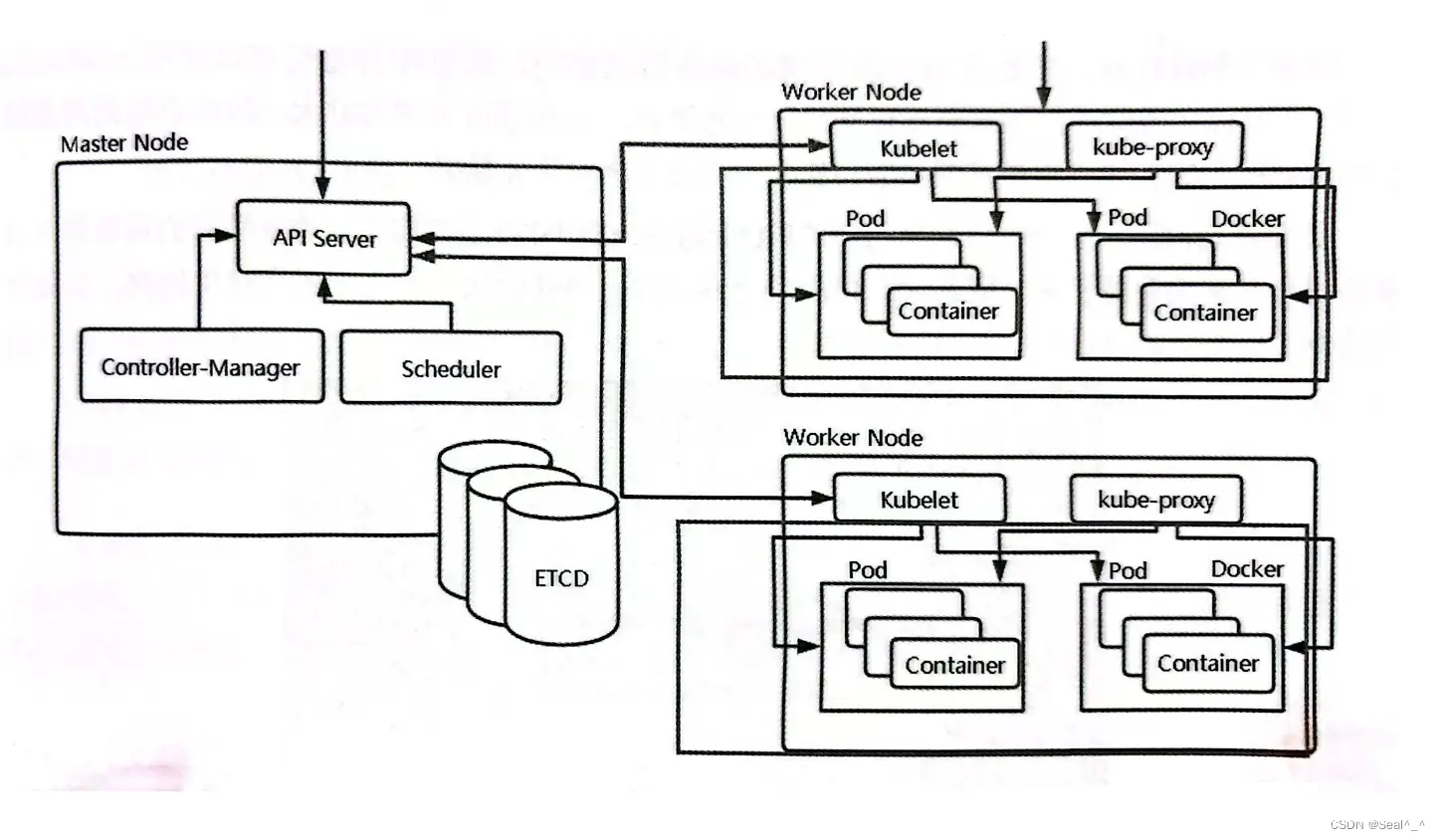
本文详细阐述了Kubernetes集群的部署过程,包括资源准备、主机环境设置、Docker安装、Kubeadm、Kubelet和Kubectl的安装与配置,以及初始化Master节点、安装网络插件、Worker节...

本文章主要介绍在Centos系统,虚拟机上安装zookeeper用来单机部署或集群部署,可为大数据组件或ambari管理中使用。教程安装的是Zookeeper3.4.6版本,安装其他版本的也可以参考该文档。...
Flask+Pyecharts+大数据集群:数据可视化大屏的实现一、相关技术介绍及相关模块安装1.相关技术介绍(1)Flask(2)Pyecharts(3)大数据集群(4)Pycharm编程工具2.相关模块安装...

使用Ansible为集群初始化并配置免密前情概要集群的36台服务器安装好了centos7.9设置了统一的root密码,并配置好了主机名和ip。现在需要实现:每台关闭防火墙和selinux删除安装操作系统时创建的默认用户user及其家目录将集群的36台...
公司之前一直使用的是CentOS系统作为测试、开发、生产环境的基础系统镜像,由于最近的CentOS的镜像彻底终止维护之后,我们在为后续项目的基础系统镜像选型进行的调研,最好是可以平替的进行类似系统的移植,经过...

集群配置(clusterconfig)所有节点共同维护同一份集群配置,共享集群内节点的相关配置信息:{node_1={addr="127.0.0.1:10014",expire="2024-01-0100:...
k8s集群的搭建_ubuntuserverkubernetes1.30...
因为我只有一台服务器,我使用的是,所有我采用的是通过安装虚拟机的方式实现集群搭建,先把需要的配置环境拉取下来,然后再通过虚拟机的克隆的方式直接把配置克隆到新的服务器上,减少重复下载。通过在ubuntu服务器上安装...

本节对ApacheKudu进行部署,通过DockerCompose配置文件,用于部署ApacheKudu集群。ApacheKudu是一个用于快速分析和实时数据处理的分布式列式存储系统,常与A...

在Kubernetes面试中,网络是一个重要的主题。理解Kubernetes网络模型、服务发现、网络策略等概念对候选人来说至关重要。以下是一些常见的Kubernetes网络面试题及其答案,帮助你准备面...