Java 集合框架:HashMap 的介绍、使用、原理与源码解析
CSDN 2024-07-31 12:05:05 阅读 85
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 020 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进一步完善自己对整个 Java 技术体系来充实自己的技术栈的同学。与此同时,本专栏的所有文章,也都会准备充足的代码示例和完善的知识点梳理,因此也十分适合零基础的小白和要准备工作面试的同学学习。当然,我也会在必要的时候进行相关技术深度的技术解读,相信即使是拥有多年 Java 开发经验的从业者和大佬们也会有所收获并找到乐趣。
–
在 Java 编程中,集合框架提供了强大而灵活的数据存储和操作方式。作为 Java 集合框架中的重要一员,<code>HashMap 是一种常用的键值对映射实现。它广泛应用于需要高效数据查找、插入和删除的场景中。理解
HashMap的工作原理对于编写高效的 Java 程序至关重要。
HashMap是一个基于哈希表的Map实现,它的设计目标是提供高效的键值对存储和操作。通过将键的哈希值映射到哈希表的索引位置,HashMap能够以接近常数时间的复杂度完成get和put操作。然而,HashMap的内部实现包含多个复杂的机制,如哈希函数、冲突解决、扩容策略等,这些都是确保其高效性能的关键因素。
本篇文章将深入探讨
HashMap的各种方面,包括其基础介绍、常见用法、工作原理以及源码解析。我们将从HashMap的基本特性和构造函数入手,逐步揭示其内部数据结构和方法的实现细节。同时,我们也会分析其性能特点和可能的优化策略,以帮助读者更好地理解和使用HashMap。
通过对
HashMap的全面解读,希望读者能够深入掌握这一关键集合类的工作机制,从而在实际开发中做出更加合理的选择和优化。无论你是刚刚接触 Java 集合框架的新手,还是希望深入了解其实现细节的资深开发者,本篇文章都将为你提供有价值的参考和指导。
文章目录
@[toc]1、HashMap 概述2、HashMap 底层数据结构1.1、JAVA7 实现1.2、JAVA8 实现1.3、源码解读
3、HashMap 的扩容机制3.1、什么时候触发扩容?3.2、JDK7 中的扩容机制3.3、JDK8 的扩容机制3.4、JDK7 的元素迁移3.5、JDK8 的元素迁移3.6、源码解读3.6.1、`resize` 方法3.6.2、`transfer` 方法3.6.3、`indexFor` 方法3.6.4、`ensureCapacity` 方法3.6.5、`addEntry` 方法
4、HashMap 相关知识点4.1、HashMap 的线程不安全4.2、关于 LinkedHashMap4.2.1、基本特性4.2.2、构造函数4.2.3、主要特性和方法4.2.4、与 `HashMap` 的区别4.2.5、示例代码
1、HashMap 概述
HashMap 根据是一个键值对集合,采用 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。HashMap 最多只允许一条记录的键为 null。
HashMap 非线程安全,即任一时刻可以有多个线程同时写 HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使 HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap。
2、HashMap 底层数据结构
HashMap 的主体为数组,链表则是主要为了解决哈希冲突而存在的("拉链法"解决冲突)。
JDK1.8 之后 HashMap 的组成多了红黑树,在满足下面两个条件之后,会执行链表转红黑树操作,以此来加快搜索速度。
链表长度大于阈值(默认为 8)HashMap 数组长度超过 64
我们用下面这张图来介绍 HashMap 的结构。
1.1、JAVA7 实现
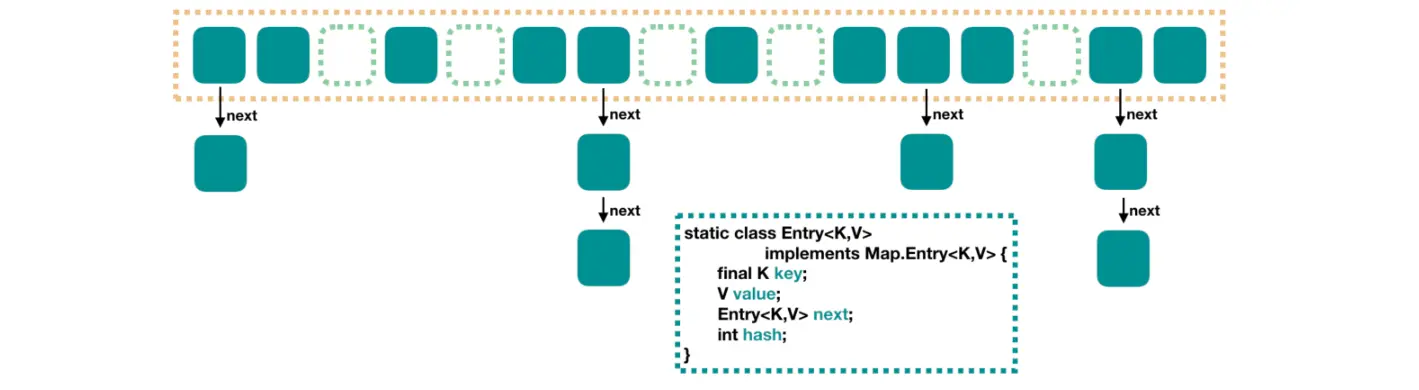
JDK1.8 之前 HashMap 里面是一个数组,数组中每个元素是一个单向链表。
上图中,每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:<code>key,value,hash 值和用于单向链表的 next
capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
