《基于 Kafka + Flink + ES 实现危急值处理措施推荐和范围校准》
CSDN 2024-08-02 14:33:10 阅读 81
📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗
🌻 近期刚转战 CSDN,会严格把控文章质量,绝不滥竽充数,欢迎多多交流。👍
文章目录
写在前面的话背景技术发明目的具体方案一、前置环境准备二、核心服务实现三、与用户门户的交互实现四、开发危急值分析模块五、开发危急值医务管理模块
危急值发送流程**危急值处理流程**方案特征总结陈词
写在前面的话
本篇文章分享一下博主所在公司的危急值处理措施推荐和范围校准的实现方案。
主要是基于 Kafka + Flink + Elasticsearch 实现,由于涉及安全问题,内容以方案介绍为主,有需要探讨的可以留言。
好,让我们开始。
背景技术
危急值是指当这种检验、检查结果出现时,表明患者可能正处于生命危险的边缘状态,临床医生需要及时得到检验、检查信息,迅速给予患者有效的干预措施或治疗,就可能挽救患者生命。危急值信息可供临床医生对生命处于危险边缘状态患者采取及时、有效的治疗,避免病人因意外发生,出现严重后果,失去最佳抢救机会。
危急值报告制度的制定与实施,能有效增强医技工作人员的主动性和责任心,提高医技工作人员的理论水平,增强医技人员主动参与临床诊断的服务意识,促进临床、医技科室之间的有效沟通与合作。危急值管理是医院管理的重要组成部分,危急值的快速甄别、确认、发布、及时接收以及对该流程监控、分析等是系统信息化管理的目标与方向。
现目前大多危急值管理系统存在如下问题:
1、各类危急值检验项目按照固定的参考范围进行危急值判定,不支持动态调整项目范围的上限和下限,往往只是简单粗暴的进行数值比对,缺乏科学的范围判定和校准方式,造成了不符合临床实际的“假”危急值频繁通知,对临床医护人员工作产生较大影响;
2、医护人员针对危急值做出的干预措施,只是单纯的填写措施并反馈医技部门,没有与病程和护理记录产生交互,处理过程也没有形成记忆和管理,针对相同的情形的工作,往往需要花费重复工作和时间,也容易产生偏差;
3、危急值涉及环节较广,没有统一的流程化管理,容易产生环节缺失,未形成完整闭环,同时,整个过程缺少环节监控、日志跟踪、和异常处理方案,也缺少全院统计汇总页面,无法提供整体改善医院危急值的方案;
发明目的
本专利发明的目的是基于 Kafka + Flink + Elasticsearch 等技术,在危急值全流程管理过程中,实现一种科学校准危急值判定范围、以及对危急值处理措施进行智能推荐的方案,以解决现目前危急值流程管理中存在的诸如危急值判定标准不准确、处理措施数据未利用、全院危急值优化机制不完善等问题,进而优化危急值流程、提升危急值处理效率、形成完整闭环追踪,最终建设完善的危急值全流程管理系统。
1、建设“假”危急值处理方案,防止提醒过于频繁,不断校准危急值项目的合理范围;
2、针对日常危急值的处理措施进行存储,形成记忆,在危急值到来时,可以给予医护人员多样化提示,充当填写助手的作用;
3、基于消息中心事件驱动机制,建设完整危急值处理流程,尽可能包含临床业务场景的各个环节,由数据中心负责完整危急值信息存储,提供闭环展示和数据查询接口;收集各科室的危急值闭环数据,生成定向指标数据,方便定期追踪、分析、评价危急值指标,督导各科室发现并完善自身危急值处理,提升全院危急值处理效率;
具体方案
本方案是基于 Kafka + Flink + Elasticsearch 实现危急值范围校准和措施推荐,具体技术方案实现如下。
一、前置环境准备
1、部署 Kafka 环境,程序引入 Kafka 相关依赖,并进行相关配置与功能集成,定义“危急值发送”和“危急值反馈”事件,同时配置事件的消息入参格式与XSD校验文本,这两个事件将作为 Kafka 的两个主题 Topic,其中,Kafka 用于充当消息中间件,负责提供生产者和消费者的协作模式;
