vLLM CPU和GPU模式署和推理 Qwen2 等大语言模型详细教程
cnblogs 2024-08-11 15:13:00 阅读 64

vLLM默认并不支持纯CPU模式部署和推理模式,老牛同学应网友要求,根据vLLM官网整理vLLM在CPU模式下如何部署和推理大语音模型,并以Qwen2为了进行验证和演示……
老牛同学在前面文章中,介绍了不同大模型的部署和推理方式。有网友给老牛同学留言,希望老牛同学能写一篇使用 vLLM 通过 CPU 和 GPU 推理 Qwen2 等大语言模型的文章,老牛同学决定本期安排起来。
由于vLLM默认并不支持 CPU 部署和推理,为了验证和演示CPU部署和推理过程,老牛同学肝了周六 1 个晚上和周日大半天,目前都成功了。因vLLM通过CPU部署推理的文档少之又少,官网有些地方也不是很明确,导致老牛同学在执行过程中走了不少弯路。因此,老牛同学希望通过本文,能帮助大家避免踩坑和走弯路。
通过本文,老牛同学将介绍vLLM的 3 部分内容:
- CPU模式下,如果编译打包vLLM框架(你没有看错:CPU模式需要我们自己编译打包)
- 通过CPU模式,演示多种方式部署和推理Qwen2大模型(其他模型也一样):本地模式、部署 API 服务、API 客户端、WebUI 等方式
- 最后,在GPU模式,简单介绍vLLM部署和推理;相比CPU环境,简单太多了,因为vLLM默认就只支持GPU环境
vLLM 官网源代码地址:https://github.com/vllm-project/vllm
vLLM 支持目前主流大模型,详细列表见官网:https://docs.vllm.ai/en/latest/models/supported_models.html
Qwen2 系列大模型在vLLM支持大模型之列,本文将详细介绍通过vLLM部署和推理Qwen2-0.5B大语言模型(之所以选择0.5B小尺寸模型,纯粹下载更快、演示更方便,其他vLLM所支持的所有大模型,其部署和推理过程完全一样,大家可以根据自己的需要选择不同的模型)
vLLM 环境准备
特别注意的是:vLLM目前只支持Linux操作系统(包括Windows WSL子系统),因此环境准备分为 2 部分:
- Linux 环境准备:我们的操作系统如果是Linux系统,那就无需其他操作;如果是Windows操作系统,需要首先安装和配置好WSL子系统,老牛同学就不介绍(本教程老牛同学也是用的Windows WSL Ubuntu 子系统)
