Web 目录爆破神器:Dirsearch 保姆级教程
CSDN 2024-07-01 08:33:01 阅读 60
一、介绍
dirsearch 是一款用于目录扫描的开源工具,旨在帮助渗透测试人员和安全研究人员发现目标网站上的隐藏目录和文件。与 dirb 类似,它使用字典文件中的单词构建 URL 路径,然后发送 HTTP 请求来检查这些路径是否存在。
以下是 dirsearch 工具的一些特点和基本用法:
特点:
多线程扫描: dirsearch 支持多线程扫描,提高目录扫描的效率。灵活的配置: 用户可以通过配置文件自定义扫描的参数,包括使用代理、设置 User-Agent 等。自定义报告: 支持生成自定义格式的报告,以便更好地整理和分享扫描结果。支持多种扫描方式: 除了常规目录扫描,还支持文件扫描、扩展名扫描等多种扫描方式。
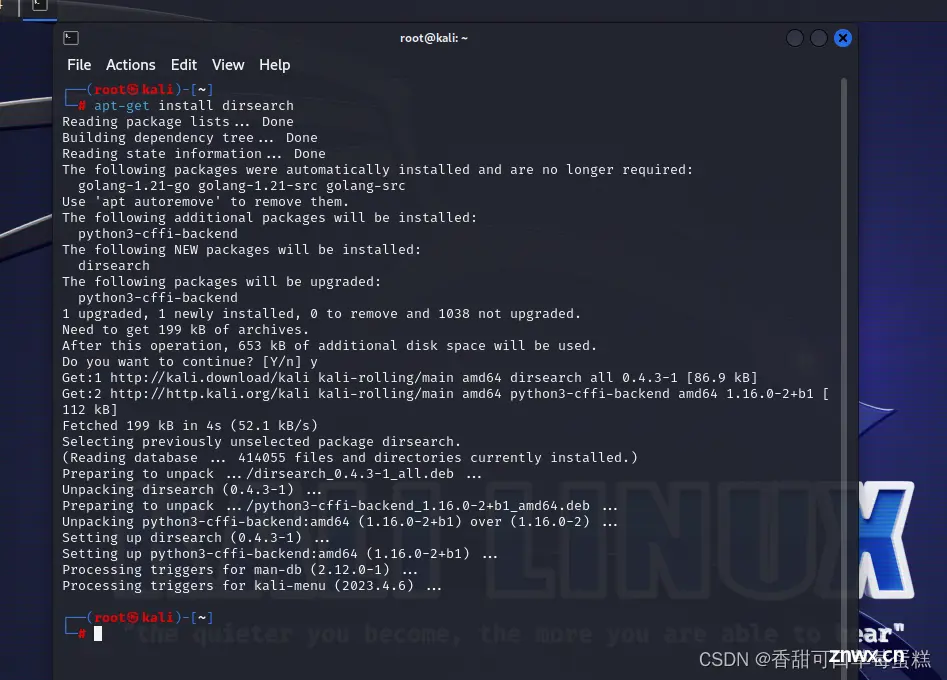
二、安装 Dirsearch
Kail Linux 下输入以下命令即可安装
apt-get install dirsearch
三、使用 Dirsearch
用法: dirsearch.py [-u|--url] 目标 [-e|--extensions] 扩展名 [选项]
选项:
--version 显示程序版本号并退出
-h, --help 显示帮助信息并退出
必填项:
-u URL, --url=URL 目标 URL(s),可以使用多个标志
-l PATH, --url-file=PATH
URL 列表文件
--stdin 从 STDIN 读取 URL(s)
--cidr=CIDR 目标 CIDR
--raw=PATH 从文件加载原始 HTTP 请求(使用 '--scheme' 标志设置协议)
-s SESSION_FILE, --session=SESSION_FILE
会话文件
--config=PATH 配置文件的路径(默认使用 'DIRSEARCH_CONFIG' 环境变量,否则使用 'config.ini')
字典设置:
-w WORDLISTS, --wordlists=WORDLISTS
自定义字典(用逗号分隔)
-e EXTENSIONS, --extensions=EXTENSIONS
用逗号分隔的扩展名列表(例如 php,asp)
-f, --force-extensions
在每个字典条目的末尾添加扩展名。默认情况下,dirsearch 只用扩展名替换 %EXT% 关键字
-O, --overwrite-extensions
使用您的扩展名(通过 `-e` 选择)覆盖字典中的其他扩展名
--exclude-extensions=EXTENSIONS
用逗号分隔的扩展名列表排除(例如 asp,jsp)
--remove-extensions
移除所有路径中的扩展名(例如 admin.php -> admin)
--prefixes=PREFIXES
添加自定义前缀到所有字典条目(用逗号分隔)
--suffixes=SUFFIXES
添加自定义后缀到所有字典条目,忽略目录(用逗号分隔)
-U, --uppercase 字典转为大写
-L, --lowercase 字典转为小写
-C, --capital 字典首字母大写
通用设置:
-t THREADS, --threads=THREADS
线程数
-r, --recursive 递归爆破
--deep-recursive 对每个目录深度执行递归扫描(例如 api/users -> api/)
--force-recursive 对每个找到的路径执行递归爆破,不仅限于目录
-R DEPTH, --max-recursion-depth=DEPTH
最大递归深度
--recursion-status=CODES
递归扫描的有效状态代码,支持范围(用逗号分隔)
--subdirs=SUBDIRS 扫描给定 URL[s]的子目录(用逗号分隔)
--exclude-subdirs=SUBDIRS
在递归扫描期间排除以下子目录(用逗号分隔)
