[kernel] 带着问题看源码 —— 脚本是如何被 execve 调用的
goodcitizen 2024-08-27 10:45:00 阅读 91
Linux 脚本文件 shebang (!#) 行最大为何只有 128 字节?为何最多只能指定一个参数?如何将这些参数排列在参数列表前面?本文通过阅读 Linux 内核源码,一一为你揭秘
前言
在《[apue] 进程控制那些事儿 》一文的"进程创建-> exec -> 解释器文件"一节中,曾提到脚本文件的识别是由内核作为 exec 系统调用处理的一部分来完成的,并且有以下特性:
- 指定解释器的以 #! (shebang) 开头的第一行长度不得超过 128
- shebang 最多只能指定一个参数
- shebang 指定的命令与参数会成为新进程的前 2 个参数,用户提供的其它参数依次往后排
这些特性是如何实现的?带着这个疑问,找出系统对应的内核源码看个究竟。
源码定位
和《[kernel] 带着问题看源码 —— 进程 ID 是如何分配的》一样,这里使用 bootlin 查看内核 3.10.0 版本源码,脚本文件是在 execve 时解析的,所以先搜索 sys_ execve:

整个调用链如下:
sys_execve -> do_execve -> do_execve_common -> search_binary_handler-> load_binary -> load_script (binfmt_script.c)
为了快速进入主题,前面咱们就不一一细看了,主要解释一下 search_binary_handler。
Linux 中加载不同文件格式的方式是可扩展的,这主要是通过内核模块来实现的,每个模块实现一个格式,新的格式可通过编写内核模块实现快速支持而无需修改内核源码。刚才浏览代码的时候已经初窥门径:
这是目前内核内置的几个模块
- binfmt_elf:最常用的 Linux 二进制可执行文件
- binfmt_elf_fdpic:缺失 MMU 架构的二进制可执行文件
- binfmt_em86:在 Aplha 机器上运行 Intel 的 Linux 二进制文件
- binfmt_aout:Linux 老的可执行文件
- binfmt_script:脚本文件
- binfmt_misc:一种新机制,支持运行期文件格式与应用对应关系的绑定
基本可以归纳为三大类:
- 可执行文件
- 脚本文件 (script)
- 机制拓展 (misc)
其中 misc 机制类似 Windows 上文件通过后缀与应用进行绑定的机制,它除了通过后缀,还可以通过检测文件中的 Magic 字段,作为判断文件类型的依据。目前的主要应用方向是跨架构运行,例如在 x86 机器上运行 arm64、甚至 Windows 程序 (wine),相比编写内核模块,便利性又降低了一个等级。
本文主要关注脚本文件的处理过程。
binfmt
内核模块本身并不难实现,以 script 为例:
<code>static struct linux_binfmt script_format = {
.module= THIS_MODULE,
.load_binary= load_script,
};
static int __init init_script_binfmt(void)
{
register_binfmt(&script_format);
return 0;
}
static void __exit exit_script_binfmt(void)
{
unregister_binfmt(&script_format);
}
core_initcall(init_script_binfmt);
module_exit(exit_script_binfmt);
主要是通过 register_binfmt / unregister_binfmt 来插入、删除 linux_binfmt 信息节点。
/*
* This structure defines the functions that are used to load the binary formats that
* linux accepts.
