【算法】哈希映射(C/C++)
摆烂小白敲代码 2024-10-04 11:05:02 阅读 92
目录
算法引入:
算法介绍:
优点:
缺点:
哈希映射实现:
unordered_map
题目链接:“蓝桥杯”练习系统
解析:
代码实现:
哈希映射算法是一种通过哈希函数将键映射到数组索引以快速访问数据的数据结构。它的核心思想是利用哈希函数的快速计算能力,将键(Key)转换为数组索引,从而实现对数据的快速访问和存储。哈希映射在现代软件开发中非常重要,它提供了高效的数据查找、插入和删除操作。

算法引入:
小白算法学校今年经过了层层考核,预选拔了六名队员,这六名队员的信息如下,好巧不巧的是这六名队员有重名的,叫张三的有两个人,叫李四的有两个人。那么教练如何区分它们呢,只叫队员的名字很可能叫错人,这是不被认可的叫法,根据下标去叫张三,可是真正的张三都不知道自己的下标是哪一个。欣慰的时,每一名队员都有一个学号,学号是唯一的值,每一名队员的学号都不一样,那么教练可以直接说出学号的值,那么就可以锁定唯一的那一位队员了,此时去用下标对应学号,那么唯一的下标值对应唯一且不重复的学号,那么这就是叫做哈希映射,下标被称为“键”,学号被称为“值”。
| 下标 | 姓名 | 学号 |
| 0 | 张三 | 100 |
| 1 | 李四 | 101 |
| 2 | 王五 | 102 |
| 3 | 赵六 | 103 |
| 4 | 张三 | 107 |
| 5 | 李四 | 108 |
算法介绍:
哈希映射在绝大部分题目中使用的频率还是比较高的,它主要的思想就是键值映射,通过一个整数也就是下标值,在一个数组里面有且仅有一个唯一的值与之对应,有点类似于经过去重的数组一样,但是这种映射是有规律可循的。

哈希映射的工作原理依赖于哈希函数,哈希函数接受一个键作为输入,并返回一个值,这个整数通常用作数组的索引。理想情况下,哈希函数应该将输入均匀分布到所有可能的索引值上,以减少不同键映射到同一个索引值的情况,即“哈希碰撞”。
当发生哈希碰撞时,有几种常见的解决策略:
1. 链地址法:每个数组元素不直接存储键值对,而是存储一个链表。当多个键通过哈希函数映射到同一索引时,这些键值对将被存储在同一个链表中。
2. 开放寻址法:当发生哈希碰撞时,哈希映射会尝试找到数组中的下一个空闲位置,按照某种系统的方式(如线性探测)进行。
优点:
哈希映射的优点就是数据操作增删改查,增加、删除、查找操作的时间复杂度接近O(1)。它还支持动态扩容,以适应数据量的增加。
缺点:
哈希映射也有一些缺点,比如哈希碰撞虽然可以减少但无法完全避免,需要通过额外的数据结构或探测算法来解决。此外,为了减少哈希碰撞,哈希表可能会预留较大的空间,导致内存利用率不是很高。
哈希映射实现:
哈希映射实现方式一般都是通过map来实现,map就类似上述的功能,可以说是一个数组,但是里面的下标可以是数字、字符、字符串、pair、结构体等,这些下标去映射值,值也有可能数字、字符、字符串、pair、结构体等,map內部的实现自建一颗红黑树,map的查询、插入、删除操作的时间复杂度都是O(logn)。map默认按照key进行升序排序,和输入的顺序无关。 如果是int/double等数值型为key,那么就按照大小排列;如果是string类型,那么就按照字符串的字典序进行排列。
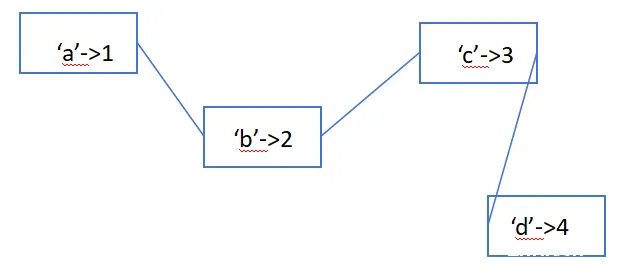
map
在使用map时,需要加入头文件#include<map>,下面解析一下map常用的函数:
1.insert
insert是插入函数,在指定的下标位置插入键值映射。
<code>mymap.insert(mymap.begin(),pair<char,int>('a',1));//指定位置插入
mymap.insert(pair<char,int>('a',1));//直接插入键值对
mymap.insert({ {'a',1},{'b',2}});//多键值对插入
//相当于mymap['a']=1;
2.find
find为查找函数,如果查找到则返回迭代器指向当前查找元素的位置,否则查找不到返回map.end()位置。
map<char,int>::iterator it=mymap.find('a');//查找关键字为'a'的迭代器位置
3.erase
erase是删除函数,能够对指定位置进行删除键值,也可以根据键进行删除,或者通过迭代器进行删除。
map<char,int>::iterator it=mymap.find('a');//查找关键字为'a'的迭代器位置
mymap.erase(it);//对map容器的第二个位置进行删除键值映射
mymap.erase('a');//删除('a',1)键值映射,删除成功能找到'a'的键,返回1,否则返回0
