【昇腾AI-CANN训练营】Ascend C算子开发-学习记录帖
m0_46596861 2024-08-01 17:01:03 阅读 74
【昇腾AI-CANN训练营】Ascend C算子开发-学习记录帖
文章目录
前言一、背景知识1. CANN&AI core2. Ascend C算子3. 核函数
二、编程范式三、香橙派的连接四、改造sinh任务1.测试运行2.改造成sinh
五、Ascend C中级认证总结
前言
<code>此为华为昇腾AI训练营(南京站)授课内容,经个人整理发布
为了更好的理解课程内容,建议读者有一定的计算机组成原理、编译原理学习基础
提示:以下是本篇文章正文内容,笔者自行整理,欢迎批评指正!
一、背景知识
1. CANN&AI core

华为的异构计算架构CANN(Compute Architecture for Neural Networks)对标NVIDA的CUDA
NPU(Neural Processing Unit)架构是一种新型的处理器设计理念,它将传统的CPU和GPU架构进行整合,并引入了深度学习算法。
AI core 采用华为自研的达芬奇架构,它包含下面几个组成部分:
计算单元(矩阵计算、向量计算、标量计算)存储系统控制单元
Ascend C编程语言开发的算子运行在AI core上
2. Ascend C算子
算子:一个函数空间到函数空间上的映射
从广义上讲,对任何函数进行某一项操作都可以认为是一个算子
CUDA与CANN的算子不通用
3. 核函数
核函数:Ascend C算子设备侧的入口核函数是直接在设备侧执行的代码使用变量类型限定符核函数必须具有void返回类型核函数的调用语句是C/C++函数调用语句的一种扩展
二、编程范式
Ascend C采用标准C++语法和一组类库API进行编程
1)矢量编程主要分为:
CopyInComputeCopyOut