2、部署 Elasticsearch 环境,程序引入 Elasticsearch 相关依赖,并进行相关配置与功能集成,Elasticsearch 定义若干索引结构,将作为危急值原始数据、关联数据、运算结果等内容的存储,并利用 Elasticsearch 特性,进行统计分析;
3、部署 Flink 环境,程序引入 Flink 相关依赖,并进行相关配置与功能集成,Flink 充当呈上启下的衔接角色,一方面用于消费 Kafka 投递的主题消息,另一方面,通过相关 API,将数据运算后,输出存储到 Elasticsearch 当中;
二、核心服务实现
1、提供对外的消息生产者接口
开发消息中心生产者接口,并对外部系统开放,该接口可以用于“危急值发送”和“危急值反馈”这两个场景。
主要逻辑是,针对消息入参进行合理性校验、解析和处理,再通过调用 Kafka API 进行消息发送,利用生产者单例去完成消息发送。
发送的主题 Topic 为“危急值发送”或“危急值反馈”。
2、利用 Flink 消费 Kafka
利用 Flink 的** **Flink Source API,添加 Kafka 作为数据来源,并订阅“危急值发送”和“危急值反馈”这两个 Topic。
针对拉取到的消息,添加消息消费处理的代码块。
3、利用 Flink 加工流数据
3.1、危急值发送流程
针对拉取到的 Kafka 的“危急值发送”Topic 主题数据,进行相应加工处理。
1)利用正则表达式提取消息入参中危急值核心属性内容,包含但不限于危急值ID、报告ID、患者ID、就诊ID等,识别出各关键属性的code和value,并组装为 Map 结构;
2)利用上述关键信息,从 Oracle 中提取危急值业务关联的报告信息、患者信息、就诊信息,以及上述内容的历史信息,从 Elasticsearch 中提取危急值区间分布信息、危急值处理措施分布等信息,将这些内容组装,用于辅助分析;
3)利用 Flink Transform API 对 Map 数据进行综合加工处理,得到相关结果;
4)危急值发送过程中,关于范围校准和措施推荐的相关运算如下:
a、获取该项目危急值的基本信息,判断该危急值是否符合当前危急值的上限和下限;
b、获取该项目危急值的区间分布情况,判断该危急值所属的区间分布,做出更新,并将结果组装;
c、获取该项目危急值的历史处理措施分布情况,并通过运算得出,按不同维度的不同措施出现的频次排列,再将结果组装;
d、获取该项目危急值历史出现时,其他同样异常的项目,并通过运算得出,这些项目和当前危急值项目之间存在的联动关系;
e、获取该项目危急值对应项目的历史值,做出趋势分析,并将结果组装;
f、获取该项目危急值的其他关联和扩展信息,用于辅助分析,并将结果组装;
g、将原始危急值数据存入Elasticsearch,再将第3步的所有运算结果进行组装,进入下一环节,充当填写助手的作用。
3.2、危急值处理流程
针对拉取到的 Kafka 的“危急值处理”Topic 主题数据,进行相应加工处理。
1)利用正则表达式提取消息入参中危急值处理的属性内容,包含但不限于危急值ID、处理方式、处理措施、处理人等,识别出各关键属性的code和value,并组装为 Map 结构;
2)同危急值发送,利用上述关键信息,从 Oracle 和 Elasticsearch 中提取关联信息,用于辅助分析
3)利用 Flink Transform API 对 Map 数据进行综合加工处理,得到相关结果;
4)危急值处理过程中,关于范围校准和措施推荐的相关运算如下:
