【Linux】开发工具入门指南,轻松掌握你的开发利器
奶芙c 2024-08-21 11:07:06 阅读 50
开发工具
1. 软件包管理器yum1.1 软件包安装方式1.2 yum的"三板斧"1.3 yum的周边
2. 开发工具3. 编辑器vim4. 编译器gcc、g++5. 项目自动化构建工具make、Makefile6. 进度条小程序7. 调试器gdb
1. 软件包管理器yum
1.1 软件包安装方式
源代码安装:用户手动下载程序的源代码,并进行编译,得到一个可执行程序。rpm包安装:预编译好的二进制包。
有些人提前把常用的软件编译好,做成软件包,相当于Windows上的安装程序,将它放在一个服务器上,通过包管理器就可以直接获取到这个编译好的软件包,直接进行安装。yum安装:yum是软件包管理器,是Linux预装的一个指令,用于搜索、下载、安装对应的软件,相当于是Linux的"应用商店"。它提供了丰富的工具、指令、程序,用于软件的安装、检查、卸载等操作。yum的所有操作必须保证主机(虚拟机)入网。
1.2 yum的"三板斧"
yum list | grep 命令
功能:查找和了解当前系统中有哪些软件包可以用。list列出当前所有的软件包、grep用来筛选出我们所需要得到软件包。

软件包的名称:主版本号 . 次版本号 . 源程序发行号 - 软件包的发行号 . 主机平台 . cpu的架构。
x86_64后缀表示64位的安装包、i686后缀表示32位的安装包,选择包时要和系统相互匹配。
e17表示操作系统商业发行版,表示Centos7/redhat7。
base表示软件源,类似于手机中的应用商店。
yum install -y 命令
功能:安装指定的软件包。它会自动找到都有哪些软件包需要下载,敲"y"确认安装,出现"complete"表示安装成功。
只有root、进行sudo的普通用户才能使用,因为安装软件需要向系统目录中写入东西。yum安装软件时只能一个安装完了才能安装另一个。
yum remove 命令
功能:卸载指定的软件包。
1.3 yum的周边
一、yum如何知道目标服务器的地址和下载连接的?
答:主要依赖于yum源(软件仓库)中的配置文件和存储库设置。/etc/yum.repos.d是yum源(软件仓库)。
yum的配置信息存储在/etc/yum.repos.d目录下,在这个目录下,有多个以.repo为后缀的文件,这些文件都是yum源的配置文件。每个.repo文件定义了一个或者多个软件仓库的细节内容,包括从哪里下载需要安装或升级的软件包。
/etc/yum.repos.d/CentOS-Base.repo是一个具体的配置文件,用于定义Centos的基础软件源,它包含了源的配置信息,如源的名称、GPG密匙、URL(目标服务器的地址和下载链接)等。通过这个配置文件,yum知道从哪里获取CentOS的软件包及其软件项,从而能够正确的进行软件的安装、升级、卸载等操作。

二、Centos的基础软件和扩展软件源
Centos的基础软件源为CentOS-Base.repo、Centos的扩展软件源为epel.repo(需提前安装yum install -y epel-release)。
基础软件源:包含了支持Centos系统日常工作的基本软件包,这些软件包是系统正常运行所必需的;扩展软件源除了包含基本软件包,还包含了其他各类软件,这些软件虽然不是系统直接所需要的,但对于特定工作或应用场景非常有用。
三、yum源更新(更改yum源中的配置文件)
步骤1:备份当前的yum源,以便出现问题时可以恢复。
cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
步骤2:下载新的yum源文件。可以从CentOS官网或国内可靠的镜像站点下载,默认情况下,新的yum源文件会以.repo为扩展名,存储在/etc/yum.repos.d/CentOS-Base.repo文件中(wget命令用于从网络上自动下载文件)。
wget https://repo.huaweicloud.com/centos/
步骤3:清除yum缓存,以便系统能够识别新的yum源。
yum clean all
步骤4:更新yum源,以便系统能够识别新的yum源文件中的软件包信息。
yum makecache
步骤5:测试新的yum源。更新yum源后,用以下命令测试新的yum是否能够正常工作。
yum list
四、云服务器、软件谁提供的的,为什么呢?