*/
struct linux_binfmt {
struct list_head lh;
struct module *module;
int (*load_binary)(struct linux_binprm *);
int (*load_shlib)(struct file *);
int (*core_dump)(struct coredump_params *cprm);
unsigned long min_coredump;/* minimal dump size */
};
linux_binfmt 的内容不多,而且回调函数不用全部实现,没有用到的留空就完事了。下面看下插入节点过程:
static LIST_HEAD(formats);
static DEFINE_RWLOCK(binfmt_lock);
void __register_binfmt(struct linux_binfmt * fmt, int insert)
{
BUG_ON(!fmt);
write_lock(&binfmt_lock);
insert ? list_add(&fmt->lh, &formats) :
list_add_tail(&fmt->lh, &formats);
write_unlock(&binfmt_lock);
}
/* Registration of default binfmt handlers */
static inline void register_binfmt(struct linux_binfmt *fmt)
{
__register_binfmt(fmt, 0);
}
利用 linux_binfmt.lh 字段 (list_head) 实现链表插入,链表头为全局变量 formats。
search_binary_handler
再看 search_binary_handler 利用 formats 遍历链表的过程:
retval = -ENOENT;
for (try=0; try<2; try++) {
最多尝试 2 次
read_lock(&binfmt_lock);
list_for_each_entry(fmt, &formats, lh) {
加锁;通过 formats 遍历整个链表
int (*fn)(struct linux_binprm *) = fmt->load_binary;
if (!fn)
continue;
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
bprm->recursion_depth = depth + 1;
检查内核模块是否 alive;执行 load_binary 前解锁 formats 链表以便嵌套;更新嵌套深度
retval = fn(bprm);
bprm->recursion_depth = depth;
if (retval >= 0) {
if (depth == 0) {
trace_sched_process_exec(current, old_pid, bprm);
ptrace_event(PTRACE_EVENT_EXEC, old_vpid);
}
put_binfmt(fmt);
allow_write_access(bprm->file);
if (bprm->file)
fput(bprm->file);
bprm->file = NULL;
current->did_exec = 1;
proc_exec_connector(current);
return retval;
}
恢复嵌套尝试;执行成功,提前退出
read_lock(&binfmt_lock);
put_binfmt(fmt);
if (retval != -ENOEXEC || bprm->mm == NULL)
break;
if (!bprm->file) {
read_unlock(&binfmt_lock);
return retval;
}
}
执行失败,重新加锁;如果非 ENOEXEC 错误,继续尝试下个 fmt
read_unlock(&binfmt_lock);
break;
}
遍历完毕,退出
其中 list_for_each_entry 就是 Linux 对 list 遍历的封装宏:
/**
* list_for_each_entry-iterate over list of given type
* @pos:the type * to use as a loop cursor.
* @head:the head for your list.
* @member:the name of the list_struct within the struct.
*/
#define list_for_each_entry(pos, head, member)\
for (pos = list_entry((head)->next, typeof(*pos), member);\
&pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
本质是个 for 循环。另外,之前的 for (try < 2) 其实并不生效,因为总会被末尾的 break 打断。
不过这里提示了一点 load_binary 的写法:当该接口返回 -ENOEXEC 时,表示这个文件“不合胃口”,请继续遍历 formats 列表尝试,下面在解读 load_script 时可以多加留意。
另外 binfmt 是可以嵌套的,假设在调用一个脚本,它使用 awk 作为解释器,那么整个执行过程看起来像下面这样:
execve (xxx.awk) -> load_script (binfmt_script) -> load_elf_binary (binfmt_elf)
这是因为 awk 作为可执行文件,本身也需要 binfmt 的处理,稍等就可以在 load_script 中看到这一点。
目前 Linux 没有对嵌套深度施加限制。
源码分析
经过一番背景知识铺垫,终于可以进入 binfmt_script 好好看看啦:
static int load_script(struct linux_binprm *bprm)
{
const char *i_arg, *i_name;
char *cp;
struct file *file;
char interp[BINPRM_BUF_SIZE];
int retval;
if ((bprm->buf[0] != '#') || (bprm->buf[1] != '!'))
return -ENOEXEC;
脚本不以 #! 开头的,忽略;注意 interp 数组的长度:#define BINPRM_BUF_SIZE 128,这是 shebang 不能超过 128 的来源
/*
* This section does the #! interpretation.