- Python 研发环境准备:老牛默认使用Miniconda,需要安装和设置。老牛同学稍微进行介绍,大模型研发环境配置详细文档,参加老牛同学之前的文章:大模型应用研发基础环境配置(Miniconda、Python、Jupyter Lab、Ollama 等)
安装 Miniconda 包管理工具
Linux/Windows WSL系统,我们可以通过命令行完成安装:
<code>mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
Shell 上下文激活Miniconda相关命令:
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh
source /home/obullxl/.bashrc
source /home/obullxl/.zshrc
设置 Miniconda 国内镜像
配置镜像是为了提升依赖包下载速度,老牛同学强烈建议进行配置。
Miniconda配置文件路径:~/.condarc,一般情况下配置文件不存在,我们可以创建并初始化它:conda config --set show_channel_urls yes
然后打开配置文件,设置依赖包镜像渠道:
show_channel_urls: true
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- defaults
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
保存配置文件,我可以查看配置是否生效:conda info
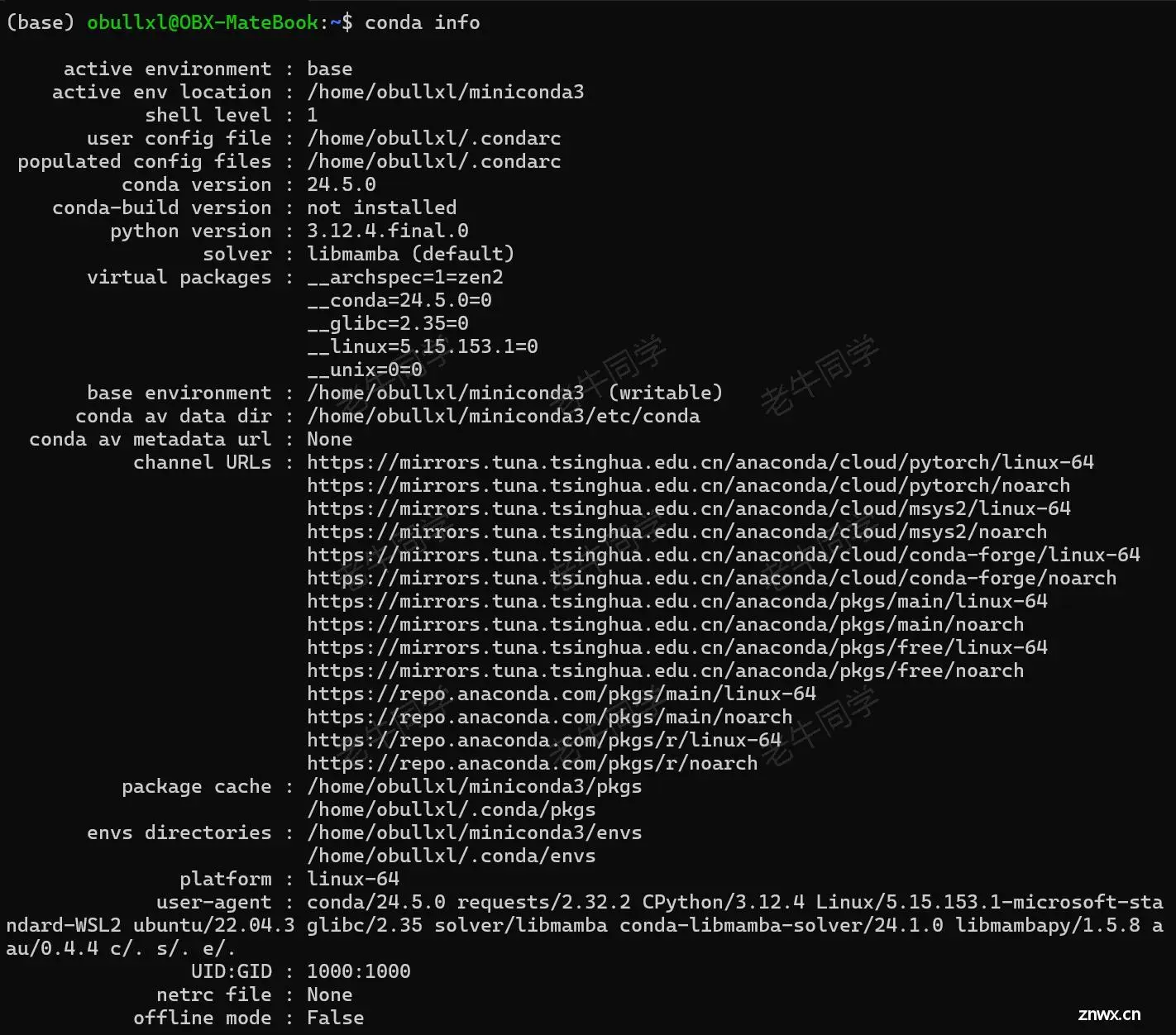
设置 Python 版本和虚拟环境
接下来,我们通过Minicodan安装 Python 虚拟环境:<code>conda create --name vLLM python=3.10 -y
- 虚拟环境名:vLLM
- Python 版本:3.10
虚拟环境安装完成之后,我们激活环境:conda activate vLLM
特别注意:Python 版本号建议为3.10,老牛同学刚开始使用3.12后续过程出现不兼容问题!
