香橙派OrangePi AI Pro测评部署车牌号识别项目
^Lim 2024-07-31 14:01:06 阅读 65
文章目录
一、前言二、香橙派 AIpro 开发板2.1 开发板简介2.2 开发板硬件规格2.3 开发板的接口详情图2.4 开箱实物
三、基于Yolov5的车牌识别系统3.1 开源地址3.2 项目介绍3.3 拉取项目并部署3.4 图片识别3.5 视频识别3.6 模型训练3.7 代码3.8 关键的分析3.9 笔者的一些想法
四、使用香橙派 AIpro 开发板遇到的问题和总结4.1 遇到的问题4.2 运行车牌号识别项目的感受4.3 总结
一、前言
随着智能交通系统的不断发展,车牌号识别技术在交通管理和车辆监控中发挥着越来越重要的作用。<code>香橙派 AIpro 开发板作为一款高性能嵌入式 AI平台 ,以其强大的计算能力和丰富的接口,成为了车牌号识别项目的理想选择。在本篇测评中,我们将详细介绍如何使用
香橙派 AIpro 开发板进行 车牌号识别,并探讨其在实际应用中的表现。
香橙派 AIpro 开发板搭载了高效的处理器和AI加速单元,能够 快速处理图像数据,识别车牌号信息。其紧凑设计和低功耗特性使其非常适合部署在实际交通监控系统中。通过这次测评,我们希望展示香橙派 AIpro 开发板在车牌号识别任务中的潜力,并为开发者提供实用的参考和指导。
在接下来的部分,我们将从 硬件配置 、软件环境搭建 、模型训练 与 优化 等方面进行详细介绍,并通过实际案例展示 香橙派 AIpro 开发板在车牌号识别项目中的性能表现和优势。希望通过本次测评,能够帮助读者更好地了解并利用
香橙派 AIpro 开发板,推动智能交通系统的发展和应用。
二、香橙派 AIpro 开发板
2.1 开发板简介
香橙派 AIpro 开发板是一款高性能的嵌入式人工智能开发平台,专为边缘计算和物联网 (IoT) 应用设计。它具有 强大的处理能力 和丰富的 扩展接口,能够满足各种 AI 和 计算任务 的需求。
2.2 开发板硬件规格

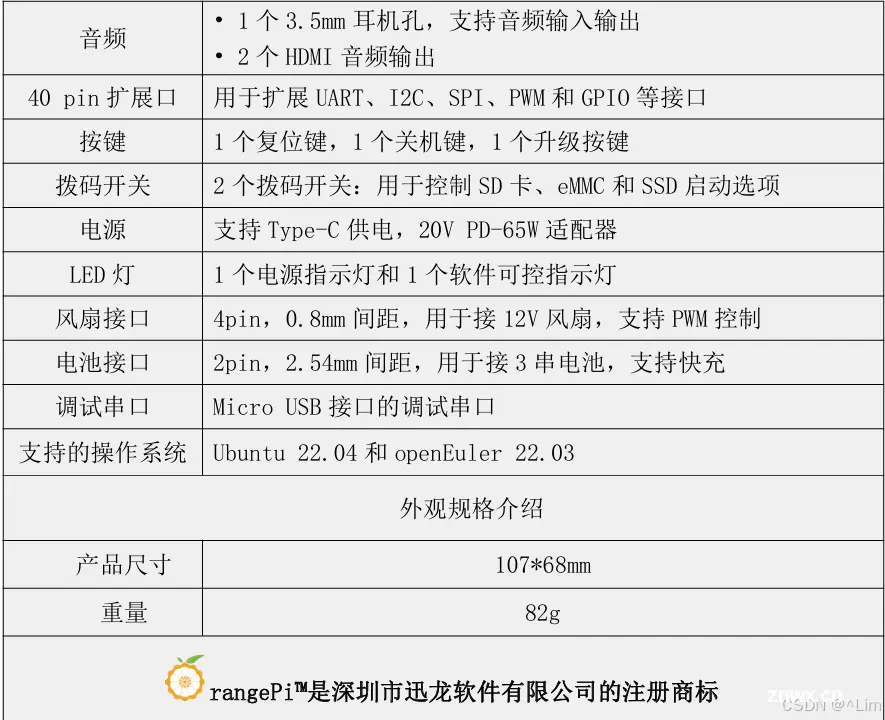
2.3 开发板的接口详情图
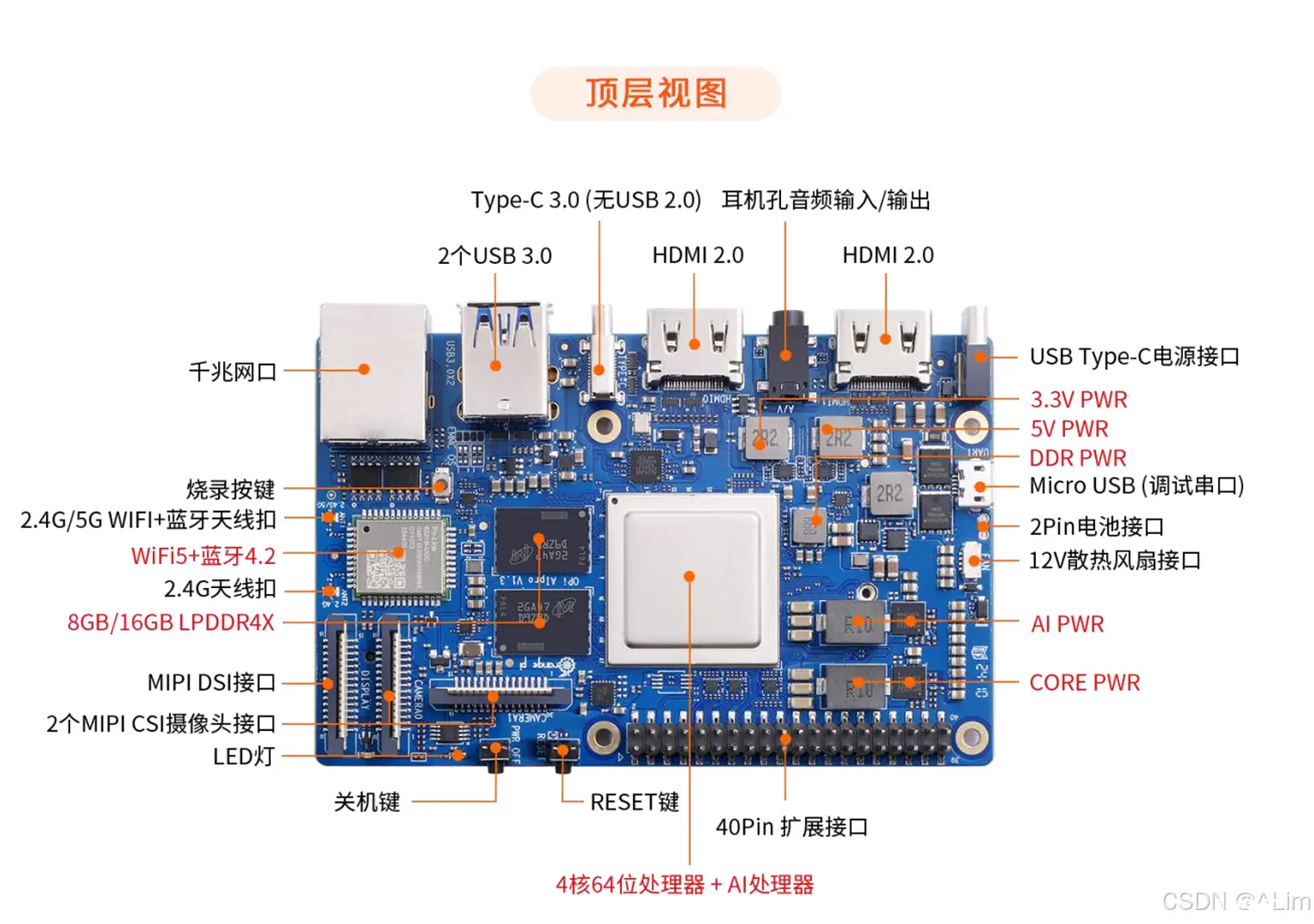
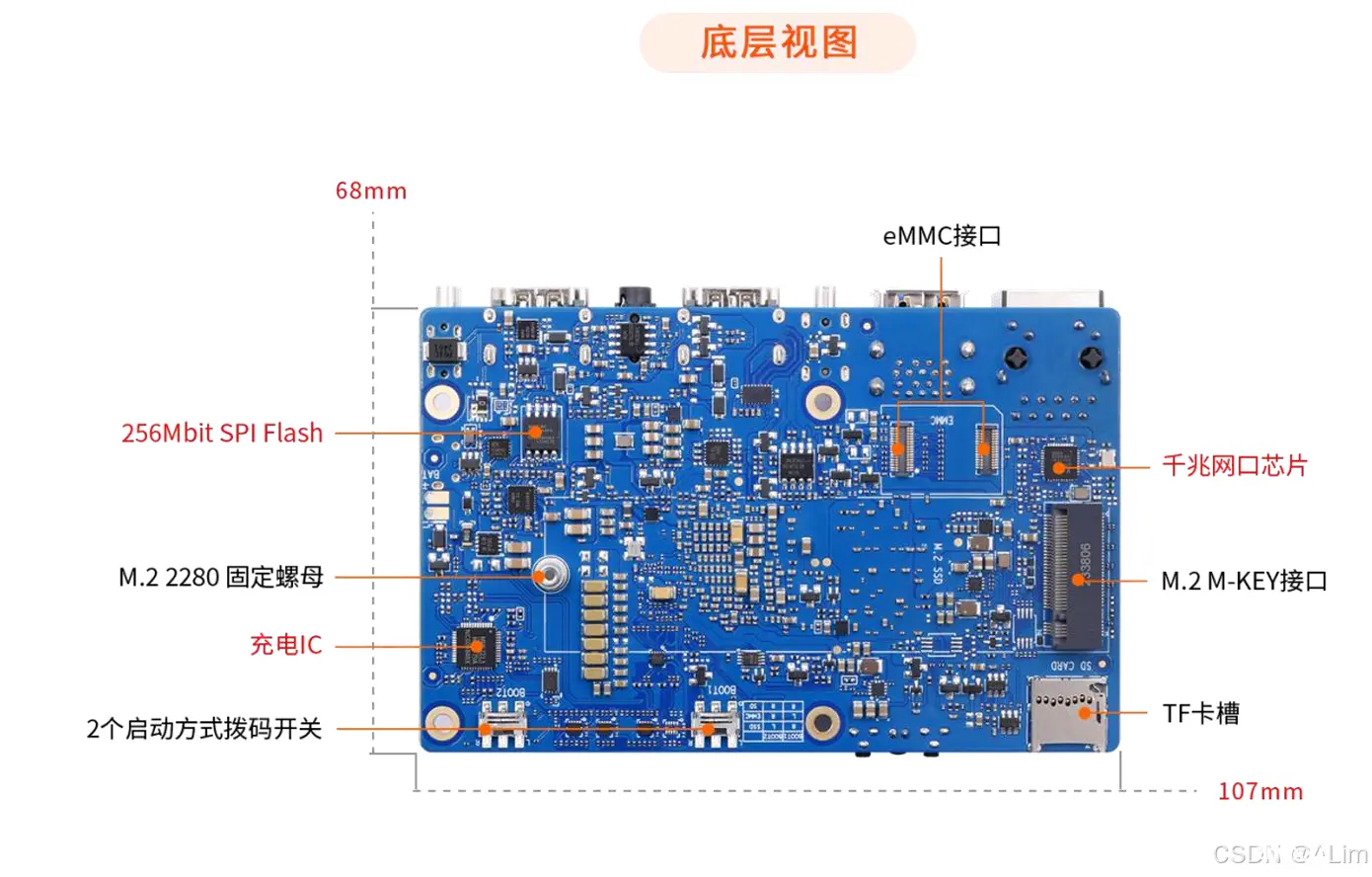
2.4 开箱实物
操作系统界面
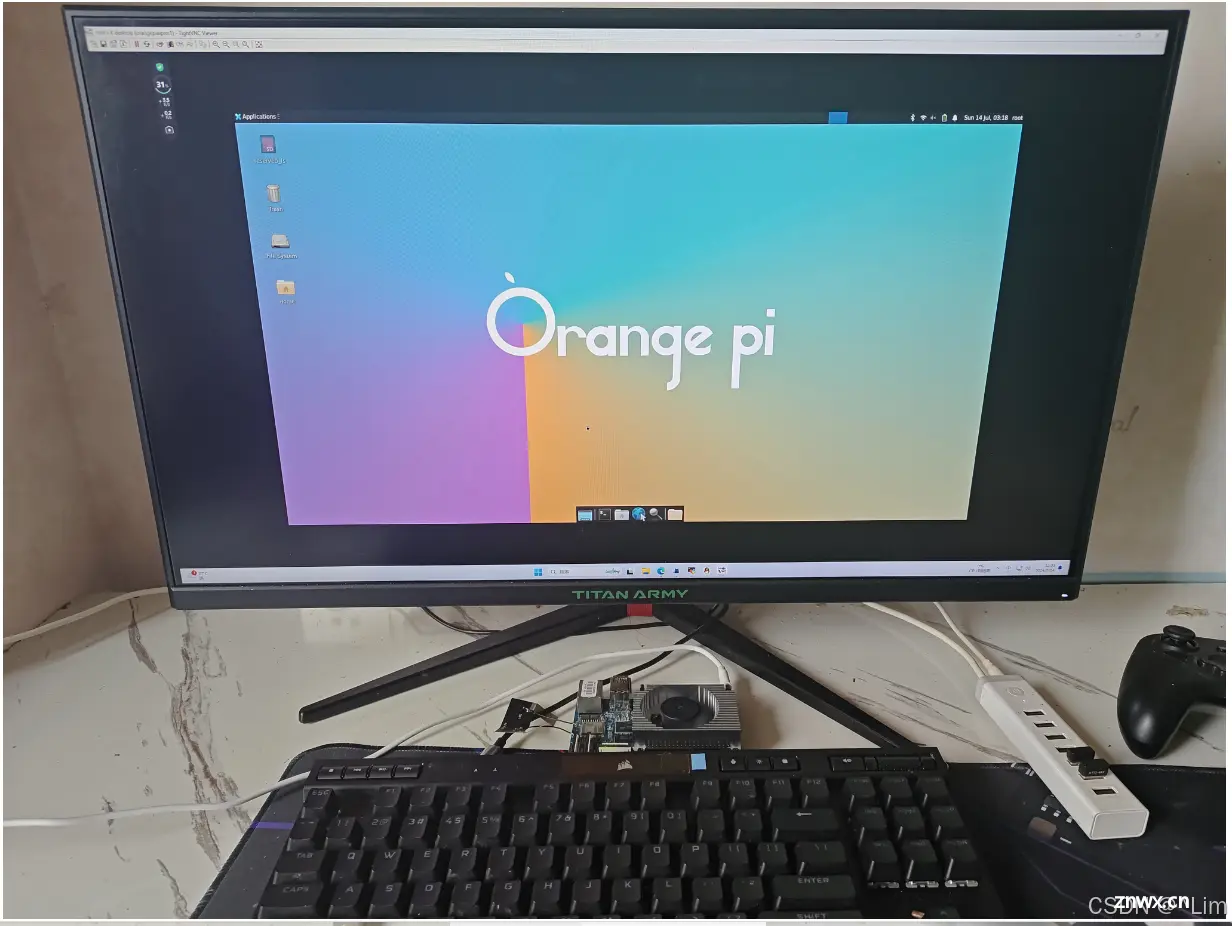
这个界面还是挺简洁的。
正面

反面

外观设计
香橙派 AIpro 开发板采用紧凑而美观的设计,其巧妙布局的元器件和接口不仅实用,更让人赏心悦目。开发板表面的元器件排列整齐,布局合理,接口的位置设计合理,方便用户连接各种外设设备,同时保持整洁有序的外观。
精细做工
开发板的做工非常精细,每一个接口和元器件的安装都非常牢固,避免了使用过程中可能出现的松动或接触不良问题。整体做工不仅提升了产品的耐用性,也为用户带来了极佳的使用体验。
板载散热系统
香橙派 AIpro 开发板还配备了高效的散热系统,包括铝合金散热片和风扇,既美观又实用。散热片表面光滑,金属质感十足,与整板的黑色主色调相得益彰,不仅有效散热,更为开发板增添了一份科技感和时尚感。
香橙派 AIpro 开发板在颜值和做工上无可挑剔
三、基于Yolov5的车牌识别系统
3.1 开源地址
基于Yolov5的车牌识别系统GitHub地址
3.2 项目介绍
此项目是一个基于深度学习的 <code>车牌号检测和识别系统 ,旨在提供一个高效、准确的解决方案,用于识别 中国车牌号 。该项目利用先进的卷积神经网络 (CNN) 技术,实现了从图像中 自动检测 和 识别车牌号 的功能,是智能交通系统中的重要组成部分。支持``12种中文车牌、支持双层车牌` 的目标识别系统。
支持如下:
1.单行蓝牌2.单行黄牌3.新能源车牌4.白色警用车牌5.教练车牌6.武警车牌7.双层黄牌8.双层白牌9.使馆车牌10.港澳粤Z牌11.双层绿牌12.民航车牌
3.3 拉取项目并部署
设置 Git 使用 GnuTLS
git config --global http.sslBackend gnutls
检查配置
git config --global --get http.sslBackend
这个命令应该返回 gnutls
克隆仓库
git clone https://github.com/we0091234/Chinese_license_plate_detection_recognition.git
进入项目文件
<code>cd Chinese_license_plate_detection_recognition/
下载解决依赖文件
由于项目所需要依赖过多,下载时间会稍微有一点长
pip install -r ./requirements.txt -i https://mirrors.aliyun.com/pypi/simple
项目文件目录
3.4 图片识别
验证集

运行
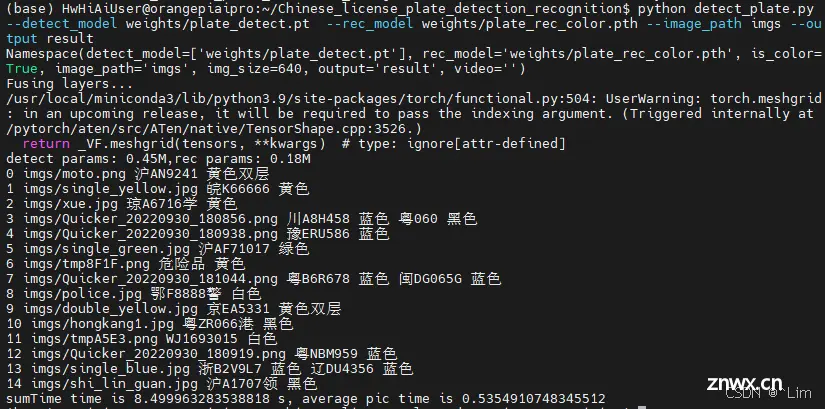
<code>python detect_plate.py --detect_model weights/plate_detect.pt --rec_model weights/plate_rec_color.pth --image_path imgs --output result