* Sorta complicated, but hopefully it will work. -TYT
*/
allow_write_access(bprm->file);
fput(bprm->file);
bprm->file = NULL;
系统已读取文件头部的一部分字节到内存,脚本文件用完了,释放
bprm->buf[BINPRM_BUF_SIZE - 1] = '\0';
if ((cp = strchr(bprm->buf, '\n')) == NULL)
cp = bprm->buf+BINPRM_BUF_SIZE-1;
*cp = '\0';
最多截取前 127 个字符,并向前搜索 shebang 结尾 (\n),若有,则设置新的结尾到那里
while (cp > bprm->buf) {
cp--;
if ((*cp == ' ') || (*cp == '\t'))
*cp = '\0';
else
break;
}
for (cp = bprm->buf+2; (*cp == ' ') || (*cp == '\t'); cp++);
if (*cp == '\0')
return -ENOEXEC; /* No interpreter name found */
前后 trim 空白字符,如果没有任何内容,忽略;注意初始时 cp 指向字符串尾部,结束时,cp 指向有效信息头部
i_name = cp;
i_arg = NULL;
for ( ; *cp && (*cp != ' ') && (*cp != '\t'); cp++)
/* nothing */ ;
while ((*cp == ' ') || (*cp == '\t'))
*cp++ = '\0';
if (*cp)
i_arg = cp;
strcpy (interp, i_name);
跳过命令名;忽略空白字符;剩下的若有内容全部作为一个参数;命令名复制到 interp 数组中备用
/*
* OK, we've parsed out the interpreter name and
* (optional) argument.
* Splice in (1) the interpreter's name for argv[0]
* (2) (optional) argument to interpreter
* (3) filename of shell script (replace argv[0])
*
* This is done in reverse order, because of how the
* user environment and arguments are stored.
*/
retval = remove_arg_zero(bprm);
if (retval)
return retval;
retval = copy_strings_kernel(1, &bprm->interp, bprm);
if (retval < 0) return retval;
bprm->argc++;
if (i_arg) {
retval = copy_strings_kernel(1, &i_arg, bprm);
if (retval < 0) return retval;
bprm->argc++;
}
retval = copy_strings_kernel(1, &i_name, bprm);
if (retval) return retval;
bprm->argc++;
retval = bprm_change_interp(interp, bprm);
if (retval < 0)
return retval;
删除 argv 的第一个参数,分别将命令名 (i_name)、参数 (i_arg 如果有的话)、脚本文件名 (bprm->interp) 放置到 argv 前三位。
注意这里调用的顺序恰好相反:bprm->interp、i_arg、i_name,这是由于 argv 在进程中特殊的存放方式导致,参考后面的解说;最后更新 bprm 中的命令名
/*
* OK, now restart the process with the interpreter's dentry.
*/
file = open_exec(interp);
if (IS_ERR(file))
return PTR_ERR(file);
bprm->file = file;
retval = prepare_binprm(bprm);
if (retval < 0)
return retval;
通过命令名指定的路径打开文件,并设置到当前进程,准备加载前的各种信息,包括预读文件的头部的一些内容
return search_binary_handler(bprm);
}
使用新命令的信息继续搜索 binfmt 模块并加载之
这里主要补充一点,对于 shebang 中的命令名字段,中间不能包含空格,否则会被提前截断,即使使用引号包围也不行 (解析代码根本未对引号做处理),下面是个例子:
> pwd
/ext/code/apue/07.chapter/test black
> ls -lh
total 52K
-rwxr-xr-x 1 yunhai01 DOORGOD 48K Aug 23 19:17 echo
-rwxr--r-- 1 yunhai01 DOORGOD 47 Aug 23 19:17 echo.sh
> cat echo.sh
#! /ext/code/apue/07.chapter/test black/demo
> ./echo a b c
argv[0] = ./echo
argv[1] = a
argv[2] = b
argv[3] = c
> ./echo.sh a b c
bash: ./echo.sh: /ext/code/apue/07.chapter/test: bad interpreter: No such file or directory
文件头预读
这里主要解释两点,一是 prepare_binprm 会预读文件头部的一些数据,供后面 binfmt 判断使用:
/*
* Fill the binprm structure from the inode.
* Check permissions, then read the first 128 (BINPRM_BUF_SIZE) bytes
*
* This may be called multiple times for binary chains (scripts for example).
*/
int prepare_binprm(struct linux_binprm *bprm)
{
umode_t mode;
struct inode * inode = file_inode(bprm->file);
int retval;
mode = inode->i_mode;
if (bprm->file->f_op == NULL)
return -EACCES;
...