3个流水任务:CopyIn负责搬入操作,Compute负责矢量计算操作,CopyOut负责搬出操作
2)矩阵编程主要分为:
CopyInSplitComputeAggregateCopyOut
相比矢量编程多了矩阵分割(Split)和聚合(Aggregate)两步
三、香橙派的连接
文档:Orange pai连接及操作实验文档
四、改造sinh任务
首先运动add任务,然后修改add算子功能为sinh函数功能
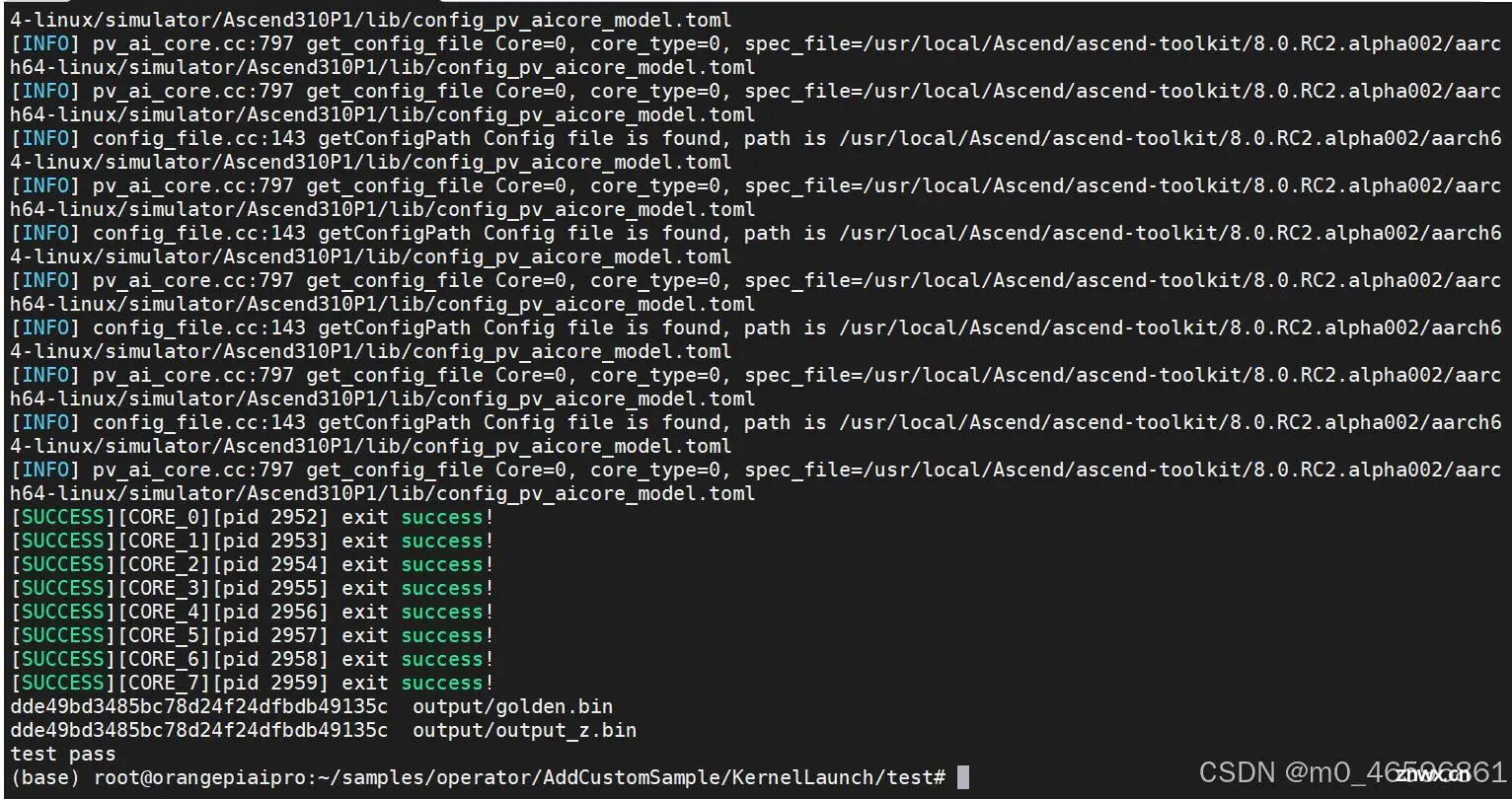
1.测试运行
根据实验手册,成功运行后会显示:test pass
2.改造成sinh
需要参考一些官方的API:华为昇腾社区-Ascend C
需要修改目录:<code>~/samples/operator/AddCustomSample/KernelLaunch/test
下的两个文档:
add_custom.cppscripts / gen_data.py
分别需要修改的地方为:
1

2
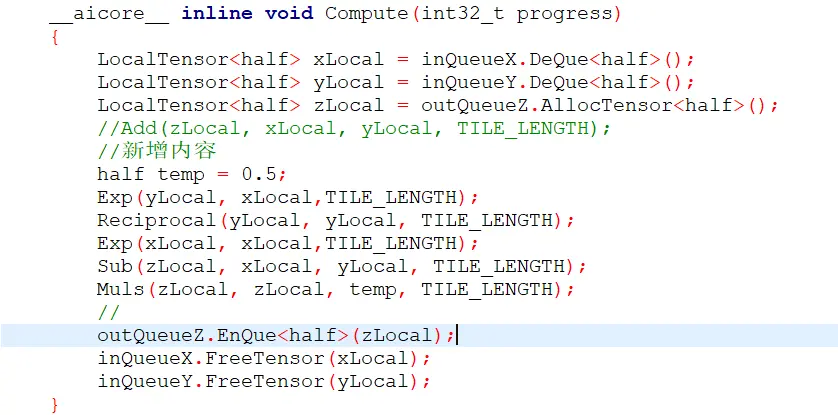
将公式修改为sinh的公式,之后用实验文档中的运行命令再次运行即可
五、Ascend C中级认证
点击链接:Ascend C中级认证考试
题目:
参考tensorflow的Sinh算子,实现Ascend C算子Sinh,算子命名为SinhCustom,并完成aclnn算子调用相关算法: sinh(x) = (exp(x) - exp(-x)) / 2.0
要求:
1、完成host侧和kernel侧代码实现。
2、实现sinh功能,支持float16类型输入,使用内核调试符方式调用算子测试通过。
3、使用单算子API调用方式调用SinhCustom算子测试通过
提交要求:
完成编程后,将上述实现的工程代码打包在rar包内提交,如SinhCustom.rar.
