机器学习的数学基础--微积分
cnblogs 2024-08-18 11:13:00 阅读 86
微积分运算在机器学习领域扮演着至关重要的角色,
它不仅是许多基础算法和模型的核心,还深刻影响着模型的优化、性能评估以及新算法的开发。
掌握微积分,不仅让我们多会一种计算方式,也有助于理解各种机器学习算法和模型是如何寻找最优参数的。
1. 为什么需要微积分?
也许有些人会觉得微积分很难,这大概是因为我们平时基本都是在计算固定的东西(用加减乘除就够了)。
比如:
而对于不断变化的事物,我们发现用传统的计算方式很难精确的描述,
比如:
- 计算汽车在一段时间内的行驶距离。实际情况下的汽车速度是不断变化的(而且是无规律的变化,跟路况,载重等多种因素有关),此时如何计算距离和速度的关系。
- 预测人口的增长。人口增长是一个连续变化的过程,受出生率、死亡率、迁移率等多种因素的影响,根据以往的人口增长数据,预测未来某个时间点人口的数量。
- 股票交易买卖时机的分析。根据以往的股价变化,预测将来在哪些价格点上更容易上涨或下跌。
微积分本质上就是一种运算方式(类似加减乘除,指数,对数等等运算),
与其他运算方式相比,它的优势在于可以精确的描述事物的变化。
2. 微分
微积分其实包括微分和积分两种运算,它们互为逆运算,就像加法与减法,乘法与除法。
微分研究函数在某一点附近的变化率,而积分研究函数在某一区间上的累积效应。
平时我使用较多的是微分,也被称为求导数。
2.1. 什么是微分
微积分的诞生还有一段“斗争”,当年,牛顿和莱布尼茨都宣称自己先发明了微积分,虽然最终牛顿胜出,但二位都是非常伟大的科学家。
由此也可见当时欧洲的科技已经发展到相当的程度,才会在科研中迫切的需要微积分这种新的运算方式。
下面通过一个速度与时间关系的示例来看看最终微积分如何帮助我们精确计算变化的。
首先,对于两个匀速运动的物体,
| 时间(\(t\)) | 速度(\(v_1\)) | 速度(\(v_2\)) |
|---|---|---|
| 0 | 5 | 8 |
| 1 | 5 | 8 |
| 3 | 5 | 8 |
| 5 | 5 | 8 |
| 10 | 5 | 8 |
匀速的情况下,速度不变,一眼就能看出谁快谁慢,并不需要微积分。
接下来,看看匀变速的情况:
| 时间(\(t\)) | 速度(\(v_1\)) | 速度(\(v_2\)) |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 2 | 3 |
| 3 | 6 | 9 |
| 5 | 10 | 15 |
| 10 | 20 | 30 |
其中\(v_1=2t\),\(v_2=3t\)。
在这种情况下,我们依然可以看出两个物体谁快谁慢,也可以计算出它们的加速度分别为2和3,不需要微积分。
最后,看看非匀变速的情况,这也是最接近实际的情况。
如果你有实际驾驶的经验就能理解,行驶过程中几乎不可能保持匀速或匀变速,影响车速的因素各种各样,你能控制的油门仅仅是其中之一。
模拟两个非匀变速的情况:
| 时间(\(t\)) | 速度(\(v_1\)) | 速度(\(v_2\)) |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 10 | 1 |
| 3 | 90 | 27 |
| 5 | 250 | 125 |
其中\(v_1=10t^2\),\(v_2=t^3\)。
这下,没那么容易看出哪个速度增加的快了吧?这两个物体在某一时刻的加速度也不是那么容易计算了吧?
