Flink CDC:基于 Apache Flink 的流式数据集成框架
Apache Flink 2024-08-27 08:07:02 阅读 56
摘要:本文整理自阿里云 Flink SQL 团队研发工程师于喜千(yux)在 SECon 全球软件工程技术大会中数据集成专场沙龙的分享。内容主要为以下四部分:
Flink CDC 开源社区介绍;
Flink CDC 的演进历史;
Flink CDC 3.x 核心特性解读;
基于Flink CDC 的实时数据集成实践。
1. Flink CDC 开源社区介绍
1.1 Flink CDC 的演进历史
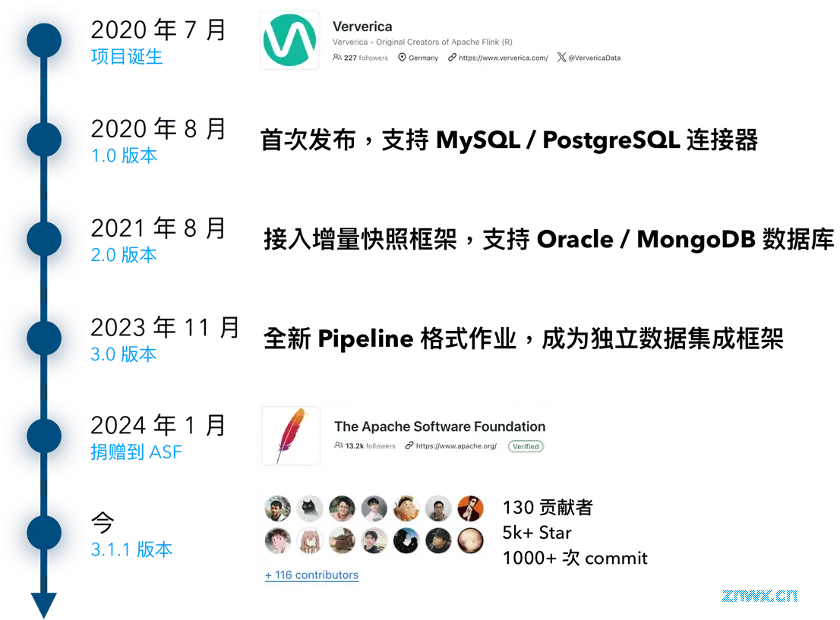
Flink CDC 最早的发展就始于 GitHub 开源社区。自 2020 年 7 月开始,项目在 Ververica 公司的 GitHub 仓库下以 Apache 2.0 协议开放源代码。并提供了从主流 MySQL 和 PG SQL 数据库中捕获变化数据的能力。2.0 版本引入了运行更高效、更稳定、支持故障恢复的增量快照框架,并且丰富了源数据库支持范围,能够从 Oracle、MongoDB 实时抽取数据。
去年 11 月发布的 CDC 3.0 版本引入了全新的 YAML pipeline 作业,能够作为一个独立的端到端数据集成框架使用,通过极简的语法更轻松地描述数据集成作业。
1.2 Flink CDC 社区现状
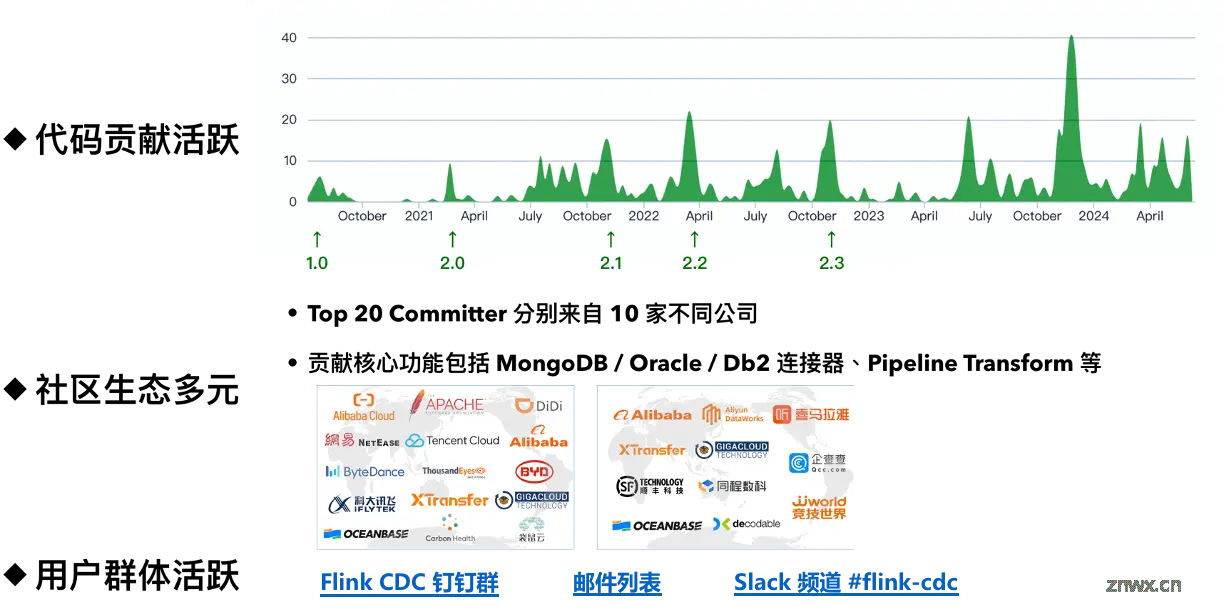
2024 年年初,Flink CDC 正式作为 Flink 的一个子项目加入 Apache 软件基金会,遵循 ASF 的标准规范流程进行新版本的开发迭代,截至目前最新的 3.1.1 版本,已经积累了来自一百三十多位贡献者的一千余次 commit、GitHub 上收获超过五千颗 star。
Flink CDC 社区同样有着极为多元的生态;GitHub Top 20 代码贡献者分别来自 10 家不同的公司,它们贡献了 MongoDB、Oracle、Db2、OceanBase 等连接器及 Pipeline Transform 等核心功能。
在加入 Apache 软件基金会后,Flink CDC 也在原有钉钉用户交流群的基础上、使用 Apache Flink 邮件列表、及面向国际用户的 Slack 频道等多样化的方式,与社区用户保持沟通、交流答疑、吸收新功能建议。
2. Flink CDC 的演进历史
2.1 CDC 技术简介
CDC(Change Data Capture,变化数据捕获)是一种实时监控数据变更,并将描述数据变化的记录实时写入数据流中的技术。在 Flink CDC 的语境里,通常特指捕获外部数据库中的增删改等操作带来的变更。CDC 技术可以被用于进行一对一的数据同步,例如自动提取主数据库中的变化并同步到备份数据库,以便进行数据备份或迁移;CDC 也支持一对多、多对一的数据分发,将源表按规则进行拆分和合并;也支持在采集数据(Extraction)后进行转换(Transform)并加载(Load)到数据仓库或数据湖中。