loadFactor:负载因子,默认为 0.75。
threshold:扩容的阈值,等于 capacity * loadFactor
1.2、JAVA8 实现
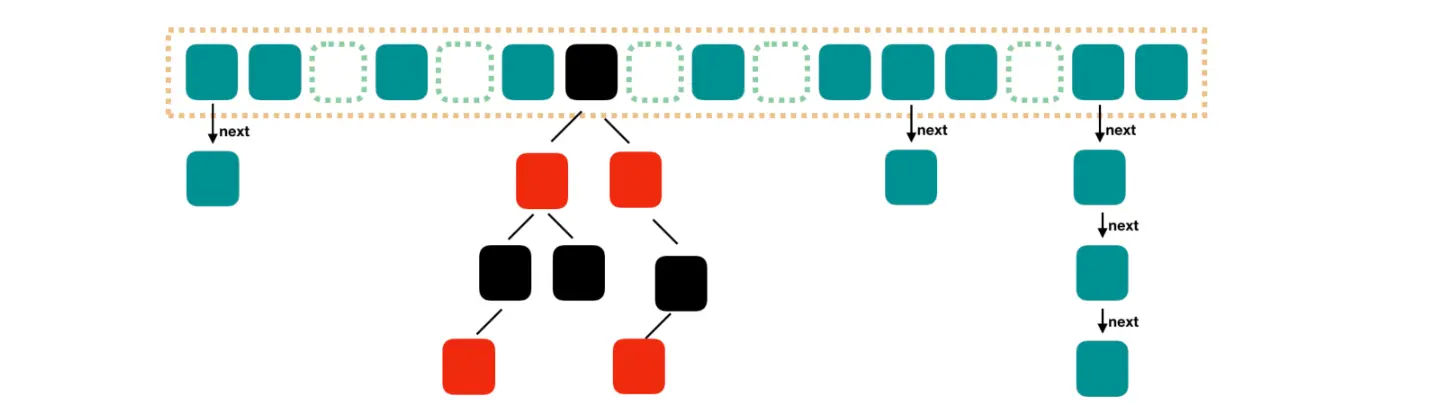
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 <code>O(n)。为了降低这部分的开销,在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
1.3、源码解读
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
/*
* 实现说明。
*
* 这个 Map 通常作为一个桶化的哈希表,但当桶过大时,它们会被转换为 TreeNodes 桶,
* 这些 TreeNodes 结构类似于 java.util.TreeMap 中的节点。大多数方法尝试使用普通桶,
* 但在适用的情况下会转到 TreeNode 方法(通过检查 instanceof 一个节点)。树形桶
* 可以像普通桶一样遍历和使用,但当过度拥挤时支持更快的查找。然而,由于在正常使用中
* 大多数桶不会过度拥挤,因此检查树桶的存在可能会延迟。
*
* 树桶(即所有元素都是 TreeNodes 的桶)主要按 hashCode 排序,但在哈希码相同的情况下,
* 如果两个元素的类 C 实现了 Comparable<C>,则使用它们的 compareTo 方法进行排序。
* (我们通过反射谨慎地检查泛型类型以验证这一点 -- 参见方法 comparableClassFor)。树桶的复杂性
* 在于提供了最坏情况下 O(log n) 的操作,当键的哈希码不同或可排序时,这一点尤其重要。这样,
* 性能在哈希码返回值分布不均或许多键共享哈希码时优雅地退化,只要它们也是 Comparable 的。
* (如果这两者都不适用,我们可能会浪费约两倍的时间和空间,但这通常由于糟糕的用户编程实践
* 导致,这些实践已经很慢,因此这种影响不大。)
*
* 由于 TreeNodes 大约是普通节点的两倍大小,我们只有在桶中包含足够多的节点时才使用它们
* (参见 TREEIFY_THRESHOLD)。当它们变得太小(由于删除或调整大小)时,它们会被转换回普通桶。
* 在哈希码分布良好的使用中,树桶很少使用。理想情况下,在随机哈希码下,桶中节点的频率遵循
* 泊松分布(http://en.wikipedia.org/wiki/Poisson_distribution),默认调整大小阈值为 0.75,
* 平均值约为 0.5,虽然由于调整大小的粒度较大,具有较大的方差。忽略方差,列表大小为 k 的预期
* 发生次数为 (exp(-0.5) * pow(0.5, k) / factorial(k))。前几个值为:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: 少于一千万分之一
*
* 树桶的根通常是其第一个节点。然而,有时(当前仅在 Iterator.remove 之后),根可能在其他地方,
* 但可以通过父链接恢复(方法 TreeNode.root())。
*
* 所有适用的内部方法都接受哈希码作为参数(通常从公共方法提供),以允许它们相互调用而不重新计算用户哈希码。
* 大多数内部方法还接受一个“tab”参数,这通常是当前表,但在调整大小或转换时可能是新表或旧表。
*
* 当桶列表被树化、拆分或撤销树化时,我们保持它们在相对访问/遍历顺序(即字段 Node.next),
* 以更好地保留局部性,并稍微简化拆分和遍历,这些操作会调用 iterator.remove。当使用比较器插入时,
* 为了在重新平衡期间保持总排序(或尽可能接近所需的排序),我们比较类和 identityHashCodes 作为平局打破者。
*
* 普通与树形模式的使用和转换由于存在子类 LinkedHashMap 而变得复杂。请参见下文,为插入、删除和访问定义了
* 钩子方法,以允许 LinkedHashMap 内部保持独立于这些机制。(这也要求某些工具方法传递一个 map 实例,
* 可能会创建新节点。)
*
* 这种类似并发编程的 SSA 基于编码风格有助于避免在所有弯曲的指针操作中出现别名错误。
*/
/**
* 默认初始容量 - 必须是 2 的幂。