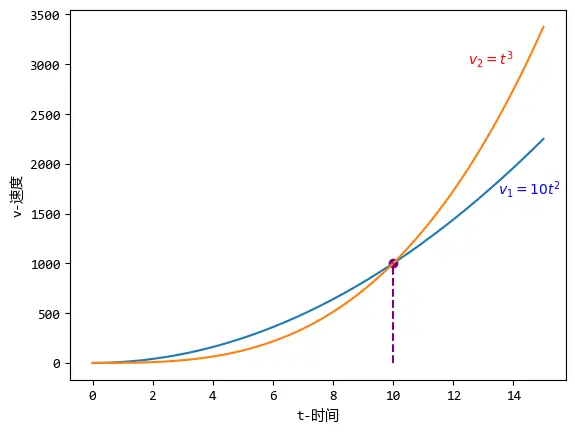
从图中虽然可以看出,10秒之前,\(v_1\)比\(v_2\)快,10秒之后,\(v_2\)比\(v_1\)快。
但是\(v_1\)和\(v_2\)哪个增长的快?即使从上面的图中也不是那么容易看出。
这时,通过微积分就能看出谁变化的快了。
微分的计算规则下一节介绍,这里先看下微分的结果:\(v_1^{'} = 20t\);\(v_2^{'}=3t^2\)。
对速度微分的结果就是速度变化的情况:
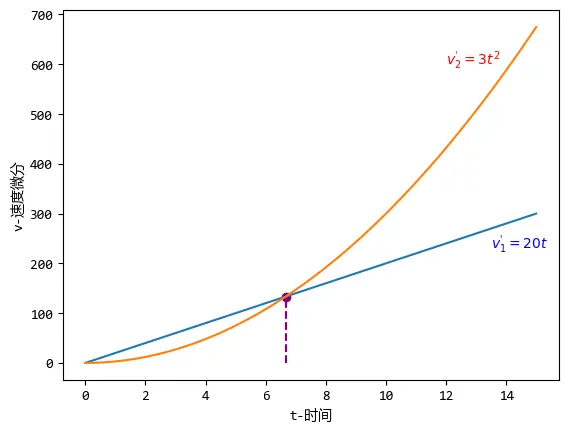
微分之后,就能精确的看出2个速度的变化情况:
- <li>紫色交点之前,\(v_1\)增加的比\(v_2\)快
- 紫色交点之后,\(v_2\)增加的比\(v_1\)快
2.2. 计算规则
从上例可以看出,对于复杂的变化情况(非均匀变化),
通过微分可以快速找出变化的规律,从而可以精确的计算每个时间点的实际数值。
微分的计算虽然没有加减乘除那么直观,但是也不复杂。
对于多项式,微分的规律如下:其中\(a\)是常数;\(n\)是变量\(x\)的指数。
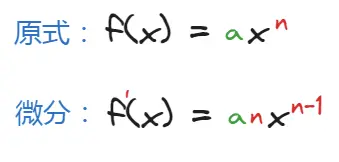
其他特殊的函数(比如三角函数,对数函数等等)可以参考维基百科的微分表:
https://en.wikipedia.org/wiki/Differentiation_rules
2.3. 链式法则
微分运算法则中,有一个很有用的特性,称为链式法则。
当需要计算嵌套函数的微分时,这个法则非常有用,比如:

一种方式是将\(y\)的多项式代入\(f\)函数中:
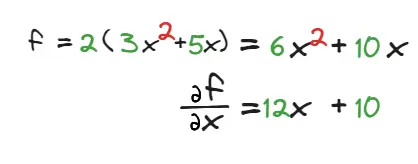
另一种方式就是链式法则,
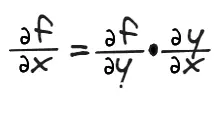
函数\(f\)对\(x\)求导,可以转换为\(f\)对\(y\)求导与\(y\)对\(x\)求导的积。由此可得:
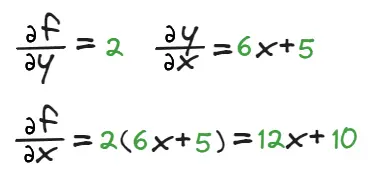
两种方式的计算结果是一样的,
不过,如果函数\(f\)和\(y\)都非常复杂的话,运用链式法则,可以极大的简化微分运算。
3. 偏微分
在机器学习的算法中,公式中不可能只有一个变量\(f(x)\),基本都是多个变量\(f(x_0,x_1,...,x_n)\)的情况。
在这种情况下,怎么计算函数\(f\)中各个变量的变化趋势呢?
