Vue3 核心源码解析
星辰大海1412 2024-09-03 09:03:01 阅读 53
Vue 发展历程

虚拟DOM 为后续做服务端渲染以及跨端框架位置提供基础。
相对应地缺点:

(1)源码优化:
对于 Vue.js 框架本身开发的优化。
目的:让代码更易于开发和维护
源码的优化主要体现在使用 monorepo和TypeScript 管理和开发源码。
这样做的目标是提升自身代码可维护性
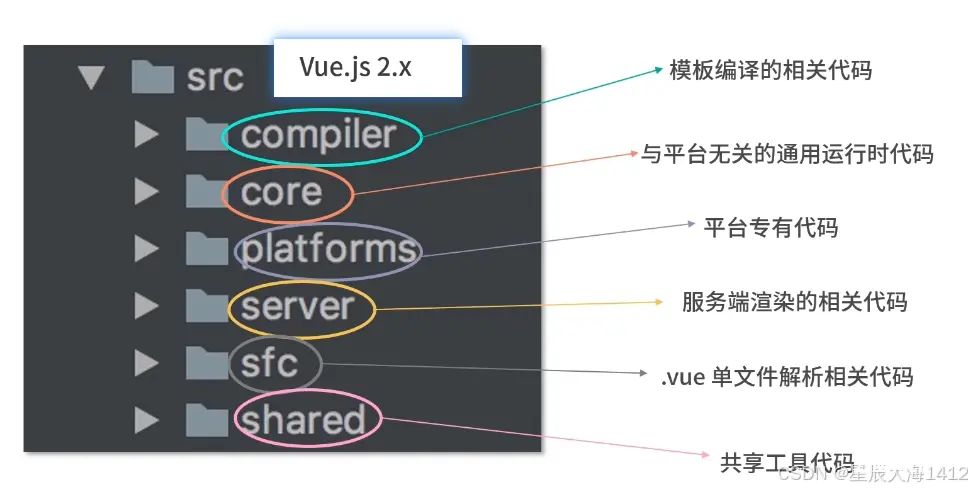
①更好的代码管理方式: monorepo

相对于 Vue.js 2.x的源码组织方式,monorepo 把这些模块拆分到不同的 package 中,每个 package 有各自的 API、类型定义和测试。
这样使得模块拆分更细化,职责划分更明确,模块之间的依赖关系也更加明确开发人员也更容易阅读、理解和更改所有模块源码,提高代码的可维护性。
例:package(比如 reactivity 响应式库)是可以独立于 Vue.js 使用的。
这样用户如果只想使用 Vue.js 3.0的响应式能力,可单独依赖这个响应式库。而不用去依赖整个 Vue.js,减小了引用包的体积大小,而 Vue.js2.x是做不到这一点的
②有类型的 JavaScript: TypeScript
——>更有利于代码的维护
因为它可以在编码期间帮你做类型检查 避免一些因类型问题导致的错误有利于它去定义接口的类型,利于IDE(集成开发环境 常见的IDE有Visual Studio、Eclipse、IntelliJ IDEA等)对变量类型的推导

Flow 是 Facebook出品的 JavaScript 静态类型检查工具,它可以以非常小的成本对已有的JavaScript 代码迁入,非常灵活,这也是Vue.is 2.0 当初选型它时一方面的考量。Flow 对于一些复杂场景类型的检查,支持得并不好。(在看 Vue.js 2.x源码的时候,在某行代码的注释中看到了对 Flow 的吐槽)

因此就选用了 TypeScript 进行整个项目的重构,TypeScript 提供了更好的类型检查,能支持复杂类型的推导。源码采用TS编写,也省去了维护地点TS文件的麻烦。
(2)性能优化:
对于 Vue.js 2.x 已经足够优秀的前端框架 它的性能优化可以从哪些方面进行突破呢?
①源码体积优化:
原理:JS包体积越小, 即网络传输时间越短,JS引擎解析包的速度越快。




