程序员的福音,AI 项目生成 GPT Engineer 实践与源码解析
易迟 2024-06-16 08:31:06 阅读 66
背景介绍
GPT Engineer 是一个基于需求描述自动生成项目源码的开源项目,主打轻量,灵活生成项目源码,可以在 AI 生成与人工生成之间进行切换,底层是基于 GPT-4 对应的编程能力,目前 Github 上 star 数量已经达到了 50k,算是一个十分火热的 AI 项目。
与大热的 AutoGPT 相比,GPT Engineer 更加轻量,没有使用递归的请求调用,避免陷入反复请求的死循环。同时 GPT Engineer 更加侧重代码生成,因此 prompt 上针对代码生成上做了针对性的优化。
动手实践
使用的 GPT Engineer 版本为 0.1.0,此版本提供的两个能力分别为:
创建新工程;优化已有代码;
安装方式很简单,在 Python 环境下安装所需的依赖,然后配置上 OPANAI_KEY 即可,这部分可以查看 github readme,这边就不进一步介绍了。
创建新工程
使用 GPT Engineer 对研发人员相对简单,直接在工程所需的目录下创建一个 prompt 文件,在此文件上描述项目相关的信息,然后调用 gpt-engineer <project_dir> 即可生成所需的代码。下面选择一个实际的需求验证 GPT Engineer 的能力。
在之前的文章中提到了 DICOM 医疗图像,期望使用医疗图像进行机器学习的训练,因此需要构造基于医疗图像的 dataset。同时期望生成 dataset 时可以从 JSON 格式的标注文件中提取标签。对应需求需要具备处理 DICOM 解析,机器学习 dataset 构造,以及必要的标签解析提取标签的能力,对应的 prompt 如下所示:
期望基于 pytorch 实现支持 DICOM 图像的 dataset 用于深度学习训练,每个图像对应一个同名的 json 文件,其中包含 `label` 字段作为图像训练的标签
这部分只是简单的需求描述,没有做太多 prompt 的优化。最终输出了代码结构如下所示:
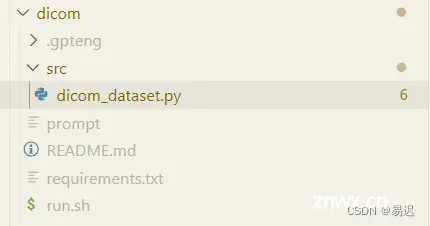
可以看到输出了对应的代码,并补充了依赖文件 requirements.txt,并增加了相关测试脚本 run.sh 方便进行测试。下面具体看下主要的代码实现:
import osimport jsonimport pydicomimport torchfrom PIL import Imagefrom torchvision.transforms import ToTensorfrom torch.utils.data import Datasetclass DicomDataset(Dataset): def __init__(self, image_dir, label_dir): self.image_dir = image_dir self.label_dir = label_dir self.image_files = os.listdir(image_dir) def __len__(self): return len(self.image_files) def __getitem__(self, idx): image_file = self.image_files[idx] image_path = os.path.join(self.image_dir, image_file) label_path = os.path.join(self.label_dir, image_file.replace('.dcm', '.json')) # Load DICOM image dicom_image = pydicom.dcmread(image_path).pixel_array # Convert DICOM image to tensor image = ToTensor()(Image.fromarray(dicom_image)) # Load label with open(label_path, 'r') as f: label = json.load(f)['label'] return image, label
可以看到实现的方法基本没有特别的问题,定义了 image_dir 为对应的图片目录,label_dir 作为标签目录,通过 image_files 获取目录下所有图片文件,并根据图片名确定了对应的标签文件,在访问数据方法 __getitem__() 中,正确返回 Tensor 格式的图像数据 image ,以及对应的标签。整体可用度很高。
对应的启动脚本 run.sh 如下所示:
python3 -m venv envsource env/bin/activatepip install -r requirements.txt
import torchfrom torch.utils.data import DataLoaderfrom src.dicom_dataset import DicomDataset# Initialize dataset and dataloaderdataset = DicomDataset('path/to/image_dir', 'path/to/label_dir')dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# Loop over the datasetfor images, labels in dataloader: # Your training code here pass
在启动脚本中包含了构造运行环境与训练流程,目前将这两部分的代码都统一放在 shell 脚本中,运行流程也基本符合预期,但是需要小幅调整对应的代码结构。可以看到对于这种模块的需求,GPT Engineer 的效果还是不错的。而且基础环境的搭建也基本可用了,研发人员在这个代码的基础上进行简单修改,开发工作量确实可以大幅减少。
优化已有代码
使用 FATE-Flow 工程随机选择了一个 python 文件 data_manager.py 进行了简单重构优化测试,创建的 prompt 如下所示:
优化代码质量,利用重构手段在保留原有方法的情况下尽可能优化代码
可以看到基本没有太多信息,只是重构进行试验,最终完成了部分内容的优化,展示其中的一小块如下所示:

