香橙派Orange AI Pro 评测体验
一WILLPOWER一 2024-07-27 16:31:03 阅读 100
前言
很高兴,收到官方的评测邀请,去体验一下目前香橙派和华为精心打造的OrangePi AIPro开发板。
背景
当2022年底ChatGPT发布后,人工智能的概念便迅速在各个行业中火爆,
当时我还在研三期间,在体验Chatgpt后,不由得感叹原来AI可以这么有用,那段时间AI绘图、AI视频、AI写代码等等功能更是让我觉得人工智能时代才是未来。
而AI呢,它具有三要素:算法、数据以及算力,于算法而言,其实学术界是早就开始研究深度学习以及机器学习算法等,因此有许多成熟的算法可以使用,而数据呢,说白了就是传感器采集和存储,现如今国产存储的发展使得存储的价格很低,因此可以以较低的成本来存储更多的数据量,便于更好的训练AI模型,最后就是算力了,这决定了训练以及处理算法的速度,而目前由于显卡GPU的迅猛发展,算力方面也得到了很好的保障。就这样三要素凑齐了,引得了很多大佬纷纷下水开始搞AI,开始布局。
那么,在有好算力的显卡的情况下,为什么还要用嵌入式AI设备(OrangePi AIPro等设备)?
是这样的,一些传统的嵌入式设备要用到AI模型,一般就只有所谓前端的采集设备将数据进行采集后通过网络上传到服务器中进行处理后,再进行传回。这样一方面流程长,响应慢,而且还可能存在着信息泄露的网络安全问题。于是大家就想到了,能不能将采集和处理都放在本地终端处理?因此,嵌入式AI设备的概念便产生了,将具有算力设备的cpu或者npu放在设备上进行在线的检测,提升了检测的速度和安全性。
并且现在还提出了在线可持续训练的概念,意思就是采集数据、训练模型以及检测都放在嵌入式设备上面,这样模型检测的准确性会随着用户的使用逐渐提高。因此嵌入式AI设备的使用也是人工智能的重要发展方向。
OrangePi AIPro作为目前嵌入式AI设备的一员,拥有着以下的特点:
硬件方面:

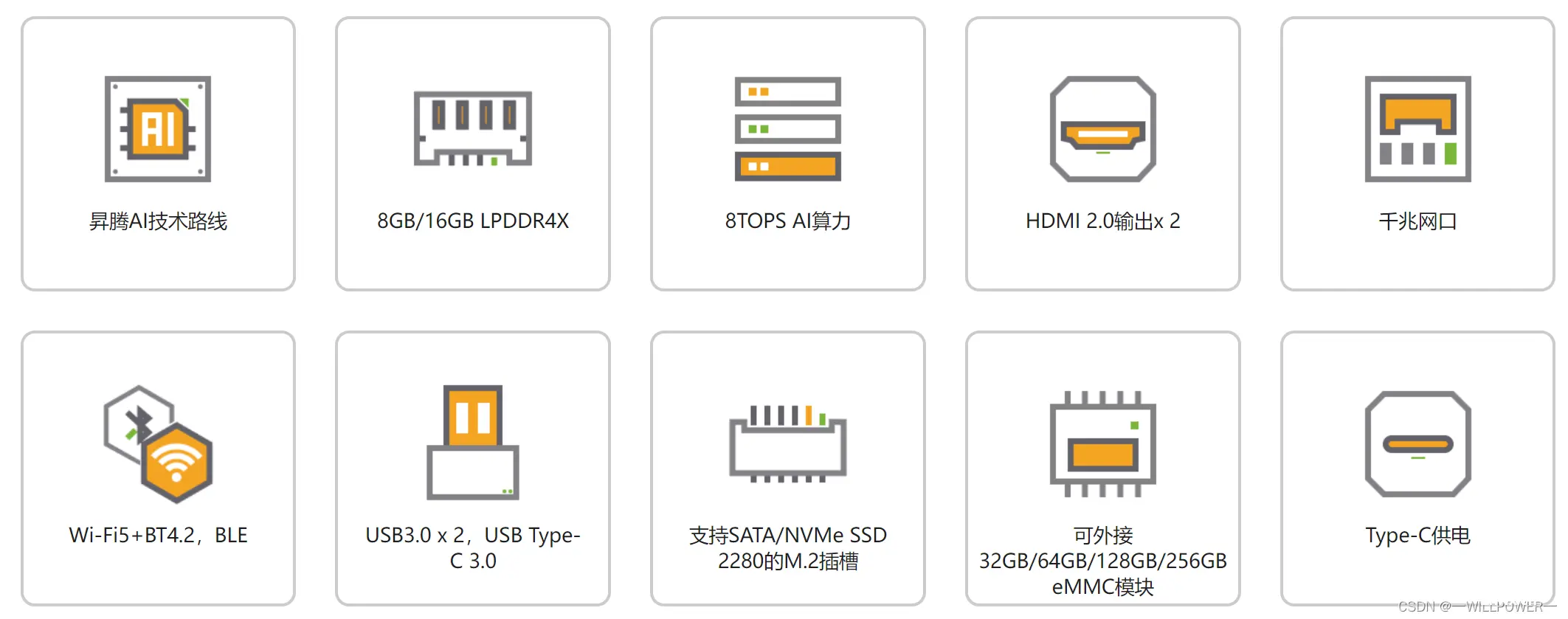
软件方面:
得益于昇腾AI的发展,让不熟悉嵌入式设备的AI开发人员能够快速将设计的模型在嵌入式开发板上进行部署。
那么有的同学就会问了?
昇腾AI到底有什么用?而嵌入式设备的AI开发和普通的AI开发有什么不同呢?
