【深度学习:大模型微调】如何微调SAM
jcfszxc 2024-06-11 14:01:03 阅读 90
【深度学习:大模型微调】如何微调SAM
什么是 Segment Anything 模型 (SAM)?什么是模型微调?为什么要微调模型?如何微调分段任何模型[使用代码]背景与架构创建自定义数据集输入数据预处理训练设置训练循环保存检查点并从中启动模型 针对下游应用程序的微调结论
随着 Meta 上周发布 Segment Anything Model (SAM),计算机视觉正在经历 ChatGPT 时刻。SAM 训练了超过 110 亿个分割掩码,是预测性 AI 用例的基础模型,而不是生成式 AI。虽然它在分割各种图像模态和问题空间的能力方面表现出了令人难以置信的灵活性,但它在没有“微调”功能的情况下发布。
本教程将概述使用掩码解码器微调 SAM 的一些关键步骤,特别是描述 SAM 中的哪些函数用于预处理/后处理数据,以便其处于良好的状态以进行微调。
什么是 Segment Anything 模型 (SAM)?
Segment Anything 模型 (SAM) 是由 Meta AI 开发的细分模型。它被认为是计算机视觉的第一个基础模型。SAM在包含数百万张图像和数十亿个掩码的庞大数据语料库上进行了训练,使其非常强大。顾名思义,SAM 能够为各种图像生成准确的分割掩码。SAM 的设计允许它考虑人类提示,使其在 Human In The Loop 注释中特别强大。这些提示可以是多模式的:它们可以是要分割的区域上的点、要分割的对象周围的边界框,也可以是有关应分割的内容的文本提示。
该模型分为 3 个组件:图像编码器、提示编码器和掩码解码器。
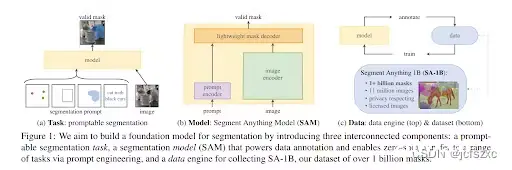
图像编码器为被分割的图像生成嵌入,而提示编码器为提示生成嵌入。图像编码器是模型中一个特别大的组件。这与轻量级掩码解码器形成鲜明对比,后者根据嵌入预测分割掩码。Meta AI 已将 Segment Anything 10 亿掩码 (SA-1B) 数据集上训练的模型的权重和偏差作为模型检查点。
什么是模型微调?
公开可用的先进模型具有自定义架构,通常提供预训练的模型权重。如果这些架构没有权重,那么用户需要从头开始训练模型,他们需要使用海量数据集来获得最先进的性能。
模型微调是采用预训练模型(架构+权重)并向其显示特定用例数据的过程。这通常是模型以前从未见过的数据,或者在其原始训练数据集中代表性不足的数据。
微调模型和从头开始之间的区别在于权重和偏差的起始值。如果我们从头开始训练,这些将根据某种策略随机初始化。在这样的起始配置中,模型对手头的任务“一无所知”并且表现不佳。通过使用预先存在的权重和偏差作为起点,我们可以“微调”权重和偏差,以便我们的模型在自定义数据集上更好地工作。例如,学习到识别猫的信息(边缘检测、计算爪子)对于识别狗很有用。
为什么要微调模型?
