Datawhale AI夏令营 第四期大模型应用开发 0811直播分享
安格1121 2024-08-16 10:01:03 阅读 98
大模型项目分类和原理解析
分类标准:是否需要微调模型、是否需要训练embedding模型、是否需要优化prompt等技术指标
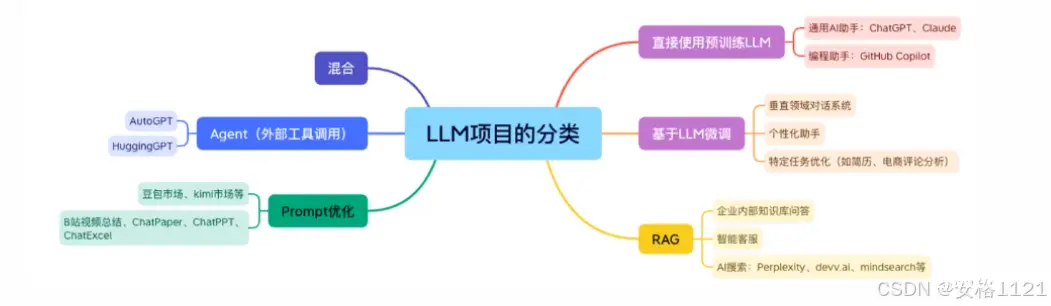
小白可以做的LLM相关事情
Prompt项目
方式1 修改Prompt项目达成需求
意译文章,生成要求风格的文案
方式2 Prompt项目结合开发
ChatPaper
利用chatgpt进行论文全文总结--专业翻译--润色--审稿--审稿回复
GitHub - kaixindelele/ChatPaper: Use ChatGPT to summarize the arXiv papers. 全流程加速科研,利用chatgpt进行论文全文总结+专业翻译+润色+审稿+审稿回复
ChatBI/ChatExcel
思路1:用户上传文件存入db,输入text生成sql语句
思路2:用户输入的text直接转化成操作表格的代码文件
相似开源项目
GitHub - eosphoros-ai/DB-GPT-Hub: A repository that contains models, datasets, and fine-tuning techniques for DB-GPT, with the purpose of enhancing model performance in Text-to-SQL
流程
将Excel作为一个数据源上传到DB-GPT当中。
DB-GPT通过Excel Python支持特性将Excel表格数据转换为数据库表格,可以利用DB-GPT中的通用能力。
用户发起对话,通过对话进行Excel数据分析。
根据DB-GPT中ChatExcel场景逻辑,调用大模型生成对应的Text2SQL语句。
利用执行插件能力,执行具体结果。
收集数据绘制图表。
返回最终结果。
ChatPPT
PPT是一种文件格式 GitHub - PandaVT/AI_PPT_demo: This repo is built for showing how to generate PPT use python
如果要处理的数据很多,超过token限制应该怎么办
方式1:长文本裁剪,分段总结汇总
方式2:Embedding ——将文本、图像等人类世界的高维信息转换为低维向量,同时保留不错的语义信息,便于进行数学运算和相似度比较。
练手demo
GitHub - JessyTsui/awesome_LLM_beginner: 送给LLM初学者的路径,看我心情和时间更新
(faiss:Facebook开源出的一个向量检索引擎)
Embedding问题——转换到哪个向量空间(相似文本用相似的向量空间表示)
对于专业领域,最好训练自己的embedding模型
通用模型解决不了的问题怎么办
ChatLaw
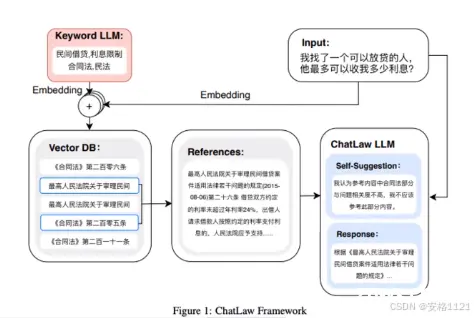
数据集
PandaVT/chinese_verdict_examples · Datasets at HF Mirror
PandaVT/chinese_law_examples · Datasets at HF Mirror
当在谈论“通用模型”和“垂直模型”的时候,在讨论什么东西
通用模型:10w个子任务
垂直模型:3w个子任务
需要的模型:10-500个子任务
怎么准备“好”数据
论文 AnyTaskTune: Advanced Domain-Specific Solutions through Task-Fine-Tuning
标题:AnyTaskTune:通过任务微调实现先进的特定领域解决方案 pdf AnyTaskTune: Advanced Domain-Specific Solutions through Task-Fine-Tuning
在一个领域内识别和定义目标子任务,然后创建专门的增强数据集进行微调,从而优化特定任务的模型性能。法律咨询反问子任务。
问题解答
SCI-GPT为什么G了:各行各业领域差距太大了
DAG项目,尽量基于faiss自己搭框架,那样细节可控
微调数据集方法:LLaMA Factory开源框架
总结
将练手demo那个学完,会收获很大
LLaMA Factory开源框架还没用过,安排上!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。