所有需要补充的文件包括:
op_host文件夹下的sinh_custom_tiling.h文件op_host文件夹下的sinh_custom.cpp文件op_kernel文件夹下的sinh_custom.cpp文件
这个实现过程可以参考samples仓库的Add算子,把Add算子的内核调用代码复制一份到SinhCustom,Add需要x,y,z三个变量,sinh只需x和y两个变量,因此删掉关于z的操作
kernel侧的sinh_custom.cpp文件内关键公式修改方法参考前文所示,完整代码如下:
<code>#include "kernel_operator.h"
using namespace AscendC;
constexpr int32_t BUFFER_NUM = 2;
class KernelSinh {
public:
__aicore__ inline KernelSinh() { }
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, uint32_t totalLength, uint32_t
tileNum)
{
//考生补充初始化代码
ASSERT(GetBlockNum() != 0 && "block dim can not be zero!");
this->blockLength = totalLength / GetBlockNum();
this->tileNum = tileNum;
ASSERT(tileNum != 0 && "tile num can not be zero!");
this->tileLength = this->blockLength / tileNum / BUFFER_NUM;
xGm.SetGlobalBuffer((__gm__ DTYPE_X *)x + this->blockLength * GetBlockIdx(),
this->blockLength);
yGm.SetGlobalBuffer((__gm__ DTYPE_Y *)y + this->blockLength * GetBlockIdx(),
this->blockLength);
pipe.InitBuffer(inQueueX, BUFFER_NUM, this->tileLength * sizeof(DTYPE_X));
pipe.InitBuffer(outQueueY, BUFFER_NUM, this->tileLength * sizeof(DTYPE_Y));
pipe.InitBuffer(tmpBuffer1, this->tileLength * sizeof(DTYPE_X));
pipe.InitBuffer(tmpBuffer2, this->tileLength * sizeof(DTYPE_X));
pipe.InitBuffer(tmpBuffer3, this->tileLength * sizeof(DTYPE_X));
pipe.InitBuffer(tmpBuffer4, this->tileLength * sizeof(DTYPE_X));
}
__aicore__ inline void Process()
{
//考生补充对“loopCount”的定义,注意对 Tiling 的处理
int32_t loopCount = this->tileNum * BUFFER_NUM;
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
private:
__aicore__ inline void CopyIn(int32_t progress)
{
//考生补充算子代码
LocalTensor<DTYPE_X> xLocal = inQueueX.AllocTensor<DTYPE_X>();
DataCopy(xLocal, xGm[progress * this->tileLength], this->tileLength);
inQueueX.EnQue(xLocal);
}
__aicore__ inline void Compute(int32_t progress)
{
//考生补充算子计算代码
LocalTensor<DTYPE_X> xLocal = inQueueX.DeQue<DTYPE_X>();
LocalTensor<DTYPE_Y> yLocal = outQueueY.AllocTensor<DTYPE_Y>();
LocalTensor<DTYPE_X> tmpTensor1 = tmpBuffer1.Get<DTYPE_X>();
LocalTensor<DTYPE_X> tmpTensor2 = tmpBuffer2.Get<DTYPE_X>();
LocalTensor<DTYPE_X> tmpTensor3 = tmpBuffer3.Get<DTYPE_X>();
LocalTensor<DTYPE_X> tmpTensor4 = tmpBuffer4.Get<DTYPE_X>();
DTYPE_X inputVal1 = -1;
DTYPE_X inputVal2 = 0.5;
//sinh(x) = (exp(x) - exp(-x)) / 2.0
Muls(tmpTensor1, xLocal, inputVal1, this->tileLength);
Exp(tmpTensor2, tmpTensor1, this->tileLength);
Exp(tmpTensor3, xLocal, this->tileLength);
Sub(tmpTensor4, tmpTensor3, tmpTensor2, this->tileLength);
Muls(yLocal, tmpTensor4, inputVal2, this->tileLength);
outQueueY.EnQue<DTYPE_Y>(yLocal);
inQueueX.FreeTensor(xLocal);
}
__aicore__ inline void CopyOut(int32_t progress)
{
//考生补充算子代码
LocalTensor<DTYPE_Y> yLocal = outQueueY.DeQue<DTYPE_Y>();
DataCopy(yGm[progress * this->tileLength], yLocal, this->tileLength);