/* fill in binprm security blob */
retval = security_bprm_set_creds(bprm);
if (retval)
return retval;
bprm->cred_prepared = 1;
memset(bprm->buf, 0, BINPRM_BUF_SIZE);
return kernel_read(bprm->file, 0, bprm->buf, BINPRM_BUF_SIZE);
}
目前这个 BINPRM_BUF_SIZE 的长度也是 128:
#define BINPRM_BUF_SIZE 128
在 do_execve_common 中也会调用这个接口来为第一次 binfmt 识别做准备:
/*
* sys_execve() executes a new program.
*/
static int do_execve_common(const char *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp)
{
struct linux_binprm *bprm;
struct file *file;
struct files_struct *displaced;
bool clear_in_exec;
int retval;
const struct cred *cred = current_cred();
...
file = open_exec(filename);
retval = PTR_ERR(file);
if (IS_ERR(file))
goto out_unmark;
sched_exec();
bprm->file = file;
bprm->filename = filename;
bprm->interp = filename;
retval = bprm_mm_init(bprm);
if (retval)
goto out_file;
bprm->argc = count(argv, MAX_ARG_STRINGS);
if ((retval = bprm->argc) < 0)
goto out;
bprm->envc = count(envp, MAX_ARG_STRINGS);
if ((retval = bprm->envc) < 0)
goto out;
retval = prepare_binprm(bprm);
if (retval < 0)
goto out;
没错,就是这里了
retval = copy_strings_kernel(1, &bprm->filename, bprm);
if (retval < 0)
goto out;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp, bprm);
if (retval < 0)
goto out;
retval = copy_strings(bprm->argc, argv, bprm);
if (retval < 0)
goto out;
retval = search_binary_handler(bprm);
if (retval < 0)
goto out;
...
}
argv 调整
另外一点是 argv 在内存中的布局,参考之前写的《[apue] 进程环境那些事儿 》,这里直接贴图:
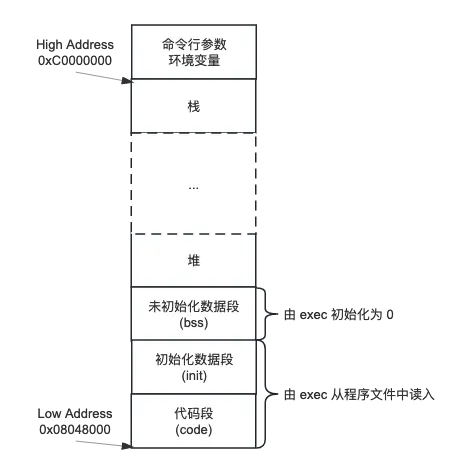
命令行参数与环境变量是放在进程高地址空间的末尾,以 \0 为间隔的字符串。由于有高地址“天花板”在存在,这里必需先根据字符串长度定位到起始位置,再复制整个字符串,此外为了保证 argv[0] 地址小于 argv[1],整个数组也需要从后向前遍历。这里借用之前写的一个例子证明这一点:
<code>#include <stdio.h>
#include <stdlib.h>
int data1 = 2;
int data2 = 3;
int data3;
int data4;
int main (int argc, char *argv[])
{
char buf1[1024] = { 0 };
char buf2[1024] = { 0 };
char *buf3 = malloc(1024);
char *buf4 = malloc(1024);
printf ("onstack %p, %p\n",
buf1,
buf2);
extern char ** environ;
printf ("env %p\n", environ);
for (int i=0; environ[i] != 0; ++ i)
printf ("env[%d] %p\n", i, environ[i]);
printf ("arg %p\n", argv);
for (int i=0; i < argc; ++ i)
printf ("arg[%d] %p\n", i, argv[i]);
printf ("onheap %p, %p\n",
buf3,
buf4);
free (buf3);
free (buf4);
printf ("on bss %p, %p\n",
&data3,
&data4);
printf ("on init %p, %p\n",
&data1,
&data2);
printf ("on code %p\n", main);
return 0;
}
随便给一些参数让它跑个输出:
> ./layout a b c d
onstack 0x7fff2757a970, 0x7fff2757a570
env 0x7fff2757aea8
env[0] 0x7fff2757b4fb
env[1] 0x7fff2757b511
env[2] 0x7fff2757b534
env[3] 0x7fff2757b544
env[4] 0x7fff2757b558
env[5] 0x7fff2757b566
env[6] 0x7fff2757b587
env[7] 0x7fff2757b5af
env[8] 0x7fff2757b5c7
env[9] 0x7fff2757b5e7
env[10] 0x7fff2757b5fa
env[11] 0x7fff2757b608
env[12] 0x7fff2757bcc0
env[13] 0x7fff2757bcc8
env[14] 0x7fff2757be1d
env[15] 0x7fff2757be3b
env[16] 0x7fff2757be59
env[17] 0x7fff2757be6a
env[18] 0x7fff2757be81
env[19] 0x7fff2757be9b