既得利益者,依托于这款操作系统对应的开发者,一般为商业公司、开源社区、独立的开发者等(希望这个社区变得越来越好,且有强大的使命感)。
操作系统的侧重点不同,开发配套的工具、配套资料不同,主打的调性不同,基准不同,吸引的人不同,配套的核心资源、文档有侧重点,吸引的开发者也有侧重点,开发出的软件也有侧重点,整个生态便形成了不同方向的操作系统。
2. 开发工具
3. 编辑器vim
一、快速认识一下vim
vim是一款多模式的编辑器,vim里面有很多子命令,用于编写和编辑各种文本文件,包括程序代码和配置文件等,是vi的升级版。
二、vim常见模式的切换
:help vim-modes
功能:在底行模式中输入,查看vim所有模式。
各个模式的功能 :
命令/正常/普通模式:vim打开时,默认的模式,所有输入都被当做命令来处理,除非你误触了模式切换的命令。用于控制屏幕光标的移动,字、字符、行的删除,移动/粘贴、复制某区段等。
插入模式:用于输入、修改文本。
底行/末行模式:用于查找字符串,列出行号,文件替换等。
替换模式:允许用户替换已有的文本,可以对文本进行任意编辑。
视图模式:可以进行各种选择操作。eg:移动光标hgkl来选择我想要操作的文本块,选中之后,可以摁shift+i进入插入模式来添加内容,或者摁d来删除选中的文本。
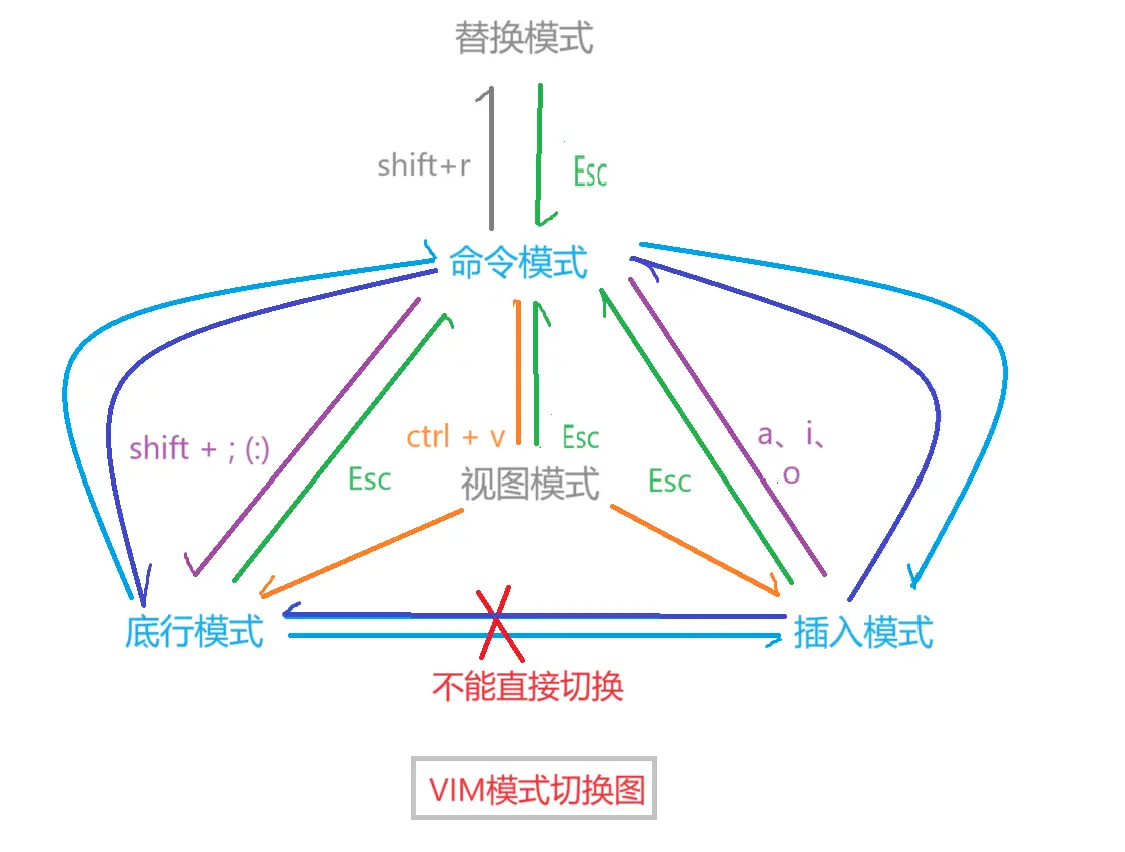
各个模式之间的切换 :
任何模式 -> 命令模式 :摁Esc键。任何模式 -> 视图模式 : ctrl v。命令模式 -> 插入模式:i(光标定位到最开始位置处)、a (光标定位到开始的下一个位置处)、o(光标定位到开始位置的下一行起始位置处)。命令模式 -> 底行模式 :shift ; 。命令模式 -> 替换模式 :shift r(R)。
三、vim常见模式下的命令集
命令模式下
控制屏幕光标的移动命令
shitf 4 : $,光标定位到当前行的最右侧结尾处。
shift 6 : ^,光标定位到当前行的最左侧开始处。
shift g : G,光标定位文本的最结尾。
n shift g : 光标定位到文本的第n行。
gg : 光标定位到文本的最开始。
h : 光标单步向左移。
j :光标单步向下移。
k:光标单步向上移。
l:光标单步向右移。
w : 光标按照"单词"在行内向后进行移动。
b : 光标按照"单词"在行内向前进行移动。
删除命令
(n) dd :批量化删除一行或多行。
(n)x :批量化删除当前光标所在的字符 或 当前光标所在以及往后的n个字符。
(n) shift x : 批量化删除当前光标所在的前一个字符 或 当前光标所在往前的n个字符。
复制命令
(n) yy : 复制一行或多行。
(n) p : 如果和yy结合,构成"复制粘贴",在光标的下一行粘贴一行或多行复制的内容,如果和DD结合,构成"剪切",移动粘贴一行或多行删除的内容。