a、若医生针对该危急值给予了正常的干预措施,则代表危急值触发范围的可信度增加,首先更新该项目危急值出现的频次记录信息;然后,增加该项目组值此时可以更新危急值范围区间数据,代表某项目出现危急值的范围区间更加精准,本区间如果本次危急值属于原有出现危急值的区间内,则增加区间出现次数,若本次危急值超出原有出现危急值的区间,则新增区间数据,扩大区间范围,并进行次数记录;最后,将医生的处理措施和危急值数值,关联存储到措施记忆索引中,该索引记录包含但不限于如下内容:不同项目所使用的处理措施,属于哪个区间,历史触发数值包含哪些,关联患者的当前和历史的报告、就诊、危急值等信息。
b、若医生针对该危急值给予了异常处理,例如点击了反馈疑问按钮,则代表危急值触发范围的可信度降低,首先插入危急值关键信息到反馈疑问索引中;然后,往危急值范围区间索引中也插入相关异常数据;最后,也将更新处理措施索引,反馈疑问也属于处理措施的一个环节;这些疑问内容都将在提供相应统计分析页面,人工进行最后裁定,范围是否变更;
4、利用 Flink 输出到 Elasticsearch
利用 Flink Elasticsearch API,添加 ElasticsearchSink 作为结果输出,将上一步计算得出的结果,按照不同维度存储到ES的不同索引结构。
包含但不下于如下索引:危急值原始数据索引、危急值扩展数据索引、危急值区间频次分布索引、危急值处理措施分布索引等。
三、与用户门户的交互实现
3.1、危急值发送流程
经过核心服务的数据处理,可以调用用户统一门户的后端接口,再利用 WebSocket 完成前后端消息推送,或由核心服务直接集成 WebSocket 负责与门户前端交互,最终在用户门户前端展示出危急值霸屏弹窗界面。
霸屏弹窗上医生除了看到危急值对应基本信息、报告信息、患者信息外,还可以填写干预措施提交,或点击反馈疑问按钮。
霸屏弹窗上将展示如下填报助手信息:
a、该项目危急值的各项处理措施出现的频次,医生可以快速点击复用;
b、该项目不同触发区间出现危急值的频次,作为医生确认危急值的参考依据;
c、该项目的历史趋势对比分析图,以及该项目出现危急值时,其他产生危急值时,同样异常的项目信息出现的频次;
d、其他历史参考信息,例如就诊历史、报告历史、危急值历史等;
3.2、危急值处理流程
医生针对危急值霸屏弹窗做出处理,将调用统一门户后端接口,触发 Kafka 的“危急值处理”Topic 主题数据,进入核心服务的危急值处理环节。
医生有两种处理模式,可以填写干预措施提交,或点击反馈疑问按钮,两种方式都可以结束处理流程。
四、开发危急值分析模块
6.1、设置定时服务,利用聚合函数对ES的数据进行二次加工处理,处理结果继续存储在新的索引空间下。
6.2、开发前端BI界面,将加工前后的危急值指标数据进行展示,并给出分析提示。
1)针对参考范围给出分析判定结果,允许人工最后确认校准范围是否改动。
2)针对处理措施给出推荐分析,针对不同处理措施,按照使用次数、处理路径、对应值范围,以及历史项目趋势、关联其他并发项目、历史诊病信息等内容,给出各项统计、指引、分析。
五、开发危急值医务管理模块
1)定义危急值评价指标:医务科应定义危急值评价指标,如:处理率%,平均处理时常h,及时处理率/24小时处理率%,患者六小时复诊率%,危急值处理总数等;
2)危急值统计:医务科需要定期对各科室危急值管理制度执行情况进行督导检查、追踪、分析,定期评价危急值报告、处置的及时性。在医务门户的危急值组件,汇聚展示各科室的危急值数据,按科室和医生两个维度,展示各类指标的排行榜和详情数据,并支持导出报表一览展示数据,定期比对全院不同时间点的指标对比,制定全院危急值阶段改善计划;
3)危急值反馈:医务科需要根据临床实际情况对危急值项目及危急值进行更新调整,将科室危急值管理纳入科室医疗质量考核,在医务人员门户开发危急值反馈组件,统一收集、分析和处理这些反馈。