微调模型的目的是为了在预训练模型从未见过的数据上获得更高的性能。例如,在从手机摄像头收集的广泛数据集上训练的图像分割模型将主要从水平角度看到图像。
如果我们尝试将此模型用于从垂直角度拍摄的卫星图像,它的性能可能不会那么好。如果我们尝试分割屋顶,该模型可能不会产生最佳结果。预训练很有用,因为模型通常已经学会了如何分割对象,因此我们希望利用这个起点来构建一个可以准确分割屋顶的模型。此外,我们的自定义数据集可能不会有数百万个示例,因此我们希望进行微调,而不是从头开始训练模型。
微调是可取的,这样我们就可以在特定用例上获得更好的性能,而不必承担从头开始训练模型的计算成本。
如何微调分段任何模型[使用代码]
背景与架构
我们在简介部分概述了 SAM 架构。图像编码器具有复杂的架构和许多参数。为了微调模型,我们有必要关注掩模解码器,因为它是轻量级的,因此微调起来更容易、更快、内存效率更高。
为了微调 SAM,我们需要提取其架构的底层部分(图像和提示编码器、掩码解码器)。我们不能使用 SamPredictor.predict(链接)有两个原因:
我们只想微调掩码解码器该函数调用 SamPredictor.predict_torch,它具有 @torch.no_grad() 装饰器(链接),这会阻止我们计算梯度
因此,我们需要检查 SamPredictor.predict 函数并调用适当的函数,并在我们想要微调的部分(掩码解码器)上启用梯度计算。这样做也是了解 SAM 工作原理的好方法。
创建自定义数据集
我们需要三件事来微调我们的模型:
用于绘制分割的图像分割地面真值掩模提示输入模型
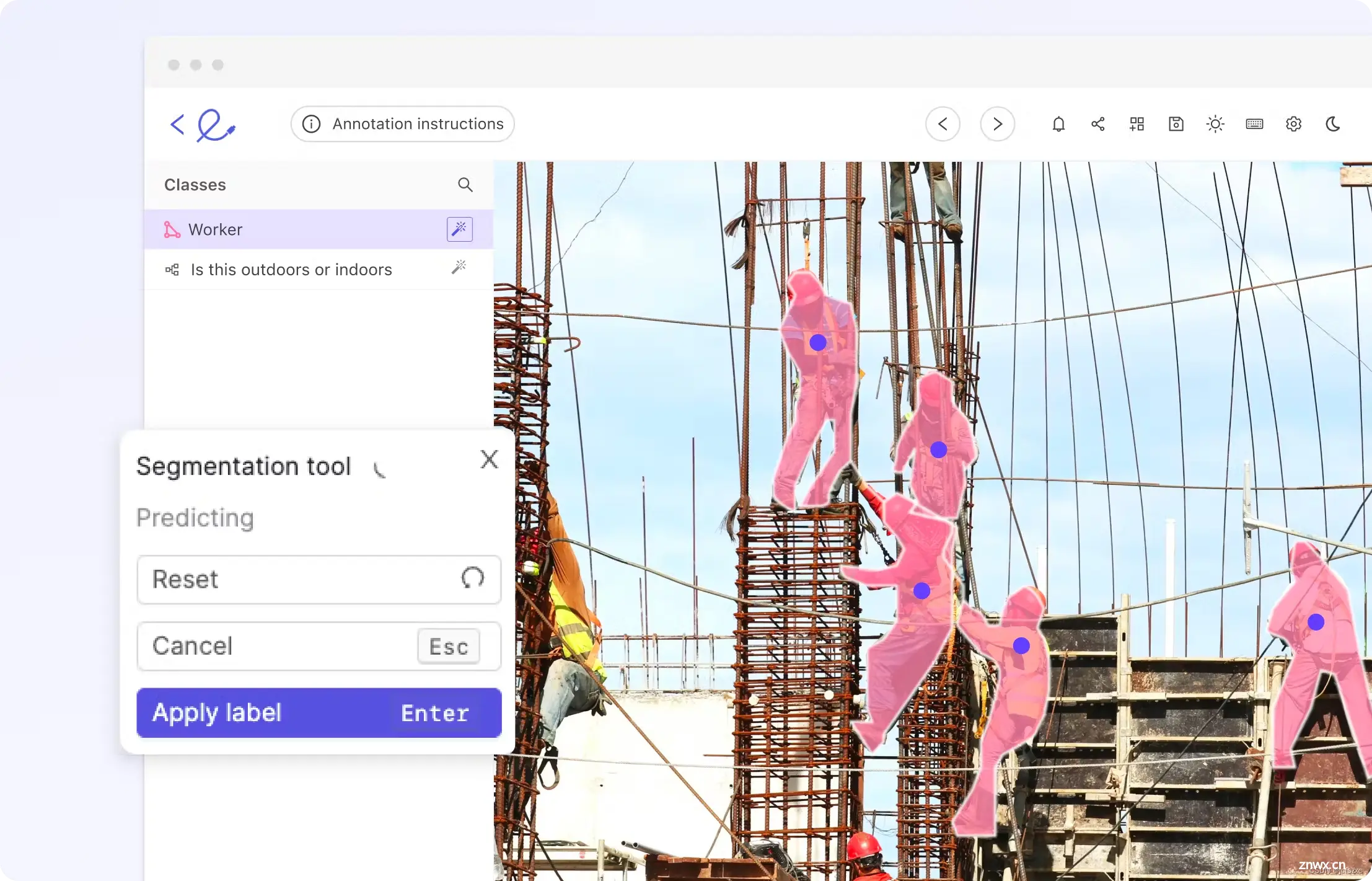
我们选择印章验证数据集(链接),因为它包含 SAM 在训练中可能未见过的数据(即文档上的印章)。我们可以通过使用预先训练的权重进行推理来验证它在此数据集上的表现是否良好,但并不完美。地面真实掩模也非常精确,这将使我们能够计算准确的损失。最后,该数据集包含分割掩码周围的边界框,我们可以将其用作 SAM 的提示。示例图像如下所示。这些边界框与人工注释者在生成分段时所经历的工作流程非常吻合。

输入数据预处理
我们需要预处理从 numpy 数组到 pytorch 张量的扫描。为此,我们可以跟踪 SamPredictor.set_image(链接)和 SamPredictor.set_torch_image(链接)内部发生的情况(对图像进行预处理)。首先,我们可以使用 utils.transform.ResizeLongestSide 来调整图像大小,因为这是预测器内部使用的转换器(链接)。然后我们可以将图像转换为pytorch张量并使用SAM预处理方法(链接)来完成预处理。
训练设置
我们下载 vit_b 模型的模型检查点,并将其加载进去:
sam_model = sam_model_registry['vit_b'](checkpoint='sam_vit_b_01ec64.pth')
我们可以使用默认值设置 Adam 优化器,并指定要调整的参数是掩码解码器的参数:
optimizer = torch.optim.Adam(sam_model.mask_decoder.parameters())
同时,我们可以设置我们的损失函数,例如均方误差
loss_fn = torch.nn.MSELoss()
训练循环
在主训练循环中,我们将迭代数据项,生成掩模,并将它们与地面实况掩模进行比较,以便我们可以根据损失函数优化模型参数。
在此示例中,我们使用 GPU 进行训练,因为它比使用 CPU 快得多。在适当的张量上使用 .to(device) 非常重要,以确保我们不会在 CPU 上使用某些张量而在 GPU 上使用其他张量。
我们希望通过将编码器包装在 torch.no_grad() 上下文管理器中来嵌入图像,否则我们将遇到内存问题,并且我们不希望微调图像编码器。