outQueueY.FreeTensor(yLocal);
}
private:
TPipe pipe;
//create queue for input, in this case depth is equal to buffer num
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX;
//create queue for output, in this case depth is equal to buffer num
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueY;
GlobalTensor<half> xGm;
GlobalTensor<half> yGm;
//考生补充自定义成员变量
TBuf<QuePosition::VECCALC> tmpBuffer1, tmpBuffer2, tmpBuffer3, tmpBuffer4;
uint32_t blockLength;
uint32_t tileNum;
uint32_t tileLength;
};
extern "C" __global__ __aicore__ void sinh_custom(GM_ADDR x, GM_ADDR y, GM_ADDR
workspace, GM_ADDR tiling) {
GET_TILING_DATA(tiling_data, tiling);
KernelSinh op;
//补充 init 和 process 函数调用内容
op.Init(x, y, tiling_data.totalLength, tiling_data.tileNum);
op.Process();
}
host侧的tiling.h文件:
#include "register/tilingdata_base.h"
namespace optiling {
BEGIN_TILING_DATA_DEF(SinhCustomTilingData)
//考生自行定义 tiling 结构体成员变量
TILING_DATA_FIELD_DEF(uint32_t, totalLength);
TILING_DATA_FIELD_DEF(uint32_t, tileNum);
END_TILING_DATA_DEF;
REGISTER_TILING_DATA_CLASS(SinhCustom, SinhCustomTilingData)
host侧的sinh_custom.cpp文件:
#include "sinh_custom_tiling.h"
#include "register/op_def_registry.h"
namespace optiling {
static ge::graphStatus TilingFunc(gert::TilingContext* context)
{
SinhCustomTilingData tiling;
//考生自行填充
const uint32_t BLOCK_DIM = 8;
const uint32_t TILE_NUM = 8;
uint32_t totalLength = context->GetInputShape(0)->GetOriginShape().GetShapeSize();
context->SetBlockDim(BLOCK_DIM);
tiling.set_totalLength(totalLength);
tiling.set_tileNum(TILE_NUM);
tiling.SaveToBuffer(context->GetRawTilingData()->GetData(),
context->GetRawTilingData()->GetCapacity());
context->GetRawTilingData()->SetDataSize(tiling.GetDataSize());
size_t *currentWorkspace = context->GetWorkspaceSizes(1);
currentWorkspace[0] = 0;
return ge::GRAPH_SUCCESS;
}
}
namespace ge {
static ge::graphStatus InferShape(gert::InferShapeContext* context)
{
const gert::Shape* x1_shape = context->GetInputShape(0);
gert::Shape* y_shape = context->GetOutputShape(0);
*y_shape = *x1_shape;
return GRAPH_SUCCESS;
}
}
namespace ops {
class SinhCustom : public OpDef {
public:
explicit SinhCustom(const char* name) : OpDef(name)
{
this->Input("x")
.ParamType(REQUIRED)
.DataType({ ge::DT_FLOAT16})
.Format({ ge::FORMAT_ND})
.UnknownShapeFormat({ ge::FORMAT_ND});
this->Output("y")
.ParamType(REQUIRED)
.DataType({ ge::DT_FLOAT16})
.Format({ ge::FORMAT_ND})
.UnknownShapeFormat({ ge::FORMAT_ND});
this->SetInferShape(ge::InferShape);
this->AICore()
.SetTiling(optiling::TilingFunc);
this->AICore().AddConfig("ascend310b");
}
};
OP_ADD(SinhCustom);
}
认证成功!
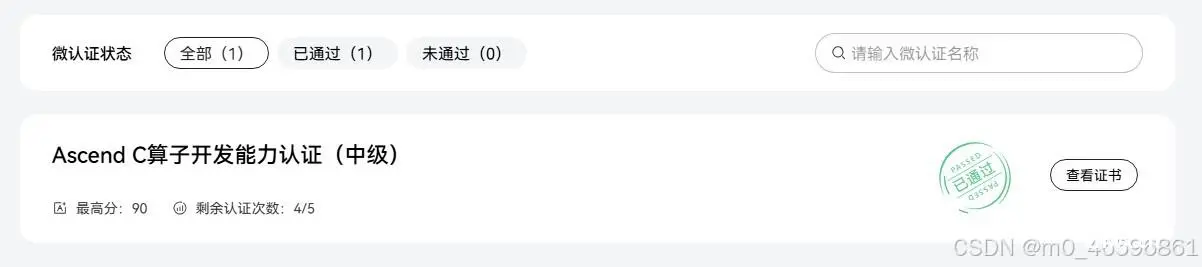
总结
训练营时间不长但收获满满,同时认识到自己有很多不足,希望勤能补拙!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。