struct HashFuncAP
{
// AP
size_t operator()(const string& s)
{
size_t hash = 0;
for (size_t i = 0; i < s.size(); i++)
{
if ((i & 1) == 0) // 偶数位字符
{
hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));
}
else // 奇数位字符
{
hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5)));
}
}
return hash;
}
};
struct HashFuncDJB
{
// DJB
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash = hash * 33 ^ ch;
}
return hash;
}
};
// 参数三:三个哈希仿函数的个数,表示一个值能映射3个位
template<size_t N,
class K = string,
class Hash1 = HashFuncBKDR,
class Hash2 = HashFuncAP,
class Hash3 = HashFuncDJB>
class BloomFilter
{
public:
void Set(const K& key)
{
// 比如:插入第一个数,映射0~M-1的比特位区间
// 一个值要映射到三个比特位上,为了减少冲突
size_t hash1 = Hash1()(key) % M;
size_t hash2 = Hash2()(key) % M;
size_t hash3 = Hash3()(key) % M;
_bs->set(hash1);
_bs->set(hash2);
_bs->set(hash3);
}
// 这里不需要写reset()删除函数,因为删除百度,腾讯判断也可能不在了。因为百度和腾讯可能会映射到同一个位置
bool Test(const K& key)
{
// 值映射的三个比特位上,只要有一个比特位为0,就是该值不在哈希表中
size_t hash1 = Hash1()(key) % M;
if (_bs->test(hash1) == false)
return false;
size_t hash2 = Hash2()(key) % M;
if (_bs->test(hash2) == false)
return false;
size_t hash3 = Hash3()(key) % M;
if (_bs->test(hash3) == false)
return false;
return true; // 存在误判(有可能3个位都是跟别人冲突的,所以误判)
}
private:
// const size_t M = 10 * N;
// 我们不能用这种成员变量,因为这个成员变量是属于对象的,只是声明,没有空间,只在初始化列表才会初始化
// 加一个静态static就可以了,那么这个变量就在静态区,就不属于对象了,而是属于整个类
// N:比特位。插入一个整数,也就是一个整数映射一个比特位,比特位扩容10倍的N
static const size_t M = 10 * N; // 想降低误判率:可以增大比特位的空间
bit::bitset<M> _bs;
// 如果就是想要使用库里面的bitset,可以new在堆区开辟一个std::bitset<M>类型的空间,将空间的地址给_bs
//std::bitset<M>* _bs = new std::bitset<M>;
};
// 库里面的stl::bitset<M>类型所开辟的空间是开在对象里面的,这个对象是一个静态数组
// 我们自己用vector<>实现的bitset是调用resize()函数开辟空间是在堆上的
void TestBloomFilter1()
{
string strs[] = { "百度","字节","腾讯" };// 中文是由多个字符构成的
BloomFilter<10> bf;
for (auto& s : strs)
{
bf.Set(s);
}
for (auto& s : strs)
{
cout << bf.Test(s) << endl;
}
for (auto& s : strs)
{
cout << bf.Test(s + 'a') << endl;
}
cout << bf.Test("摆渡") << endl;
cout << bf.Test("百渡") << endl;
}
布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特 位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为 零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可 能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其 他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
布隆过滤器删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
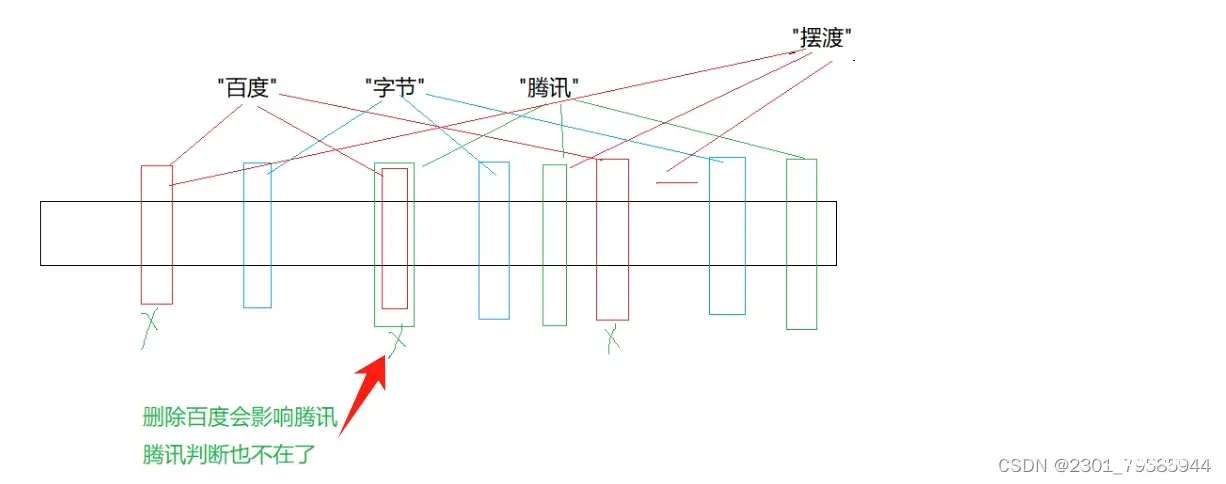
每个位置改成多个位的引用计数就可以支持。比如:一个映射位置给8个bit标记,但是这样空间的消耗就大了。
布隆过滤器优点
增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无 关哈希函数相互之间没有关系,方便硬件并行运算布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势数据量很大时,布隆过滤器可以表示全集,其他数据结构不能使用同一组散列函数的布隆过滤器可以进行交、并、差运算
布隆过滤器缺陷
有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再 建立一个白名单,存储可能会误判的数据)不能获取元素本身一般情况下不能从布隆过滤器中删除元素如果采用计数方式删除,可能会存在计数回绕问题
布隆过滤器的面试题
给两个文件,分别有100亿个query(字符串),我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法?
