算子开发 AI CPU算子 CANN算子 ascend c 编程 Cube计算单元、Vector计算单元和Scalar计算单元 算子原型库
EwenWanW 2024-07-09 09:31:14 阅读 86
算子开发 AI CPU算子 CANN算子 ascend c 编程 Cube计算单元、Vector计算单元和Scalar计算单元
算子开发在人工智能和机器学习领域扮演着重要角色,特别是在构建和优化神经网络模型时。以下是关于算子开发、AI CPU算子、CANN算子、Ascend C编程以及Cube计算单元、Vector计算单元和Scalar计算单元的详细介绍。
算子开发:
在网络模型中,算子对应层或节点的计算逻辑。它可以是简单的数学运算(如加法、乘法),也可以是复杂的深度学习算法(如卷积、池化)。
在某些情况下,如将第三方开源框架转化为适配特定硬件的模型时,可能会遇到硬件不支持的算子。此时,开发者需要自定义算子以填补这一空白。
自定义算子开发通常涉及多个步骤,包括算子原型定义、对应开源框架的算子适配插件、算子信息库定义和算子实现。
AI CPU算子:
AI CPU算子特指运行在AI处理器中CPU计算单元上的表达一个完整计算逻辑的运算。
当遇到硬件不支持的算子时,开发者可以通过自定义AI CPU算子进行功能调测,以提升调测效率。
CANN算子:
CANN(Compute Architecture for Neural Networks)是华为针对神经网络计算推出的一个计算架构,它支持多种硬件平台,包括Ascend系列的AI处理器。
CANN算子特指基于CANN计算架构开发的算子,这些算子经过优化,可以高效地在Ascend AI处理器上运行。
Ascend C编程:
Ascend C是CANN针对算子开发场景推出的编程语言,它原生支持C和C++标准规范,并提供了多层接口抽象、自动并行计算、孪生调试等关键技术,以提高算子开发效率。
使用Ascend C开发自定义算子可以最大化匹配用户的开发习惯,提高开发效率,并助力AI开发者低成本完成算子开发和模型调优部署。
Cube计算单元、Vector计算单元和Scalar计算单元:
这三种计算单元是AI Core(神经网络处理器中的核心计算单元)的重要组成部分。
Cube计算单元即矩阵计算单元,主要完成矩阵相关的运算。
Vector计算单元即向量计算单元,用于向量的计算。
Scalar计算单元即标量运算单元,主要用于程序的流程控制、分支判断、指令的地址和参数计算以及基本的算术运算等。
算子原型库:
算子原型库是一个包含各种算子原型定义的集合。这些原型定义了算子的输入、输出、计算逻辑等关键信息。
在算子开发过程中,开发者通常会从算子原型库中选择合适的算子原型作为起点,然后根据具体需求进行定制和优化。
,算子开发是人工智能和机器学习领域中的一个重要环节,它涉及到多个方面的技术和工具。通过深入理解算子开发的概念、技术和工具链,开发者可以更加高效地构建和优化神经网络模型。
一、算子是什么
算子(Operator)在深度学习和神经网络中是一个核心概念,它通常被理解为神经网络计算图(Computational Graph)中的一个计算节点。神经网络模型可以被视为一个有向无环图(DAG, Directed Acyclic Graph),其中每个节点都表示一个操作或变换,即一个算子。
算子在神经网络中执行各种计算任务,包括但不限于:
线性变换(如矩阵乘法,用于全连接层)
非线性激活函数(如ReLU, Sigmoid, Tanh等)
卷积操作(用于卷积神经网络中的卷积层)
池化操作(如最大池化、平均池化)
归一化操作(如Batch Normalization)
其他操作,如填充(Padding)、裁剪(Cropping)等
在推理(Inference)阶段,为了提高模型的执行速度和效率,开发者会采用多种优化策略,其中算子融合(Operator Fusion)是一种常见的技术。算子融合是指将多个连续且相互关联的算子合并为一个新的算子,从而减少内存读写次数、降低计算复杂度和提高推理速度。例如,将卷积层(Convolution)和批量归一化层(Batch Normalization)以及ReLU激活函数融合为一个单独的算子,可以显著减少推理过程中的内存占用和计算时间。