测试文件夹 imgs ,结果保存再 result 文件夹 中
运行结果
命令行
实际结果

3.5 视频识别
验证视频
车牌号识别项目demo视频
运行
<code>python detect_plate.py --detect_model weights/plate_detect.pt --rec_model weights/plate_rec_color.pth --video 2.mp4
视频文件为 2.mp4. 保存为 result.mp4
运行结果
命令行
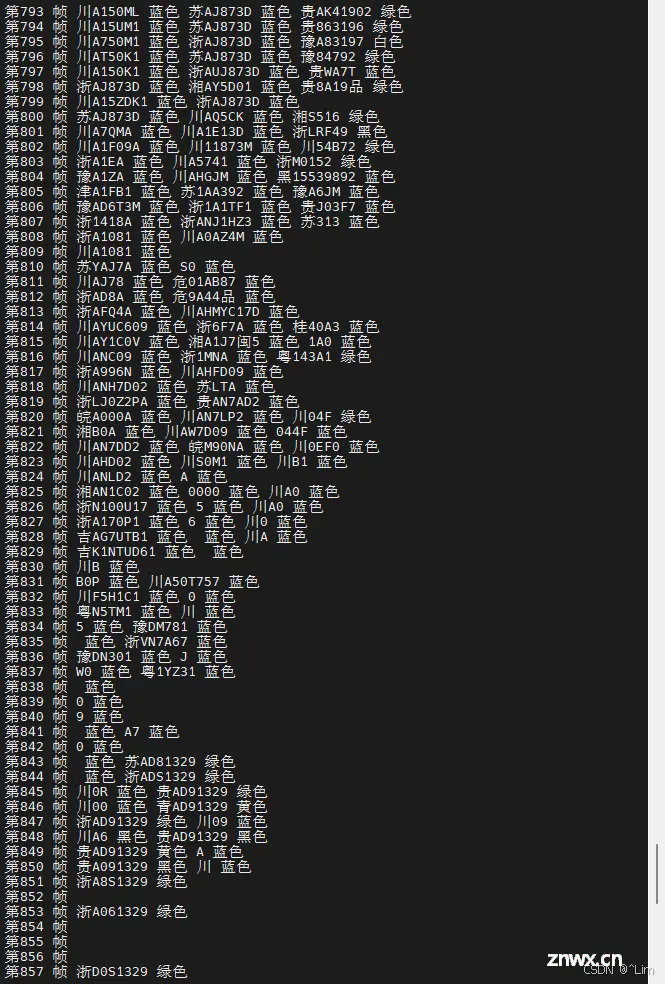
实际效果
车牌号识别项目demo输出视频
3.6 模型训练
在使用过程中,肯定是要自己配置 <code>训练的AI大模型.当我们需要训练自己的模型时只需要更改data/widerface.yaml 文件中的train与val路径即可。
train: /mnt/Gpan/Mydata/pytorchPorject/yolov5-face/ccpd/train_detect
val: /mnt/Gpan/Mydata/pytorchPorject/yolov5-face/ccpd/val_detect
说明:
train: /your/train/path: #修改成你的训练集路径
val: /your/val/path: #修改成你的验证集路径
更改完成后可直接使用命令开始训练
python3 train.py --data data/widerface.yaml --cfg models/yolov5n-0.5.yaml --weights weights/plate_detect.pt --epoch 120
python3 train.py:
运行 Python 脚本 train.py,这是 YOLOv5 的训练脚本。 --data data/widerface.yaml:
指定数据集的配置文件。data/widerface.yaml 是一个YAML 文件,包含训练数据和验证数据的路径、类别信息等。 --cfg models/yolov5n-0.5.yaml:
指定模型配置文件。models/yolov5n-0.5.yaml 是一个 YAML 文件,定义了 YOLOv5 模型的结构和参数。 --weights weights/plate_detect.pt:
指定预训练权重文件。weights/plate_detect.pt 是一个权重文件,通常是一个预训练的模型,用于加速训练过程或提高模型性能。 --epoch 120:
指定训练的轮数。120 表示训练将进行 120 个 epoch(轮次)。
3.7 代码
# -*- coding: UTF-8 -*-
import argparse
import time
from pathlib import Path
import os
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
import copy
import numpy as np
from models.experimental import attempt_load
from utils.datasets import letterbox
from utils.general import check_img_size, non_max_suppression_face, apply_classifier, scale_coords, xyxy2xywh, \
strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized
from utils.cv_puttext import cv2ImgAddText
from plate_recognition.plate_rec import get_plate_result,allFilePath,init_model,cv_imread
# from plate_recognition.plate_cls import cv_imread
from plate_recognition.double_plate_split_merge import get_split_merge
clors = [(255,0,0),(0,255,0),(0,0,255),(255,255,0),(0,255,255)]
danger=['危','险']
def order_points(pts): #四个点按照左上 右上 右下 左下排列
rect = np.zeros((4, 2), dtype = "float32")
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts): #透视变换得到车牌小图
# rect = order_points(pts)
rect = pts.astype('float32')
(tl, tr, br, bl) = rect
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
return warped
def load_model(weights, device): #加载检测模型
