PandasAI的应用与实战解析(二):PandasAI使用流程与功能介绍
TracyCoder123 2024-07-09 17:01:08 阅读 72
文章目录
1.使用PandasAI进行开发的流程2.配置文件解析3.支持的数据库类型4.支持的LLMs5.其他
PandasAI这个工具最突出的优点就是通过结合了Pandas和生成式LLMs,极大地为开发人员降低了工作量。
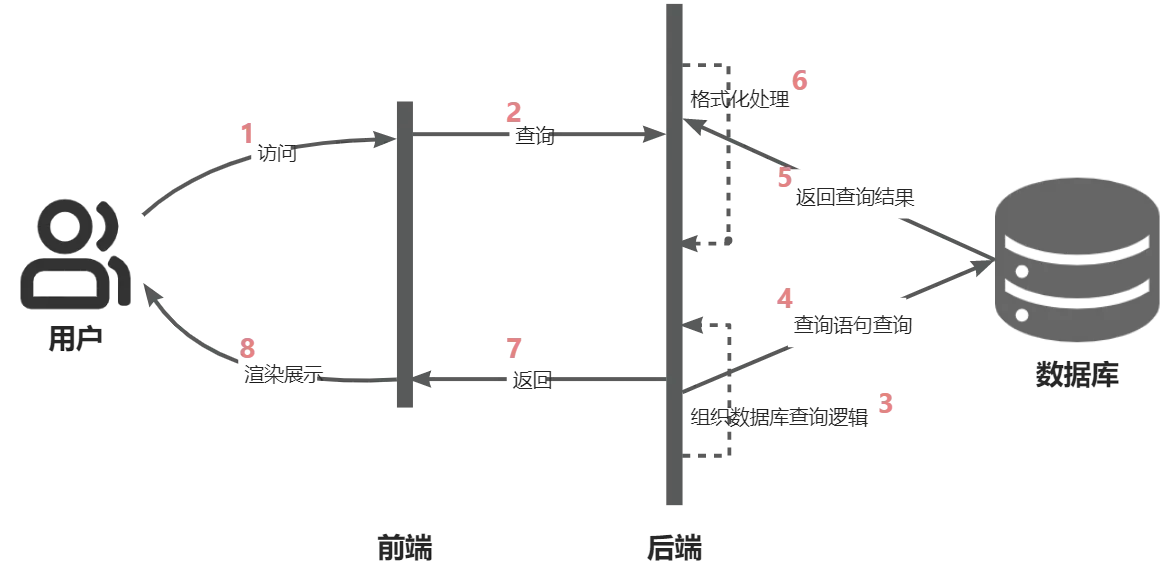
传统的开发调用流程(数据分析相关):
可以看到,对于开发人员来说实现一个需求需要完成多个步骤。
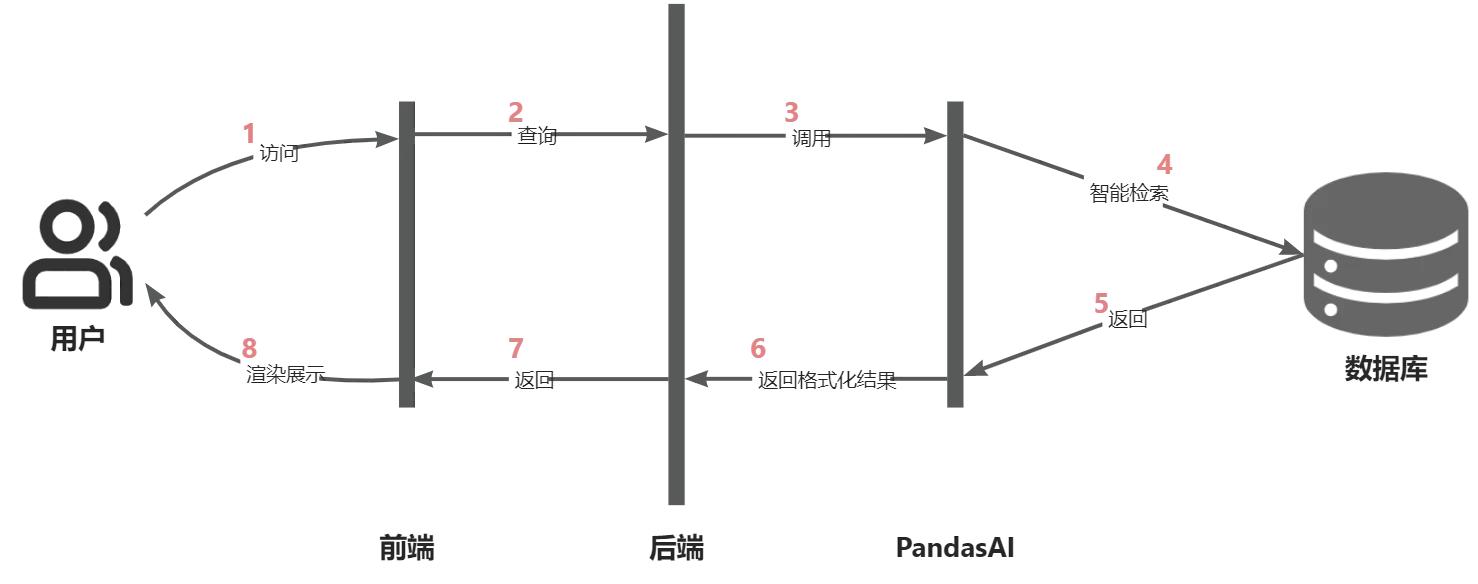
使用PandasAI之后的开发调用流程:
PandasAI 使用生成式 AI 模型来理解和解释自然语言查询,并将其转换为 python 代码和 SQL 查询。然后,它使用代码与数据进行交互,并将结果返回给用户。可以看到,PandasAI从很大程度上降低了后端开发的工作量。
1.使用PandasAI进行开发的流程
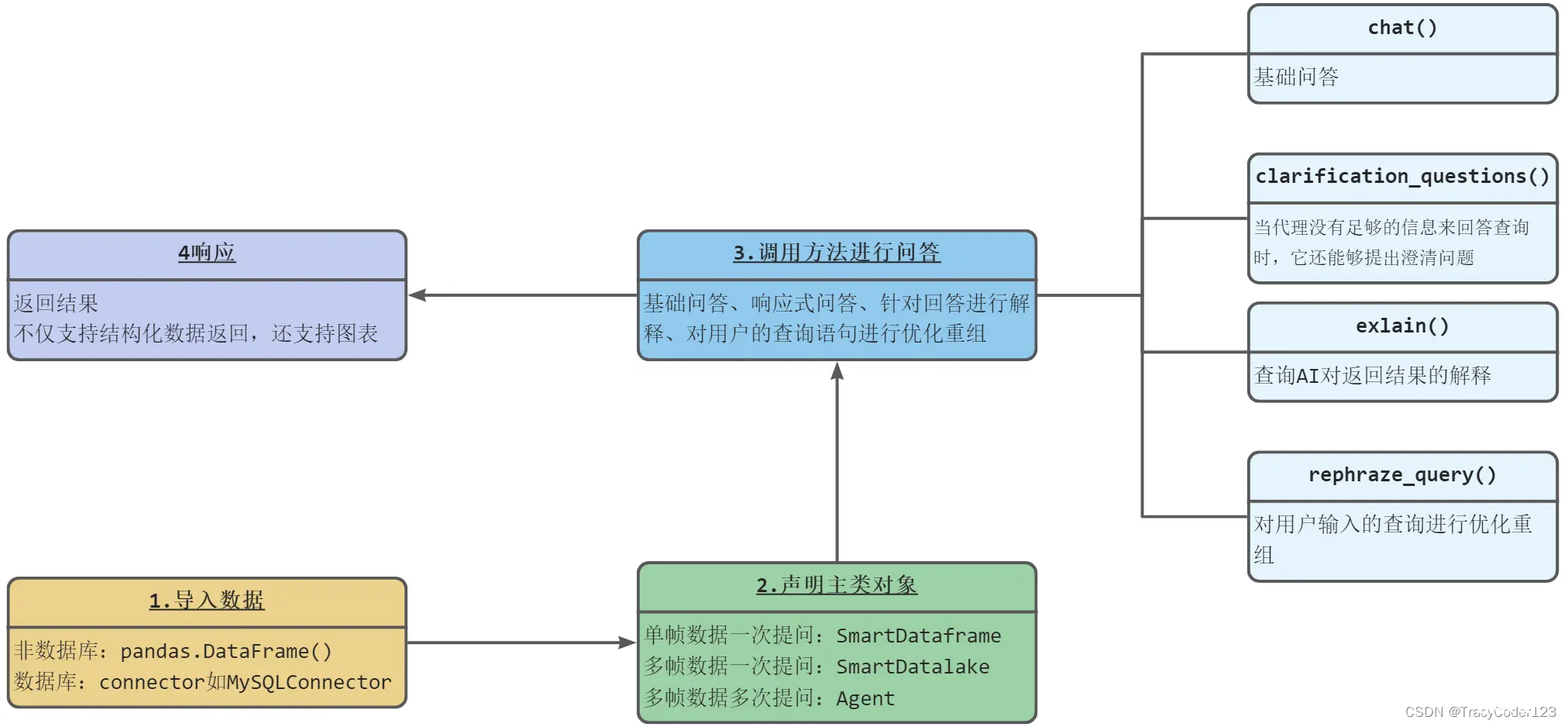