env[20] 0x7fff2757bea3
env[21] 0x7fff2757beb3
env[22] 0x7fff2757bec4
env[23] 0x7fff2757bee0
env[24] 0x7fff2757bf13
env[25] 0x7fff2757bf36
env[26] 0x7fff2757bf62
env[27] 0x7fff2757bf83
env[28] 0x7fff2757bfa1
env[29] 0x7fff2757bfc3
env[30] 0x7fff2757bfce
arg 0x7fff2757ae78
arg[0] 0x7fff2757b4ea
arg[1] 0x7fff2757b4f3
arg[2] 0x7fff2757b4f5
arg[3] 0x7fff2757b4f7
arg[4] 0x7fff2757b4f9
onheap 0x1056010, 0x1056420
on bss 0x6066b8, 0x6066bc
on init 0x606224, 0x606228
on code 0x40179d
重点看下 argv 与 envp 的地址,envp 高于 argv;再看各个数组内部的情况,索引低的地址也低。结合之前的内存布局图,就需要这样排布各个参数:
- 先排布 envp,envp 内部从后向前遍历
- 后排布 argv,argv 内部从后向前遍历
代码也确实是这样写的:
retval = copy_strings(bprm->envc, envp, bprm);
if (retval < 0)
goto out;
retval = copy_strings(bprm->argc, argv, bprm);
if (retval < 0)
goto out;
上面这段之前在 do_execve_common 中展示过,先排布 envp 后排布 argv,再看数组内部的处理:
/*
* 'copy_strings()' copies argument/environment strings from the old
* processes's memory to the new process's stack. The call to get_user_pages()
* ensures the destination page is created and not swapped out.
*/
static int copy_strings(int argc, struct user_arg_ptr argv,
struct linux_binprm *bprm)
{
struct page *kmapped_page = NULL;
char *kaddr = NULL;
unsigned long kpos = 0;
int ret;
while (argc-- > 0) {
倒序遍历数组
const char __user *str;
int len;
unsigned long pos;
ret = -EFAULT;
str = get_user_arg_ptr(argv, argc);
if (IS_ERR(str))
goto out;
len = strnlen_user(str, MAX_ARG_STRLEN);
if (!len)
goto out;
ret = -E2BIG;
if (!valid_arg_len(bprm, len))
goto out;
/* We're going to work our way backwords. */
pos = bprm->p;
str += len;
bprm->p -= len;
计算当前字符串长度并预留位置,注意复制时可能存在跨页情况,字符串也是从尾向头分割为一块块复制的
while (len > 0) {
int offset, bytes_to_copy;
if (fatal_signal_pending(current)) {
ret = -ERESTARTNOHAND;
goto out;
}
cond_resched();
offset = pos % PAGE_SIZE;
if (offset == 0)
offset = PAGE_SIZE;
bytes_to_copy = offset;
if (bytes_to_copy > len)
bytes_to_copy = len;
offset -= bytes_to_copy;
pos -= bytes_to_copy;
str -= bytes_to_copy;
len -= bytes_to_copy;
if (!kmapped_page || kpos != (pos & PAGE_MASK)) {
struct page *page;
page = get_arg_page(bprm, pos, 1);
if (!page) {
ret = -E2BIG;
goto out;
}
if (kmapped_page) {
flush_kernel_dcache_page(kmapped_page);
kunmap(kmapped_page);
put_arg_page(kmapped_page);
}
kmapped_page = page;
kaddr = kmap(kmapped_page);
kpos = pos & PAGE_MASK;
flush_arg_page(bprm, kpos, kmapped_page);
}
if (copy_from_user(kaddr+offset, str, bytes_to_copy)) {
ret = -EFAULT;
goto out;
}
}
}
ret = 0;
复制单个字符串,字符串可能非常大,一个就好几页,干活的主要是 copy_from_user
out:
if (kmapped_page) {
flush_kernel_dcache_page(kmapped_page);
kunmap(kmapped_page);
put_arg_page(kmapped_page);
}
return ret;
}
出错处理
了解了 argv 与 envp 的布局后,突然发现在数组前插入元素反而简单了,不过需要先将第一个元素删除,这里 Linux 使用了一个 trick:直接移动 argv 指针 (bprm->p) 略过第一个参数:
/*
* Arguments are '\0' separated strings found at the location bprm->p
* points to; chop off the first by relocating brpm->p to right after
* the first '\0' encountered.