mymap.erase(mymap.begin(),mymap.end());//删除整个map容器,功能相当于clear
4.clear
clear函数则是清空函数,对整个map容器进行清空,里面不再有键值映射关系。
mymap.clear();
5.遍历
map的遍历有很多种,但是最常见的还是迭代器遍历,迭代器遍历非常方便,可以很好的操作map容器,其次使用range遍历,前提是C++11的编译器,其特点是简洁。
map<char,int>::iterator iter;
for(iter=mymap.begin();iter!=mymap.end();iter++){//迭代器遍历
cout<<iter->first<<" "<<iter->second;
}
for(auto it1:mymap){//range遍历
cout<<it1.first<<" "<<it1.second;
}
其他
下面是C++ map其他的一些函数。
begin() 返回指向map头部的迭代器
end() 返回指向map末尾的迭代器
count() 返回指定元素出现的次数,因为key值不会重复,所以非0即1
empty() 判空,map为空则返回true
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代器
size() 返回map中元素的个数
swap() 交换两个map里面的键值
upper_bound() 返回键值>给定元素的第一个位置
lower_bound() 返回键值>=给定元素的第一个位置
value_comp() 返回比较元素value的函数
key_comp() 返回比较元素key的函数
#include<iostream>
#include<map>
using namespace std;
map<char,int> mymap;
int main(){
mymap.insert(mymap.begin(),pair<char,int>('a',1));//指定位置插入
mymap.insert(pair<char,int>('a',1));//直接插入键值对
mymap.insert({ {'a',1},{'b',2}});//多键值对插入
//相当于mymap['a']=1;
map<char,int>::iterator it=mymap.find('a');//查找关键字为'a'的迭代器位置
mymap.erase(it);//对map容器的第二个位置进行删除键值映射
mymap.erase('a');//删除('a',1)键值映射,删除成功能找到'a'的键,返回1,否则返回0
mymap.erase(mymap.begin(),mymap.end());//删除整个map容器,功能相当于clear
map<char,int>::iterator iter;
for(iter=mymap.begin();iter!=mymap.end();iter++){//迭代器遍历
cout<<iter->first<<" "<<iter->second;
}
for(auto it1:mymap){//range遍历
cout<<it1.first<<" "<<it1.second;
}
if(!mymap.empty()){//empty函数
cout<<1<<endl;
}
map<char,int> youmap;
swap(mymap,youmap);//swap函数 map交换
if(!mymap.count('a')){//count函数
cout<<1<<endl;
}
auto it2=mymap.lower_bound(1);//lower_bound函数
map<char,int>::key_compare comp = mymap.key_comp();//key_comp()函数
bool result = comp('a', 'b');
cout <<result<<endl; // 输出 1 (true)
return 0;
}
unordered_map
unordered_map和map类似,都是存储的key-value的值,可以通过key快速索引到value。不同的是unordered_map不会根据key的大小进行排序,存储时是根据key的hash值判断元素是否相同,即unordered_map内部元素是无序的。unordered_map的底层是一个防冗余的哈希表(开链法避免地址冲突)。unordered_map用到自定义的类型,需要对key定义hash_value函数并且重载operator == 哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,时间复杂度为O(1),函数基本都一样。
题目链接:“蓝桥杯”练习系统
问题描述
给定2维平面上n个整点的坐标,一条直线最多能过几个点?