数据库变化捕获(CDC)的有效实施策略主要包括两种:一是定期查询方法(Query-based CDC),二是基于日志的实时处理(Log-based CDC)。前者通过周期性地直接查询数据库来探测变化,此法简单但受限于查询频率与延迟,难以满足实时性要求,尤其在资源消耗与低延迟需求的流处理场景下非最优选择。相比之下,后者利用了数据库自带的日志机制(如 MySQL 的 Binlog、Oracle 的 Redo Log、MongoDB 的 OpLog)来捕捉变更。该方式通过监听并解析这些连续更新的日志流,能够在数据更改发生时几乎无延迟地捕获到变化,无需频繁查询数据库本身。此过程不仅减轻了数据库压力,而且由于日志的顺序性和完备性,能确保每个变更事件精确地被消费一次,实现“恰好一次”的处理语义,保障了数据处理的一致性和可靠性。Flink CDC 从一开始就采用这一策略,融合了基于日志的实时 CDC 技术与 Flink 引擎提供的 Checkpoint 机制,确保了数据处理过程中的一致性与容错能力,为实时数据分析与处理提供了一个高效、可靠的解决方案。
2.2 早期 CDC 技术局限
早期的各种 CDC 实现的实用性并不理想。以 Flink CDC 1.x 版本为例,主要问题包括以下几个方面:
快照处理效率低下:Flink CDC 1.x 在执行数据库快照时,仅支持单一并发模式访问源数据库,导致快照生成过程可能耗时数小时乃至更久。
需要获取数据库锁和表锁:为了确保快照后能无缝衔接增量数据处理,需要精确记录日志的读取位置。但这一过程需要使用FLUSH TABLES WITH READ LOCK命令,它会锁定全局数据库,在最坏情况下可能导致数据库的所有读写操作全部挂起,甚至引起服务中断。
缺乏故障恢复机制:快照阶段在遭遇网络故障、数据不一致等异常情况时,缺乏有效的故障恢复策略,迫使整个快照过程从头开始。结合前述快照的低效性,这一缺陷极大地降低了系统的稳定性和实用性,使得在实际生产环境部署时风险较高,难以与成熟的数据同步解决方案相竞争。
2.3 Flink CDC 接入增量快照框架
真正让 Flink CDC 开始变得更加易用,并且相比其他框架具备一定优势的是 CDC 2.0 版本中的几项框架层面的大更新。首先,针对 MySQL、MongoDB 等主流常用数据库,实现了增量快照算法的改造,终于支持了任意多并发快照读取、无需对数据库、数据表进行加锁,也一并支持了 checkpoint 和故障恢复功能;依据 Netflix 的一篇 DBlog 论文提出的无锁快照的算法,实现了不锁表、多并发的情况下正确完成一致性快照的功能。下面我来详细介绍一下这些改进的实现。