原理: 未被引入的square模块被标记,压缩阶段会利用压缩工具真正删除没用到的代码。

②数据劫持优化:
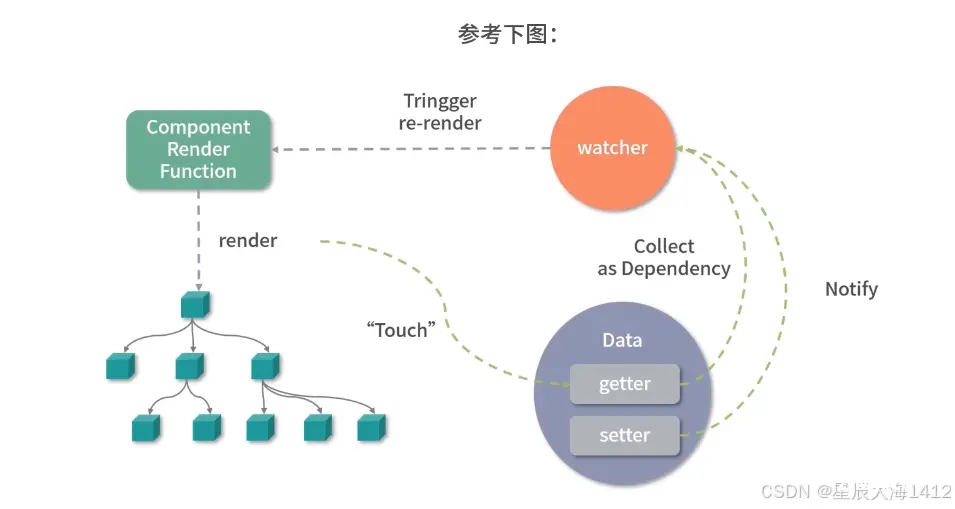
Vue.js 区别于 React.js 的一大特色是Vue的数据是响应式的。

DOM 是数据的一种映射, 数据发生变化后可以自动更新DOM,用户只需要专注于数据的修改,没有其余的性质负担。但是这样子的功能实现必须需要劫持数据的访问与更新。
当数据改变后,为了自动更新 DOM,那么就必须劫持数据的更新。
也就是说当数据发生改变后能自动执行一些代码去更新 DOM。
Vue.js 怎么知道更新哪一片 DOM 呢?
因为在渲染 DOM 的时候访问了数据,我们可以对它进行访问劫持。
这样就在内部建立了依赖关系,也就知道数据对应的 DOM 是什么了 。内部需要依赖watcher的数据结构做依赖管理
Vue1 和 Vue2 通过 object.defineProperty 进行数据劫持:
缺陷:必须知道要拦截的key是什么,因此不能检测对象的属性的添加和删除。
如果要劫持内部深层次的对象变化,就需要递归遍历这个对象,通过Object.defineProperty把每一层对象的数据都变成响应式的。——> 响应式数据过于复杂,就会有相当大的性能负担。

劫持了一整个对象,因此对对象属性的增加和删除都能够检测到。

这样的好处是真正访问到的内部对象才会变成响应式,而不是无脑递归这样无疑也在很大程度上提升了性能。
(3)编译优化:Block tree

响应式过程发生在new Vue到 init 阶段。



虽然 Vue.js 2.x 的数据更新并触发重新渲染的粒度是组件级的:,虽然Vue能保证触发更新的组件最小化,但是在单个组件内部,依然需要遍历该组件的整个 windows 树。


代码只有一个动态节点,很多的 diff 和遍历其实是不需要的,导致Windows 性能与模板大小正相关,跟动态节点的数量无关。当一些组件整个模板只有少量动态节点时,这些遍历都是性能的浪费。
理想状态只需要 diff 这个绑定 message 动态节点的p标签即可

Block tree
Blocktree 是一个将模版基于动态节点指令切割的嵌套区块,每个区块内部的节点结构是固定的每个区块只需要以一个 Array 来追踪自身包含的动态节点。借助 Block tree,Vue.js 将vnode 更新性能由与模版整体大小相关提升为与动态内容的数量相关

(4)语法API优化: Composition API

①优化逻辑组织

Options APl
OptionsAPl的设计是按照 methods、computed、data、props 这些不同的选项分类当组件小的时候,这种分类方式一目了然; 但是在大型组件中,一个组件可能有多个逻辑关注点当使用 Options API的时候,每一个关注点都有自己的 Options如果需要修改一个逻辑点关注点,就需要在单个文件中不断上下切换和寻找


按照逻辑关注点做颜色编码, 当使用Option API 编写组件时,逻辑关注点都是非常分散的。


开发项目变得复杂时,免不了需要抽象出一些复用逻辑。

鼠标位置监听的例子:

如果有大量的Mixin就会有命名冲突和数据来源不清晰。
首先每个 mixin 都可以定义自己的 props、data,它们之间是无感的所以很容易定义相同的变量,导致命名冲突。对组件而言,如果模板中使用不在当前组件中定义的变量,那么就会不太容易知道这些变量在哪里定义的,这就是数据来源不清晰
但是Vue.js 3.0 设计的 Composition APl,就很好地帮助我们解决了 mixins 的这两个问