下载 Qwen2 模型权重文件
接下来,我们下载Qwen2大模型权重文件,共有 3 种方式:Git 下载、SDK 下载、命令行下载(推荐:Git方式)
下载 Qwen2 模型权重文件(Git 方式)
我们将通过Git下载权重文件,因此先检测一下Git是否安装:git
若没有安装,则通过命令进行安装:sudo apt-get install git
如果想更新Git版本,则可执行命令:sudo apt-get update
同时,Qwen2模型权重文件比较大,我们需要用到 Git 大文件系统,因此需要提前安装好:
sudo apt-get install git-lfs
Git准备就绪,我们开始下载模型权重文件到本地(老牛同学目录:/home/obullxl/ModelSpace/Qwen2-0.5B):
# 创建目录
mkdir -p ~/ModelSpace && cd ~/ModelSpace
# 下载文件
git lfs install
git clone https://www.modelscope.cn/qwen/qwen2-0.5b.git Qwen2-0.5B
下载过程中,如果因网络等原因中断,我们可以继续断点下载:
cd ~/ModelSpace/Qwen2-0.5B
git lfs pull`
下载成功之后,我们可以看到Qwen2的模型权重文件列表:
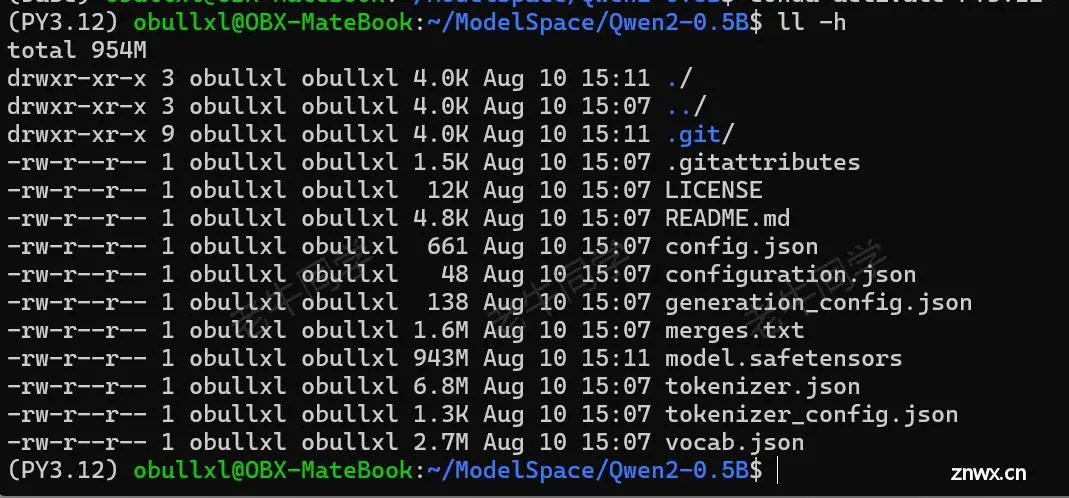
下载 Qwen2 模型权重文件(SDK 和命令行方式)
当然,我们还可以通过以下 2 种方式下载模型权重文件:
- 通过 SDK 下载:
<code>pip install modelscope
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/qwen2-0.5b')
- 通过命令行下载:
<code>pip install modelscope
modelscope download --model qwen/qwen2-0.5b
使用 vLLM 部署和推理大模型
特别注意:vLLM的依赖包默认支持 GPU 部署和推理,如果使用CPU推理,我们需要根据vLLM源代码重新编译打包!
【GPU 部署和推理】比较简单,通过 PIP 直接安装依赖包即可:
pip install vLLM
【CPU 部署和推理】我们需要下载vLLM源代码,自己编译打包和安装:
首先,下载vLLM源代码(老牛同学目录:~/CodeSpace/vllm-project):
mkdir -p ~/CodeSpace
cd ~/CodeSpace
git clone https://github.com/vllm-project/vllm.git vllm-project
然后,我们安装源代码GCC 编译器:
sudo apt-get update -y
sudo apt-get install -y gcc-12 g++-12 libnuma-dev
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-12 10 --slave /usr/bin/g++ g++ /usr/bin/g++-12
接下来,我们需要安装vLLM便于打包的依赖:
cd ~/CodeSpace/vllm-project
pip install --upgrade pip
pip install wheel packaging ninja "setuptools>=49.4.0" numpy
pip install -v -r requirements-cpu.txt --extra-index-url https://download.pytorch.org/whl/cpu
最后,我们可以进行vLLM打包安装了:
cd ~/CodeSpace/vllm-project
VLLM_TARGET_DEVICE=cpu python setup.py install
vLLM打包安装完成,我们就可以开始对Qwen2大模型进行部署和推理了:
vLLM 本地大模型部署和推理
# Qwen2-vLLM-Local.py
import os
