20240629 每日AI必读资讯
程序员的店小二 2024-06-30 08:31:02 阅读 67

🚀 Google 深夜突袭,Gemma 2 狂卷 Llama 3
- Gemma2性能超越Llama3,提供9B和27B版本,性能接近70B模型但大小仅为其40%
- Gemma2支持高效推理,单个GPU即可实现全精度推理,广泛的硬件支持
- Gemma2兼容多种AI框架,提供实际应用示例和指南,谷歌计划支持通过Google Cloud Vertex AI轻松部署
🔗 https://aistudio.google.com/app/prompts/new_freeform
🔗 Google 深夜突袭,Gemma 2 狂卷 Llama 3-CSDN博客


🤖硅基智能开源其AI数字人交互平台
- 可以轻松创建逼真数字人
- 提供了很完善的工具和支持,部署过程变得非常简单和低成本。
- 功能支持:
语音识别:高效的语音输入,支持多种语言和口音。
语音合成:生成自然流畅的语音输出
实时交互:支持与用户的即时互动,提供快速响应。
多终端支持:可在Android和iOS设备上轻松部署,扩大使用场景。
模型下载:提供多个数字人模型的下载和使用,无需训练,即可使用。
🔗GitHub:https://github.com/GuijiAI/duix.ai
🔗在线体验:https://apps.apple.com/us/app/duix-your-ai-companion/id6451088879


📢和 GPT 4o 匹敌 世界上最快的语音机器
- 能实现500毫秒的语音到语音响应 接近人类对话的自然速度
- 为达到这种低延迟,开发团队优化了网络架构、AI模型性能和语音处理逻辑。
- 使用WebRTC网络发送音频,部署了Deepgram的快速转录和语音生成模型,并将所有AI模型在Cerebrium的容器中自托管,以减少延迟。
🔗在线体验:https://fastvoiceagent.cerebrium.ai