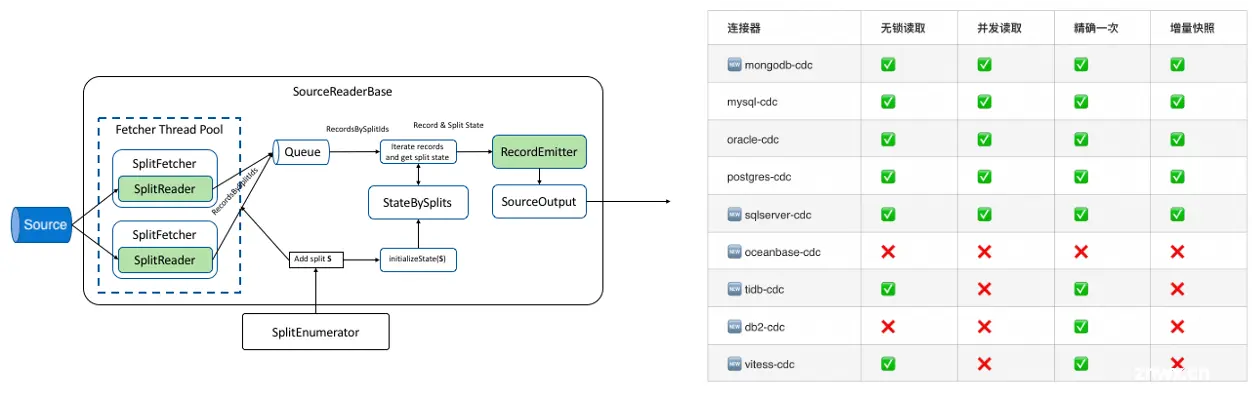
早期的Flink CDC 基于 Flink 的原始 SourceFunction API 实现,要求开发者自行实现并发处理、数据分片、多线程任务协调及状态管理等底层细节,大大增加了实现难度和维护成本。FLIP-27 提案则引入了新的 Flink Source API 架构,将数据源的读取架构拆分为两大核心组件:SplitEnumerator 与 Reader。SplitEnumerator 负责数据源的逻辑划分,将其细分为多个独立的处理单元(分片),而 Reader 则负责从给定的分片中抽取数据,这一设计极大地提升了抽象层次和灵活性。
在 Flink CDC 增量快照框架的实现中,SplitEnumerator 会在快照初始化阶段根据数据库特性,尽可能均匀地将待捕获的数据集切分为多个快照分片。例如,MongoDB CDC 会利用数据库提供的 splitVector 函数按数据量进行均匀分割;MySQL CDC 则采取抽样策略评估每行数据大小,依据主键进行均匀产生分片。随后,这些分片被 Flink 引擎调度分发至多个并行的 Reader 实例,独立执行并发数据读取,显著增强了快照处理的并发效率与整体吞吐量。此架构还允许每个 Reader 维护独立的内部状态并持久化至Checkpoint 中,确保系统在遭遇故障时,能够恢复至最近一次的状态,而无需从头执行快照,极大地增强了系统的健壮性和容错能力。
CDC 2.x 系列版本系列历经五次小版本迭代,在不断维持最新 Flink 版本兼容性的基础上,在原本支持的 MySQL、Oracle、PG 数据库的基础上扩展 CDC 数据源支持,并将更多数据源接入了高效的增量快照框架。
3. Flink CDC 3.0 核心特性解读
3.1 Flink CDC 2.x 版本回顾
回顾 Flink CDC 2.x 的最终版本,从最开始的 CDC Connectors for Flink 开始历经三年多发展,本质上仍然是依赖 Flink 运行时的一组连接器工具类库,用户必须编写 SQL 作业或 Java DataStream 作业方可使用,这在用户体验上不够直观友好。此外,Flink CDC 受制于 Flink Source 的职责约束,难以在保持与现有下游连接器及 SQL 框架兼容的同时对事件格式进行扩展或调整,难以支持诸如表结构变更、数据路由、持久化存储、自动扩展等进阶能力。
例如,使用 Flink CDC 2.x 调整表结构过程涉及到多个系统组件的手动执行:暂停作业、记录 savepoint、同步更新上下游数据库 Schema、最后从保存点恢复作业。这一过程不仅引入了数据同步的延迟,还存在因 Schema 不同步导致的作业稳定性风险,而这些问题超出了 Flink CDC 作为单一 Source connector 所能解决的能力范畴。