*/
int remove_arg_zero(struct linux_binprm *bprm)
{
int ret = 0;
unsigned long offset;
char *kaddr;
struct page *page;
if (!bprm->argc)
return 0;
do {
offset = bprm->p & ~PAGE_MASK;
page = get_arg_page(bprm, bprm->p, 0);
if (!page) {
ret = -EFAULT;
goto out;
}
kaddr = kmap_atomic(page);
for (; offset < PAGE_SIZE && kaddr[offset];
offset++, bprm->p++)
;
kunmap_atomic(kaddr);
put_arg_page(page);
if (offset == PAGE_SIZE)
free_arg_page(bprm, (bprm->p >> PAGE_SHIFT) - 1);
} while (offset == PAGE_SIZE);
bprm->p++;
bprm->argc--;
ret = 0;
out:
return ret;
}
经过更新后,bprm->p 指向了第二个参数,argc 减少了 1,后面新参数插入时,会自动覆盖它:
retval = copy_strings_kernel(1, &bprm->interp, bprm);
if (retval < 0) return retval;
bprm->argc++;
if (i_arg) {
retval = copy_strings_kernel(1, &i_arg, bprm);
if (retval < 0) return retval;
bprm->argc++;
}
retval = copy_strings_kernel(1, &i_name, bprm);
if (retval) return retval;
bprm->argc++;
copy_string_kernel 将基于 kernel 获取的源字符串调用 copy_strings,因此一切又回到了前面的逻辑,这里只要保持参数倒序处理即可,这段代码之前在 load_script 时展示过,这回大家看明白了吗?
总结
开头提出的三个问题:
- 指定解释器的以 shebang 开头的第一行长度不得超过 128
- shebang 最多只能指定一个参数
- shebang 指定的命令与参数会成为新进程的前 2 个参数,用户提供参数依次后排
都一一得到了解答,其中 shebang 长度 128 这个限制,和整个 execve 预读长度 ()BINPRM_BUF_SIZE) 息息相关,也与 binfmt_misc 规定的格式相关,看起来不好随便突破。
另外通过通读源码,得到了以下额外的知识:
- 解释器文件可嵌套,且没有深度限制
- 解释器第一行中的命令名不能包含空白字符
- 命令行参数在内存空间是倒排的,这一点貌似主要是为了在数组头部插入元素更便利,如果有需求要在数组尾部插入元素,可能就得改为正排了
最后对于 shebang 支持多个 arguments 这一点,目前看只要修改 binfmt_scrpts,应该是可以实现的,这个课题就留给感兴趣的读者作为作业吧,哈哈~
参考
[1].linux下使用binfmt_misc设定不同二进制的打开程序
[2].Linux中的binfmt-misc原理分析
[3].binfmt.d 中文手册
[4].Linux 的 binfmt_misc (binfmt) module 介紹
[5].Linux系统的可执行文件格式详细解析
[6].Kernel Support for miscellaneous Binary Formats (binfmt_misc)
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。