当将第三方开源框架(如TensorFlow, PyTorch等)训练的神经网络模型转化为适配当前处理器(如GPU, FPGA, ASIC等)的模型时,可能会遇到不支持的算子。这通常是因为不同的硬件架构和处理器具有不同的指令集和性能特性,因此并非所有算子都能在目标硬件上直接执行。在这种情况下,开发者需要实现自定义算子(Custom Operator)来填补这一空白。自定义算子开发涉及到算子的定义、实现、测试和优化等多个步骤,以确保其能够正确地运行在目标硬件上并满足性能要求。
可以将算子理解为神经网络计算图的计算节点。计算图是神经网络模型的底层表达,神经网络模型可以当作一个有向无环图。对某一层执行的ReLU激活操作、对卷积输入执行的填充操作都是算子。
推理侧对模型的加速策略,有些是围绕算子展开。比如算子融合,将常见且有相互关系的多个算子融合为一个,可以减少内存读写次数提高模型执行速度。
在NN模型训练或者推理过程中,将第三方开源框架转化为适配当前处理器的模型时遇到了不支持的算子。
1、Tensorflow 角度理解
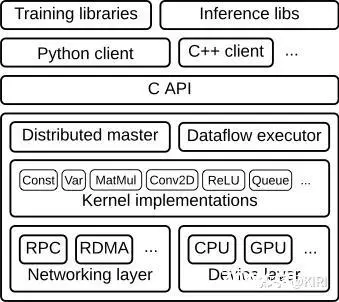
Tensorflow 是一个多语言的项目,Tensorflow 的底层功能主要由 C 与 C++ 实现,并在此基础上派生出了 Python api、Java api、C++ api。因为 Python 相较于 C++ 这种静态语言,能支持交互式编程写起来比较舒服,基本上都是 python 来写训练模型的脚本,而在线上部署模型的时候 C++、Java 使用的频率更多。
TensorFlow确实是一个支持多种编程语言的开源机器学习框架,其中底层的计算引擎主要由C++和C实现,以提供高效的计算性能和对不同硬件平台的支持。这些底层功能通过TensorFlow的公共API暴露给上层应用。
以下是你提到的一些关键点的详细解释:
底层实现(C++和C):TensorFlow的底层实现使用了大量的C++和C代码,这些代码构成了TensorFlow的核心计算引擎,称为Eigen(用于线性代数操作)和XLA(用于跨平台编译和优化)。C++的选择主要是因为其高效性、面向对象编程的特性和对硬件的直接控制能力。
Python API:Python因其简洁易读、支持交互式编程和拥有大量机器学习库(如NumPy、Pandas等)的优点,成为TensorFlow的主要使用语言。TensorFlow的Python API提供了丰富的功能,使得用户可以方便地构建、训练和评估神经网络模型。
C++ API:虽然Python API在研究和原型开发中使用广泛,但在生产环境中,C++ API可能更受欢迎。C++ API提供了对底层功能的直接访问,使得开发者能够更精细地控制模型的部署和执行。此外,C++的性能优势也使其成为高性能计算任务的首选语言。
Java API:TensorFlow也提供了Java API,这使得Java开发者能够利用TensorFlow的功能。Java API特别适用于Android应用中的机器学习模型部署,因为Android平台主要使用Java作为开发语言。
模型部署:在线上部署模型时,C++和Java的使用频率更高。这是因为C++和Java提供了更好的性能、更低的延迟和更精细的内存管理,这对于实时应用或需要高性能的场景至关重要。此外,一些硬件平台可能只支持C++或Java的API,这也使得这两种语言成为模型部署时的首选。
用 Tensorflow 训练模型的时候,在模型跑起来之前会看到这段日志
上一篇: 无需编程,用 Coze 轻松打造你的 AI Agent
下一篇: 《模拟电子技术》期末复习笔记4——上交大郑益慧课件知识点整理
本文标签
算子开发 AI CPU算子 CANN算子 ascend c 编程 Cube计算单元、Vector计算单元和Scalar计算单元 算子原型库
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。