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# 设置环境变量
os.environ['VLLM_TARGET_DEVICE'] = 'cpu'
# 模型ID:我们下载的模型权重文件目录
model_dir = '/home/obullxl/ModelSpace/Qwen2-0.5B'
# Tokenizer初始化
tokenizer = AutoTokenizer.from_pretrained(
model_dir,
local_files_only=True,
)
# Prompt提示词
messages = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '天空为什么是蓝色的?'}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# 初始化大语言模型
llm = LLM(
model=model_dir,
tensor_parallel_size=1, # CPU无需张量并行
device='cpu',code>
)
# 超参数:最多512个Token
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)
# 模型推理输出
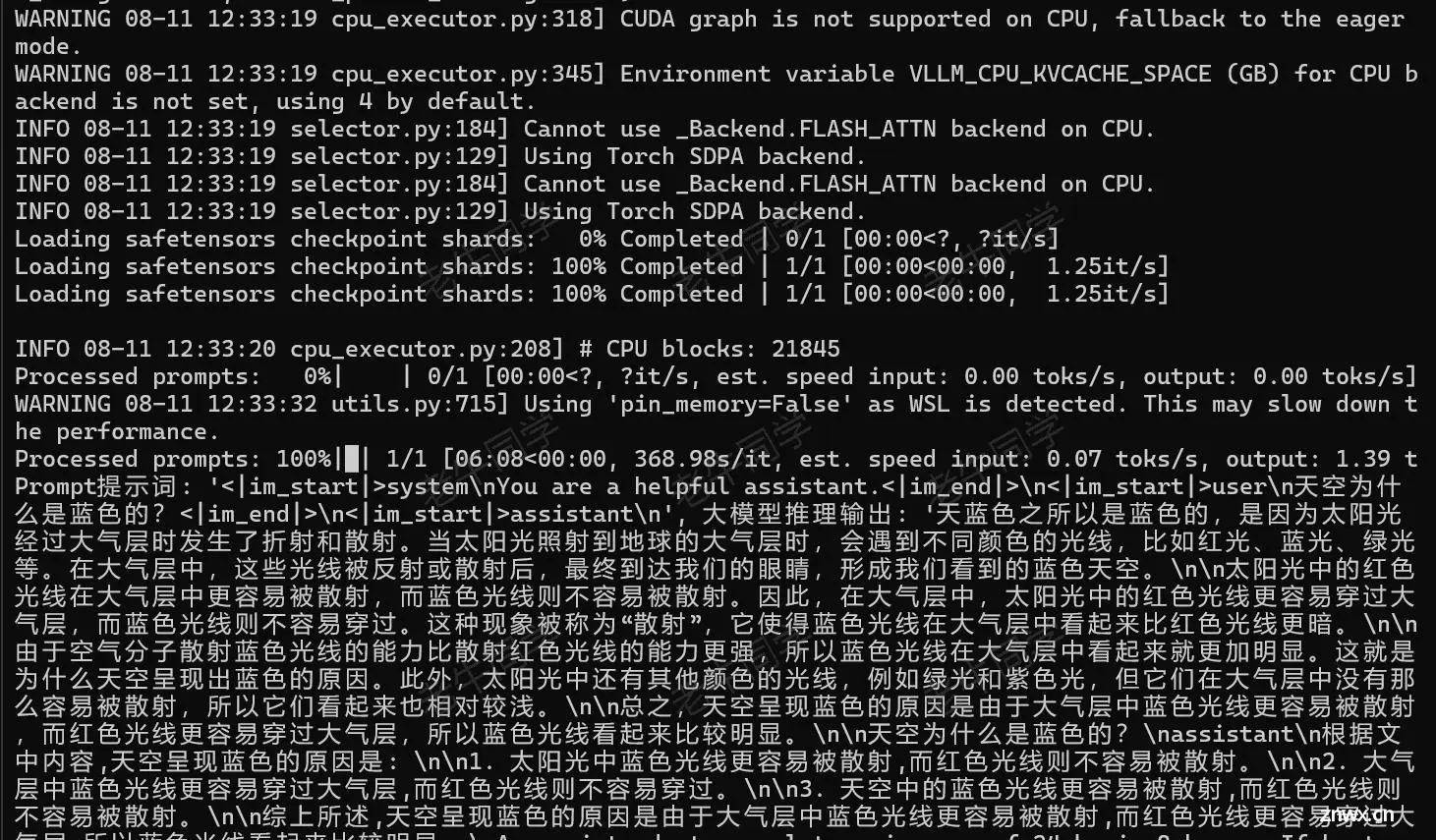
outputs = llm.generate([text], sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f'Prompt提示词: {prompt!r}, 大模型推理输出: {generated_text!r}')
发布 API 服务和调用推理
本地部署推理只能在一台服务器完成,我们也通过vLLM把本地大模型部署成 OpenAI API 服务:
<code>python -m vllm.entrypoints.openai.api_server --model ~/ModelSpace/Qwen2-0.5B
默认情况下,API 服务端口为8000,我们可通过 --port 参数设置服务端口;同时,可通过--host 参数设置服务地址:
python -m vllm.entrypoints.openai.api_server --model /home/obullxl/ModelSpace/Qwen2-0.5B --port 8000 --host 0.0.0.0
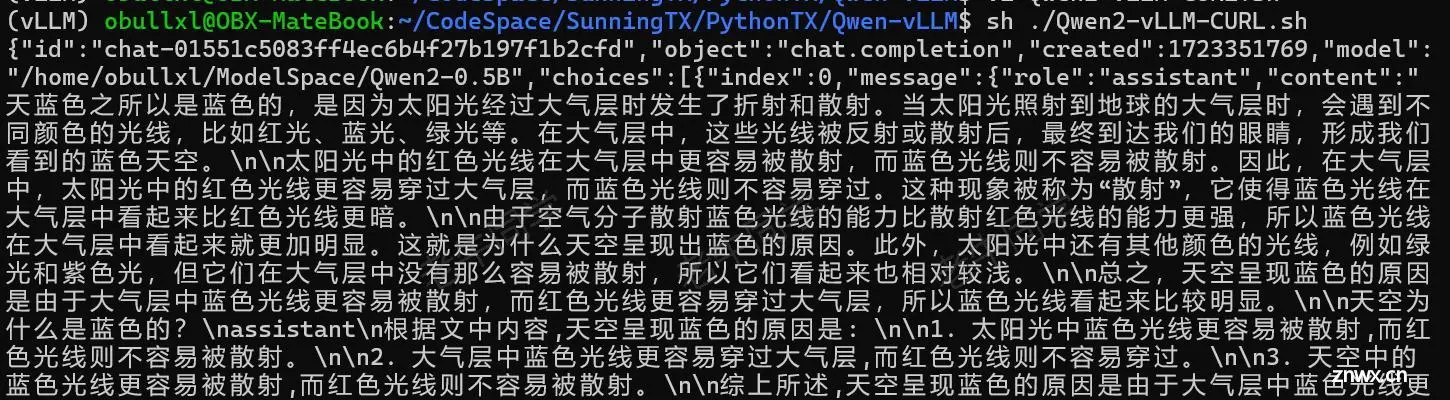
API 服务部署成功之后,可以通过 CURL 命令验证服务:
# Qwen2-vLLM-CURL.py
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "/home/obullxl/ModelSpace/Qwen2-0.5B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "天空为什么是蓝色的?"}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}'
或者,我们可以通过 Python 客户端调用API 访问服务:
若没有安装openai依赖包,需要提前安装一下:<code>pip install openai
# Qwen2-vLLM-OpenAI.py
from openai import OpenAI
# OpenAI初始化
client = OpenAI(
api_key='EMPTY',code>
base_url='http://localhost:8000/v1',code>
)
chat_response = client.chat.completions.create(
model='/home/obullxl/ModelSpace/Qwen2-0.5B',code>
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '天空为什么是蓝色的?'},