此外,项目的开源属性和中立性亦成为关注点。Flink CDC Connector 的代码库及版权属于 Ververica 商业实体,与 Apache Software Foundation 及 Flink Committee 在法律上相互独立,让用户在商业化使用、外部贡献者考虑代码贡献时带来一些疑虑。
3.2 Flink CDC 3.0 的设计目标


CDC 3.0 希望能够在保留已有的成熟代码库的基础上,解决上述这些关键的痛点问题。首先,在已有的 SQL 和 Java API 的基础上,提供全新的 YAML API,作为一种主要面向数据集成用户的使用方式,支持对数据摄取、变换、路由、写入的全过程进行自定义的描述。YAML 并非从头开始的重新实现,而是基于已有的成熟 API 的封装和增强。原有的 Table 和 DataStream API 仍然会被积极维护、增添新功能和修正错误,供具有高级数据处理需求的用户使用。
此外,YAML API 还提供了针对 Schema Evolution 表结构变更提供了支持。现在要修改 Schema 无需再重启作业;CDC 在从上游表中检测到 Schema 结构变更的事件后,会将表结构状态持久化到 State 中记录,并自动将兼容的变更应用到下游的 Sink 数据库中。CDC 3.0 为 Schema Evolution 功能提供了开箱即用的支持,只需要选用兼容的 Source 和 Sink 连接器,并且在 pipeline 配置项中打开 Schema Evolution 的开关即可。
最后,在完成上述新增功能演进之后,Flink CDC 被作为一个独立的流式数据集成框架,被捐赠进入 Apache 软件基金会,确保了项目管理和开发的规范和中立。
3.3 Flink CDC 3.0 核心架构
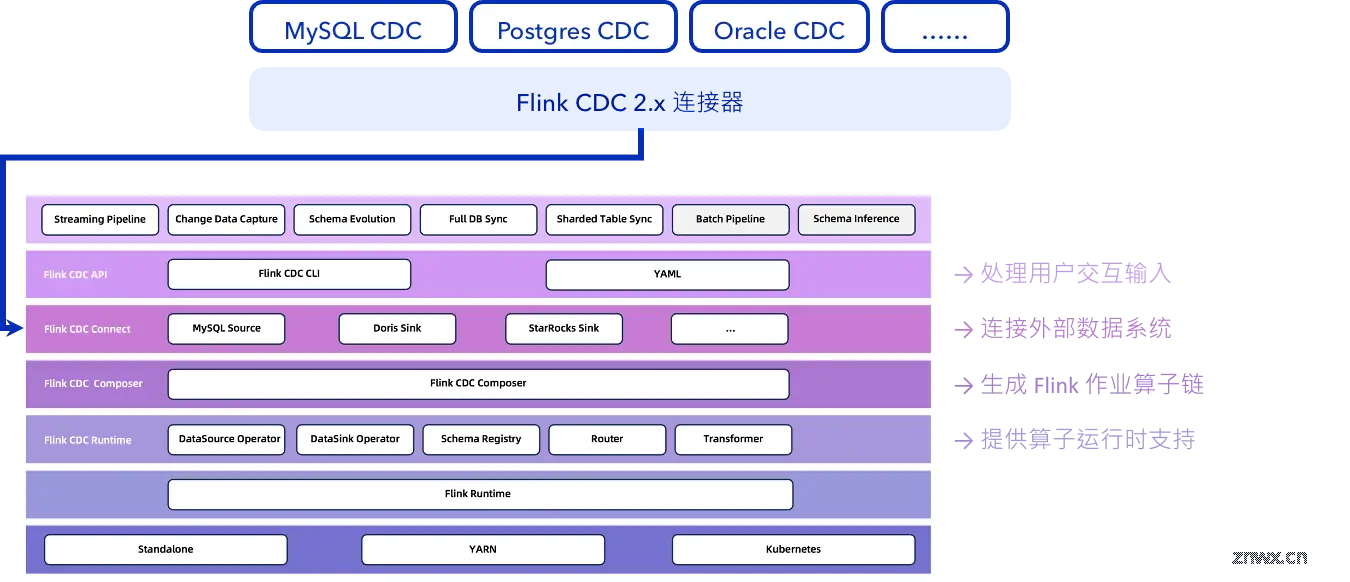
从软件架构上来说,3.0 版本之前的 Flink CDC 仅仅是一组 Flink Source 连接器的组合,无法独立使用;这些组件在版本更新后并没有被废弃,而是被用于实现 Flink CDC 3 版本中最为关键的连接层(Flink CDC Connect),它们用于支撑上层的 YAML pipeline 作业和 Flink CDC 命令行界面(Flink CDC CLI)的运行。在 Connect 层之下,是负责创建 Flink CDC 作业执行算子图、生成 Flink 任务的 Composer 层、以及在运行时为连接器提供 Schema Evolution、Transform 和 Route 等功能支持的 Runtime 层。上述的运行时模块均作为独立的 Flink 算子由 Flink Runtime 提供状态存储、生命周期管理等支撑。