shift · :~,大小写进行替换。
替换命令
(n) r : 批量替换当前光标所在的字符 或 当前光标所在以及往后的n个字符。
shift r : R,切换为替换模式,可以对文本进行任意位置替换,即:任意进行编辑。
撤销上次操作
u : 撤销。
ctrl r : 对撤销进行撤销。
其他功能命令
shift 3 : #,高亮查找,再摁n键表示跳到下一个查找的地方。
vim 文件 +行号:打开vim时,光标自动跳到指定的行。
shift zz : 保存并退出vim。
底行模式下
set nu : 设置行号。
set nonu : 取消行号。
!命令:不退出vim前提下,支持该命令的功能。
vs 文件名:打开新的界面,形成了多终端,如果在新的界面底行模式执行了w,就会在该目录下创建新文件。
ctrl ww : 光标在多终端进行切换。
wq(保存并退出)、w(保存)、q(退出),后面接感叹号!表示强制做、wq!(保存并强制退出)。
3.批量化加注释、去注释
加注释:ctrl v -> hjkl进行区域化选择 -> shift i -> // -> Esc。
去注释:ctrl v -> hjkl进行区域化选择 -> d
4. 编译器gcc、g++
一、快速认识以下gcc、g++
gcc、g++都是编译器,gcc只能用于编译C语言,g++即适用于编译C语言,又适用于编译C++语言(推荐)。
-o选项:在gcc、g++编译器中用于指定输出文件的名称,让开发者控制可执行文件或者库文件的名称。
二、程序的翻译过程 — gcc选项
语言和编译器的自举过程
是先有的语言,还是先有的用该语言编写的编译器? 先有语言,再有用该语言编写的编译器。
程序的翻译过程,实质是将高级语言,转换为二进制,生成可执行文件(软件)。
编写C语言 -> 用低级语言(汇编语言)编写的汇编编译器来编译C语言 -> 生成可执行文件,形成了C语言。
编写用C语言编写的C编辑器 -> 用低级语言(汇编语言)编写的汇编编译器来编译C语言 -> 生成可执行文件, 形成了C编译器 -> 以后使用用C写的C编译器 -> 来编译用C语言写的文件。
C编译器优化版本V2 -> 用C编译器版本V1来编译 -> 生成可执行文件,形成了V2版本的编译器。
C语言不会直接被编译为为二进制文件,需要先被编译为汇编语言、然后再把汇编代码编译为二进制文件。
预处理
gcc -E 源文件test -o 目标文件test.i :从现在开始进行程序的翻译过程,当预处理执行完后,就停下来。
工作:去注释、宏替换、头文件展开、条件编译。
a. 头文件展开:本质是在预处理阶段,将头文件的内容拷贝到源文件中。