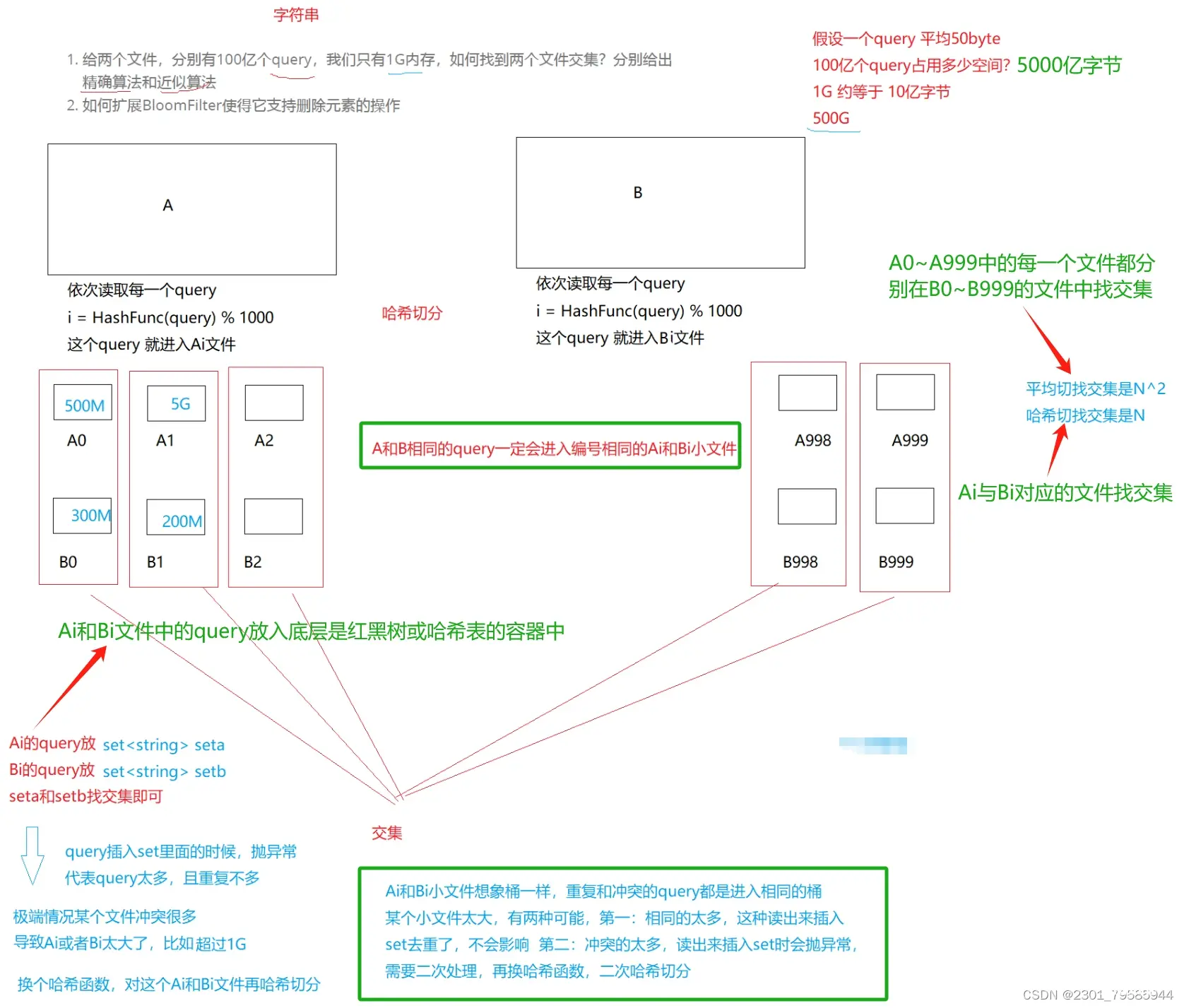
小文件在找交集是没有误判的,因为已经读到内存当中了,不需要在使用布隆过滤器,直接将文件中的数据放到底层为哈希表或红黑树的容器中。
之前的算法要用布隆过滤器,因为数据在数据库中,都去数据库中查找太慢了,所以用布隆过滤,会效率高。
哈希切割
给一个超过100G大小的log file, log中存着IP地址,设计算法找到出现次数最多的IP地址? 与上题条件相同,如何找到top K的IP?如何直接用Linux系统命令实现?

如果是top K ,就自己建立一个小堆,默认是大堆,我们还得写一个仿函数,因为不能用pair<string,int>类型比,我们要用pair<string,int>类型中的second来进行比较,控制成一个K个数的小堆。
海量数据问题特征:数据量大,内存存不下。
先考虑具有特点的数据结构能否解决?比如:位图、堆、布隆过滤器等。大事化小思路。哈希切分(不能平均切分),切小以后,放到内存中能处理。
总结
好了,本篇博客到这里就结束了,如果有更好的观点,请及时留言,我会认真观看并学习。
不积硅步,无以至千里;不积小流,无以成江海。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。