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 即 16
/**
* 最大容量,当构造函数的参数指定了更高的值时使用。
* 必须是 2 的幂 <= 1<<30。
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 当构造函数中未指定时使用的负载因子。
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 使用树而不是列表的桶计数阈值。桶中的节点数至少达到这个阈值时,会将桶转换为树。
* 该值必须大于 2,且应至少为 8,以与树形移除时的回退假设匹配。
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 在调整大小操作期间,将(拆分的)桶撤销树化的桶计数阈值。应小于 TREEIFY_THRESHOLD,并且
* 最多为 6,以与删除时的收缩检测匹配。
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* 可以树化的最小表容量。(否则如果桶中节点过多,表将调整大小。)
* 应至少是 TREEIFY_THRESHOLD 的 4 倍,以避免调整大小和树化阈值之间的冲突。
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* 基本的哈希桶节点,用于大多数条目。(参见下文的 TreeNode 子类,以及 LinkedHashMap 的 Entry 子类。)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // 哈希码
final K key; // 键
V value; // 值
Node<K,V> next; // 下一个节点
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; } // 返回键
public final V getValue() { return value; } // 返回值
public final String toString() { return key + "=" + value; } // 返回键值对的字符串表示
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value); // 返回键值对的哈希码
}
public final V setValue(V newValue) {
V oldValue = value; // 保存旧值
value = newValue; // 设置新值
return oldValue; // 返回旧值
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false; // 返回是否相等
}
}
}
源码解读:
HashMap 类概述:
HashMap 是一个基于哈希表的 Map 实现。它允许使用键值对存储数据,键和值都可以是任意对象;它实现了 Map 接口,允许通过键来存取值。它还实现了 Cloneable 和 Serializable 接口,支持克隆和序列化。 内部结构和工作原理:
桶化哈希表:HashMap 使用桶(数组)来存储键值对。每个桶中的节点链表用于处理哈希冲突;树形桶:当一个桶中的节点数达到 TREEIFY_THRESHOLD(8),桶会被转化为树结构(TreeNode)。这样可以提供更快的查找速度;转换条件:如果桶中的节点数下降到 UNTREEIFY_THRESHOLD(6),树形桶会被转换回普通桶。 关键常量:
DEFAULT_INITIAL_CAPACITY:默认初始容量为 16;MAXIMUM_CAPACITY:最大容量为 2302^{30}230;DEFAULT_LOAD_FACTOR:默认负载因子为 0.75f,用于控制桶的扩容;TREEIFY_THRESHOLD 和 UNTREEIFY_THRESHOLD:控制桶是否转为树结构的阈值。 Node 类:
Node 类是 HashMap 中的基本节点类。每个节点包含键、值、哈希码和指向下一个节点的引用;equals 和 hashCode 方法用来比较节点和计算哈希码,确保 HashMap 的一致性和性能。
3、HashMap 的扩容机制
为了方便说明,这里明确几个名词:
capacity :即容量,默认16。loadFactor :加载因子,默认是0.75threshold :阈值,阈值=容量*加载因子。默认12。当元素数量超过阈值时便会触发扩容