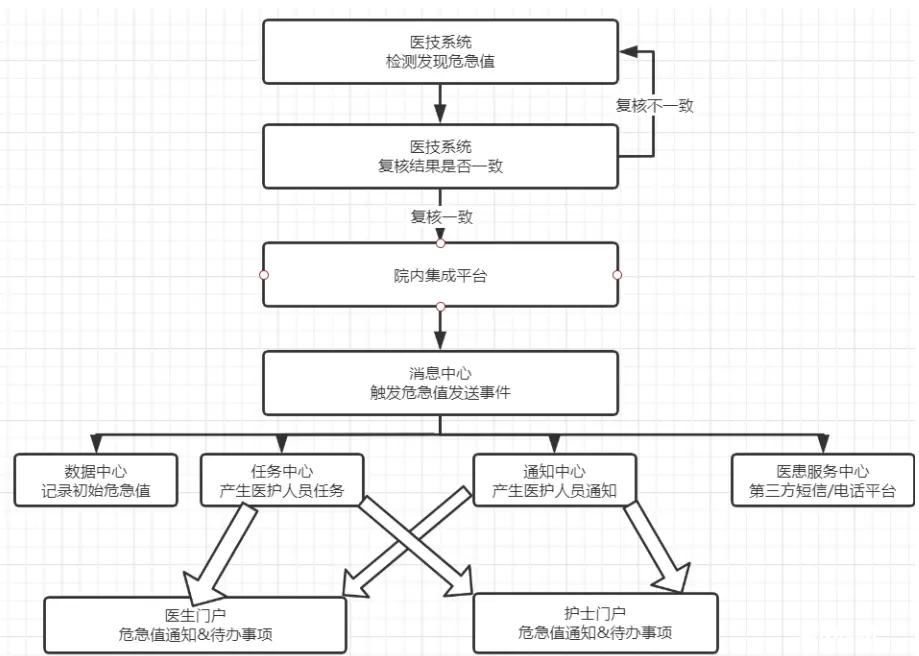
危急值发送流程
流程:LIS - 数据中心 - 生产者 - Kafka Source - Flink - 加工处理 - Elasticsearch
1、医技人员发现危急值情况时,检查(验)者首先要确认检查仪器、设备和检验过程是否正常,核查标本是否有错,操作是否正确,仪器传输是否有误,在确认临床及检查(验)过程各环节无异常的情况下,及时复查(影像科室可根据实际情况决定是否需要复查),如两次复查结果相同, 才可以将检查(验)结果发出。
2、检查(验)系统发出危急值后,将通过院内集成平台发起对数据中心危急值发送接口的调用,首先将进行危急值的存储,接着调用本方案中的消息中心生产者接口,投递“危急值发送”Topic 至 Kafka;
3、本方案的核心服务,将利用 Flink 订阅 Kafka 的危急值发送 Topic,并利用 Flink Transform API 对接收到的数据进行加工处理,形成需要的数据,再利用 Flink Elasticsearch API,添加 ElasticsearchSink 将结果输出到 Elasticsearch 相关索引中;
4、经过核心服务的数据处理,可以调用用户统一门户的后端接口,再利用 WebSocket 完成前后端消息推送,或由核心服务直接集成 WebSocket 负责与门户前端交互。最终在用户门户前端展示出危急值霸屏弹窗界面;
5、至此,发送流程结束。
危急值处理流程
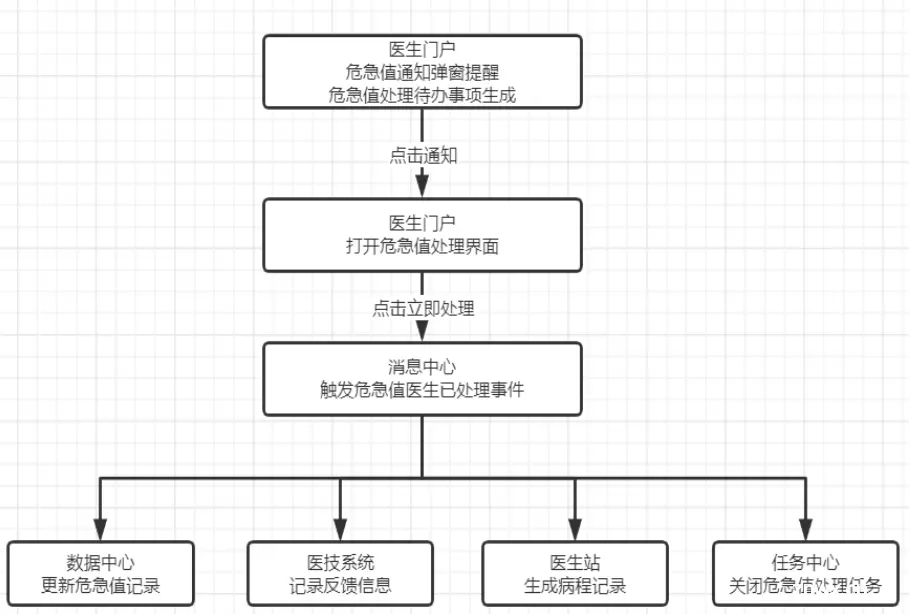
流程:门户 - 数据中心 - 生产者 - Kafka Source - Flink - 加工处理 - Elasticsearch
1、医生用户在日常使用门户系统过程中,若收到危急值发送通知,则会以霸屏弹窗的形式进行展示;
2、医生根据患者的危急值信息,以及报告信息、就诊信息等内容进行判断,若确认符合危急值范畴,则填写相应干预措施,触发数据中心的危急值处理逻辑;
3、数据中心首先更新危急值信息,然后将通过院内集成平台发起对检查(验)系统危急值发送接口的调用,紧接着调用本方案中的消息中心生产者接口,投递“危急值处理”Topic 至 Kafka;
4、本方案的核心服务,将利用 Flink 订阅 Kafka 的危急值处理 Topic,并利用 Flink Transform API 对接收到的数据进行加工处理,形成需要的数据,再利用 Flink Elasticsearch API,添加 ElasticsearchSink 将结果输出到 Elasticsearch 的相关索引中;
5、若第2步,医生判断该危急值属于误报,则点击“反馈疑问”按钮,将调用“医务管理模块”的错误问题上报接口,以便后续分析;
方案特征
1、基于 Kafka + Flink 组合实现,利用了大数据流式引擎技术的优势,针对危急值的发送和处理场景,实现高可靠、高效实时、高扩展性的数据加工,最终实现危急值范围校准和措施推荐的目的;
2、利用 Elasticsearch 存储多样化的指标运算结果,再利用 ES 的聚合函数功能对结果二次分析处理,整体方案扩展性和可重用性都获得较大的提升;
3、将消息中心事件驱动机制应用于危急值场景,为危急值闭环流程的关键节点建立消息事件,通过动态订阅的方式为事件指定订阅服务,流程清晰可插拔。以消息中心为枢纽建立完整危急值处理流程,尽可能覆盖实际业务场景的各个环节,提升业务覆盖面和人员参与度;
总结陈词
上文介绍了博主所在公司的《基于 Kafka + Flink + ES 实现危急值处理措施推荐和范围校准》方案。
💗 后续会逐步分享企业实际开发中的实战经验,有需要交流的可以联系博主。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。