Flink CDC 3.0 采用了无状态(stateless)的设计模式,不承担持久化任何额外状态的职责,保持了架构的简洁性与轻量化;在架构图中,也未引入一个单独的 CDC Server API 服务负责任务的生命周期管理,诸如初始化、执行与终止等关键功能均由Flink 原生引擎框架承担,且能够更好地利用 Flink 成熟且强大的作业管理与调度机制。此设计决策极大地简化了 Flink CDC 的部署架构与运维复杂度,消除了额外部署独立的“CDC服务”的需要。用户仅需提供一个可用的 Flink 集群环境,便能无缝集成并启动 Flink CDC 任务,无论该集群是配置为独立 Standalone 模式、运行于 YARN 之上,还是构建在 Kubernetes 之中。这种设计不仅强化了系统的灵活性与可扩展性,还充分利用了 Flink 现有的多样化部署能力,实现了与 Flink 生态系统深度且高效的整合。
3.4 Flink CDC 3.0 API 设计
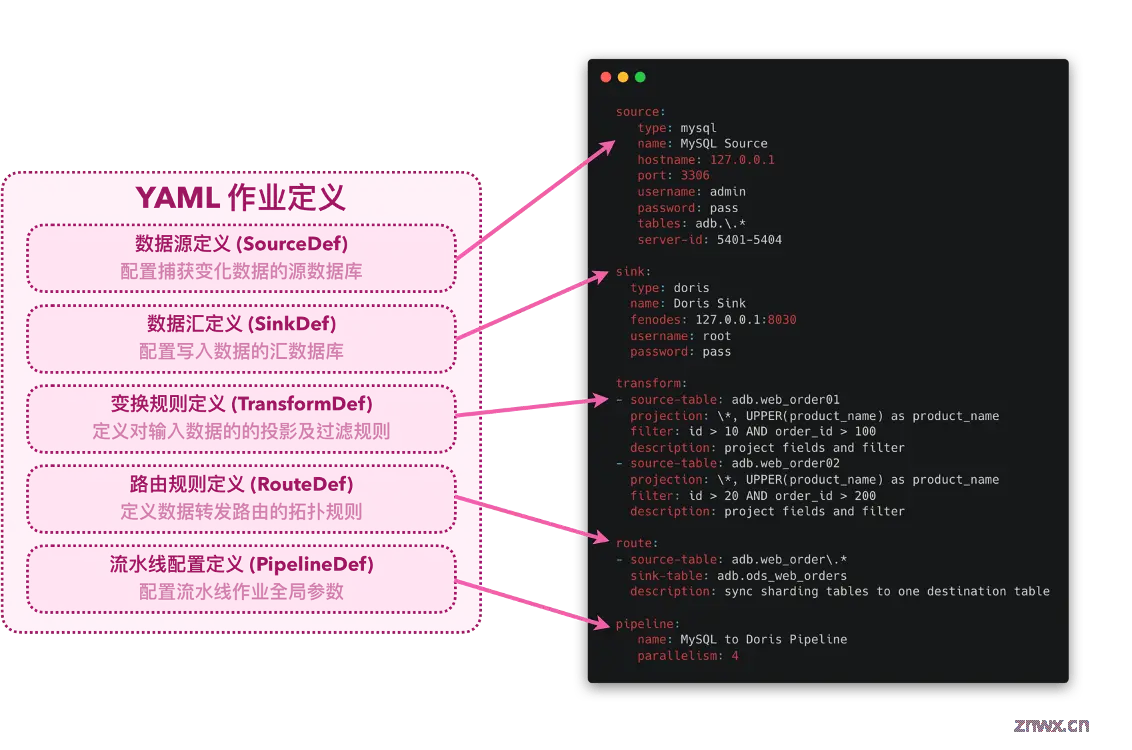
Flink CDC 3.0 引入了基于 YAML 的作业配置方式,采用基于配置的描述性语句全面地定义端到端的数据集成流程和 Pipeline 作业。这一设计围绕数据同步的核心要素展开,通过五大配置模块描述了源数据库配置、目标数据库设定、数据转换与过滤逻辑、数据路由策略,以及全局作业选项所需的信息。YAML Pipeline 的设计侧重于直观表达任务需求,而非技术实现细节,从而极大提升了 Pipeline 作业的抽象程度和易用性。相较于 Flink 的 DataStream API 与 Table API,YAML 配置方法在保留高级功能的同时,有效屏蔽了底层实现的复杂性,如数据结构处理、序列化/反序列化机制、网络传输细节等,使用户能够聚焦于数据集成任务本身,而非技术实现的细节。这种设计不仅降低了用户上手使用的难度,还促进了配置的可读性和维护性,提升了数据集成任务的配置效率与灵活性。
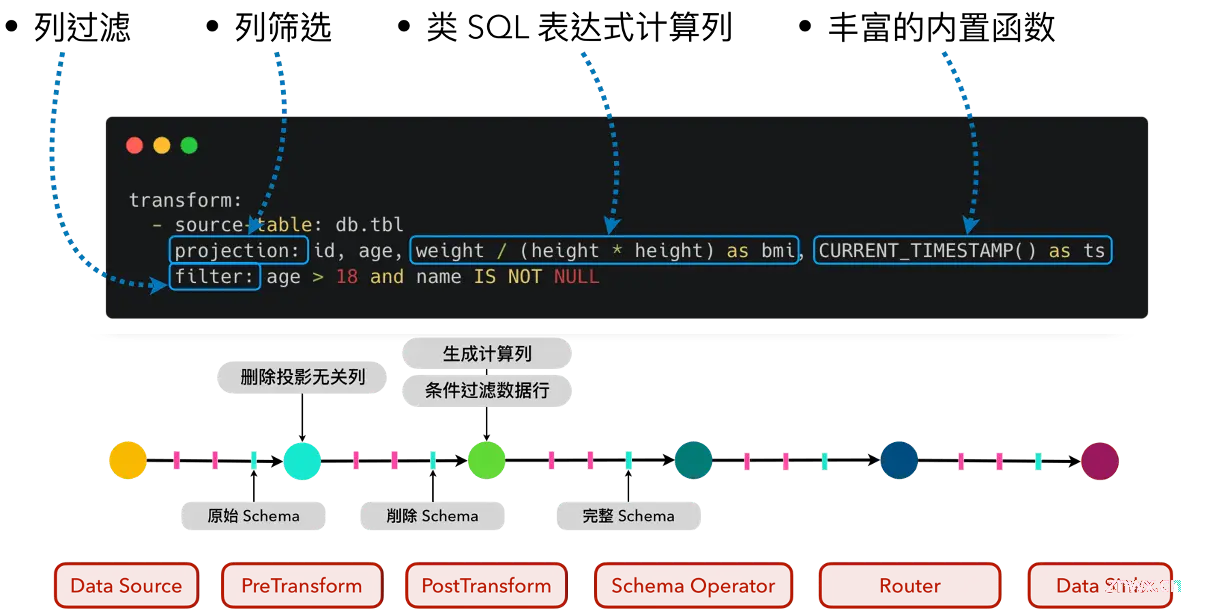
Flink CDC 3.0 通过引入强大的数据转换(Transform)支持,在确保配置简洁直观的同时,提供了丰富的数据处理和转换的能力。在 SQL 语句中编写的 SELECT、WHERE 等指令,或是 Java 代码里调用的 .map、.filter等算子表达式实现的转换逻辑,现在仅需 YAML 配置文件中撰写简洁的语句即可清楚地定义。这种设计不仅简化了开发流程,还显著提升了配置的可读性和维护性。转换规则使用类 SQL 的兼容表达式语法,允许用户直接在配置中执行列计算,同时集成了 Flink SQL 的 Scalar Function 库,涵盖了大部分 SQL 内置函数,确保了从传统 SQL Transform 任务向 YAML 配置模式平滑过渡的无缝体验。