是这样的,以Orange AI Pro为例,其搭载了昇腾 AI 处理器,可提供 8TOPS INT8 的计算能力,但是这个计算性能是必须要特殊处理才可以使用到的,那么对于传统设备的AI开发者需要怎么做呢?昇腾AI给出了较好的答案,它提供了针对AI场景推出的异构计算架构CANN(Compute Architecture for Neural Networks),其对上支持多种AI框架,对下服务AI处理器与编程,发挥承上启下的关键作用。传统开发人员只需要在常用AI框架下进行正常开发后,利用CANN提供的昇腾张量编译器(Ascend Tensor Compiler,简称ATC)将其转换为昇腾AI处理器能识别的OM模型。然后使用AscendCL(Ascend Computing Language,昇腾计算语言),来调用模型进行推理等。不只有这些,昇腾AI栈还提供了AIPP(Artificial Intelligence Pre-Processing)以及DVPP(Digital Vision Pre-Processing)等工具用于进行加速数据预处理,让整个流程变得迅速而便捷。
说了这么多,下面来体验一下吧。
开发板的全貌


可以看到板子的资源是很丰富的,带有常用的如摄像头、屏幕以及通用IO部分,用于采集数据,并且带有AI处理器用于AI开发,这也注定了,它可以实现图像、视频等多种数据分析与推理计算,可广泛用于教育、机器人、无人机等场景。
体验案例
OrangeAI Pro的特色是嵌入式AI方面,因此本次体验着重于使用它所搭载的AI资源。
这里,以昇腾官方给的快速入门案例为例子进行体验。
环境需求
环境:Ubuntu22.04
安装第三方依赖:
<code>sudo apt-get install -y gcc g++ make cmake zlib1g zlib1g-dev openssl libsqlite3-dev libssl-dev libffi-dev unzip pciutils net-tools libblas-dev gfortran libblas3
安装Python相关依赖:
pip3 install attrs numpy decorator sympy cffi pyyaml pathlib2 psutil protobuf scipy requests absl-py wheel typing_extensions
为了用到昇腾提供的算力,我们首先要部署昇腾AI软件栈,来进行开发。