model = attempt_load(weights, map_location=device) # load FP32 model
return model
def scale_coords_landmarks(img1_shape, coords, img0_shape, ratio_pad=None): #返回到原图坐标
# Rescale coords (xyxy) from img1_shape to img0_shape
if ratio_pad is None: # calculate from img0_shape
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
else:
gain = ratio_pad[0][0]
pad = ratio_pad[1]
coords[:, [0, 2, 4, 6]] -= pad[0] # x padding
coords[:, [1, 3, 5, 7]] -= pad[1] # y padding
coords[:, :8] /= gain
#clip_coords(coords, img0_shape)
coords[:, 0].clamp_(0, img0_shape[1]) # x1
coords[:, 1].clamp_(0, img0_shape[0]) # y1
coords[:, 2].clamp_(0, img0_shape[1]) # x2
coords[:, 3].clamp_(0, img0_shape[0]) # y2
coords[:, 4].clamp_(0, img0_shape[1]) # x3
coords[:, 5].clamp_(0, img0_shape[0]) # y3
coords[:, 6].clamp_(0, img0_shape[1]) # x4
coords[:, 7].clamp_(0, img0_shape[0]) # y4
# coords[:, 8].clamp_(0, img0_shape[1]) # x5
# coords[:, 9].clamp_(0, img0_shape[0]) # y5
return coords
def get_plate_rec_landmark(img, xyxy, conf, landmarks, class_num,device,plate_rec_model,is_color=False): #获取车牌坐标以及四个角点坐标并获取车牌号
h,w,c = img.shape
result_dict={ }
tl = 1 or round(0.002 * (h + w) / 2) + 1 # line/font thickness
x1 = int(xyxy[0])
y1 = int(xyxy[1])
x2 = int(xyxy[2])
y2 = int(xyxy[3])
height=y2-y1
landmarks_np=np.zeros((4,2))
rect=[x1,y1,x2,y2]
for i in range(4):
point_x = int(landmarks[2 * i])
point_y = int(landmarks[2 * i + 1])
landmarks_np[i]=np.array([point_x,point_y])
class_label= int(class_num) #车牌的的类型0代表单牌,1代表双层车牌
roi_img = four_point_transform(img,landmarks_np) #透视变换得到车牌小图
if class_label: #判断是否是双层车牌,是双牌的话进行分割后然后拼接
roi_img=get_split_merge(roi_img)
if not is_color:
plate_number,rec_prob = get_plate_result(roi_img,device,plate_rec_model,is_color=is_color) #对车牌小图进行识别
else:
plate_number,rec_prob,plate_color,color_conf=get_plate_result(roi_img,device,plate_rec_model,is_color=is_color)
# cv2.imwrite("roi.jpg",roi_img)
result_dict['rect']=rect #车牌roi区域
result_dict['detect_conf']=conf #检测区域得分
result_dict['landmarks']=landmarks_np.tolist() #车牌角点坐标
result_dict['plate_no']=plate_number #车牌号
result_dict['rec_conf']=rec_prob #每个字符的概率
result_dict['roi_height']=roi_img.shape[0] #车牌高度
result_dict['plate_color']=""
if is_color:
result_dict['plate_color']=plate_color #车牌颜色
result_dict['color_conf']=color_conf #颜色得分