Composition APl
除了在逻辑复用方面有优势,也会有更好的类型支持因为它们都是一些函数,在调用函数时,自然所有的类型就被推导出来了。不像 Options API 所有的东西使用 this另外,CompositionAPl 对 tree-shaking 友好,代码也更容易压缩
②引入 RFC:
使每个版本改动可控


过渡期:



组件渲染
在 Vue.js 中,组件是一个非常重要的概念,整个应用的页面都是通过组件渲染来实现的
编写组件开始,到最终真实的 DOM 又是怎样的一个转变过程呢?
组件:



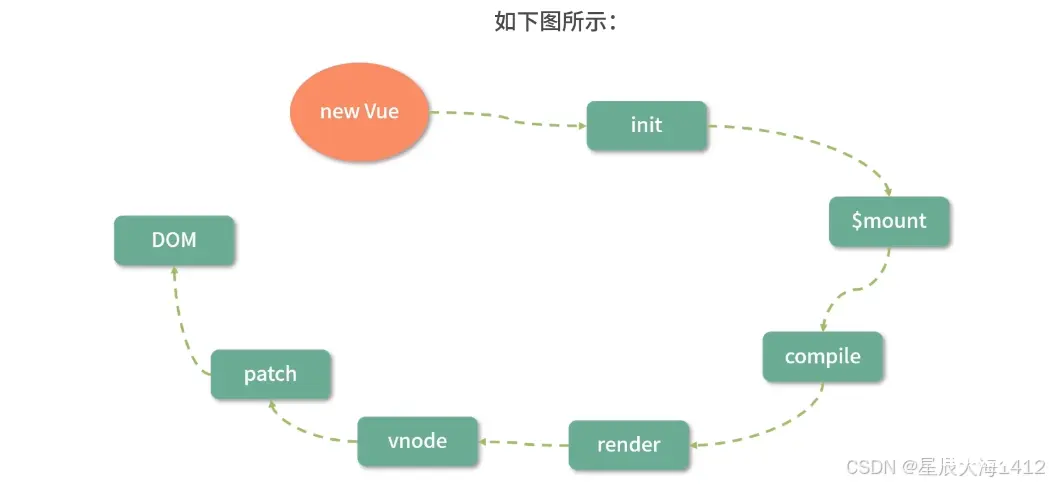
①应用程序初始化:
一个组件可以通过 “模板加对象描述” 的方式创建,组件创建好以后是如何被调用并初始化的呢?
因为整个组件树是由根组件开始渲染的。
为了找到根组件的渲染入口,需要从应用程序的初始化过程开始分析

本质:把 app 组件挂载到 id 为 app 的DOM节点上。
createApp 是一个入口函数,Vue对外暴露的函数
createApp 主要是:
创建 app 对象;重启 app.mount 方法
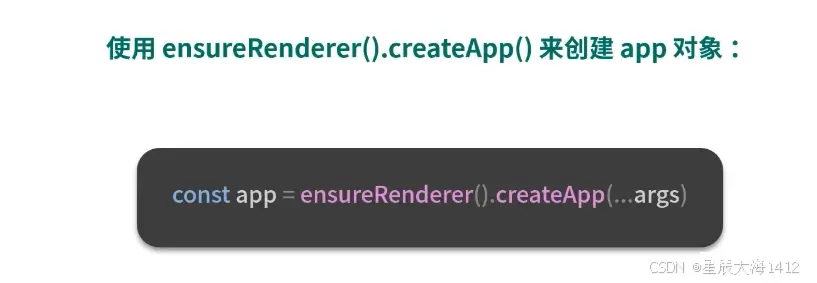
ensureRenderer() 用来创建一个渲染器对象
渲染器:为跨平台渲染做准备(包含平台渲染核心逻辑的JS对象)
优点:用户只依赖响应式包的时候,就不会创建渲染器,可以通过 tree-shaking 移除核心渲染逻辑相关的代码



在整个 app 对象创建过程中,Vue.js 利用 闭包和函数柯里化 的技巧,很好地实现了参数保留比如,在执行 app.mount 的时候,不需要传入 渲染器render(因为在执行 createAppAPI的时候渲染器 render 参数已经被保留下来了 )
先思考一下,为什么要重写 app.mount 这个方法而不把相关逻辑放在 app 对象的 mount 方法内部来实现呢?