技术实现层面,Transform 流程构建了一个高效的执行图:PreTransform 算子分析配置的转换规则,识别并筛选出需要处理的列——包括明确指定的输出列、计算列中引用的列,以及过滤条件涉及的列,从而提前优化数据流,剔除非必要数据,有效减小传输负担。后续的 PostTransform 算子则更加精细化地执行过滤与投影操作。首先,依据用户设定的过滤条件精确筛选数据行,随后,按照配置的投影规则计算填充新的列值,确保输出数据结构与预期方案匹配。
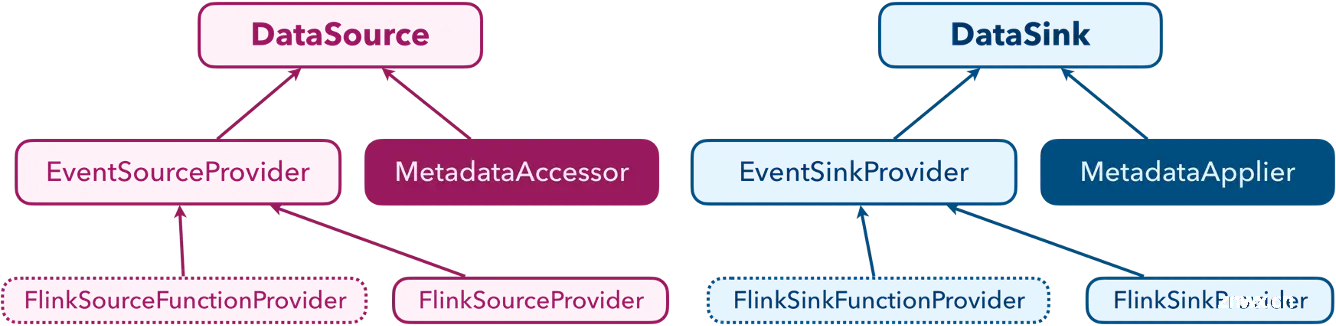
在设计实现核心的 Connect 连接层时,鉴于 Pipeline 作业需在已有的 CDC Source Connectors 基础上实现 Schema Evolution 等新特性,单纯沿用旧有接口显然无法满足需求。然而,完全摒弃既有生态的丰富资源并非明智之举,尤其是考虑到 Flink 生态系统中已经广泛存在的现有 Source 与 Sink 连接器。
为此,Flink CDC 3.0 定义了 DataSource与DataSink,他们是专为 3.0 版本新特性打造的,而涉及 Schema 元数据操作的复杂性则被封装于 MetadataAccessor 与 MetadataApplier 类中,使得数据读写的核心逻辑依旧能够无缝对接 Flink 既有的 Source 与 Sink API,极大地减轻了连接器迁移的工作负担。此外,通过使用 SourceProvider 与 SinkProvider 这一抽象层级,Flink CDC 实现了对 Flink 新旧 API 的双重兼容,包括对早期 Function API 的支持。实践证明,这一策略不仅加速了如 JDBC、Oceanbase、MaxCompute 等多样下游连接器的快速集成,同时也为未来连接器的扩展与迭代铺设了灵活且坚实的基石。
3.5 Flink CDC 3.0 Schema Evolution 功能
接下来介绍 CDC 3.0 重点支持的 Schema Evolution 功能。由于 Flink CDC 不为每条数据变更事件携带对应 Schema 的信息,因此保证并行执行作业时,确保注册中心中记录的 Schema 始终保持正确和一致非常重要,否则如果使用了错误版本的 Schema 对事件进行处理,会导致消息记录的序列化过程失败。
为了保证这一点,Flink CDC 规定了这样的 Schema 变更处理过程:
1、在作业的某一个 Schema Operator 节点收到表结构变更事件时,
2、Schema Operator 会立即阻塞来自上游的所有事件(包括数据变更事件和表结构变更事件),
3、并且向 Schema 注册表中心 Registry 报告;
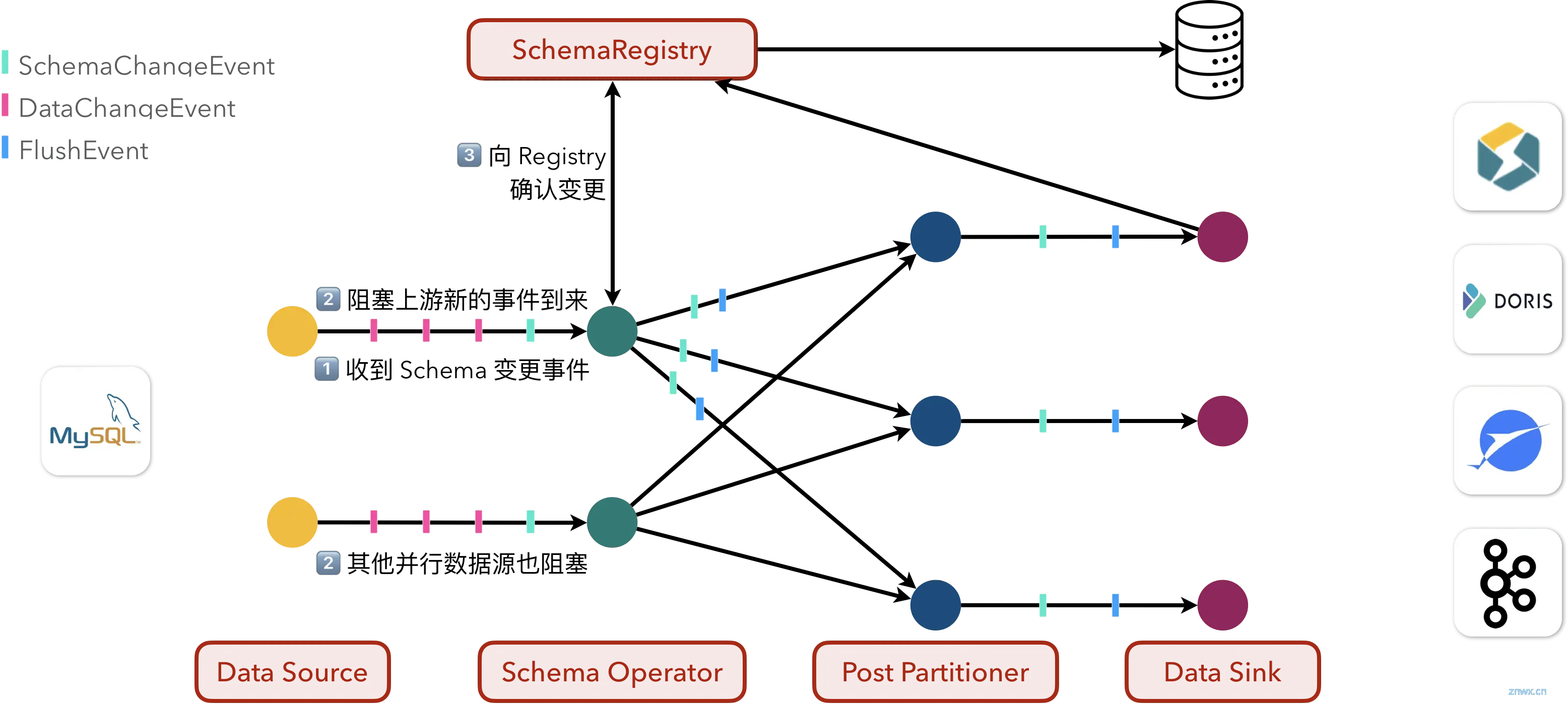