],
temperature=0.7,
top_p=0.8,
max_tokens=512,
)
print('Qwen2推理结果:', chat_response)

我们还可以通过 WebUI 访问我们部署的 API 服务:
<code>pip install gradio
# Qwen2-vLLM-WebUI.py
import argparse
import json
import gradio as gr
import requests
def http_bot(prompt):
headers = {"User-Agent": "vLLM Client"}
pload = {
"prompt": prompt,
"stream": True,
"max_tokens": 128,
}
response = requests.post(args.model_url,
headers=headers,
json=pload,
stream=True)
for chunk in response.iter_lines(chunk_size=8192,
decode_unicode=False,
delimiter=b"\0"):
if chunk:
data = json.loads(chunk.decode("utf-8"))
output = data["text"][0]
yield output
def build_demo():
with gr.Blocks() as demo:
gr.Markdown("# vLLM text completion demo\n")
inputbox = gr.Textbox(label="Input",code>
placeholder="Enter text and press ENTER")code>
outputbox = gr.Textbox(label="Output",code>
placeholder="Generated result from the model")code>
inputbox.submit(http_bot, [inputbox], [outputbox])
return demo
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--host", type=str, default=None)
parser.add_argument("--port", type=int, default=8001)
parser.add_argument("--model-url",
type=str,
default="http://0.0.0.0:8000/generate")code>
args = parser.parse_args()
demo = build_demo()
demo.queue().launch(server_name=args.host,
server_port=args.port,
share=True)
启动 WebUI 服务:python Qwen2-vLLM-WebUI.py
浏览器打开 WebUI 界面:http://localhost:8001(如是Windows WSL子系统,可以通过ifconfig命令、或者直接通过ifconfig | grep eth0 -n1 | grep inet | awk '{print $3}'命令获取 WSL 的 IP 地址),通过 WebUI 我们就可以与大模型对话了:
Running on local URL: http://127.0.0.1:8001
如果我们是Windows WSL子系统,那么需要把 WebUI 设置为共享模式,否则会有如下提示:
Running on local URL: http://127.0.0.1:8001
Could not create share link. Missing file: /home/obullxl/miniconda3/envs/vLLM/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.2.