with torch.no_grad():image_embedding = sam_model.image_encoder(input_image)
我们还可以在 no_grad 上下文管理器中生成提示嵌入。我们使用边界框坐标,转换为 pytorch 张量。
with torch.no_grad(): sparse_embeddings, dense_embeddings = sam_model.prompt_encoder( points=None, boxes=box_torch, masks=None, )
最后,我们可以生成蒙版。请注意,这里我们处于单掩码生成模式(与通常输出的 3 个掩码相反)。
low_res_masks, iou_predictions = sam_model.mask_decoder( image_embeddings=image_embedding, image_pe=sam_model.prompt_encoder.get_dense_pe(), sparse_prompt_embeddings=sparse_embeddings, dense_prompt_embeddings=dense_embeddings, multimask_output=False,)
这里的最后一步是将蒙版放大回原始图像大小,因为它们的分辨率较低。我们可以使用 Sam.postprocess_masks 来实现这一点。我们还希望从预测的掩码生成二进制掩码,以便我们可以将它们与我们的基本事实进行比较。为了不破坏反向传播,使用火炬泛函非常重要。
upscaled_masks = sam_model.postprocess_masks(low_res_masks, input_size, original_image_size).to(device)from torch.nn.functional import threshold, normalizebinary_mask = normalize(threshold(upscaled_masks, 0.0, 0)).to(device)
最后,我们可以计算损失并运行优化步骤:
loss = loss_fn(binary_mask, gt_binary_mask)optimizer.zero_grad()loss.backward()optimizer.step()
通过在多个 epoch 和批次中重复此操作,我们可以微调 SAM 解码器。
保存检查点并从中启动模型
一旦我们完成训练并对性能提升感到满意,我们可以使用以下方法保存调整模型的状态字典:
torch.save(model.state_dict(), PATH)
然后,当我们想要对与我们用于微调模型的数据类似的数据进行推理时,我们可以加载此状态字典。
针对下游应用程序的微调
虽然 SAM 目前不提供开箱即用的微调功能,但我们正在构建与 Encord 平台集成的自定义微调器。如本文所示,我们对解码器进行微调以实现这一目标。这可以作为 Web 应用程序中开箱即用的一键式过程使用,其中超参数是自动设置的。
Original vanilla SAM mask:

由模型的微调版本生成的掩模:

我们可以看到这个面罩比原来的面罩更紧。这是对印章验证数据集中的一小部分图像进行微调,然后在以前未见过的示例上运行调整后的模型的结果。通过进一步的训练和更多的例子,我们可以获得更好的结果。
结论
就这样,伙计们!
您现在已经学会了如何微调分段任意模型 (SAM)。如果您希望对 SAM 进行开箱即用的微调,您可能还会有兴趣了解我们最近在 Encord 中发布了分段任意模型,使您无需编写任何代码即可微调模型。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。