要使用PandasAI进行开发,首先,需要导入数据,可以是非数据库的pandas.DataFrame()或者数据库的connector如MySQLConnector。然后,声明主类对象,根据数据的不同可以选择单帧数据一次提问的SmartDataFrame、多帧数据一次提问的SmartDatalake或多帧数据多次提问的Agent。接下来,调用方法进行回答,包括基础问、响应式提问、针对回答进行解释、对用户的查询语句进行优化重组。最后,返回结果,不仅支持结构化数据返回,还支持图表(如下图所示):
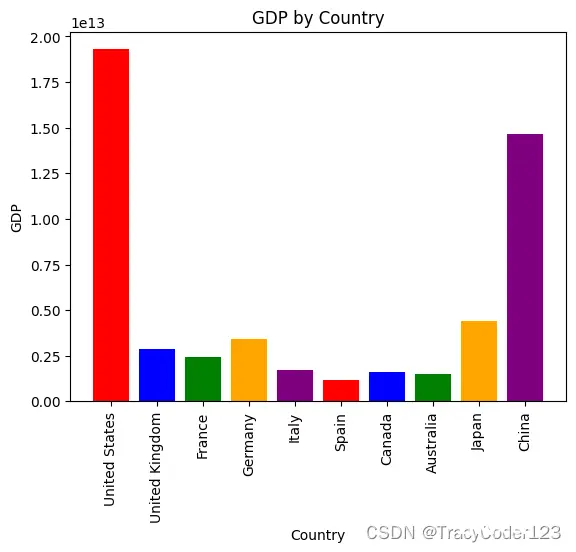
代码示例如下:
<code>"""Example of using PandasAI with a pandas dataframe"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
llm = OpenAI(api_token="你的OpenAI Token")code>