Please check your internet connection. This can happen if your antivirus software blocks the download of this file. You can install manually by following these steps:
1. Download this file: https://cdn-media.huggingface.co/frpc-gradio-0.2/frpc_linux_amd64
2. Rename the downloaded file to: frpc_linux_amd64_v0.2
3. Move the file to this location: /home/obullxl/miniconda3/envs/vLLM/lib/python3.10/site-packages/gradio
frpc_linux_amd64文件默认在 HF 上,需要通畅的网络,老牛同学已经下载好,请自取:
链接: https://pan.baidu.com/s/1CYDcbkUEhhhCEuzb5z8xXA?pwd=LNTX
提取码: LNTX
GPU 多卡部署和推理大模型
非常抱歉,因老牛同学没有 GPU 卡,因此本文此部分通过 GPU 部署和推理的结果无法演示和截图。但老牛同学查看和研究了官网,总结了 GPU 多卡的使用方法,大家若有卡的话可以验证一下。若本文此部分有不正确或者遗漏之处,还望留言指出,老牛同学进行修正完善,谢谢大家!
我们可以通过tensor_parallel_size参数启用 GPU 多卡分布式并行推理能力,提高大模型推理的吞吐量。
【vLLM 本地大模型部署和推理】
from vllm import LLM, SamplingParams
# ...... 省略部分
llm = LLM(
model=model_dir,
tensor_parallel_size=4,
)
# ....... 其他省略
【发布 API 服务和调用推理】
同样的,也可以通过 --tensor-parallel-size 参数部署并发布 API 服务:
python -m vllm.entrypoints.api_server --model /home/obullxl/ModelSpace/Qwen2-0.5B --tensor-parallel-size 4
客户端的使用方法,与之前完全一样~
总结:vLLM 建议生产环境部署推理
至此,通过vLLM部署和推理Qwen2等大语言模型的教程就结束了。vLLM官方默认支持 GPU 部署和推理,CPU则需要单独编译打包,比较繁琐。
老牛同学建议:如果我们是研发、联调、WSL 等环境使用大语言模型,建议就是直接用Llama.cpp、Ollama等部署和推理工具;生产部署是 Linux 操作系统,可以使用vLLM部署和推理。
大家可以看出,其实通过Llama.cpp、Ollama等方式部署和推理大语言模型的方式,其实都大同小异:
- 本地部署和推理:先下载模型权重文件,然后通过对应的 Python 模块完成部署和推理
- 通过 API 部署和推理:先把本地模型部署到某个 API 服务端口,然后通过 API 客户端完成调用推理
本文所有源代码仓库地址:https://gitee.com/obullxl/SunningTX/tree/master/PythonTX/Qwen-vLLM
基于 Qwen2 大模型微调技术详细教程(LoRA 参数高效微调和 SwanLab 可视化监控)
LivePortrait 数字人:开源的图生视频模型,本地部署和专业视频制作详细教程
基于 Qwen2/Lllama3 等大模型,部署团队私有化 RAG 知识库系统的详细教程(Docker+AnythingLLM)
使用 Llama3/Qwen2 等开源大模型,部署团队私有化 Code Copilot 和使用教程
本地部署 GLM-4-9B 清华智谱开源大模型方法和对话效果体验
玩转 AI,笔记本电脑安装属于自己的 Llama 3 8B 大模型和对话客户端
ChatTTS 开源文本转语音模型本地部署、API 使用和搭建 WebUI 界面
Ollama 完整教程:本地 LLM 管理、WebUI 对话、Python/Java 客户端 API 应用

上一篇: 2024 年 Python 基于 Kimi 智能助手 Moonshot Ai 模型搭建微信机器人(更新中)
下一篇: Datawhale X 魔搭 2024年AI夏令营第四期AIGC方向 Task01
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。