-i CODES, --include-status=CODES
包括状态代码,用逗号分隔,支持范围(例如 200,300-399)
-x CODES, --exclude-status=CODES
排除状态代码,用逗号分隔,支持范围(例如 301,500-599)
--exclude-sizes=SIZES
通过大小(用逗号分隔)排除响应(例如 0B,4KB)
--exclude-text=TEXTS
通过文本排除响应,可以使用多个标志
--exclude-regex=REGEX
通过正则表达式排除响应
--exclude-redirect=STRING
如果正则表达式(或文本)与重定向 URL 匹配,则排除响应(例如 '/index.html')
--exclude-response=PATH
排除类似于此页面响应的响应,以路径为输入(例如 404.html)
--skip-on-status=CODES
每当命中其中一个状态代码时跳过目标,用逗号分隔,支持范围
--min-response-size=LENGTH
最小响应长度
--max-response-size=LENGTH
最大响应长度
--max-time=SECONDS 扫描的最大运行时间
--exit-on-error 每当发生错误时退出
请求设置:
-m METHOD, --http-method=METHOD
HTTP 方法(默认: GET)
-d DATA, --data=DATA
HTTP 请求数据
--data-file=PATH 包含 HTTP 请求数据的文件
-H HEADERS, --header=HEADERS
HTTP 请求头,可以使用多个标志
--header-file=PATH 包含 HTTP 请求头的文件
-F, --follow-redirects
跟随 HTTP 重定向
--random-agent 为每个请求选择随机 User-Agent
--auth=CREDENTIAL 身份验证凭证(例如 user:password 或 bearer token)
--auth-type=TYPE 身份验证类型(basic, digest, bearer, ntlm, jwt, oauth2)
--cert-file=PATH 包含客户端证书的文件
--key-file=PATH 包含客户端证书私钥的文件(未加密)
--user-agent=USER_AGENT
--cookie=COOKIE
连接设置:
--timeout=TIMEOUT 连接超时
--delay=DELAY 请求之间的延迟
--proxy=PROXY 代理 URL(HTTP/SOCKS),可以使用多个标志
--proxy-file=PATH 包含代理服务器的文件
--proxy-auth=CREDENTIAL
代理身份验证凭证
--replay-proxy=PROXY
重放找到的路径时使用的代理
--tor 使用 Tor 网络作为代理
--scheme=SCHEME 原始请求的协议或 URL 中没有协议时使用的协议(默认: 自动检测)
--max-rate=RATE 每秒的最大请求数
--retries=RETRIES 失败请求的重试次数
--ip=IP 服务器 IP 地址
--interface=NETWORK_INTERFACE
要使用的网络接口
高级设置:
--crawl 在响应中爬取新路径
显示设置:
--full-url 在输出中显示完整的 URL(在安静模式下自动启用)
--redirects-history
显示重定向历史
--no-color 无彩色输出
-q, --quiet-mode 安静模式
输出设置:
-o PATH, --output=PATH
输出文件
--format=FORMAT 报告格式(可用: simple, plain, json, xml, md, csv, html, sqlite)
--log=PATH 日志文件
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。