为了使整个开发过程快速,我选择了再PC机上进行开发环境的部署,而运行环境还是再Orange AI Pro开发板上,尽管开发环境也能部署在其中,但是某些编译和模型转换放在上面是没有必要的(使用交叉编译即可)。
CANN开发运行环境搭建流程如下图所示:
图片来源

在资源获取网页去获取CANN开发包,这里我们选择CPU架构为X86_64

安装CANN开发套件包:
<code>./Ascend-cann-toolkit_8.0.RC2.alpha002_linux-x86_64.run --install
然后激活CANN的开发环境:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
(你可以将其写在.bashrc中)
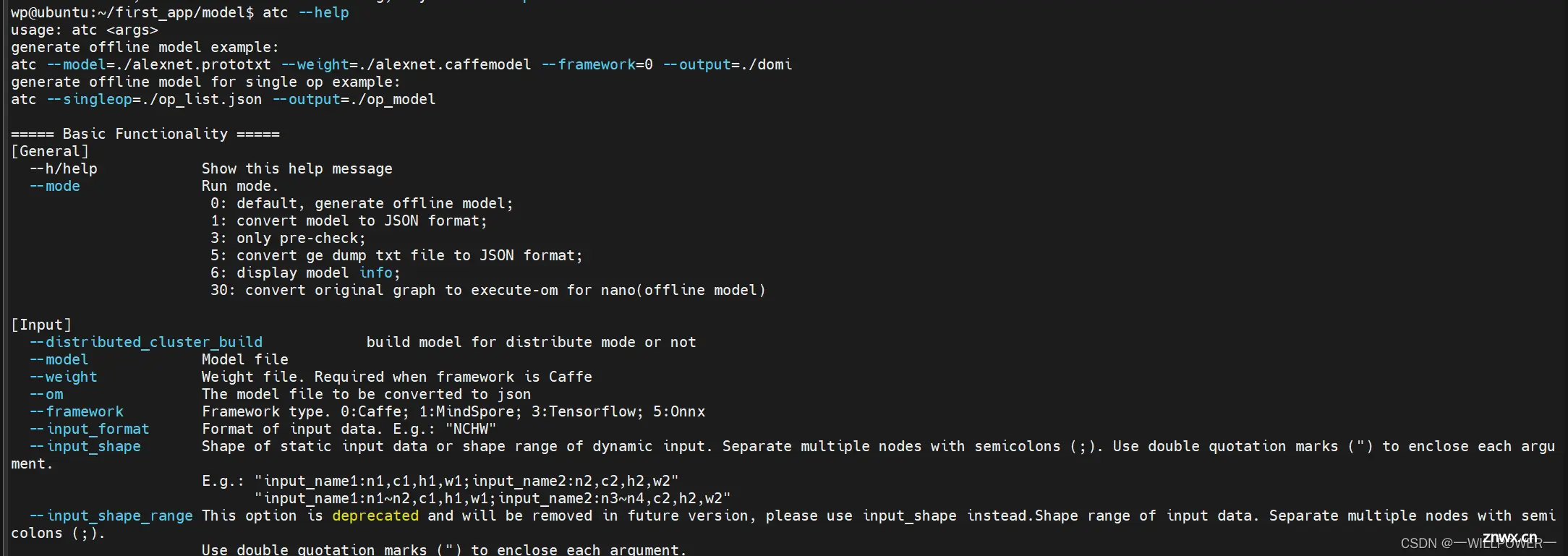
安装完成后,可以使用命令
atc --help查看命令是否可用,可用说明环境就ok了
图片分类应用
模型转换
为了进行快速验证,这里使用已经训练好的ResNet-50模型进行转换。
首先下载已经训练好的模型:
<code>wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/resnet50/resnet50.onnx
这一步就是传统AI开发的模型训练后的结果,假想我们是一个AI开发人员,那么下一步我们就是要使用AI框架提供的函数去调用模型然后推理。同理,为了能够在开发板上使用计算资源,我们需要转换模型为开发板上AI资源能够调用的模型进行推理,这里就需要使用ATC工具进行模型转换(对于开源框架的模型,不能直接在昇腾AI处理器上进行推理,需要使用ATC(Ascend Tensor Compiler)工具将开源框架的网络模型转换为适配昇腾AI处理器的离线模型(*.om文件)):
atc --model=resnet50.onnx --framework=5 --output=resnet50 --input_shape="actual_input_1:1,3,224,224" --soc_version=Ascend310B4code>
这里的参数含义可以从ATC工具使用指南找到。
转换完成后,会生成resnet50.om文件,可以使用scp工具上传到开发板中,然后就是代码部分了。
加载模型进行推理
为了能够加载模型进行推理,就需要使用AscendCL来进行开发,它真的是太方便了,提供了AscendCL C以及AscendCL Python两种方式进行开发,对于平常使用Python进行AI开发的人员实在太友好了。因此这里我也是选择使用Python进行开发。其中代码如下:
import os
import acl
import numpy as np
from PIL import Image
ACL_MEM_MALLOC_HUGE_FIRST = 0
ACL_MEMCPY_HOST_TO_DEVICE = 1
ACL_MEMCPY_DEVICE_TO_HOST = 2
class net:
def __init__(self, model_path):
# 初始化函数
self.device_id = 0
# step1: 初始化
ret = acl.init()
# 指定运算的Device
ret = acl.rt.set_device(self.device_id)
# step2: 加载模型,本示例为ResNet-50模型
# 加载离线模型文件,返回标识模型的ID
self.model_id, ret = acl.mdl.load_from_file(model_path)
# 创建空白模型描述信息,获取模型描述信息的指针地址
self.model_desc = acl.mdl.create_desc()
# 通过模型的ID,将模型的描述信息填充到model_desc
ret = acl.mdl.get_desc(self.model_desc, self.model_id)
# step3:创建输入输出数据集
# 创建输入数据集
self.input_dataset, self.input_data = self.prepare_dataset('input')
# 创建输出数据集
self.output_dataset, self.output_data = self.prepare_dataset('output')
def prepare_dataset(self, io_type):
# 准备数据集
if io_type == "input":
# 获得模型输入的个数
io_num = acl.mdl.get_num_inputs(self.model_desc)
acl_mdl_get_size_by_index = acl.mdl.get_input_size_by_index
else:
# 获得模型输出的个数
io_num = acl.mdl.get_num_outputs(self.model_desc)