这就用到了偏微分(也称为偏导数),也就是函数\(f\)对其中一个变量求导数。
3.1. 计算规则
了解了微分的计算方法,那么偏微分的计算就很简单了。比如一个含有两个变量的函数:
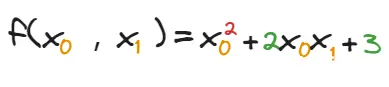
那么,对\(x_0\)和 \(x_1\)分别求导数的结果如下:
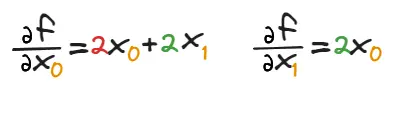
简单来说,对\(x_0\)求导数时,把\(x_1\)当成常数看待;对\(x_1\)求导数时,把\(x_0\)当成常数看待。
通过偏微分计算,我们就能发现哪个变量变化时对函数\(f\)的结果影响最大。
对应的场景就是机器模型(\(f\))中,哪个属性(\(x_0, x_1\))对模型的结果影响最大。
3.2. 偏微分的图形意义
对于偏微分,也可以从图像上来看,不过超过3个维度的图像无法绘制,所以只能绘制带有2个参数的函数。
绘制上面示例中函数:\(f(x_0,x_1)=x_0^{2}+2x_0x_1+3\)
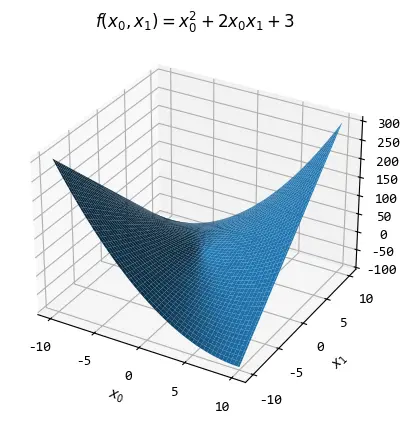
然后分别对\(x_0,x_1\)求偏微分,对\(x_0\)的偏微分为:\(f^{'}(x_0)=2x_0+2x_1\)
\(x_1\)取不同的值时,偏微分的图像为:
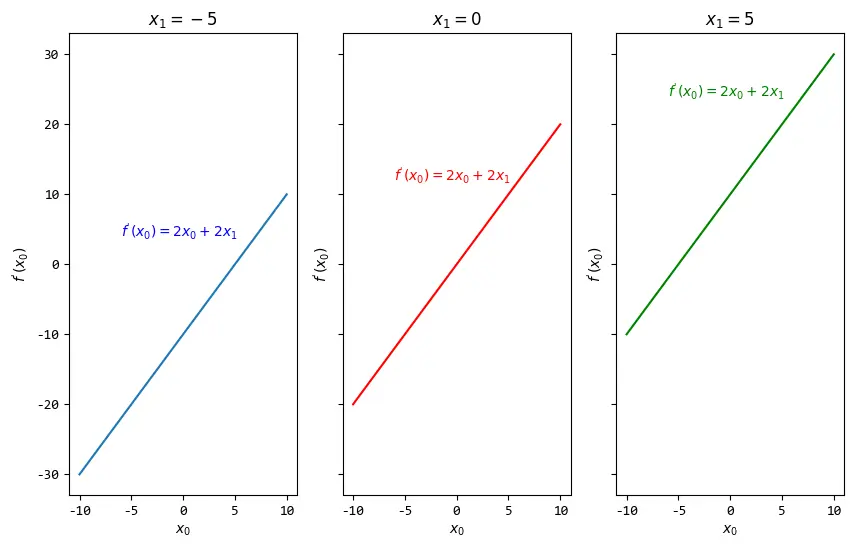
从图中可以看出,偏微分\(f^{'}(x_0)\)的变化率是线性增长的,\(x_1\)只是影响它的起始值。
如果把\(f(x_0,x_1)=x_0^{2}+2x_0x_1+3\)看成一个机器学习模型,
那么随着属性\(x_0\)的增大,\(x_0\)对模型的影响越来越大。
对\(x_1\)的偏微分为:\(f^{'}(x_1)=2x_0\),\(x_0\)取不同的值时,偏微分的图像为:
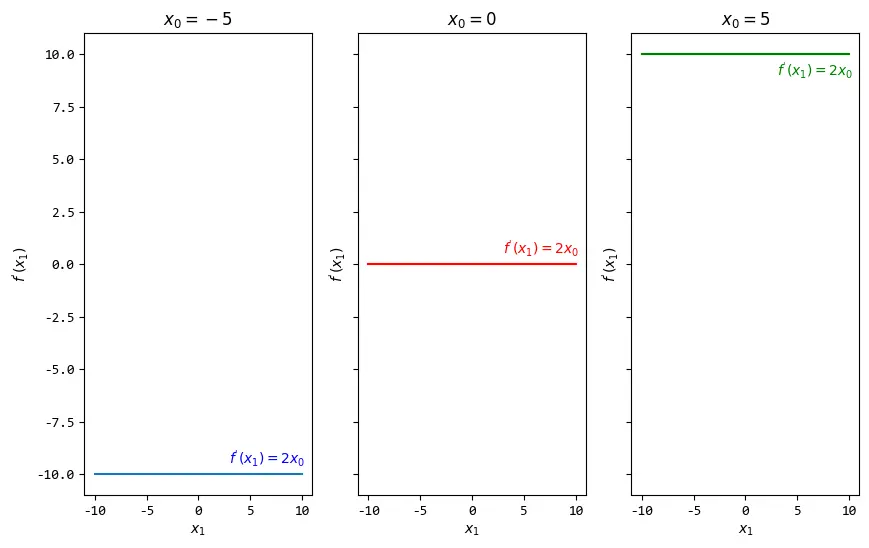
从图中可以看出,偏微分\(f^{'}(x_1)\)的变化率是固定的,\(x_0\)决定它的变化率是多少。
如果把\(f(x_0,x_1)=x_0^{2}+2x_0x_1+3\)看成一个机器学习模型,
那么随着属性\(x_1\)对模型影响的大小是稳定的,影响多大取决于\(x_0\)的取值。
4. 总结
我平时接触的机器学习算法中,微分使用的比较多,所以这里只介绍了微分的相关运算,积分是微分的逆运算,这里不再赘述。
对于复杂函数的积分,也有积分表可以查询(https://en.wikipedia.org/wiki/Lists_of_integrals)。
最后,总结下在哪些机器学习算法中会遇到微积分的运算。
- <li>梯度下降算法:用于寻找函数的局部最小值。它通过计算损失函数关于模型参数的梯度(即偏导数),并沿着梯度的反方向更新参数。
- 反向传播算法:基于链式法则,从输出层到输入层逐层计算梯度,从而更新网络中的权重和偏置。
- 损失函数的设计:均方误差损失函数和交叉熵损失函数都是可导的,并且它们的梯度可以很容易地通过微积分计算出来。
- 正则化技术:为了防止模型过拟合,常常使用正则化项通过惩罚模型的复杂度来减少过拟合的风险。此时,正则化项的设计依赖于微积分,因为需要计算它们关于模型参数的梯度,以便在优化过程中考虑它们的影响。
- 概率模型与贝叶斯方法:在机器学习的概率模型中,微积分被用于计算概率分布、条件概率、边缘概率以及期望等。
- 特征选择与降维:在特征选择和降维技术中,如主成分分析(
PCA)和线性判别分析(LDA),微积分被用于计算数据的协方差矩阵、特征值、特征向量等,从而帮助识别出最重要的特征或降低数据的维度。 - 其他。。。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。