NLP:spacy库安装与zh_core_web_sm配置
钢盔兔 2024-06-21 17:03:03 阅读 74
到公司来第一个项目竟然是偏文本信息抽取与结构化的,(也太高看我了┭┮﹏┭┮)
反正给机会了就上吧,我就一臭实习的,怕个啥。配置了两天的环境,也踩了不少坑,我把我的经历给大家分享一下:
首先确定zh_core_web_sm版本:
安装路径
(当然你可以换一个模型,我这里是以zh_core_web_sm为例,因为它下载容量小一些,不过精确率也稍微差一点,想追求效果好的可以试试zh_core_web_trf-3.7.0他是基于特征抽取器Tranformer,有想了解这方面背景故事的小伙伴可以看看这位大佬的博客:NLP12篇核心文章)
这一步非常重要,因为只有确定了他的版本号,才可以往后面去下载spacy,因为你如果后面两个版本对不上,执行代码的时候就会显示找不到zh_core_web_sm。记录你的版本号,之后按照这个博主的流程下载:下载流程。
而且注意版本最好不要太低,我一开始安装的是3.1.0的,但是后面安装spacy的时候就安装不上了(会报下面的错),最后换成3.7.0的就好了
如果后续有报错的话可以尝试加上下一步的镜像去下载,虽然不知道为什么,但是加上了确实可以解决我的问题
之后安装spacy,先在终端输入下面四行指令
(这里最好使用anconda创建一个新的虚拟环境,防止串包,因为下载的东西有点多。anconda创建切换环境)
pip install -U pip setuptools wheelpip install -U spacy==之前记录下来的版本号 pip install spacy-transformerspython3 -m spacy download zh_core_web_trf
这里直接用的话就会很慢,最好后面补充镜像去下载:
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple
如果加上了还显示连接超时的话,可能就是公司的网络太慢了,可以连一下自己的热点试试
最后应该就好了,给一段测试代码自己试试叭:
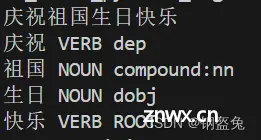
# # coding=utf-8import spacynlp = spacy.load("zh_core_web_sm")doc = nlp("庆祝祖国生日快乐")print(doc.text)for token in doc: print(token.text, token.pos_, token.dep_)

环境到此配置的差不多了,下篇论文我们将讲解如何训练专属于我们的模型:下一篇
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。