4、注册表中心在收到表结构变更请求后,会先向下游发送 FlushEvent,要求 Sink 将未提交的数据变更全部落盘;因为按照语义,必须在所有先前的、对应旧 Schema 信息的数据记录都正确落盘之后,方可开始应用一次结构变更。
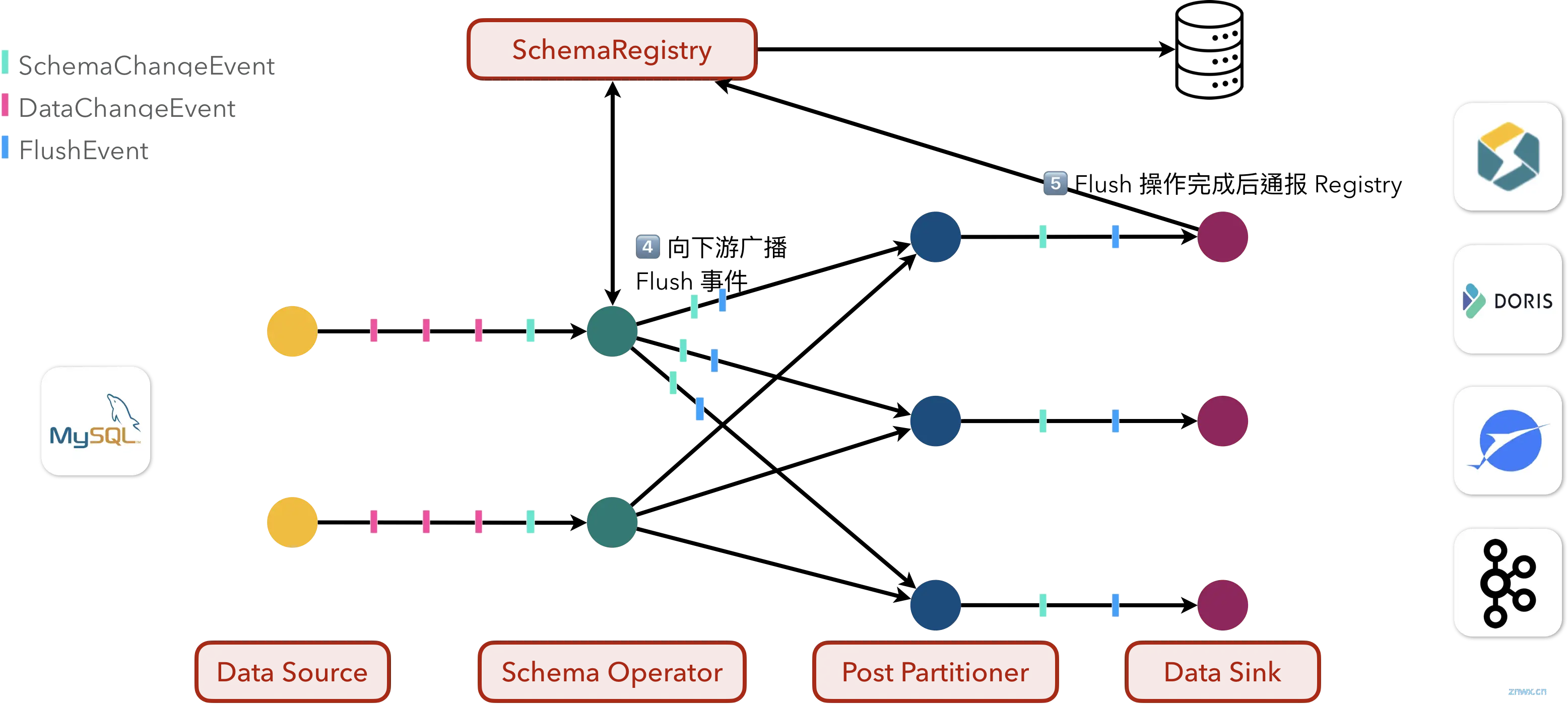
5、在所有的 Sink 都完成 Flush 操作并通报 Registry 后,
6、Registry 会通过 MetadataApplier API 将表结构变更应用到下游数据库之中;
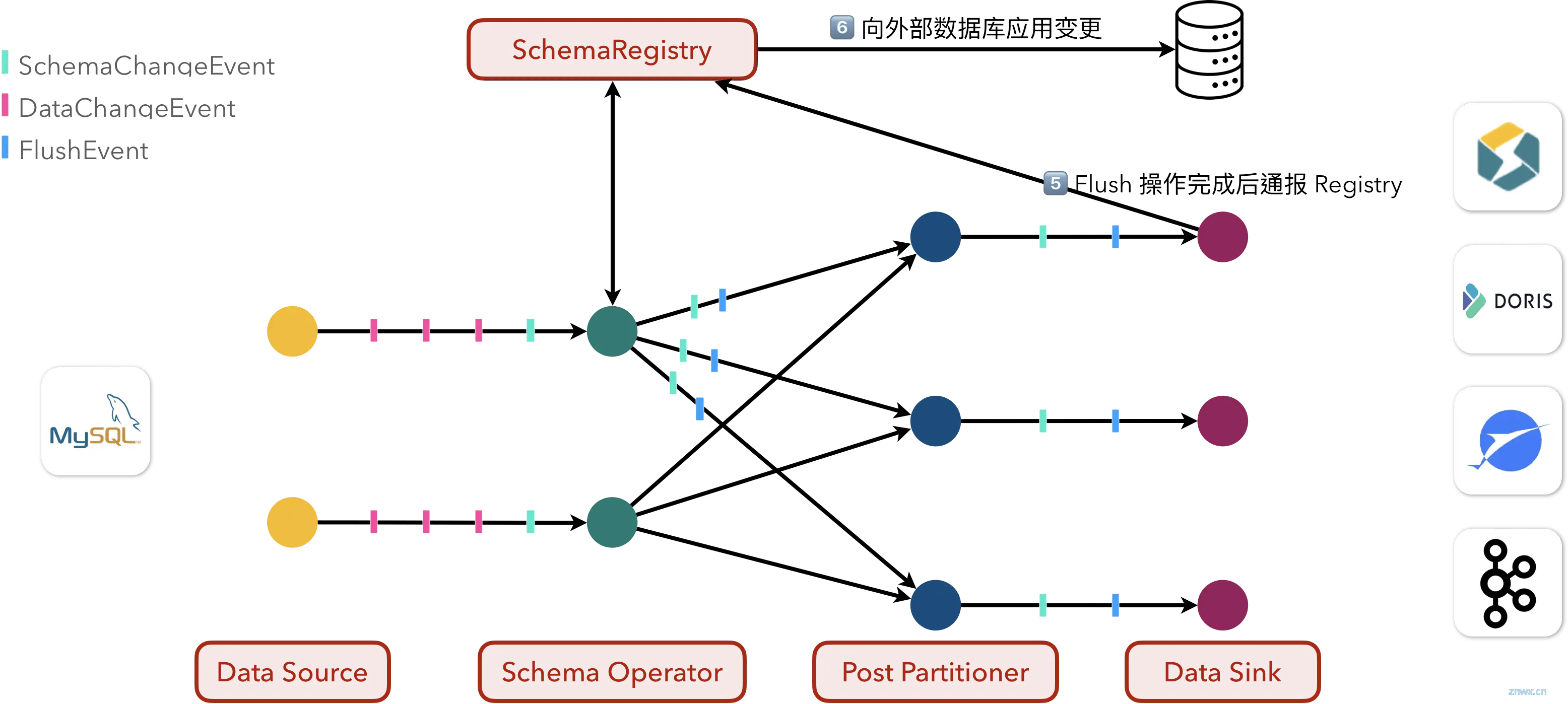
7、最后,向 Schema Operator 告知此次 Schema 变更事件结束,
8、可以停止阻塞,开始继续处理来自上游的其他事件了。
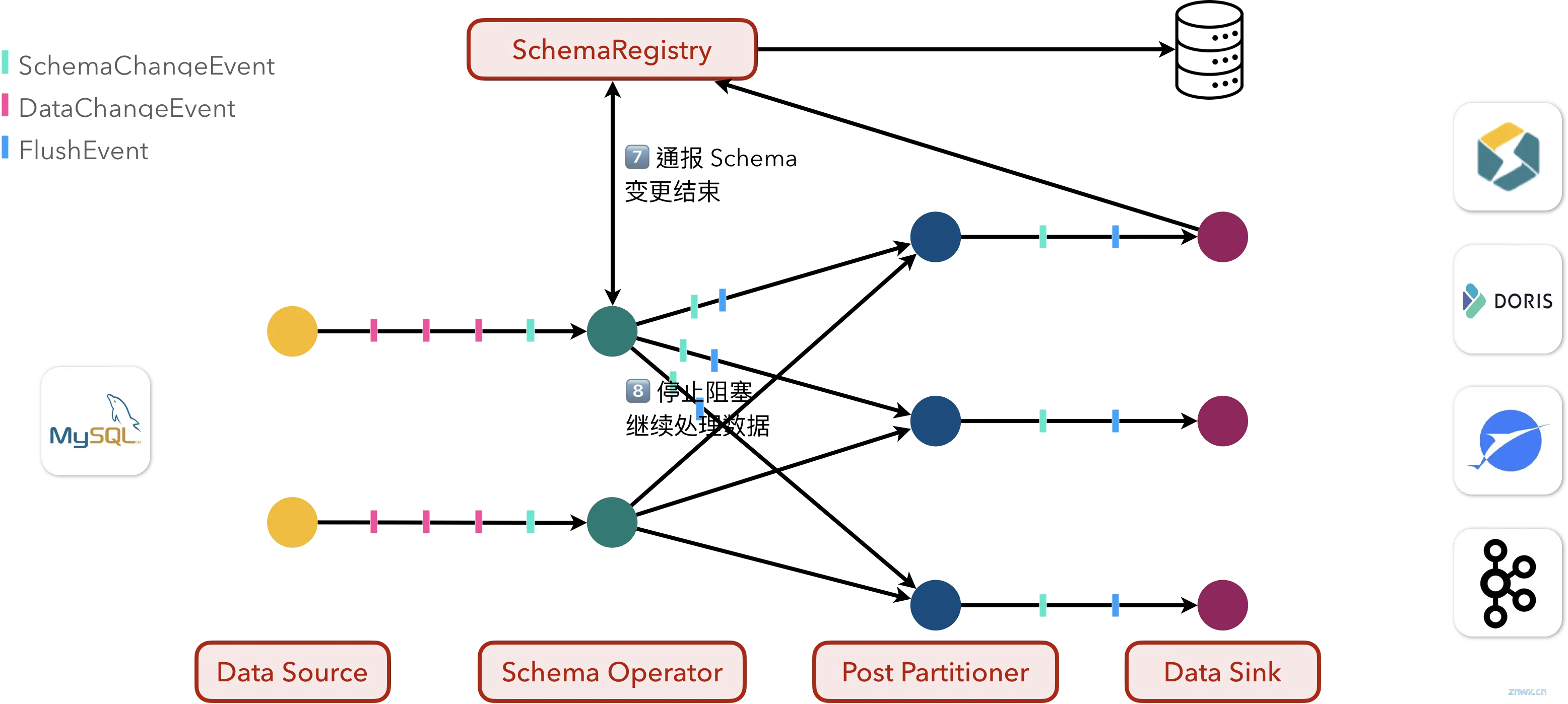
这是一次正常表结构变更演化的全过程。而在向下游应用表结构变更发生错误时,Flink CDC 提供了多种可配置的行为模式:
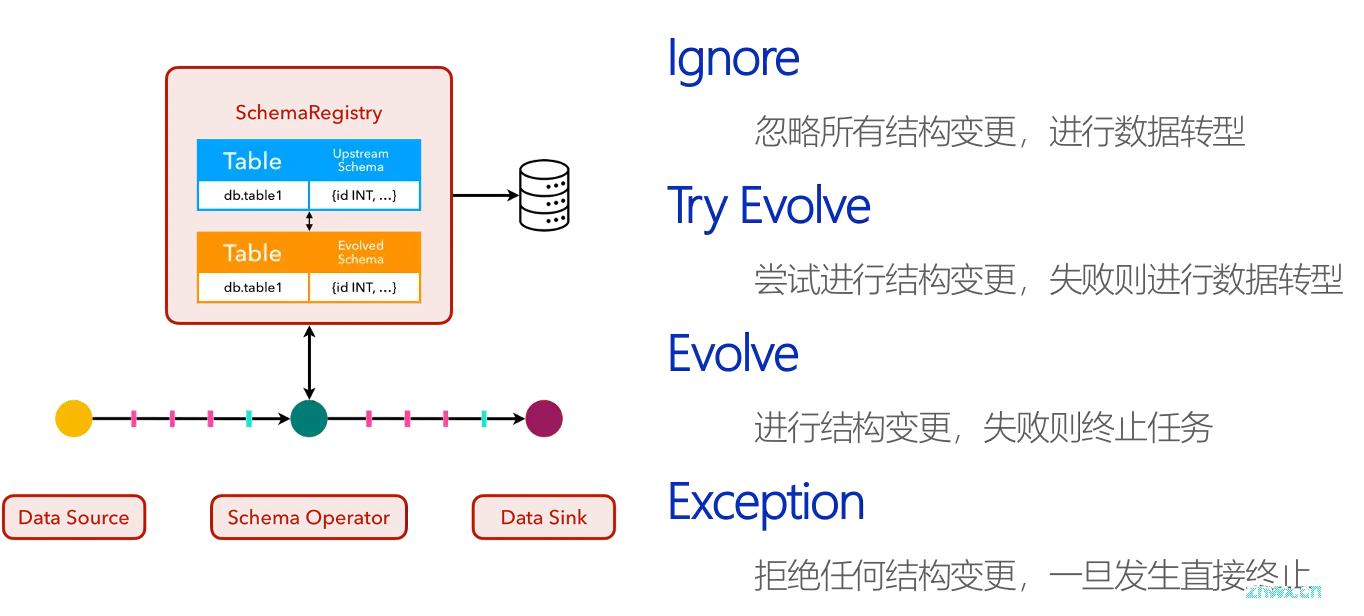
Ignore 模式下,忽略所有结构变更。
Try Evolve 模式下,尝试进行结构变更,失败则忽略。
Evolve(默认)模式下,进行结构变更,失败则终止任务。
Exception 模式下,拒绝任何结构变更,一旦发生直接终止任务。
从 Ignore 到 Exception,对 Schema Evolution 的限制是从最宽容到最严格的。通过支持不同的配置文件模式配置,用户可以根据自己的需要和实际需求,为每个作业配置特定的 Schema Evolution 规则。
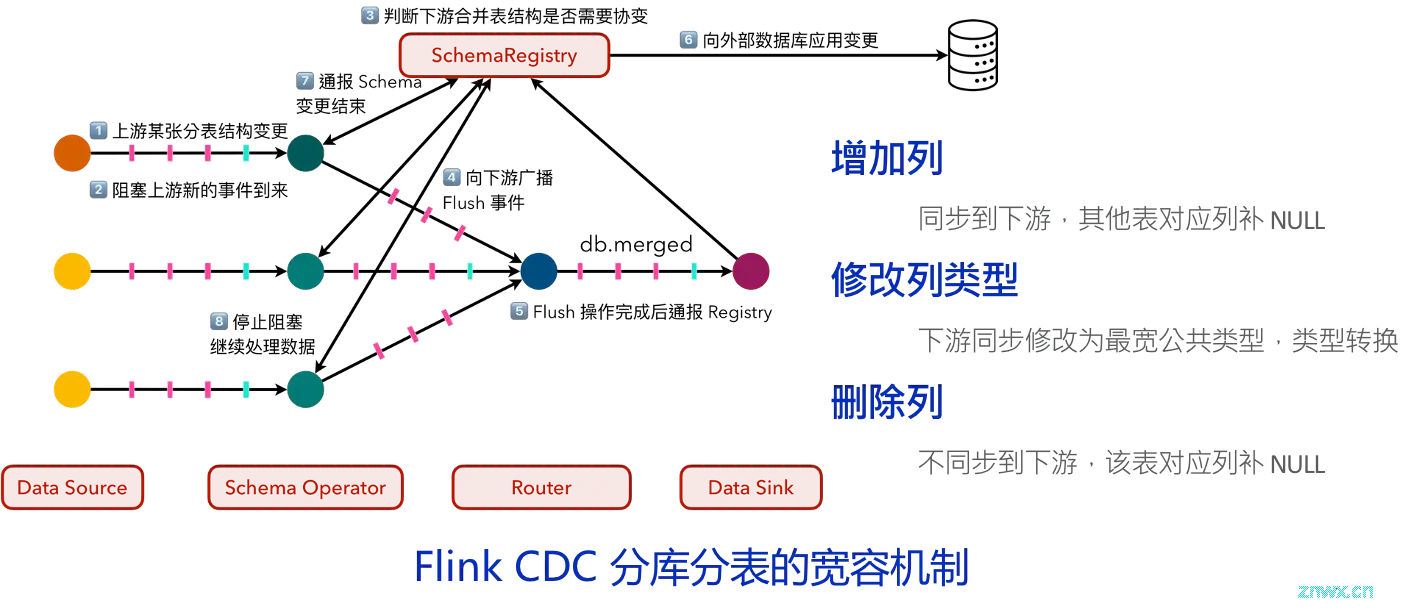
除了表结构变更功能之外,在收集用户反馈需求时,开发者们了解到一种很常见的数据同步场景是将来自上游 MySQL 数据库的多张分表合并,并写入下游的数据仓库或数据湖中。现在,用户只需要在 YAML 配置文件中编写一条路由规则块,指定源表和写入表即可实现分库分表的合并。例如,这里来自上游的分表在经过路由后合并为单一一张 merged 表,来自上游三张表的建表事件被合并为同一条,来自每张源表的数据变更事件也被改写为对单一合并表的记录。
路由功能也可以与表结构变更功能共同发挥作用,提供额外的容错功能。例如,在上游某一张分表发生表结构变更,导致上游合并的三张分表结构产生差异的时候,一般的处理行为就是认为合并分表的条件已经不再满足了,直接抛出失败停止作业。CDC 为了尽量保证作业的容错性、能够在保证不丢失有效数据的情况下尽量稳定地持续运行作业,提供了额外的容错机制选项,允许 Pipeline 作业在某些情况下容忍错误继续运行。