acl_mdl_get_size_by_index = acl.mdl.get_output_size_by_index
# 创建aclmdlDataset类型的数据,描述模型推理的输入。
dataset = acl.mdl.create_dataset()
datas = []
for i in range(io_num):
# 获取所需的buffer内存大小
buffer_size = acl_mdl_get_size_by_index(self.model_desc, i)
# 申请buffer内存
buffer, ret = acl.rt.malloc(buffer_size, ACL_MEM_MALLOC_HUGE_FIRST)
# 从内存创建buffer数据
data_buffer = acl.create_data_buffer(buffer, buffer_size)
# 将buffer数据添加到数据集
_, ret = acl.mdl.add_dataset_buffer(dataset, data_buffer)
datas.append({ "buffer": buffer, "data": data_buffer, "size": buffer_size})
return dataset, datas
def forward(self, inputs):
# 执行推理任务
# 遍历所有输入,拷贝到对应的buffer内存中
input_num = len(inputs)
for i in range(input_num):
bytes_data = inputs[i].tobytes()
bytes_ptr = acl.util.bytes_to_ptr(bytes_data)
# 将图片数据从Host传输到Device。
ret = acl.rt.memcpy(self.input_data[i]["buffer"], # 目标地址 device
self.input_data[i]["size"], # 目标地址大小
bytes_ptr, # 源地址 host
len(bytes_data), # 源地址大小
ACL_MEMCPY_HOST_TO_DEVICE) # 模式:从host到device
# 执行模型推理。
ret = acl.mdl.execute(self.model_id, self.input_dataset, self.output_dataset)