3.1、什么时候触发扩容?
一般情况下,当元素数量超过阈值时便会触发扩容。每次扩容的容量都是之前容量的2倍
3.2、JDK7 中的扩容机制
JDK7 的扩容机制相对简单,有以下特性:
空参数的构造函数:以默认容量、默认负载因子、默认阈值初始化数组。内部数组是空数组。有参构造函数:根据参数确定容量、负载因子、阈值等。第一次 put 时会初始化数组,其容量变为不小于指定容量的2的幂数。然后根据负载因子确定阈值。如果不是第一次扩容,则新阈值 = 新容量 X 负载因子
3.3、JDK8 的扩容机制
JDK8 的扩容做了许多调整。
HashMap 的容量变化通常存在以下几种情况:
空参数的构造函数:实例化的 HashMap 默认内部数组是 null,即没有实例化。第一次调用 put 方法时,则会开始第一次初始化扩容,长度为16。有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的2的幂数,将这个数设置赋值给阈值(threshold)。第一次调用put方法时,会将阈值赋值给容量,然后让 阈值 = 容量 X 负载因子(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!)如果不是第一次扩容,则容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,负载因子还是不变)
此外还有几个细节需要注意:
首次 put 时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;不是首次 put,则不再初始化,直接存入数据,然后判断是否需要扩容;
3.4、JDK7 的元素迁移
JDK 7中,HashMap 的内部数据保存的都是链表。因此逻辑相对简单:在准备好新的数组后,map 会遍历数组的每个“桶”,然后遍历桶中的每个 Entity,重新计算其 hash 值(也有可能不计算),找到新数组中的对应位置,以头插法插入新的链表。
这里有几个注意点:
是否要重新计算hash值的条件这里不深入讨论,读者可自行查阅源码。因为是头插法,因此新旧链表的元素位置会发生转置现象。元素迁移的过程中在多线程情境下有可能会触发死循环(无限进行链表反转)。
3.5、JDK8 的元素迁移
JDK8则因为巧妙的设计,性能有了大大的提升:由于数组的容量是以2的幂次方扩容的,那么一个Entity在扩容时,新的位置要么在原位置,要么在 原长度+原位置 的位置。原因如下图:
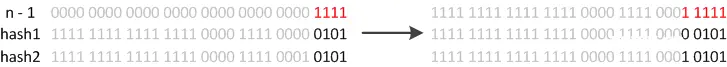
数组长度变为原来的2倍,表现在二进制上就是多了一个高位参与数组下标确定。此时,一个元素通过hash转换坐标的方法计算后,恰好出现一个现象:最高位是0则坐标不变,最高位是1则坐标变为“10000+原坐标”,即“原长度+原坐标”。如下图:
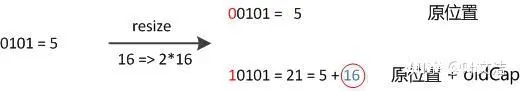
因此,在扩容时,不需要重新计算元素的hash了,只需要判断最高位是1还是0就好了。
JDK8在迁移元素时是正序的,不会出现链表转置的发生。如果某个桶内的元素超过8个,则会将链表转化成红黑树,加快数据查询效率。
3.6、源码解读
在 HashMap 的实现中,扩容机制是一个关键的部分,用于保持 HashMap 的性能,防止哈希表过载。扩容时,HashMap 会将当前表的容量翻倍,并重新计算每个节点的索引,将其重新放入新的表中。扩容是一个昂贵的操作,因此 HashMap 使用负载因子来控制扩容的频率,避免频繁的扩容操作。扩容操作通常在添加新元素时触发,当 HashMap 的大小超出预设的阈值时进行。
这些方法和机制一起确保了 HashMap 在大数据量下的性能和效率。扩容机制主要涉及到以下几个方法和步骤:
3.6.1、resize 方法
resize 方法是 HashMap 扩容的核心方法。当哈希表的负载因子超过设定阈值时,HashMap 会调用 resize 方法来扩容。扩容的过程包括以下几个步骤:
java
复制代码
void resize(int newCapacity) {
Node<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Node<K,V>[] newTable = (Node<K,V>[]) new Node[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int) (newCapacity * loadFactor);