b. 条件编译:本质是对代码进行动态裁剪,主要是适用预处理指令来实现的,eg:ifdef、ifndef、elif、endif等。两个应用:防止头文件被重复包含(#ifndef -> #define -> endif)、对多版本进行功能维护(如专业版和免费版,有些功能重叠)。
c. -D选项:定义宏及其值。在条件编译中,通过给编译器传递不同的宏值,来进行对代码的动态裁剪。
<code>#include<stdio.h>
2
3 //#define VERSION1 1
4 //#define VERSION2 2
5
6 int main()
7 {
8 #ifdef VERSION1 //条件编译
9 printf("Hello Version 1.0\n");
10 #elif VERSION2
11 printf("Hello Version 2.0\n");
12 #else
13 printf("Hello Free Version\n");
14 #endif
15 return 0;
16 }
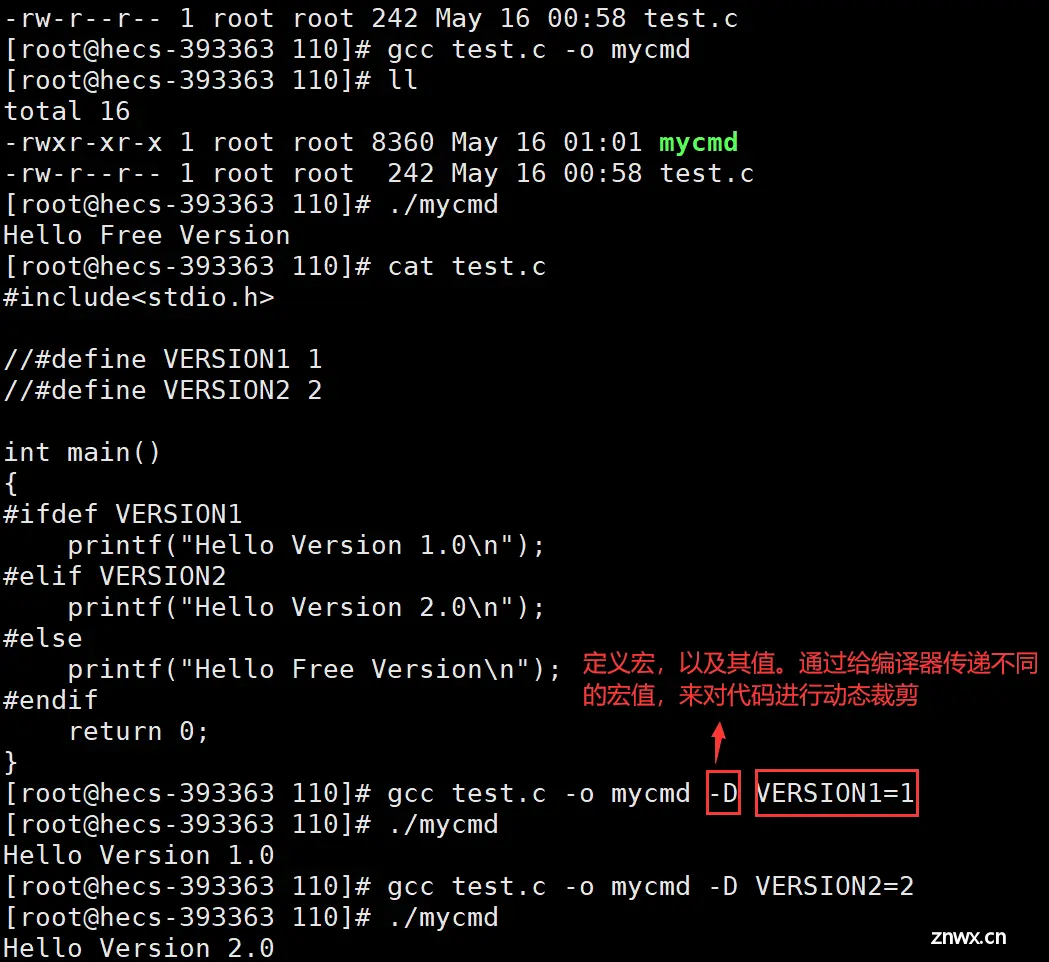
编译
gcc -S test.i -o test.s : 从现在开始进行程序的翻译过程,当编译执行完后,就停下来。
工作:将C语言转化汇编语言。
汇编
gcc -c test.s -o test.o : 从现在开始进行程序的翻译过程,当汇编执行完后,就停下来。
工作:将汇编语言转化二进制语言。且生成可重定位的目标二进制文件(.o),不能被执行。
链接
gcc test.o -o mycmd : 生成可执行程序,-o指定可执行程序文件名。
工作:模块组合(将多个源文件组合起来,形成一个可执行程序)、引人库函数、解决符号引用、优化与调整等。
链接器将可执行程序与库中的函数进行链接, 确保程序在运行时能够调用这些函数。
💡注意:gcc生成可执行程序时,默认为动态链接。
💡Tips:多个平台要支持开发,必须提前在系统中安装语言的库和标准头文件。(ESc -> iso)。
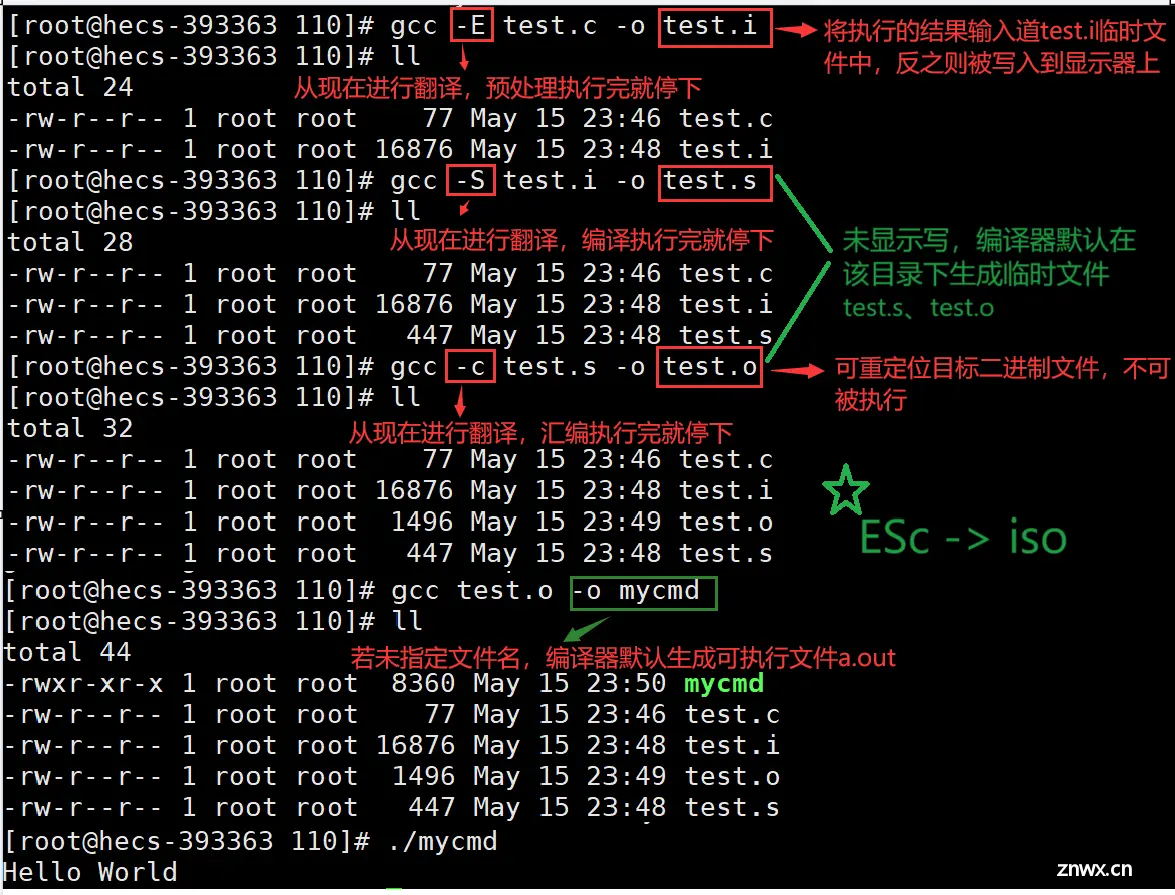
三、动、静态库 — 链接
动、静态库
库的本质是一个可执行的二进制形式(不是二进制文件),可以被操作系统载入到内存中执行。
Linux下,有两种库,分别为静态库、动态库(共享库)。
Linux下:动态库(.so)、静态库(.a);Windows下:动态库(.dll)、静态库(.lib)。
静态库:程序在编译时,它的内容会全部被拷贝到最终的可执行文件中。即:只要你的程序使用了某个静态库,则这个静态库中的所有代码都会被复制到你的可执行文件中。一般情况下系统不直接提供静态库,需要自己手动下载添加。
安装C、C++静态库:yum install -y glibc-static libstdc+±static
