昇思25天学习打卡营第1天|快速入门
小 明 2024-08-16 15:37:01 阅读 61
昇思25天学习打卡营第1天|快速入门
目录
昇思25天学习打卡营第1天|快速入门实操教程
一、MindSpore内容简介
主要特点:
MindSpore的组成部分:
二、入门实操步骤
1. 安装必要的依赖包
2. 下载并处理数据集
3. 构建网络模型
4. 训练模型
5. 测试模型性能
6. 进行多轮训练
7. 示例输出
总结
博主v:XiaoMing_Java
博主v:XiaoMing_Java
一、MindSpore内容简介
本文主要是借助昇思大模型平台的Jupyter云上开发学习昇思MindSpore入门知识
昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景统一部署三大目标。
设计目标是使得深度学习的开发变得更加简单高效,并提供统一的部署方案。它能够支持多种运行环境,包括云端、边缘和终端设备。
主要特点:
易开发:MindSpore 提供了友好的API接口,使得开发者可以快速上手,同时调试过程也变得更加直观。高效执行:框架在计算效率、数据预处理和分布式训练方面进行了优化,可以充分利用硬件资源。全场景支持:无论是在云端还是边缘设备,甚至是小型IoT设备,MindSpore都能提供良好的支持。
MindSpore的组成部分:
ModelZoo(模型库):提供丰富的深度学习算法模型,开发者也可以贡献自己的模型。MindSpore Extend(扩展库):支持领域扩展,如图神经网络(GNN)、深度概率编程等。MindSpore Science(科学计算):专为科学计算设计,包含领先的数据集和高精度模型。MindExpression(全场景统一API):支持Python前端表达与编程接口,简化开发流程。MindSpore Data(数据处理层):提供高效的数据处理和常用数据集加载功能。MindCompiler(AI编译器):优化计算图,支持各种硬件加速。MindRT(运行时系统):实现高效的运行时支持,适用于不同场景。MindSpore Insight(可视化调试工具):提供可视化训练监控和调优能力。MindSpore Armour(安全增强库):针对企业级应用提供安全与隐私保护功能。

二、入门实操步骤
接下来,我们将通过MindSpore的API来快速构建和训练一个简单的深度学习模型。
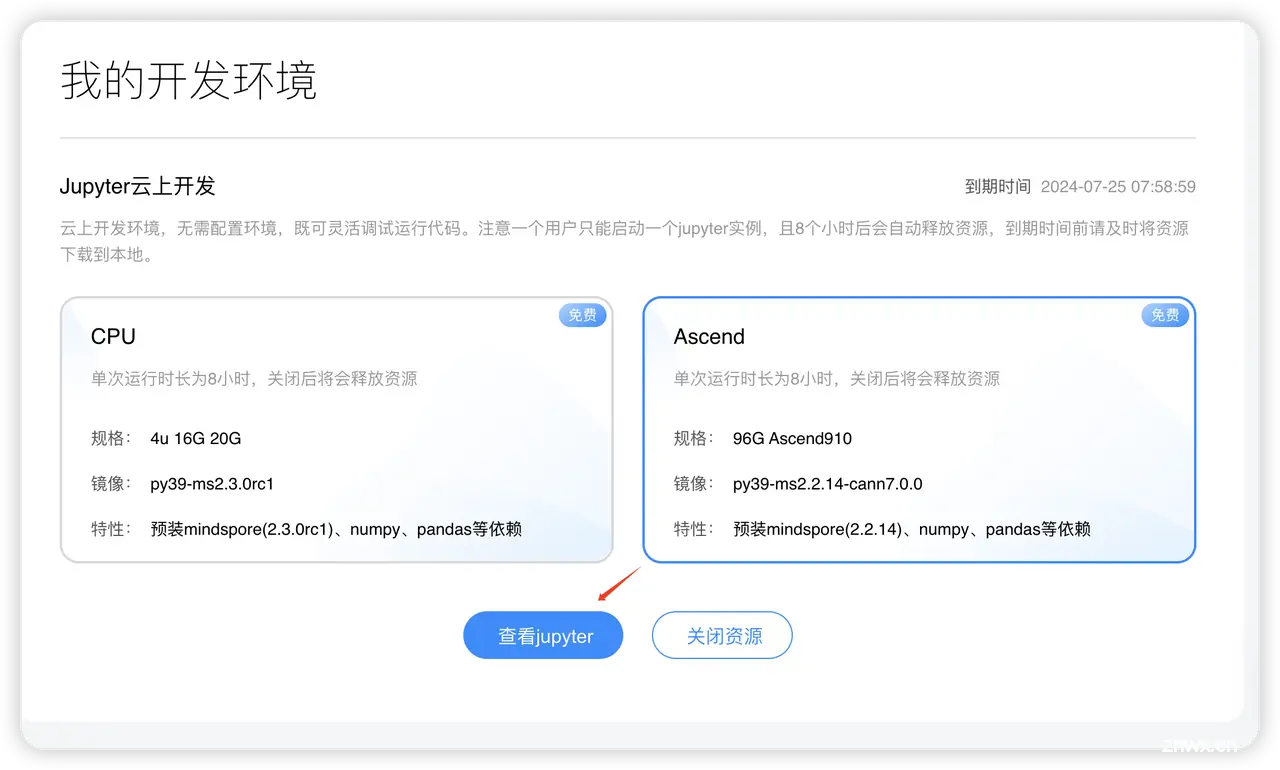
1. 安装必要的依赖包
首先,在进行任何开发之前,您需要确保已经安装了MindSpore及其相关依赖。可以使用以下命令进行安装:
然后我们导入所需的库:
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
2. 下载并处理数据集
在我们的示例中,我们将使用MNIST数据集,这是一个经典的手写数字识别数据集。下面是下载该数据集的代码:
# 导入下载工具
from download import download
# 定义数据集的URL
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip"
# 下载数据集并解压
path = download(url, "./", kind="zip", replace=True)code>
3. 构建网络模型
接下来,我们定义一个简单的神经网络模型,该模型由多个全连接层和ReLU激活函数组成:
# 定义模型结构
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten() # 扁平化层
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512), # 输入层到隐藏层
nn.ReLU(), # 激活函数
nn.Dense(512, 512), # 隐藏层到隐藏层
nn.ReLU(),
nn.Dense(512, 10) # 隐藏层到输出层
)
def construct(self, x):
x = self.flatten(x) # 扁平化输入数据
logits = self.dense_relu_sequential(x) # 前向传播
return logits
model = Network()
print(model) # 打印模型结构