}
解释:
newCapacity:新的容量,即扩容后的大小。oldTable:原始的哈希表。newTable:新的哈希表,大小为 newCapacity。transfer 方法:负责将原哈希表中的所有节点转移到新哈希表中。
3.6.2、transfer 方法
transfer 方法负责将旧的哈希表中的节点移动到新的哈希表中,同时进行再哈希操作:
java
复制代码
void transfer(Node<K,V>[] newTable) {
Node<K,V>[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; ++j) {
Node<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Node<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
解释:
src:旧的哈希表。newCapacity:新哈希表的容量。indexFor 方法:计算节点在新哈希表中的索引。e.next:节点的下一个节点。newTable[i]:将节点添加到新哈希表中。
3.6.3、indexFor 方法
indexFor 方法用来计算给定哈希码的节点在新哈希表中的索引位置:
java
复制代码
static int indexFor(int hash, int length) {
return hash & (length - 1);
}
解释:
hash:节点的哈希码。length:哈希表的长度。hash & (length - 1):将哈希码与哈希表长度减一进行按位与运算,得到索引位置。
3.6.4、ensureCapacity 方法
ensureCapacity 方法用于确保 HashMap 的容量足够,避免在添加新元素时触发不必要的扩容:
java
复制代码
public void ensureCapacity(int minCapacity) {
int threshold = table.length * loadFactor;
if (minCapacity > threshold) {
resize(table.length * 2);
}
}
解释:
minCapacity:期望的最小容量。threshold:当前负载因子下的阈值。如果 minCapacity 大于 threshold,则调用 resize 方法扩容。
3.6.5、addEntry 方法
addEntry 方法用于在 HashMap 中添加新节点。如果插入操作导致负载因子超过阈值,会触发扩容:
java
复制代码
void addEntry(int hash, K key, V value, int bucketIndex) {
Node<K,V> e = table[bucketIndex];
table[bucketIndex] = new Node<>(hash, key, value, e);
if (size++ >= threshold) {
resize(2 * table.length);
}
}
解释:
hash:节点的哈希码。key:节点的键。value:节点的值。bucketIndex:节点在桶中的索引位置。如果 size(当前节点数量)超过了 threshold,则调用 resize 方法扩容。
4、HashMap 相关知识点
4.1、HashMap 的线程不安全
HashMap 在 Java 中是一个非常流行的集合类,用于存储键值对。然而,HashMap 是线程不安全的,这意味着在多线程环境中对同一个 HashMap 实例的并发操作可能会导致不一致的状态或数据损坏。下面是 HashMap 线程不安全的主要原因及其影响:
线程不安全的原因:
非同步操作:HashMap 的所有方法都是非同步的。这意味着如果多个线程同时对一个 HashMap 实例进行读写操作,可能会导致数据竞争和不一致的问题(在 Jdk1.8 中,在多线程环境下,会发生数据覆盖的情况)。
扩容过程中的竞态条件:当 HashMap 扩容时(即调整内部数组的大小),需要重新计算每个元素的位置并将它们移动到新的数组中。如果在扩容过程中另一个线程正在修改哈希表,可能会导致数据丢失、重复或丢失(在 Jdk1.7 中,在多线程环境下,扩容时会造成环形链或数据丢失。)。