动态库:程序在编译时,它的内容不会被拷贝到最终的可执行文件中。而是作为独立文件存在。而是在程序运行时,操作系统就会加载所需的动态库。在编译时,只保存了一些符号信息,以便在运行时解析和链接这些函数。
Tips : 同一个动态库,可以被多个程序所共享使用 -》对动态库的依赖强。
动、静态库的优、缺点
动态库的优点:不会出现大量重复的代码,比较节省资源(磁盘空间、内存、网络等资源)。
动态库的缺点:对库的依赖性很强(依赖外部的共享文件),一旦库丢失,所有使用这个库的程序不能运行了。
静态库的优点:不依赖库(不依赖额外的文件),同类型平台(相同的操作系统或相似的硬件架构系统)都可以使用。
静态库的缺点:可执行程序通常大小比较大,浪费资源(磁盘空间、内存、网络等资源)。
动、静态链接
静态链接:前提条件,存在静态库。是在编译时,将程序的目标代码与所需的库函数中的目标代码合并为一个可执行文件,运行时程序加载到内存中(不需要额外的库)。即:在编译时,将静态库中的所有代码拷贝到最终的可执行程序中。
动态链接:前提条件,存在动态库。运行时(需要额外的库)将磁盘中程序和库文件一起被加载到内存中执行。在编译时,只保存了一些符号信息,以便在运行时解析和链接这些函数。
在动态链接中,可执行文件中只包含了动态库中的函数的引用(地址),实际的函数代码存储在动态库中。
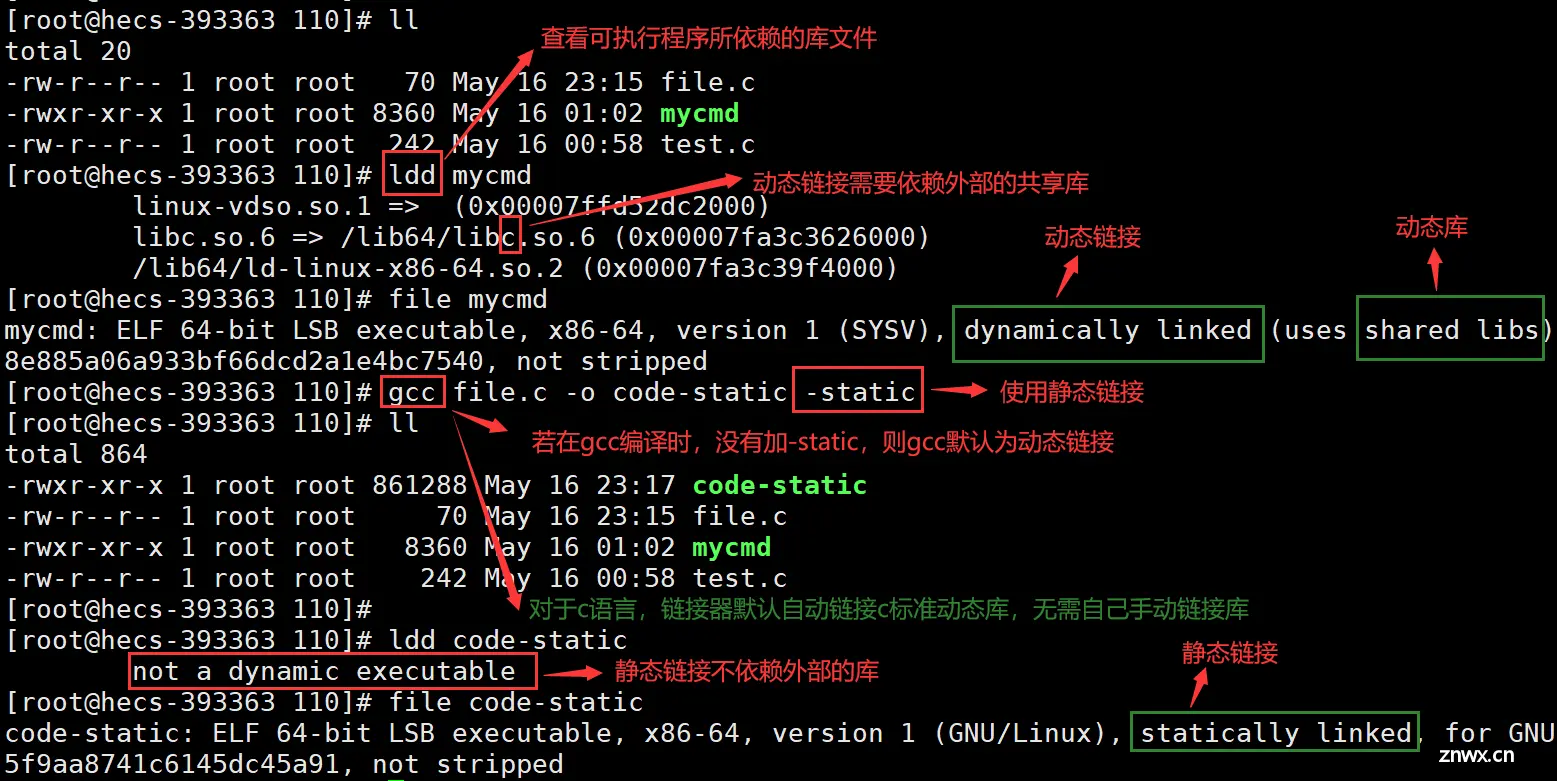
ldd 命令:查看可执行程序是否依赖库。
5. 项目自动化构建工具make、Makefile
一、概念
make是指令,Makefile是文件。作用是用于完成自动化构建和自动化清理项目。
make也是命令工具,用来解释Makefile中指令的命令工具。Makefile一旦写好了,只需要make命令,整个工程进行"自动化编译", 极大提高了软件开发的效率。
二、Makefile中的依赖关系、依赖方法
依赖关系:目标文件与源文件或其他目标文件之间的依赖关系,告诉make工具哪些文件需要被构建,形成目标文件。(相当于是"为什么",我为什么要帮你,因为依赖关系)。
依赖方法:告诉make工具如何从源文件变成目标文件。(相当于是"如何做",我该怎么去帮助你,根据依赖方法)。

三、原理
在默认方式下,make的工作原理:
make会在当前目录下找Makefile 或 makefile文件。
如果找到了,make、Makefile在找寻文件的最终目标文件时,默认make从上往下扫描Makefile文件,默认形成的是第一个目标文件,且只会形成一个,eg : man。可以通过在命令行指定目标名来构建特定的目标,eg : make clean。
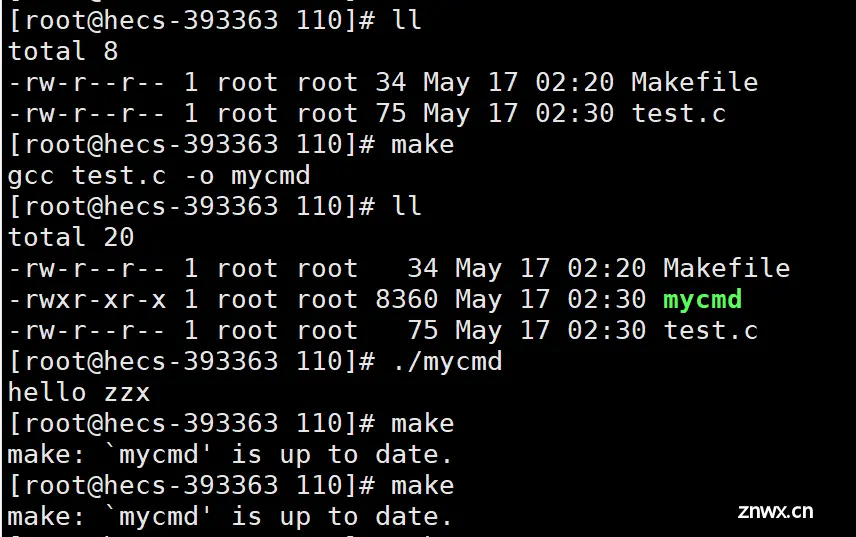
如果如果第一个目标文件所依赖的文件test.o最近被修改时间,比目标文件最近被修改的时间新,则会执行它后面定义的命令(依赖方法)来生成目标文件。