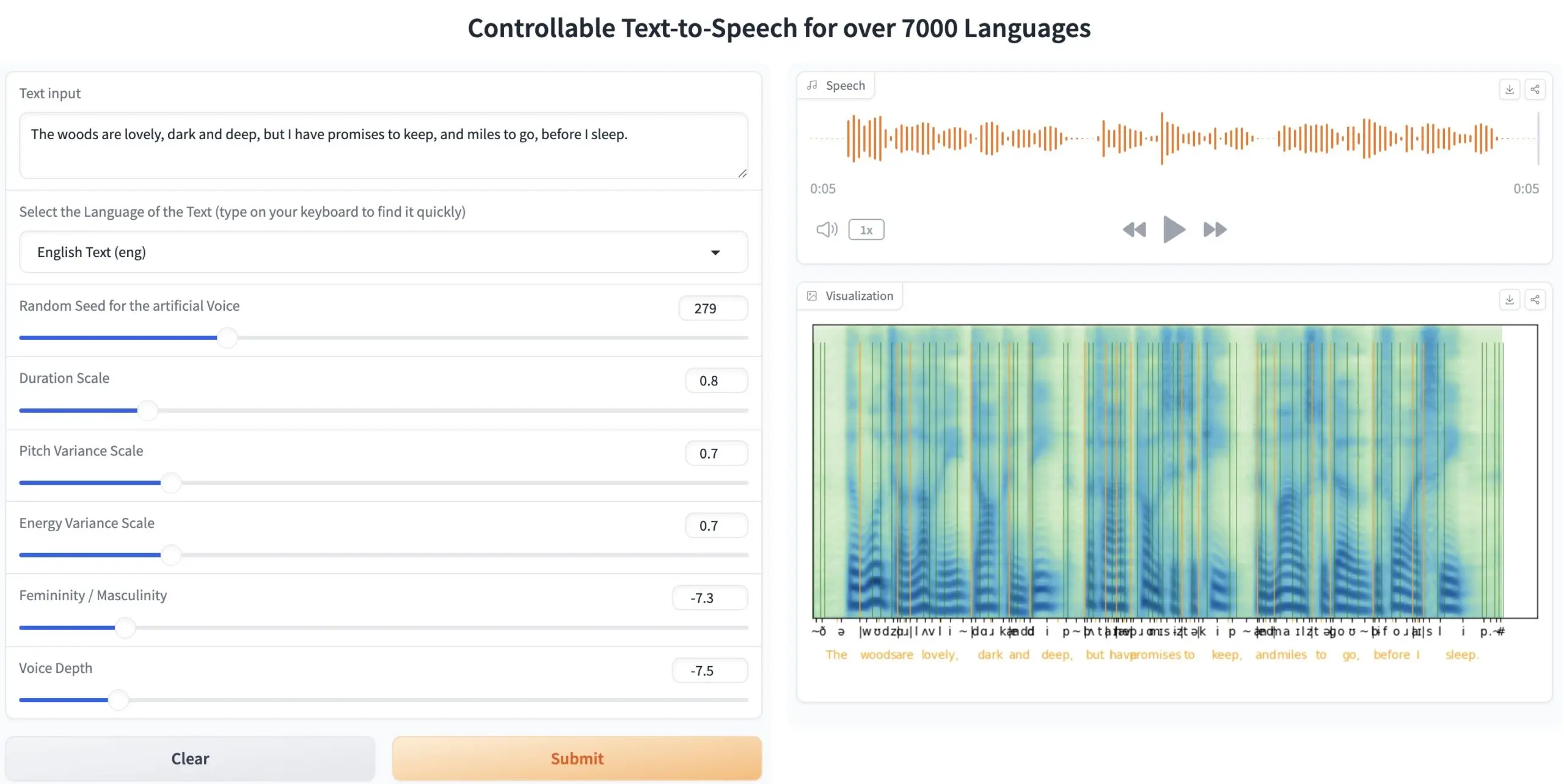
🌐ToucanTTS:支持超过 7000 多种语言的TTS模型
- 斯图加特大学自然语言处理研究所(IMS)开发了一个超全文本转语音模型ToucanTTS。
- 支持几乎所有的 ISO-639-3 标准语言,这意味着它理论上可以支持超过 7000 种语言。是目前支持语言种类最多的 TTS 模型。
- 支持多说话人语音合成功能,可以模拟不同说话人的节奏、重音和语调。这对于需要风格多样性和语音自定义的应用非常有用。
- 还允许用户控制语音的多个参数,包括音调、语速、情感等。
🔗GitHub:https://github.com/DigitalPhonetics/IMS-Toucan
🔗在线演示:https://huggingface.co/spaces/Flux9665/MassivelyMultilingualTTS
🔗数据集:https://huggingface.co/datasets/Flux9665/BibleMMS

🔧Resemble AI发布AI音频检测模型Detect-2B 准确率达到 94%
- Detect-2B是下一代深度伪造检测模型,准确率达94%。
- 使用预训练的子模型和微调来检查音频片段,判断是否由AI生成。
- 模型架构基于随机概率模型,在不同语言的深度伪造音频检测上表现出色。
- DETECT-2B 适用于需要检测深度伪 造音频的场景,可以帮助用户识别并防范 AI 生成的欺诈音频。
🔗 https://top.aibase.com/tool/detect-2b

🚩不靠谱?热门AI搜索工具Perplexity被指引用错误信息
- Perplexity被曝引用错误的AI生成垃圾信息,来自可疑的博客和LinkedIn文章。
- GPTZero发现Perplexity链接的来源中有越来越多是AI生成的,Perplexity有时会使用这些来源中的过时和不正确信息。
- Perplexity声称答案来自“可靠来源”,AI算法是否真的能从好的信息中获取好的信息值得怀疑。

🎨Viggle推出Move功能:可保留照片的原始背景 无需额外编辑
- 保留原始背景: "Move"功能与之前限制在绿色和白色背景的功能不同,保留照片原始背景,无需额外编辑。
- 易于访问:用户只需访问https://viggle.ai 即可使用新功能。
- 无需复杂编辑:直接上传照片,轻松为其添加动画效果,无需繁琐后期处理。
🔗 https://viggle.ai
🔗 https://blink.csdn.net/details/1744090

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。