df = SmartDataframe("./data/data.csv", config={ "llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Calculate the sum of the gdp of north american countries")
print(response)
print(cb)
2.配置文件解析
PandasAI项目的配置文件pandasai.json:
{
"save_logs": true,
"verbose": false,
"enforce_privacy": false,
"enable_cache": true,
"use_error_correction_framework": true,
"max_retries": 3,
"open_charts": true,
"save_charts": false,
"save_charts_path": "exports/charts",
"custom_whitelisted_dependencies": [],
"llm": "openai",
"llm_options": null
}
llm:要使用的 LLM。llm_options:用于 LLM 的选项(例如 api 令牌等)。save_logs:是否保存 LLM 的日志。日志存放在项目根目录的Truepandasai.log中。verbose:是否在执行 PandasAI 时在控制台打印日志。enforce_privacy:是否强制执行隐私。默认值为 False,如果设置为True,PandasAI 不会向 LLM 发送任何数据,而只会发送元数据。默认情况下,PandasAI 会发送 5 个匿名样本,以提高结果的准确性。save_charts:是否保存 PandasAI 生成的图表,默认值为True 。可以在项目的根目录或指定的路径中找到图表。save_charts_path:保存图表的路径。open_charts:是否在解析来自 LLM 的响应时打开图表。enable_cache:是否启用缓存。use_error_correction_framework:是否使用纠错框架。max_retries:使用纠错框架时要使用的最大重试次数。custom_whitelisted_dependencies:要使用的自定义白名单依赖。