知识点:问:make、makefile如何知道可执行目标文件是比较新的的呢?
答:通过对比时间(Modify时间 : 文件内容被修改的时间),将可执行文件的modify时间与源代码的modify时间相比较,如果源文件modeify时间较新,说明源文件被修改了,可以被进行编译,否则,反之。
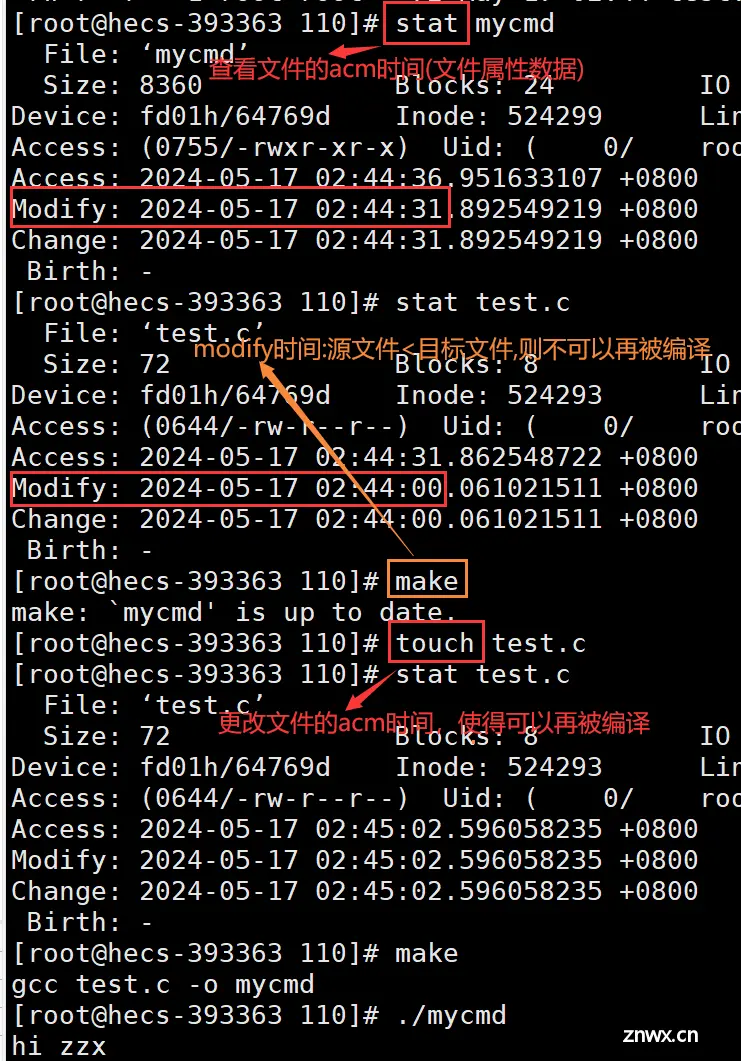
Modify时间的改变会联动使得Change时间改变,因为Modify时间是对文件内容进行修改的时间,影响文件的大小,文件大小也是文件属性,Change时间是对文件属性进行修改的时间。 Access时间是文件被查看的时间,但并不是实时变动的,而是到了一定情况,才会改变,提高了代码的整体效率,减轻了操作系统的负担。
如果第一个目标文件所依赖的文件test.o不存在,则make会在当前文件中找目标文件为test.o的依赖文件,再反向执行依赖方法。
知识点:make、Makefile的语法推导理解:
<code>mycmd:test.o
gcc test.o -o mycmd
test.o:test.s
gcc -c test.s -o test.o
test.s:test.i
gcc -S test.i -o test.s
test.i:test.c
gcc -E test.c -o test.i
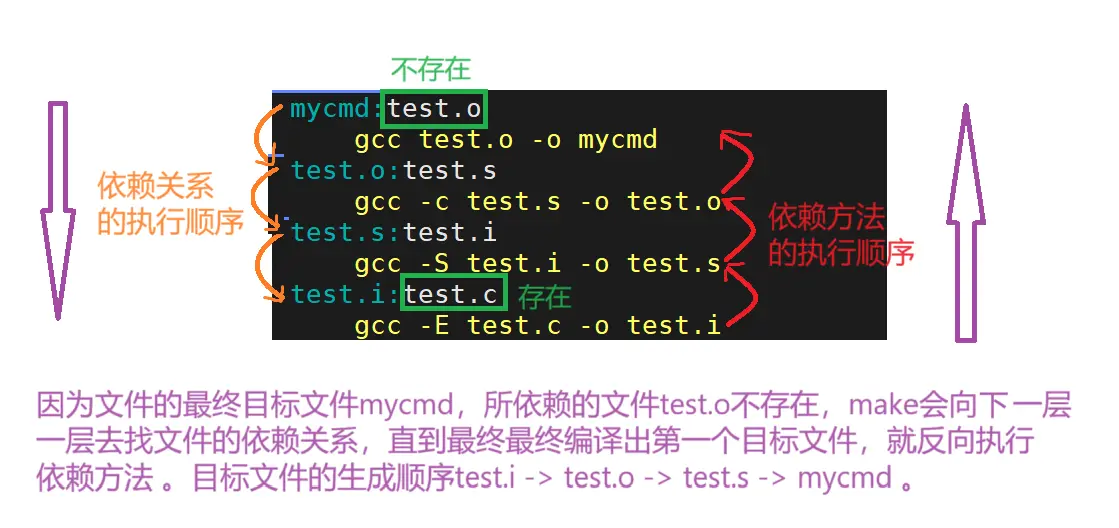
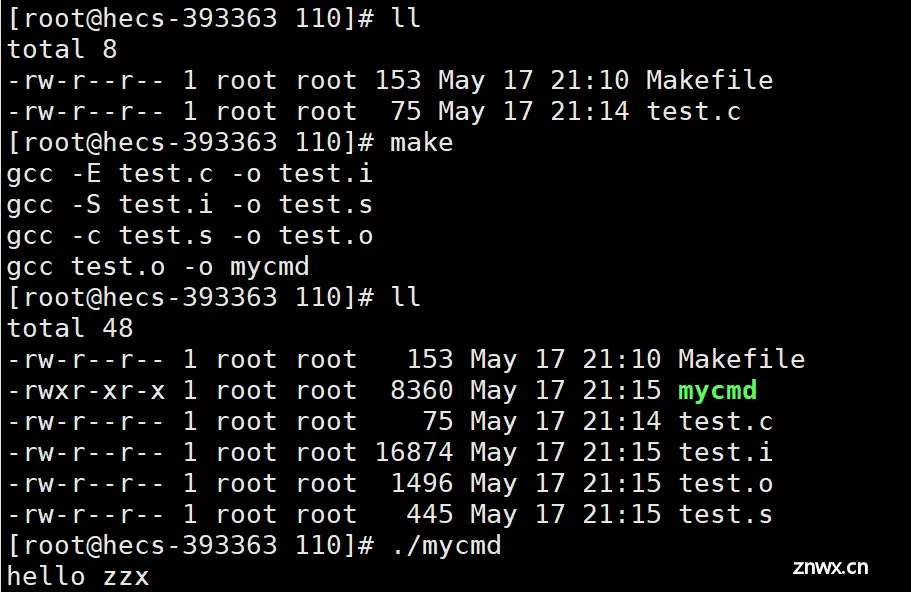
在找寻过程中,如果出现错误,eg:最后被依赖的文件不存在,make就会直接退出,并报错。而对于所定义的命令错误,或者编译不成功,make不搭理它们,仍生成可执行程序。即:make只管文件的依赖关系。
四、语法补充
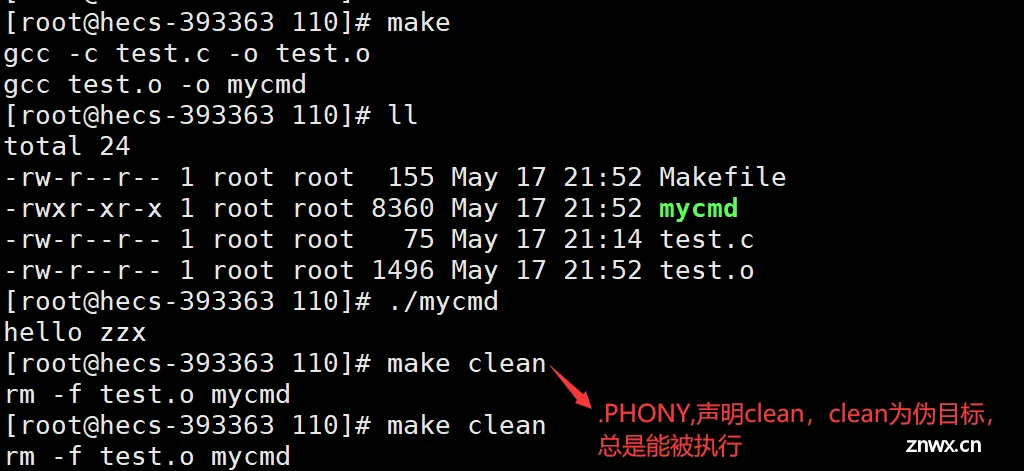
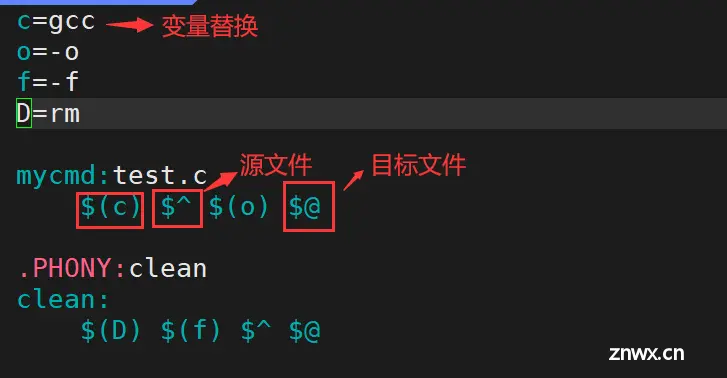
.PHONY :声明伪目标,总是能被执行。
.PHONY 是makefile中的特殊目标,用于声明伪目标。伪目标是个标签,而不是真正的目标文件,用于执行特定的命令序列。由于伪目标不是一个文件,所以 make 无法根据文件是否存在、更新来决定是否执行它。要通过伪目标方式执行其对应的命令,需要在 make 命令后明确指定该目标名称。
.PHONY targetname , targetname为伪目标。声明为.PHONY的文件将不受文件是否存在的影响,make总是认为伪目标是最新的,即:伪目标就可以作为一个总是能被执行的命令。常用来声明clean的目标文件,进行清理项目。
<code>mycmd:test.o
gcc test.o -o mycmd
test.o:test.c
gcc -c test.c -o test.o