# 处理模型推理的输出数据,输出top5置信度的类别编号。
inference_result = []
for i, item in enumerate(self.output_data):
buffer_host, ret = acl.rt.malloc_host(self.output_data[i]["size"])
# 将推理输出数据从Device传输到Host。
ret = acl.rt.memcpy(buffer_host, # 目标地址 host
self.output_data[i]["size"], # 目标地址大小
self.output_data[i]["buffer"], # 源地址 device
self.output_data[i]["size"], # 源地址大小
ACL_MEMCPY_DEVICE_TO_HOST) # 模式:从device到host
# 从内存地址获取bytes对象
bytes_out = acl.util.ptr_to_bytes(buffer_host, self.output_data[i]["size"])
# 按照float32格式将数据转为numpy数组
data = np.frombuffer(bytes_out, dtype=np.float32)
inference_result.append(data)
vals = np.array(inference_result).flatten()
# 对结果进行softmax转换
vals = np.exp(vals)
vals = vals / np.sum(vals)
return vals
def __del__(self):
# 析构函数 按照初始化资源的相反顺序释放资源。
# 销毁输入输出数据集
for dataset in [self.input_data, self.output_data]:
while dataset:
item = dataset.pop()
ret = acl.destroy_data_buffer(item["data"]) # 销毁buffer数据
ret = acl.rt.free(item["buffer"]) # 释放buffer内存
ret = acl.mdl.destroy_dataset(self.input_dataset) # 销毁输入数据集