result_dict['plate_type']=class_label #单双层 0单层 1双层
return result_dict
def detect_Recognition_plate(model, orgimg, device,plate_rec_model,img_size,is_color=False):#获取车牌信息
# Load model
# img_size = opt_img_size
conf_thres = 0.3 #得分阈值
iou_thres = 0.5 #nms的iou值
dict_list=[]
# orgimg = cv2.imread(image_path) # BGR
img0 = copy.deepcopy(orgimg)
assert orgimg is not None, 'Image Not Found '
h0, w0 = orgimg.shape[:2] # orig hw
r = img_size / max(h0, w0) # resize image to img_size
if r != 1: # always resize down, only resize up if training with augmentation
interp = cv2.INTER_AREA if r < 1 else cv2.INTER_LINEAR
img0 = cv2.resize(img0, (int(w0 * r), int(h0 * r)), interpolation=interp)
imgsz = check_img_size(img_size, s=model.stride.max()) # check img_size
img = letterbox(img0, new_shape=imgsz)[0] #检测前处理,图片长宽变为32倍数,比如变为640X640
# img =process_data(img0)
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1).copy() # BGR to RGB, to 3x416x416 图片的BGR排列转为RGB,然后将图片的H,W,C排列变为C,H,W排列
# Run inference
t0 = time.time()
img = torch.from_numpy(img).to(device)
img = img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
# t1 = time_synchronized()/
pred = model(img)[0]
# t2=time_synchronized()
# print(f"infer time is {(t2-t1)*1000} ms")
# Apply NMS
pred = non_max_suppression_face(pred, conf_thres, iou_thres)
# print('img.shape: ', img.shape)
# print('orgimg.shape: ', orgimg.shape)
# Process detections
for i, det in enumerate(pred): # detections per image
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], orgimg.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
det[:, 5:13] = scale_coords_landmarks(img.shape[2:], det[:, 5:13], orgimg.shape).round()
for j in range(det.size()[0]):
xyxy = det[j, :4].view(-1).tolist()
conf = det[j, 4].cpu().numpy()
landmarks = det[j, 5:13].view(-1).tolist()
class_num = det[j, 13].cpu().numpy()
result_dict = get_plate_rec_landmark(orgimg, xyxy, conf, landmarks, class_num,device,plate_rec_model,is_color=is_color)
dict_list.append(result_dict)
return dict_list
# cv2.imwrite('result.jpg', orgimg)
def draw_result(orgimg,dict_list,is_color=False): # 车牌结果画出来
result_str =""
for result in dict_list:
rect_area = result['rect']
x,y,w,h = rect_area[0],rect_area[1],rect_area[2]-rect_area[0],rect_area[3]-rect_area[1]
padding_w = 0.05*w
padding_h = 0.11*h