.PHONY:clean #声明伪目标,总是能被执行
clean:
rm -f test.o mycmd
变量替换
6. 进度条小程序
一、缓冲区
C语言给IO函数提供了一个缓冲区。从键盘中输入的数据,都被存放到缓冲区中了。缓冲区是个临时存储区,用于存储待处理的数据。当遇到Enter、\n、程序结束等时,缓冲区会进行刷新。
二、回车、换行
\n 作用是换行,光标的位置与上一行相同;\r作用是回车,光标回到该行的开头;Enter作用是回车换行。
倒计时小程序
<code>//Linux下的注释:如果为语言,则方法与语言的注释相同;如果为bash,单行注释采用#
#include<stdio.h>
#include<unistd.h> // 休眠函数的头文件,sleep毫秒、usleep微秒
int main()
{
int cnt = 10;
while(cnt)
{
printf("%-2d\r", cnt); // 以左对齐进行两个位置的输出,printf打印的是单个字符
fflush(stdout); // 刷新缓冲区,将缓冲区中的数据输入到显示器中
usleep(1000000); // 1秒
--cnt;
}
return 0;
}
三、进度条
简易版
// 简易版的进度条
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#define NUM 103
#define Body '='
#define Head '>'
void process()
// 简易版的进度条
#include"processbar.h"
const char *transfer = "|/-\\";
int main()
{
// c++98标准不支持变长数组,vs不支持,Linux支持
// const int n = 103;
// char buffer[n] = {'\0'};
int n = strlen(transfer);
char buffer[NUM];
memset(buffer, '\0', sizeof(buffer));
int cnt = 0;
while(cnt <= 100)
{
~printf("[%-100s][%3d%%][%c]\r",buffer,cnt,transfer[cnt%n]);
fflush(stdout);
usleep(100000);
buffer[cnt++] = Body;
if(cnt < 100) buffer[cnt] = Head;
}
printf("\n");
}
#include"processbar.h"
int main()
{
process();
return 0;
}
升级版
问:进度是多少,进度条知道吗?什么进度?