ret = acl.mdl.destroy_dataset(self.output_dataset) # 销毁输出数据集
# 销毁模型描述
ret = acl.mdl.destroy_desc(self.model_desc)
# 卸载模型
ret = acl.mdl.unload(self.model_id)
# 释放device
ret = acl.rt.reset_device(self.device_id)
# acl去初始化
ret = acl.finalize()
def transfer_pic(input_path):
# 图像预处理
input_path = os.path.abspath(input_path)
with Image.open(input_path) as image_file:
# 缩放为224*224
img = image_file.resize((224, 224))
# 转换为float32类型ndarray
img = np.array(img).astype(np.float32)
# 根据imageNet图片的均值和方差对图片像素进行归一化
img -= [123.675, 116.28, 103.53]
img /= [58.395, 57.12, 57.375]
# RGB通道交换顺序为BGR
img = img[:, :, ::-1]
# resnet50为色彩通道在前
img = img.transpose((2, 0, 1))
# 返回并添加batch通道
return np.array([img])
def print_top_5(data):
top_5 = data.argsort()[::-1][:5]
print("======== top5 inference results: =============")
for j in top_5:
print("[%d]: %f" % (j, data[j]))
if __name__ == "__main__":
resnet50 = net('./model/resnet50.om')
image_paths = ["./data/dog1_1024_683.jpg", "./data/dog2_1024_683.jpg"]
for path in image_paths:
# 图像预处理,此处仅供参考,用户按照自己需求进行预处理
image = transfer_pic(path)