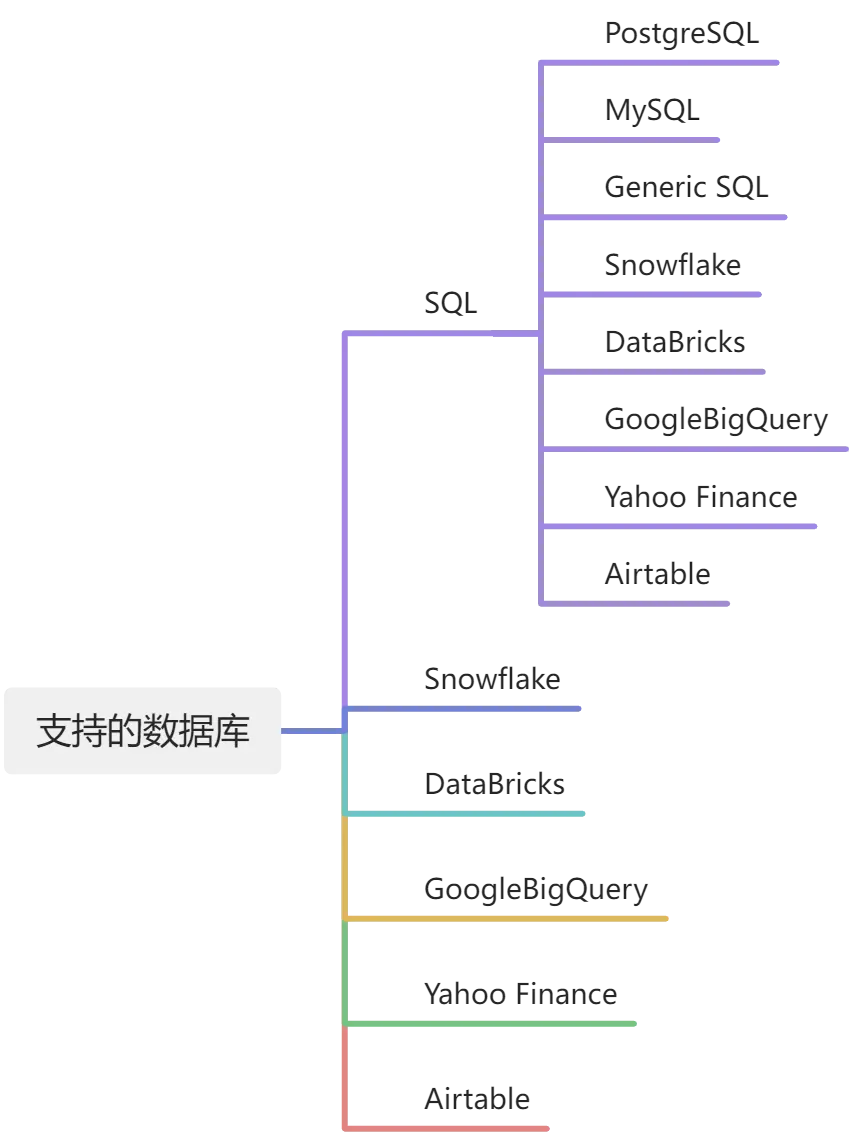
3.支持的数据库类型
PandasAI支持多种数据库:
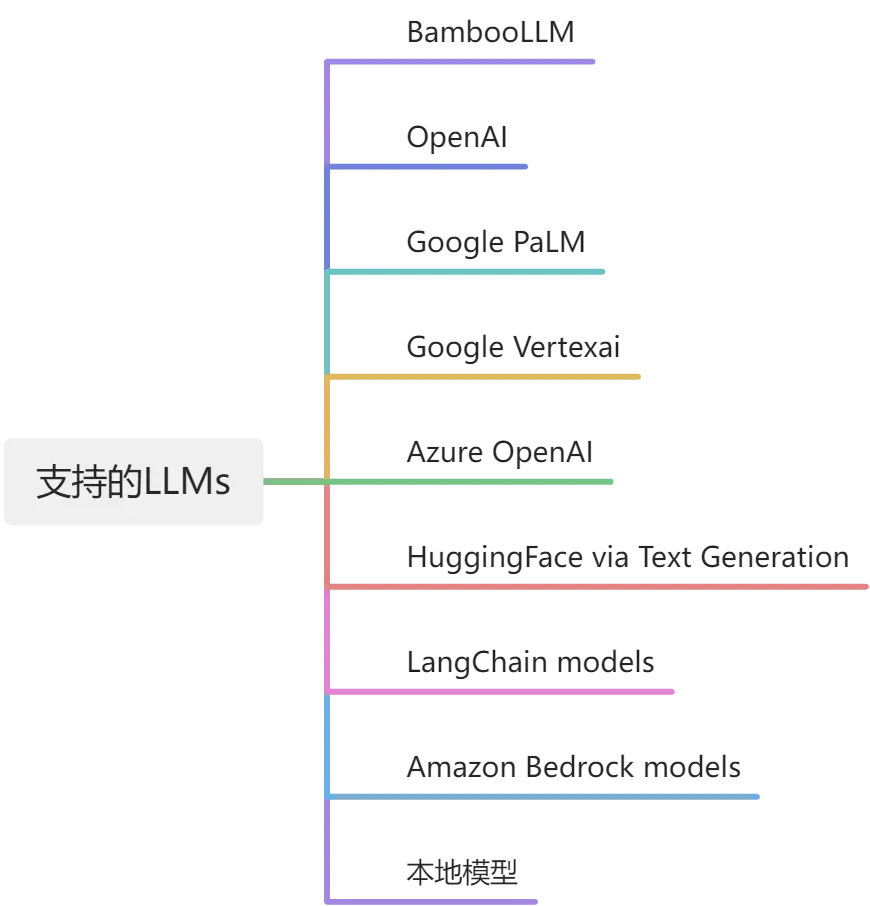
4.支持的LLMs
PandasAI 支持本地模型的使用,尽管通常情况下较小的模型性能可能不够理想。若要使用本地模型,首先需要在一个遵循OpenAI API的本地推理服务器上托管该模型。该作者声称已验证这种方法可在Ollama和LM Studio环境中正常运行。
5.其他
缓存:
PandasAI 使用缓存来存储先前查询的结果。这很有用,原因有两个:1)它允许用户快速检索查询结果,而无需等待模型生成响应。2)它减少了对模型的 API 调用次数,从而降低了使用模型的成本。
对响应进行定制:
PandasAI 提供了以自定义方式处理聊天响应的灵活性。默认情况下,PandasAI 包含一个 ResponseParser 类,可以根据需要扩展该类来修改响应输出。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。