rect_area[0]=max(0,int(x-padding_w))
rect_area[1]=max(0,int(y-padding_h))
rect_area[2]=min(orgimg.shape[1],int(rect_area[2]+padding_w))
rect_area[3]=min(orgimg.shape[0],int(rect_area[3]+padding_h))
height_area = result['roi_height']
landmarks=result['landmarks']
result_p = result['plate_no']
if result['plate_type']==0:#单层
result_p+=" "+result['plate_color']
else: #双层
result_p+=" "+result['plate_color']+"双层"
result_str+=result_p+" "
for i in range(4): #关键点
cv2.circle(orgimg, (int(landmarks[i][0]), int(landmarks[i][1])), 5, clors[i], -1)
cv2.rectangle(orgimg,(rect_area[0],rect_area[1]),(rect_area[2],rect_area[3]),(0,0,255),2) #画框
labelSize = cv2.getTextSize(result_p,cv2.FONT_HERSHEY_SIMPLEX,0.5,1) #获得字体的大小
if rect_area[0]+labelSize[0][0]>orgimg.shape[1]: #防止显示的文字越界
rect_area[0]=int(orgimg.shape[1]-labelSize[0][0])
orgimg=cv2.rectangle(orgimg,(rect_area[0],int(rect_area[1]-round(1.6*labelSize[0][1]))),(int(rect_area[0]+round(1.2*labelSize[0][0])),rect_area[1]+labelSize[1]),(255,255,255),cv2.FILLED)#画文字框,背景白色
if len(result)>=1:
orgimg=cv2ImgAddText(orgimg,result_p,rect_area[0],int(rect_area[1]-round(1.6*labelSize[0][1])),(0,0,0),21)
# orgimg=cv2ImgAddText(orgimg,result_p,rect_area[0]-height_area,rect_area[1]-height_area-10,(0,255,0),height_area)
print(result_str)
return orgimg
def get_second(capture):
if capture.isOpened():
rate = capture.get(5) # 帧速率
FrameNumber = capture.get(7) # 视频文件的帧数
duration = FrameNumber/rate # 帧速率/视频总帧数 是时间,除以60之后单位是分钟
return int(rate),int(FrameNumber),int(duration)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--detect_model', nargs='+', type=str, default='weights/plate_detect.pt', help='model.pt path(s)') #检测模型code>
parser.add_argument('--rec_model', type=str, default='weights/plate_rec_color.pth', help='model.pt path(s)')#车牌识别+颜色识别模型code>
parser.add_argument('--is_color',type=bool,default=True,help='plate color') #是否识别颜色code>
parser.add_argument('--image_path', type=str, default='imgs', help='source') #图片路径code>
parser.add_argument('--img_size', type=int, default=640, help='inference size (pixels)') #网络输入图片大小code>
parser.add_argument('--output', type=str, default='result', help='source') #图片结果保存的位置code>
parser.add_argument('--video', type=str, default='', help='source') #视频的路径code>
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") #使用gpu还是cpu进行识别