可以看到在没有明确方向的情况下,确实执行了必要的重构优化,因为 FATE 作为开源项目,整体代码质量已经相对高了,在这个基础上做了一些简单了变量优化。
源码解析
实践之后可以进一步看看 GPT Engineer 的源码实现,这边主要以创建新工程的流程为例进行全流程的跟踪:
启动命令
命令行执行的命令 gpt-engineer <project_dir> 对应于 gpt_engineer/cli/main.py 中的 main() 方法,具体的实现简化后如下所示:
def main(): # 选择本次运行的模式,默认模式 DEFAULT 就是新建项目, IMPROVE_CODE 就是优化已有项目的代码 steps_config = StepsConfig.DEFAULT if lite_mode: if steps_config == StepsConfig.DEFAULT: steps_config = StepsConfig.LITE if improve_mode: steps_config = StepsConfig.IMPROVE_CODE ai = AI( model_name=model, temperature=temperature, azure_endpoint=azure_endpoint, ) dbs = DBs( memory=DB(memory_path), logs=DB(memory_path / "logs"), input=DB(input_path), workspace=DB(workspace_path), preprompts=DB(preprompts_path(use_custom_preprompts, input_path)), archive=DB(archive_path), project_metadata=DB(project_metadata_path), ) if steps_config not in [ StepsConfig.EXECUTE_ONLY, StepsConfig.USE_FEEDBACK, StepsConfig.EVALUATE, StepsConfig.IMPROVE_CODE, ]: archive(dbs) load_prompt(dbs) steps = STEPS[steps_config] # 执行模式对应的步骤 for step in steps: messages = step(ai, dbs)
可以看到最核心的流程很简单,就是根据用户选择的模式确定 steps_config, 根据 steps_config 确定对应的步骤 steps,然后依次执行所有的步骤。
默认模式的步骤
每个模式对应的步骤都有所不同,我们使用默认情况下新建项目对应的步骤进行分析,对应的 STEPS 常量定义在 gpt_engineer/core/steps.py 中,DEFAULT 对应为步骤为:
simple_gen 生成对应的工程代码gen_entrypoint 生成工程对应的入口代码execute_entrypoint 指定对应的入口代码human_review 人工反馈,搜集用户反馈信息
最核心的代码生成主要就是 simple_gen() 和 gen_entrypoint(),通过这两部分生成了一个包含入口程序的新项目。
simple_gen()
这部分的实现如下所示:
def simple_gen(ai: AI, dbs: DBs) -> List[Message]: messages = ai.start(setup_sys_prompt(dbs), dbs.input["prompt"], step_name=curr_fn()) to_files_and_memory(messages[-1].content.strip(), dbs) return messages
可以看到核心的代码就是调用 ai.start() 方法生成对应的结果,此方法对应的实现在 gpt_engineer/core/ai.py 中,其中的实现如下所示:
# 基于用户的 prompt 构造 Message 发送 ChatGPT 请求def start(self, system: str, user: str, step_name: str) -> List[Message]: messages: List[Message] = [ SystemMessage(content=system), HumanMessage(content=user), ] return self.next(messages, step_name=step_name)def next( self, messages: List[Message], prompt: Optional[str] = None, *, step_name: str,) -> List[Message]: if prompt: messages.append(self.fuser(prompt)) callbacks = [StreamingStdOutCallbackHandler()] response = self.backoff_inference(messages, callbacks) self.update_token_usage_log( messages=messages, answer=response.content, step_name=step_name ) messages.append(response) return messagesdef backoff_inference(self, messages, callbacks): return self.llm(messages, callbacks=callbacks) # type: ignore
而对应的 self.llm 构造在初始化阶段完成,对应如下所示:
from langchain.chat_models import AzureChatOpenAI, ChatOpenAI# 创建 ChatOpenAI 对象,用于发起 ChatGPT 网络请求def create_chat_model(self, model: str, temperature) -> BaseChatModel: if self.azure_endpoint: return AzureChatOpenAI( openai_api_base=self.azure_endpoint, openai_api_version="2023-05-15", # might need to be flexible in the future deployment_name=model, openai_api_type="azure", streaming=True, ) return ChatOpenAI( model=model, temperature=temperature, streaming=True, client=openai.ChatCompletion, )self.llm = create_chat_model(self, self.model_name, self.temperature)
可以看到 start() 就是将系统 prompt 与用户 prompt 构造为 langchain 的 Message,然后利用 langchain 提供的封装发起 ChatGPT 网络请求。
网络请求的发起没有太多需要关注的地方,关键在于 prompt 是如何生成的。这部分主要包含用户 prompt 与系统 prompt
用户 prompt
这部分是通过在创建项目前创建的 prompt 文件指定的,如果初始化时没有指定,GPT Engineer 也会通过交互式的方式要求用户描述项目相关的需求;
系统 prompt
通过 setup_sys_prompt() 方法进行创建,对应的实现如下所示:
def setup_sys_prompt(dbs: DBs) -> str: return ( dbs.preprompts["roadmap"] + dbs.preprompts["generate"].replace("FILE_FORMAT", dbs.preprompts["file_format"]) + "\nUseful to know:\n" + dbs.preprompts["philosophy"] )
可以看到系统 prompt 是通过预定义的 prompt 进行拼凑而成。预定义的 prompt 定义在 gpt_engineer/preprompts 目录下,上面方法中几个预定义的 prompt 分别有一个同名文件进行对应,这边就简单列举一个 roadmap 文件。对应如下:
You will get instructions for code to write.You will write a very long answer. Make sure that every detail of the architecture is, in the end, implemented as code.
这部分告知需要将架构的实现细节以代码形式呈现,其他的预定义的prompt 有兴趣的可以查看对应的目录。
gen_entrypoint()
此方法对应的实现如下所示:
def gen_entrypoint(ai: AI, dbs: DBs) -> List[dict]: messages = ai.start( system=( "You will get information about a codebase that is currently on disk in " "the current folder.\n" "From this you will answer with code blocks that includes all the necessary " "unix terminal commands to " "a) install dependencies " "b) run all necessary parts of the codebase (in parallel if necessary).\n" "Do not install globally. Do not use sudo.\n" "Do not explain the code, just give the commands.\n" "Do not use placeholders, use example values (like . for a folder argument) " "if necessary.\n" ), user="Information about the codebase:\n\n" + dbs.memory["all_output.txt"], step_name=curr_fn(), ) regex = r"```\S*\n(.+?)```" matches = re.finditer(regex, messages[-1].content.strip(), re.DOTALL) dbs.workspace["run.sh"] = "\n".join(match.group(1) for match in matches) return messages
可以看到同样是调用 ai.start() 方法,利用 langchain 提供的封装间接调用 ChatGPT 接口完成请求,通过特定 prompt 实现了生成入口代码的能力。
总结
通过上面的流程可以看到 GPT Engineer 当前阶段具备的能力以及对应的实现方案。通过精心设计的 prompt 利用 ChatGPT 的能力,可以构造一个工程的能力,尝试去解决就差一个程序员的产品困境,整体使用的体验还不错,而且使用起来极其方便,想法还是很棒的。
从实际应用场景来看,与 AutoGPT 不同之处在于 GPT Engineer 没有反复循环调用,因此架构设计上更加简单一些,也可以避免 AutoGPT 死循环导致消耗大量 token 的问题,但是因为缺失了循环调用,因此可以生成的项目代码规模就比较有限,目前更适用于生成一个项目 demo 或特定的项目模块。
后续随着 GPT Engineer 的迭代,可能会具备更强的历史状态维持能力,通过持续在上一次的状态上进行代码生成,也许能胜任更大规模的项目代码生成。现阶段另一个可能的应用方案是通过人工拆分模块,利用 GPT Engineer 进行模块级别的实现,接着在 Github copilot 协助下进行二次开发,预期效率可以得到大幅提升。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。