例如,在上游某一张表增加了额外的一列的时候,这一信息会被自动同步到下游;而对于其他不存在这一新增列的表,对应的数据行则会自动被用 NULL 值填充,以便符合下游最新的结构。类似的,删除某一张表的一列也不会导致下游表的对应列被删除,只是这张表接下来到来的数据会被填充上空值。对于列类型修改导致各张分表对应字段类型不一致的情况,则会尝试推导出能够无损容纳所有上游类型的协变类型。例如,框架允许将 FLOAT 宽转换为 DOUBLE,SMALLINT 转换 BIGINT、精度较低的 DECIMAL 转换到精度较高的数字类型。
但在这种无损的转换不成立的时候,CDC 还是会抛出错误并停止作业,而不是默默地进行有损的数据压缩和变换。作为一个数据集成框架,在进行隐式自动转换的时候,遵守的设计原则是不丢弃、不删除、不压缩任何来自上游的数据,确保在默认的模式下尽可能完整地将数据传递给下游。
4. 基于 Flink CDC 的实时数据集成实践
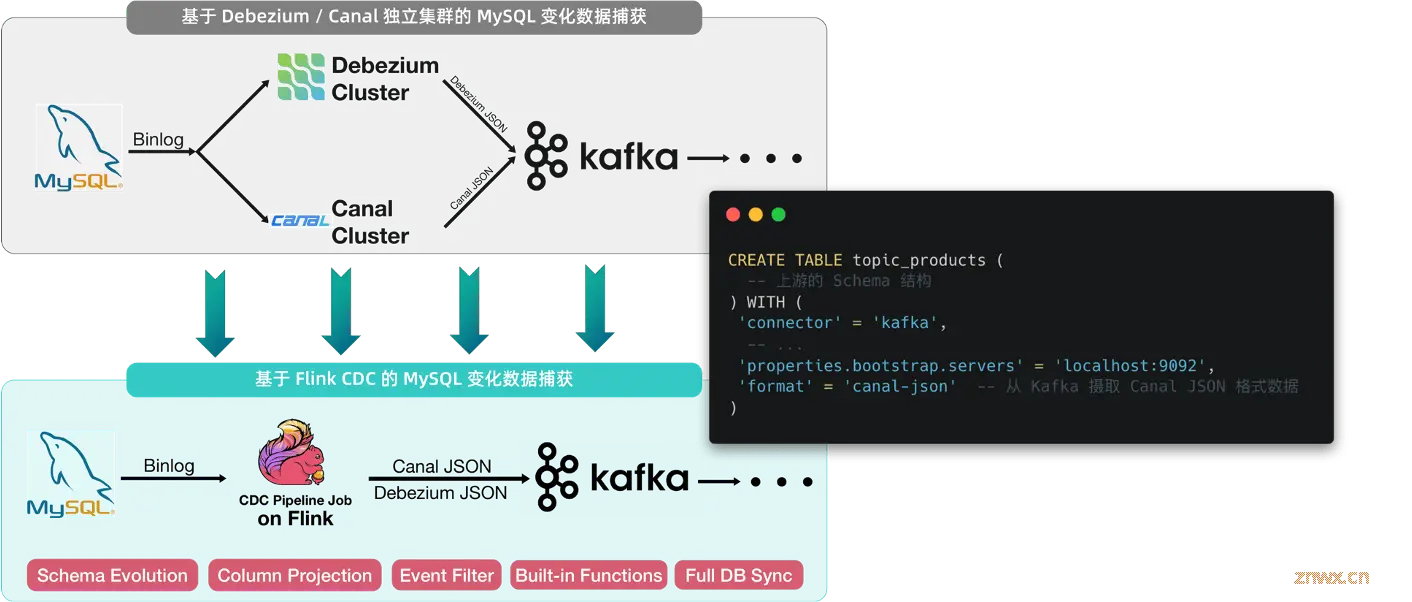
首个案例聚焦于实现MySQL数据库至Apache Kafka的实时数据传输。在不采用 Flink CDC 的场景下,需要独立部署 Debezium 或 Canal 集群,这些系统负责监听 MySQL 的 Binlog,转换数据为特定的 JSON 模型(遵循 Debezium 或 Canal 的格式定义),并推送至 Kafka,便于下游的 Flink、Spark Streaming 等多种流处理引擎订阅并进一步加工处理。
Flink CDC 3.0 版本显著增强了其功能集,内建了直接写入 Kafka 的输出连接器,不仅支持 Debezium 和Canal JSON 格式的输出,还深度整合了 Flink 的生态系统优势,为同属 Flink 环境下的数据摄取与分析任务提供了无缝集成的便利性,免除了额外基础设施的配置需求。此外,Flink CDC 3.0 还引入了多项高级特性,包括但不限于模式进化(Schema Evolution)、列操作(如投影和过滤)的 Transform 能力、丰富的内置函数支持,以及全面的数据库同步机制,为数据在进入消息队列前提供了高度可定制的预处理能力,如数据净化、选择性过滤及表结构优化,从而提升了数据处理的灵活性与效率。
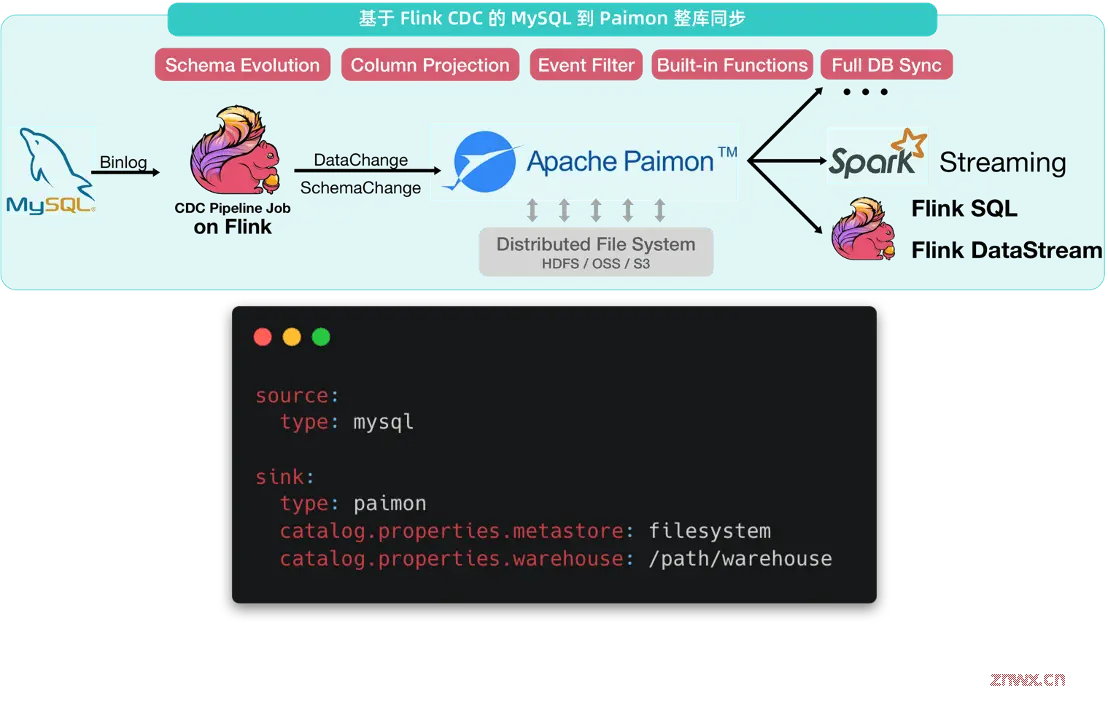
总结
作为一个从开始就诞生于 GitHub 的开源项目,Flink CDC 目前有着活跃的用户社区和繁荣的开源生态;
在三次大版本迭代的过程中成长为技术领先的分布式数据集成框架;
在最新的 3.0 版本中,CDC 为用户提供了开箱可用、功能丰富的 YAML Pipeline 作业支持;
并且能够支撑典型的实时数据集成、入仓入湖的实践。
欢迎大家多多关注 Flink CDC,从钉钉用户交流群[1]、
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。