4. 训练模型
接下来,我们需要定义损失函数和优化器,然后编写训练步骤:
<code># 实例化损失函数和优化器
loss_fn = nn.CrossEntropyLoss() # 使用交叉熵损失
optimizer = nn.SGD(model.trainable_params(), learning_rate=1e-2) # Stochastic Gradient Descent
# 定义前向传播函数
def forward_fn(data, label):
logits = model(data) # 模型预测
loss = loss_fn(logits, label) # 计算损失
return loss, logits
# 获取梯度函数
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# 定义单步训练函数
def train_step(data, label):
(loss, _), grads = grad_fn(data, label) # 计算损失和梯度
optimizer(grads) # 更新参数
return loss
def train(model, dataset):
size = dataset.get_dataset_size() # 数据集大小
model.set_train() # 设置模型为训练模式
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label) # 单步训练
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch # 转换为numpy格式
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
5. 测试模型性能
编写测试函数以评估模型在测试集上的表现:
def test(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size() # 测试集大小
model.set_train(False) # 设置模型为评估模式
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data) # 模型预测
total += len(data) # 累计样本数
test_loss += loss_fn(pred, label).asnumpy() # 计算总损失
correct += (pred.argmax(1) == label).asnumpy().sum() # 计算正确预测数
test_loss /= num_batches # 平均损失
correct /= total # 正确率
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
6. 进行多轮训练
训练过程需要多次迭代数据集,一次完整的迭代称为一轮(epoch)。可以使用如下代码进行训练和测试:
epochs = 3 # 设置训练轮数
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(model, train_dataset) # 训练
test(model, test_dataset, loss_fn) # 测试结果
print("Done!")

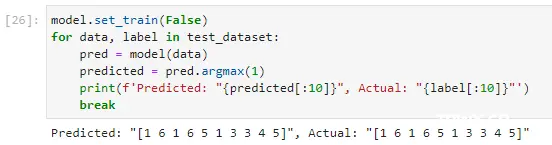
7. 示例输出
在每一轮训练后,您将会看到如下输出:

总结
通过上述步骤,我们成功地使用MindSpore构建并训练了一个简单的深度学习模型,并验证了模型的性能。这一过程展示了MindSpore的易用性和强大功能,非常适合新手入门学习。
在实际操作中,您可以根据需要调整模型的结构、超参数以及数据集,以探索更多深度学习技术的可能性。希望本教程对您有所帮助!
博主v:XiaoMing_Java
博主v:XiaoMing_Java
📫作者简介:嗨,大家好,我是 小 明(小明java问道之路),互联网大厂后端研发专家,2022博客之星TOP3 / 博客专家 / CSDN后端内容合伙人、InfoQ(极客时间)签约作者、阿里云签约博主、全网5万粉丝博主。
🍅 文末获取联系 🍅 👇🏻 精彩专栏推荐订阅收藏 👇🏻
专栏系列(点击解锁)
学习路线(点击解锁)
知识定位
🔥Redis从入门到精通与实战🔥
Redis从入门到精通与实战
围绕原理源码讲解Redis面试知识点与实战
🔥MySQL从入门到精通🔥
MySQL从入门到精通
全面讲解MySQL知识与企业级MySQL实战 🔥计算机底层原理🔥
深入理解计算机系统CSAPP
以深入理解计算机系统为基石,构件计算机体系和计算机思维
Linux内核源码解析
围绕Linux内核讲解计算机底层原理与并发
🔥数据结构与企业题库精讲🔥
数据结构与企业题库精讲
结合工作经验深入浅出,适合各层次,笔试面试算法题精讲
🔥互联网架构分析与实战🔥
企业系统架构分析实践与落地
行业最前沿视角,专注于技术架构升级路线、架构实践
互联网企业防资损实践
互联网金融公司的防资损方法论、代码与实践
🔥Java全栈白宝书🔥
精通Java8与函数式编程
本专栏以实战为基础,逐步深入Java8以及未来的编程模式
深入理解JVM
详细介绍内存区域、字节码、方法底层,类加载和GC等知识
深入理解高并发编程
深入Liunx内核、汇编、C++全方位理解并发编程
Spring源码分析
Spring核心七IOC/AOP等源码分析
MyBatis源码分析
MyBatis核心源码分析
Java核心技术
只讲Java核心技术
上一篇: 解决Ubuntu18.04的git clone报错Failed to connect to github.com port 443: Connection refused
下一篇: CentOS7.6单机部署RabbitMQ消息队列——实施方案
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。