标注的可跨平台的组件渲染流程:先创建Vnode,再渲染Vnode。rootCotainer可以是(DOM或者是其他平台的其他类型的值,即这些代码执行逻辑都是与平台无关的,因此需要重写方法来完善外平台下的渲染逻辑。)


②核心渲染流程:
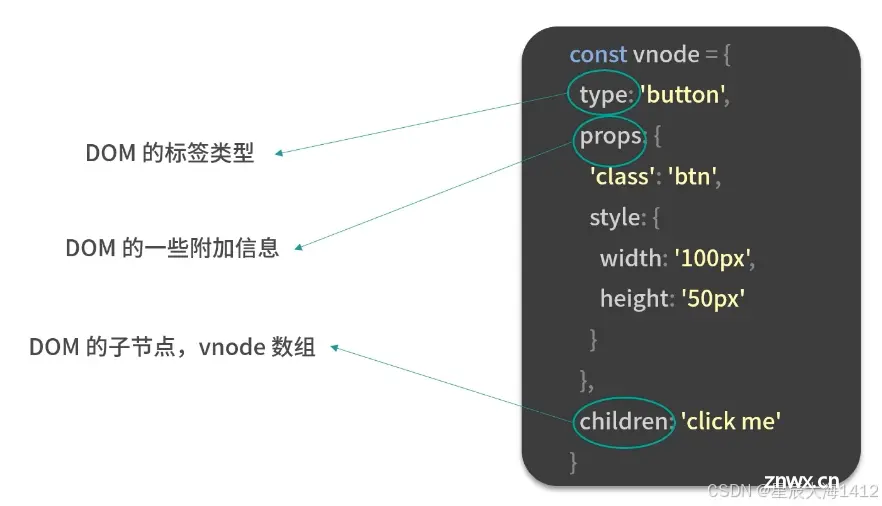
创建 vnode 和渲染 vnode

1️⃣普通元素节点:



2️⃣组件节点



即不会真的在页面上渲染一个 CustomComponent 标签,而是渲染组件内部定义的 HTML 标签。
3️⃣纯文本Vnode
4️⃣注释Vnode
内部还针对Vnode tag做了更详细的分类,并且把VNode类型做编码,以便在后面的配置阶段,可以根据不同的类型执行相应的处理逻辑:

那么 vnode 有什么优势呢?
为什么一定要设计 vnode 这样的数据结构呢?

首先这种基于 vnode 实现的 MVVM 框架,在每次 render to vnode 的过程中,渲染组件会有一定的 JavaScript 耗时,特别是大组件
当我们去更新组件的时候,用户会感觉到明显的卡顿。
虽然 diff 算法在减少 DOM 操作方面足够优秀,但最终还是免不了操作 DOM所以说性能并不是 vnode 的优势




创建VNode操作:对 props 做标准化处理,对 Vnode 的类型信息编码,创建 VNode 对象,标准化子节点children
app.mount 内部通过执行 render 函数去渲染创建的 VNode

patch 函数功能:
根据 VNode 挂载 DOM根据新旧 VNode 更新 DOM


重点关注对组件的处理、对普通 DOM 元素 两种类型的处理节点的渲染逻辑


主要操作:创建组件实例, 设置组件实例,设置并运行带副作用的渲染函数


初始渲染主要做两件事情: 渲染组件生成subTree(VNode对象)、把 subTree 挂载到 container 中


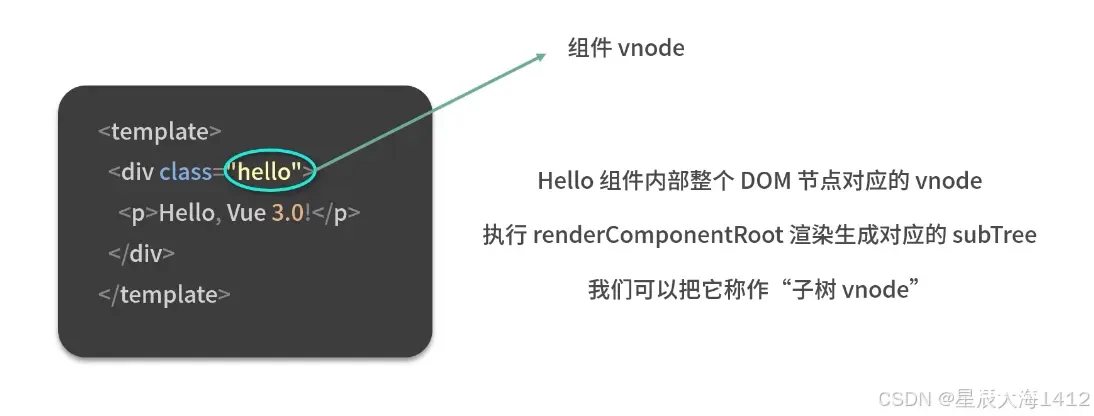
hello节点渲染生成的Vnode就是hello对应的init Vnode(组件Vnode)hello组件内部的整个DOM节点对应的Vnode就是执行 renderComponentRoot 渲染生成对应的subTree,可以称之为子树Vnode
每个组件都有对应的render函数
renderComponentRoot 就是执行 render 函数,创建整个组件内部的Vnode,把这个 Vnode 再经过内部一层标准化就能得到该函数的返回结果即子树Vnode。渲染生成子树Vnode后就是大勇patch函数把子树Vnode挂载到content中。
对普通DOM元素的处理流程:


如果是其他平台比如 Weex,hostCreateElement 方法就不再是操作 DOM而是平台相关的 API了,这些平台相关的方法是在创建渲染器阶段作为参数传入的
创建完 DOM 节点后,接下来要做的是判断如果有 props 的话给这个 DOM 节点添加相关的 class、style、event等属性,并做相关的处理这些逻辑都是在 hostPatchProp 函数内部做的

DOM和VNode都是一棵树,并且结构和DOM一一映射。




处理完所有子节点后, 通过insert的方法把创建DOM元素节点挂载到content下
因为 insert 的执行是在处理子节点后,所以挂载的顺序是先子节点,后父节点
最终挂载到最外层的容器上
在 mountChildren 的时候递归执行的是 patch 函数,而不是 mountElement 函数
这是因为子节点可能有其他类型的vnode,比如组件 vnode


梳理了组件渲染的过程,本质上就是把各种类型的 vnode 渲染成真实 DOM组件是由模板、组件描述对象和数据构成的,数据的变化会影响组件的变化组件的渲染过程中创建了一个带副作用的渲染函数当数据变化的时候就会执行这个渲染函数来触发组件的更新
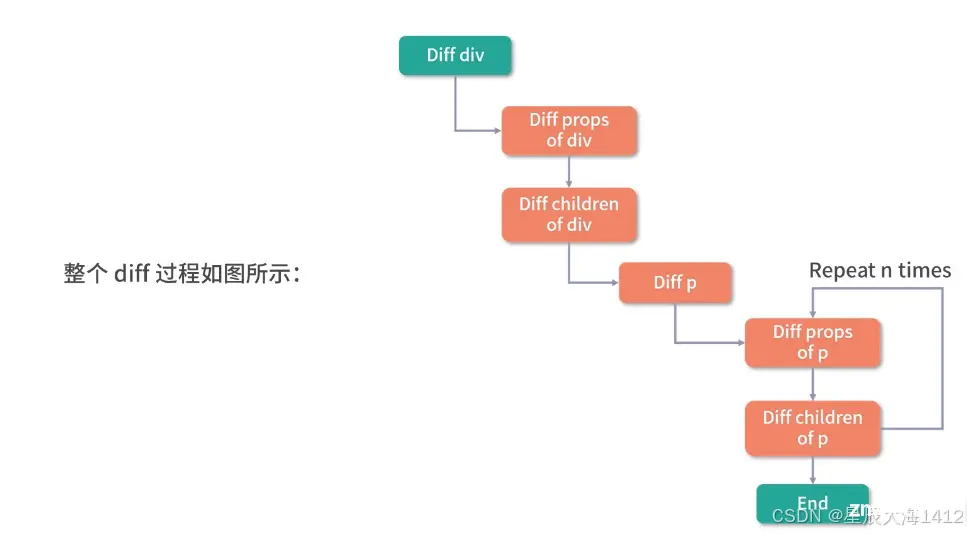
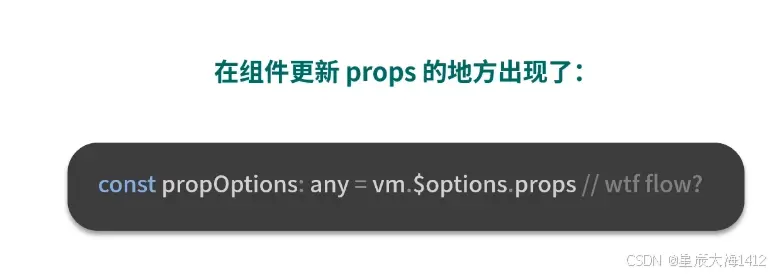
③ 副作用渲染函数更新组件的过程


声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。