链表操作:在 HashMap 中,哈希冲突通过链表解决。多个线程同时访问或修改同一个桶的链表可能会导致链表结构损坏。例如,一个线程可能在另一个线程遍历链表时修改链表,这会导致遍历过程中的异常或丢失数据。
线程不安全的影响:
数据不一致:并发写入操作可能会导致数据丢失或覆盖,导致 HashMap 中的数据不一致。例如,两个线程同时插入相同的键,可能会导致只保留一个值,而另一个值被丢弃。
性能问题:在多线程环境中,如果多个线程频繁对 HashMap 进行操作,可能会导致大量的锁竞争,影响程序性能。
无限循环或抛出异常:在扩容或操作链表时,多个线程并发操作可能导致链表结构混乱,甚至可能导致无限循环或抛出 ConcurrentModificationException 异常。Ps:关于死循环的问题,在 Java8 中个人认为是不存在了,在 Java8 之前的版本中之所以出现死循环是因为在resize的过程中对链表进行了倒序处理;在Java8中不再倒序处理,自然也不会出现死循环。
线程安全的替代方案:
HashMap 在设计时并未考虑多线程的并发问题,因此在多线程环境中使用时需要特别小心。为了避免线程不安全的问题,可以使用 ConcurrentHashMap 或通过 Collections.synchronizedMap 方法来确保线程安全。了解 HashMap 的线程不安全特性以及合适的替代方案,可以帮助开发者在并发编程中选择正确的数据结构。
为了在多线程环境中使用类似于 HashMap 的数据结构,Java 提供了几种线程安全的替代方案:
ConcurrentHashMap:ConcurrentHashMap 是 java.util.concurrent 包中的类,提供了线程安全的哈希表实现。它通过将数据分段并使用锁分段技术来实现并发操作的高效支持。
ConcurrentHashMap<K, V> map = new ConcurrentHashMap<>();
Collections.synchronizedMap:Collections.synchronizedMap 方法可以将任何 Map 包装成线程安全的 Map。这种包装会对所有的操作加锁,从而确保线程安全。
Map<K, V> synchronizedMap = Collections.synchronizedMap(new HashMap<>());
ReadWriteLock:如果应用场景涉及到大量的读操作和少量的写操作,可以考虑使用 ReadWriteLock(如 ReentrantReadWriteLock),它允许多个线程同时读操作,但在写操作时进行排他锁定。
ReadWriteLock lock = new ReentrantReadWriteLock();
Lock readLock = lock.readLock();
Lock writeLock = lock.writeLock();
4.2、关于 LinkedHashMap
在使用 HashMap 的时候,可能会遇到需要按照当时 put 的顺序来进行哈希表的遍历。但我们知道 HashMap 中不存在保存顺序的机制。
LinkedHashMap 专为此特性而生。在 LinkedHashMap 中可以保持两种顺序,分别是插入顺序和访问顺序,这个是可以在 LinkedHashMap 的初始化方法中进行指定的。相对于访问顺序,按照插入顺序进行编排被使用到的场景更多一些,所以默认是按照插入顺序进行编排。
LinkedHashMap 相对于 HashMap,增加了双链表的结果(即节点中增加了前后指针),其他处理逻辑与 HashMap 一致,同样也没有锁保护,多线程使用存在风险。
4.2.1、基本特性
继承与实现:
继承自 HashMap:LinkedHashMap 继承了 HashMap 的所有功能,包括哈希表的存储和操作。实现 Map 接口:LinkedHashMap 实现了 Map 接口,因此可以用作常规的键值对映射。
链表结构:
LinkedHashMap 使用双向链表维护元素的插入顺序或访问顺序。这意味着可以在迭代时按照插入顺序或访问顺序遍历元素。
4.2.2、构造函数
LinkedHashMap 提供了几种构造函数:
默认构造函数:
LinkedHashMap<K, V> map = new LinkedHashMap<>();
指定初始容量:
LinkedHashMap<K, V> map = new LinkedHashMap<>(int initialCapacity);
指定初始容量和负载因子:
LinkedHashMap<K, V> map = new LinkedHashMap<>(int initialCapacity, float loadFactor);
指定初始容量、负载因子和顺序类型:
LinkedHashMap<K, V> map = new LinkedHashMap<>(int initialCapacity, float loadFactor, boolean accessOrder);
accessOrder 为 true 时,表示按照访问顺序排列元素(最近访问的元素会移动到链表的末尾),为 false 时,按照插入顺序排列元素。
4.2.3、主要特性和方法
插入顺序:如果构造时 accessOrder 为 false(默认值),LinkedHashMap 维护元素的插入顺序。即迭代时元素的顺序与插入顺序一致。
访问顺序:如果构造时 accessOrder 为 true,LinkedHashMap 维护元素的访问顺序。即每次访问元素(通过 get 方法)时,该元素会被移动到链表的末尾,确保迭代顺序是最近访问顺序。
LinkedHashMap 特有方法:
boolean containsValue(Object value):检查 LinkedHashMap 是否包含指定的值。V get(Object key):获取指定键的值,并根据 accessOrder 参数更新访问顺序。void put(K key, V value):插入一个新的键值对或更新现有的键值对。Set<Map.Entry<K, V>> entrySet():返回一个包含 LinkedHashMap 中所有键值对的 Set 视图。
4.2.4、与 HashMap 的区别
顺序维护:HashMap 不保证元素的顺序,而 LinkedHashMap 保证插入顺序或访问顺序。
性能:LinkedHashMap 的性能通常稍微低于 HashMap,因为它需要维护额外的链表结构。然而,LinkedHashMap 提供了对元素顺序的控制,这是 HashMap 所不具备的。
用途:LinkedHashMap 适用于需要保持元素顺序的情况,例如实现缓存机制时,需要按照访问顺序维护元素。
4.2.5、示例代码
以下是使用 LinkedHashMap 的示例:
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapExample {
public static void main(String[] args) {
// 按照插入顺序
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
map.put("One", 1);
map.put("Two", 2);
map.put("Three", 3);
// 按照访问顺序
LinkedHashMap<String, Integer> accessOrderMap = new LinkedHashMap<>(16, 0.75f, true);
accessOrderMap.put("One", 1);
accessOrderMap.put("Two", 2);
accessOrderMap.put("Three", 3);
// 访问元素,更新访问顺序
accessOrderMap.get("Two");
System.out.println("Insertion order:");
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
System.out.println("\nAccess order:");
for (Map.Entry<String, Integer> entry : accessOrderMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}
输出:
Insertion order:
One: 1
Two: 2
Three: 3
Access order:
One: 1
Three: 3
Two: 2
总的来说,LinkedHashMap 是 HashMap 的一个扩展,增加了对元素顺序的维护。它适用于需要保持插入顺序或访问顺序的场景。虽然性能略低于 HashMap,但其顺序保证是其独特的优势。如果你的应用场景需要按顺序遍历 Map,LinkedHashMap 是一个合适的选择。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。