输入格式
第一行一个整数n表示点的个数
以下n行,每行2个整数分别表示每个点的x,y坐标。
输出格式
输出一个整数表示答案。
样例输入
5
0 0
1 1
2 2
0 3
2 3
样例输出
3
数据规模和约定
n<=1500,数据保证不会存在2个相同的点。
点坐标在int范围内
解析:
这是妥妥的map的映射啊,这个是斜率double类型去映射int类型的直线点的个数,用哈希表关键字与键值映射即可,斜率当关键字,每有一个点在此直线上不断加一即可。话不多说,直接上代码,代码附注释。
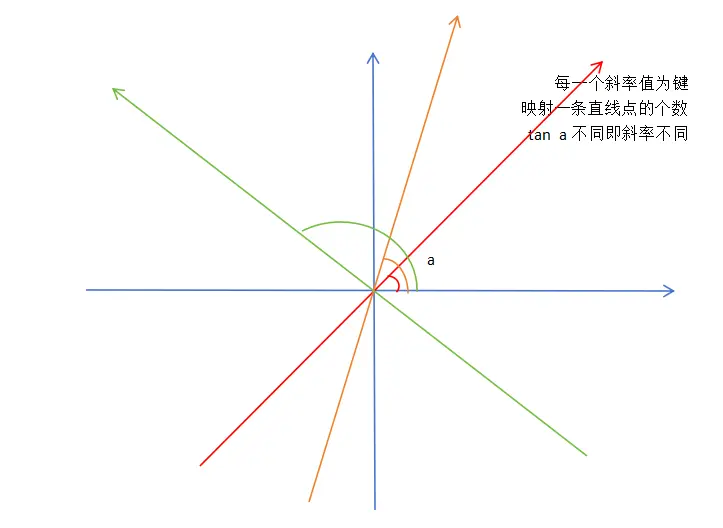
代码实现:
<code>#include<iostream>
#include<utility>
#include<map>
using namespace std;
pair<int,int> a[2000];//输入二维坐标,用pair或结构体
int n,maxx;
int main(){
cin>>n;
for(int i=0;i<n;i++){
cin>>a[i].first>>a[i].second;//输入位置
}
map<double,int> p;//用map映射
for(int i=0;i<n;i++){//始点
for(int j=i+1;j<n;j++){//终点
double k;//斜率
k=double(a[i].second-a[j].second)/(a[i].first-a[j].first);//强转为double,否则数据会四舍五入
if(p[k]==0){//如果此次斜率是第一次出现,说明两点构成一条直线,点数为2,需要多加一次
p[k]++;
}
p[k]++;//如果存在了那就再此基础上加一即可
maxx=max(p[k],maxx);//寻找最大值
}
p.erase(p.begin(),p.end());//暴力枚举,若不清空,会影响下一个始点的计算
//我们是先固定起点,再遍历终点,求斜率
//若有三个点构成一条直线,第一次固定第一个点为始点,终点遍历后面两个点,此时为点数3
//若不清空继续遍历,第二个点为始点,第三个点为终点,p[k]++还会继续,变为4,重复计算,所以清空
}
cout<<maxx<<endl;
return 0;
}
哈希映射算法应用的场景还是非常多的,博主在参加第十五届蓝桥杯国赛的时候,80%的题目都用到了map映射,博主感觉国赛考察map映射能力去处理、解决问题还是比较重要的。执笔至此,感触彼多,全文将至,落笔为终,感谢各位的支持。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。