# device =torch.device("cpu")
opt = parser.parse_args()
print(opt)
save_path = opt.output
count=0
if not os.path.exists(save_path):
os.mkdir(save_path)
detect_model = load_model(opt.detect_model, device) #初始化检测模型
plate_rec_model=init_model(device,opt.rec_model,is_color=opt.is_color) #初始化识别模型
#算参数量
total = sum(p.numel() for p in detect_model.parameters())
total_1 = sum(p.numel() for p in plate_rec_model.parameters())
print("detect params: %.2fM,rec params: %.2fM" % (total/1e6,total_1/1e6))
# plate_color_model =init_color_model(opt.color_model,device)
time_all = 0
time_begin=time.time()
if not opt.video: #处理图片
if not os.path.isfile(opt.image_path): #目录
file_list=[]
allFilePath(opt.image_path,file_list) #将这个目录下的所有图片文件路径读取到file_list里面
for img_path in file_list: #遍历图片文件
print(count,img_path,end=" ")code>
time_b = time.time() #开始时间
img =cv_imread(img_path) #opencv 读取图片
if img is None:
continue
if img.shape[-1]==4: #图片如果是4个通道的,将其转为3个通道
img=cv2.cvtColor(img,cv2.COLOR_BGRA2BGR)
# detect_one(model,img_path,device)
dict_list=detect_Recognition_plate(detect_model, img, device,plate_rec_model,opt.img_size,is_color=opt.is_color)#检测以及识别车牌
ori_img=draw_result(img,dict_list) #将结果画在图上
img_name = os.path.basename(img_path)
save_img_path = os.path.join(save_path,img_name) #图片保存的路径
time_e=time.time()
time_gap = time_e-time_b #计算单个图片识别耗时
if count:
time_all+=time_gap
cv2.imwrite(save_img_path,ori_img) #opencv将识别的图片保存
count+=1
print(f"sumTime time is { time.time()-time_begin} s, average pic time is { time_all/(len(file_list)-1)}")
else: #单个图片
print(count,opt.image_path,end=" ")code>
img =cv_imread(opt.image_path)
if img.shape[-1]==4:
img=cv2.cvtColor(img,cv2.COLOR_BGRA2BGR)
# detect_one(model,img_path,device)
dict_list=detect_Recognition_plate(detect_model, img, device,plate_rec_model,opt.img_size,is_color=opt.is_color)
ori_img=draw_result(img,dict_list)
img_name = os.path.basename(opt.image_path)
save_img_path = os.path.join(save_path,img_name)
cv2.imwrite(save_img_path,ori_img)
else: #处理视频
video_name = opt.video
capture=cv2.VideoCapture(video_name)
fourcc = cv2.VideoWriter_fourcc(*'MP4V')
fps = capture.get(cv2.CAP_PROP_FPS) # 帧数
width, height = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)), int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 宽高