# 将数据按照每个输入的顺序构造list传入,当前示例的ResNet-50模型只有一个输入
result = resnet50.forward([image])
# 输出top_5
print_top_5(result)
del resnet50
最后使用
python3 first_app.py运行应用程序
输出如下:
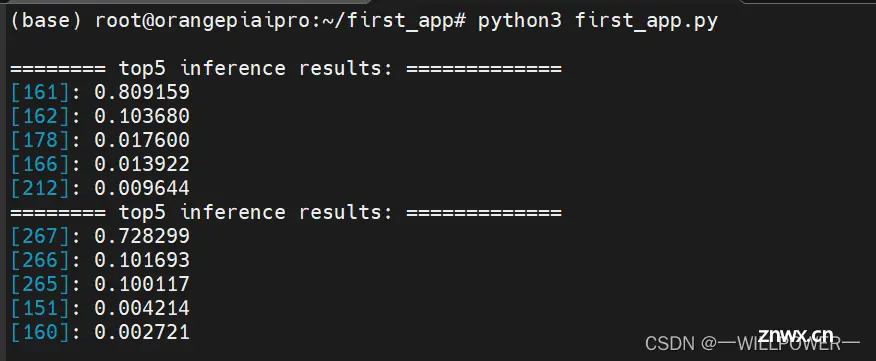
这里前面表示标签,后面表示置信度:
其中161和267代表含义如下
“161”: basset
“267”: standard_poodle
图一为:

图二为:

可以看到推理结果是正确的。
一些预置的 AI 应用样例体验
通过ssh连上OrangeAIPro后
<code>cd /home/HwHiAiUser/samples/notebooks
然后使用 start_notebook.sh 脚本启动 Jupyter Lab
./start_notebook.sh 192.168.1.194
其中192.168.1.194为其局域网ip
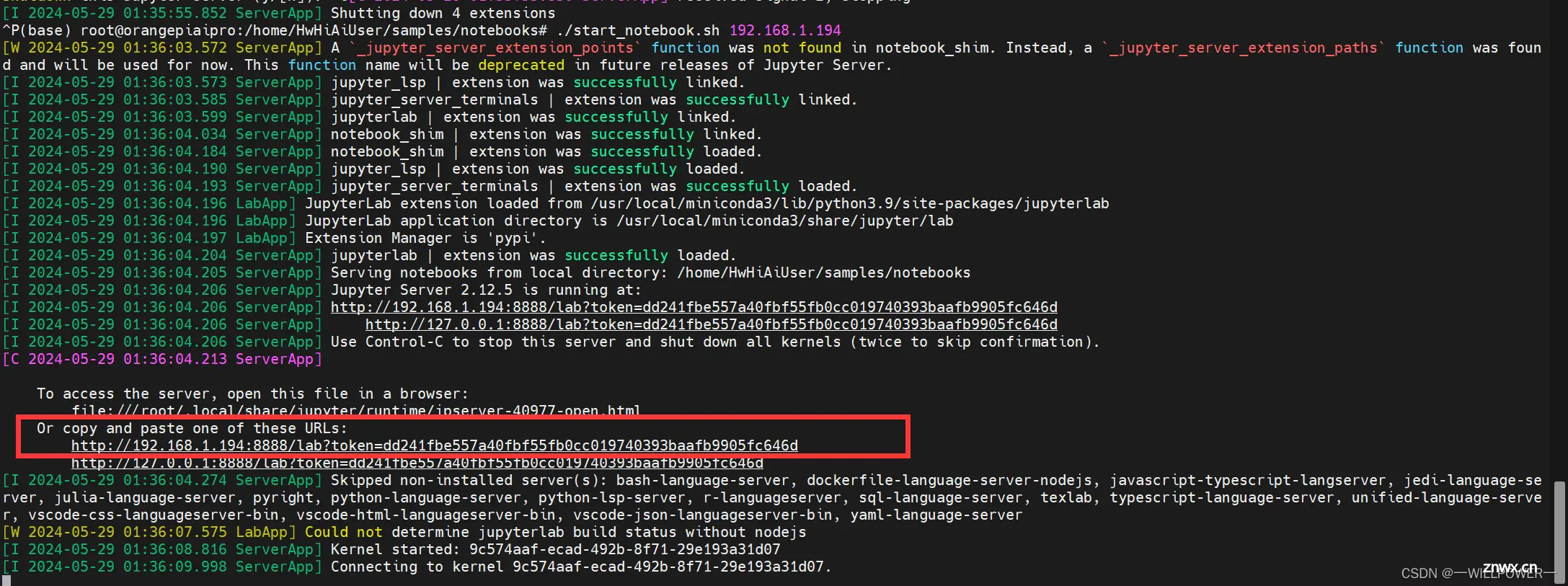
然后访问一下ip进入jupyter界面。
可以看到官方提供了多达10个例子来展示。这里以yolov5这个例子为例,执行后效果如下:
( YOLOv5是一种单阶段目标检测算法,在这个样例中,选取了YOLOv5s,它是YOLOv5系列中较为轻量的网络,适合在边缘设备部署,进行实时目标检测。)
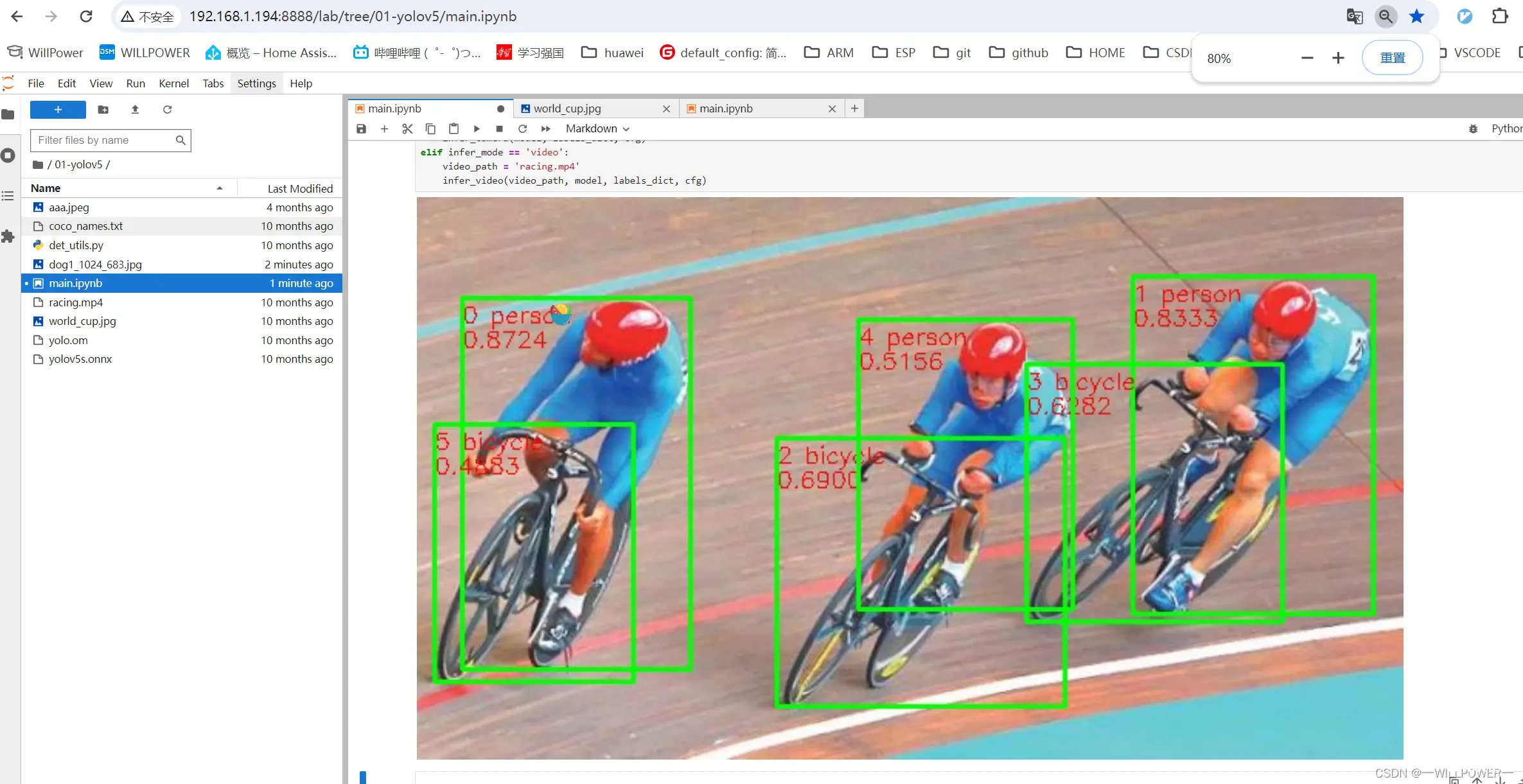
那么实时检测的效果如下:
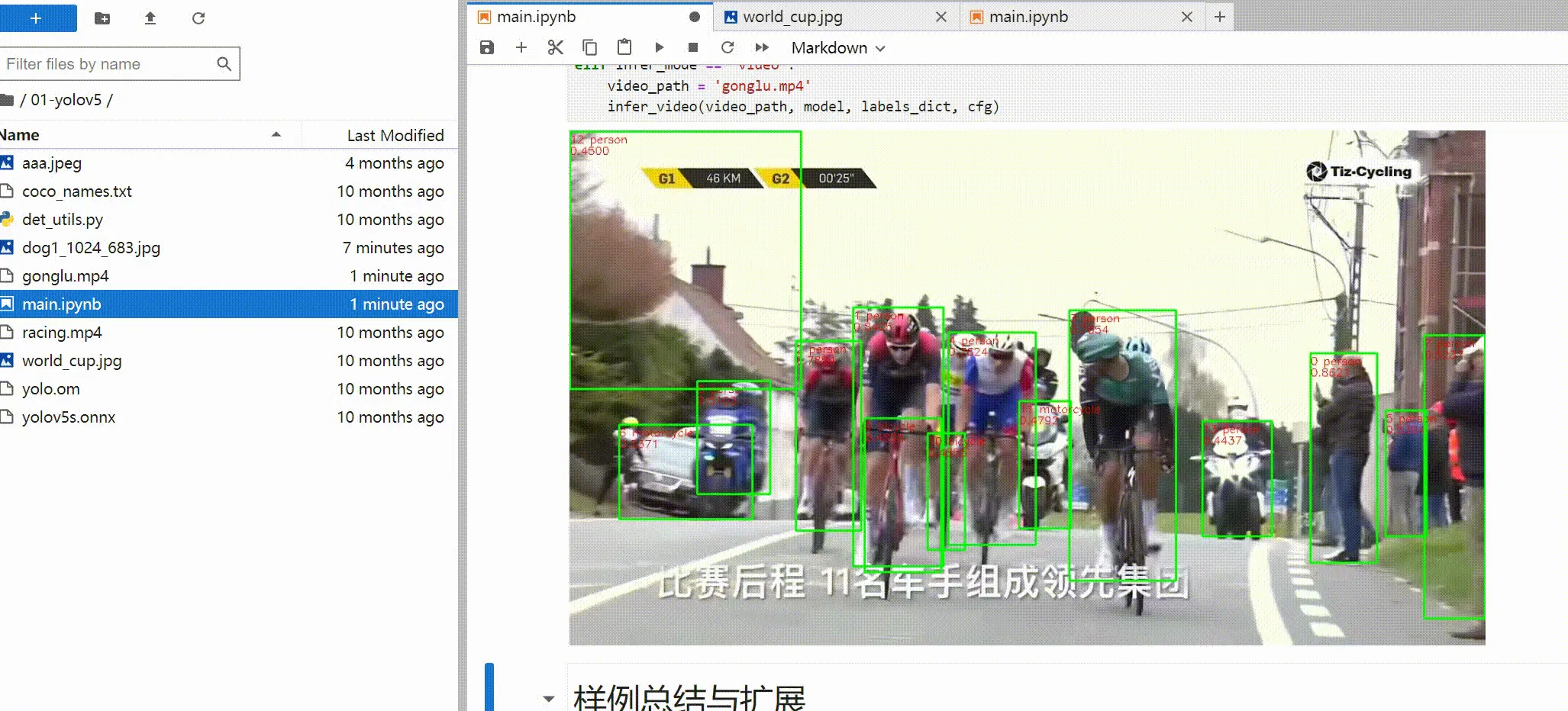
总结
本次拿到Orange AI Pro体验感还是很不错的,得益于香橙派以及华为的合作,让嵌入式AI的开发变得如此轻松,想必以后会发展的很好。
对了,我觉得将这个板子作为智能家居的中控是个非常不错的选择,低功耗,带算力,本身的接口也较多易拓展,真的是一个智能家居中控的不二之选(完全可以将智能家居采集的数据在终端进行收集,然后训练自己的模型,甚至在线学习,让你的智能家居控制变得更加精准,识别也更为定制化)。也许这是一个非常不错的发展方向,以后有时间可以研究研究。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。