out = cv2.VideoWriter('result.mp4', fourcc, fps, (width, height)) # 写入视频
frame_count = 0
fps_all=0
rate,FrameNumber,duration=get_second(capture)
if capture.isOpened():
while True:
t1 = cv2.getTickCount()
frame_count+=1
print(f"第{ frame_count} 帧",end=" ")code>
ret,img=capture.read()
if not ret:
break
# if frame_count%rate==0:
img0 = copy.deepcopy(img)
dict_list=detect_Recognition_plate(detect_model, img, device,plate_rec_model,opt.img_size,is_color=opt.is_color)
ori_img=draw_result(img,dict_list)
t2 =cv2.getTickCount()
infer_time =(t2-t1)/cv2.getTickFrequency()
fps=1.0/infer_time
fps_all+=fps
str_fps = f'fps:{ fps:.4f}'
cv2.putText(ori_img,str_fps,(20,20),cv2.FONT_HERSHEY_SIMPLEX,1,(0,255,0),2)
# cv2.imshow("haha",ori_img)
# cv2.waitKey(1)
out.write(ori_img)
# current_time = int(frame_count/FrameNumber*duration)
# sec = current_time%60
# minute = current_time//60
# for result_ in result_list:
# plate_no = result_['plate_no']
# if not is_car_number(pattern_str,plate_no):
# continue
# print(f'车牌号:{plate_no},时间:{minute}分{sec}秒')
# time_str =f'{minute}分{sec}秒'
# writer.writerow({"车牌":plate_no,"时间":time_str})
# out.write(ori_img)
else:
print("失败")
capture.release()
out.release()
cv2.destroyAllWindows()
print(f"all frame is { frame_count},average fps is { fps_all/frame_count} fps")
3.8 关键的分析
库和依赖项:
使用了 cv2(OpenCV)进行图像处理。使用 torch 进行深度学习模型的加载和推理。包含自定义的工具和模块,如 models.experimental, utils.datasets, utils.general 等。
功能模块:
车牌检测:通过 attempt_load 函数加载预训练模型,然后使用 non_max_suppression_face 进行非最大值抑制以过滤检测结果。车牌识别:通过 get_plate_result 函数对检测到的车牌区域进行字符识别。图像处理:包括透视变换(four_point_transform 函数)和文字绘制(cv2ImgAddText 函数)。
数据处理:
使用 letterbox 函数调整图像大小以适应模型输入。使用 scale_coords 函数将检测结果映射回原始图像尺寸。
3.9 笔者的一些想法
批处理处理
原代码:
没有批处理逻辑,一次只能处理一张图像。
def process_image(image_path, model, recognizer, device):
image = cv_imread(image_path)
plates = detect_plate(image, model, device)
results = []
for plate in plates:
plate_image = extract_plate_image(image, plate)
result = recognize_plate(plate_image, recognizer)
results.append(result)
return results
改成:
添加了批处理逻辑,提升了处理效率。
def batch_process_images(image_paths, model, recognizer, device, batch_size=8):
results = []
for i in range(0, len(image_paths), batch_size):
batch_paths = image_paths[i:i + batch_size]
batch_images = [cv2.imread(str(path)) for path in batch_paths]
batch_detections = [detect_plate(img, model, device) for img in batch_images]
for img, detections in zip(batch_images, batch_detections):
for bbox in detections:
plate_image = extract_plate_image(img, bbox[0])
result = recognize_plate(plate_image, recognizer)
results.append(result)
return results
效率提升:优化后的代码使用批处理方法,一次处理多张图像,减少了重复调用函数的开销,提高了整体处理速度。
代码简洁:通过批处理,减少了重复代码,使逻辑更加简洁明了。
配置管理
原代码
所有参数都在代码中硬编码,缺乏灵活性。
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--image_folder', type=str, required=True, help='Path to the folder containing images')code>
parser.add_argument('--weights', type=str, default='weights/best.pt', help='Path to weights file')code>
parser.add_argument('--recognizer_weights', type=str, default='weights/recognizer.pth', help='Path to recognizer weights')code>
parser.add_argument('--device', default='', help='Device to run on (e.g. 0 or 0,1,2,3 or cpu)')code>
args = parser.parse_args()
改成
def load_config(config_path):
with open(config_path, 'r') as file:
config = yaml.safe_load(file)
return config
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--config_path', type=str, default='config.yaml', help='Path to the config file')code>
args = parser.parse_args()
config = load_config(args.config_path)
device = select_device(config['device'])
model = attempt_load(config['weights'], map_location=device)
recognizer = init_model(config['recognizer_weights'])
灵活性:优化后的代码通过配置文件管理参数,便于修改和扩展,适应不同的应用场景。
可维护性:参数集中管理,使代码更加整洁,便于维护和升级。
四、使用香橙派 AIpro 开发板遇到的问题和总结
4.1 遇到的问题
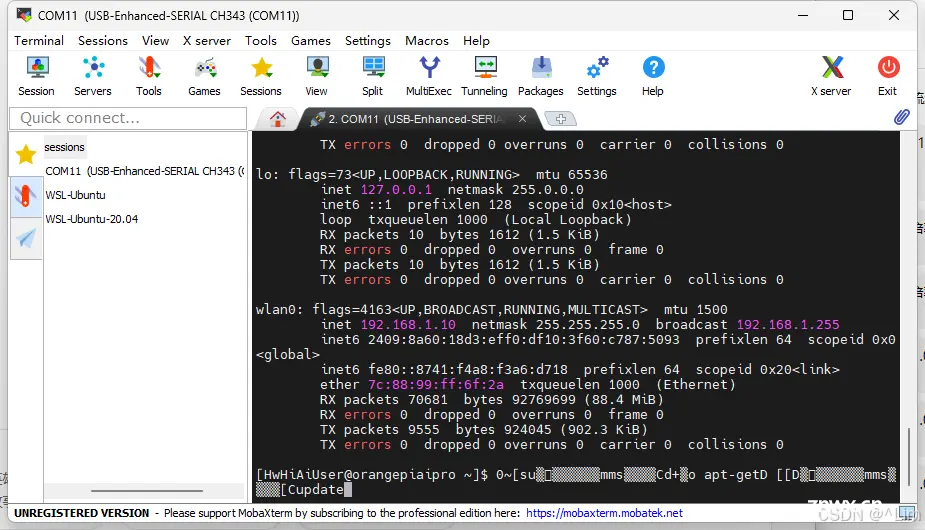
在使用串口调试香橙派 AIpro 开发板时,遇到了输入命令时出现 文字乱跳、乱码 的问题。这导致第一次开机时无法顺利配置网络,从而不能使用 ssh。具体问题如下:
使用 openEuler 系统时:
串口输入直接卡死,无法输入命令。即使重新复位也无效,只有断电重新开机才能恢复。 更换 Ubuntu 系统后:
串口输入虽然没有再卡死,但文字乱跳的问题依然存在,影响正常输入。
这种现象严重影响了系统的初始配置和使用体验,需要寻找解决方案来确保串口调试的稳定性和可靠性。
4.2 运行车牌号识别项目的感受
香橙派 AIpro 开发板在开机时风扇声音较大,但启动后声音会立即减小。在运行模型期间,风扇声音保持稳定,没有 明显变化。我已经连续工作了 十几个小时 ,期间风扇的声音一直很小。同时,散热器的温度不高,表明该产品本身的散热性能相当出色。
4.3 总结
香橙派 AIpro 开发板有着其 <code>强大的性能 和 丰富的接口 ,开发者进行 AI 和 物联网项目 的时候是一个很好的选择。虽然在初始配置和兼容性方面存在一些挑战,但通过适当的调整和配置,这些问题都可以得到解决。并不会影响正常使用。
总体而言,香橙派 AIpro 开发板为边缘计算和智能应用提供了一个高效 、灵活 的平台,具有广泛的应用前景和发展潜力,作为一款国产化开发板,它在 本地支持 、适应本土需求。具有独特优势,与树莓派相比,香橙派 AIpro 在 性能 和 扩展性上 还有 价格上更具优势,特别适合 高级开发者 和 专业项目 。
值得一提的是,香橙派 AIpro 的颜值和做工优于市面上许多其他产品,使其在外观和质量上也具备很强的竞争力
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。