答:进度条不是单独存在的,它通常是依托于其他应用场景中,eg:下载。
#include"processbar.h"
int FILE_SIZE = 1024*1024*1024; //文件总大小
//模拟一种实际应用场景——下载
void download(Calfc cb) //回调函数的方式
{
srand(time(NULL)^1023);
int total = FILE_SIZE;
while(total)
{
int one = rand()%(1024*1024*5); //单次下载量
total -= one; //未下载量
if(total < 0) total = 0;
double rate = (FILE_SIZE - total)*100.0 / FILE_SIZE; //下载比例
cb(rate); //调用进度条,进行刷新
usleep(10000); //休眠
}
printf("\n");
}
int main()
{
download(process);
return 0;
}
// 简易版的进度条
#include"processbar.h"
const char *transfer = "|/-\\"; //光标转动,表示下载工作仍在进行
char buffer[NUM] = { 0};
void process(double rate) //进度条
{
// c++98标准不支持变长数组,vs不支持,Linux支持
// const int n = 103;
// char buffer[n] = {'\0'};
int n = strlen(transfer);
static int cnt = 0;
if(rate <= 1.0) buffer[0] = Head;
//printf打印颜色:/033[属性;背景颜色;文字颜色\033[0m
printf("[\033[0;44;31m%-100s\033[0m][%.1f%%][%c]\r",buffer,rate,transfer[cnt%n]);
fflush(stdout);
buffer[(int)rate] = Body;
if((int)rate + 1 < 100) buffer[(int)rate + 1] = Head;
cnt++; //不让cnt=rate,尽管rate未更新,但下载工作仍在进行中
}
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<time.h>
#define NUM 103
#define Body '='
#define Head '>'
typedef void (*Calfc)(double);
void process(double rate);
void download(Calfc cb);
7. 调试器gdb
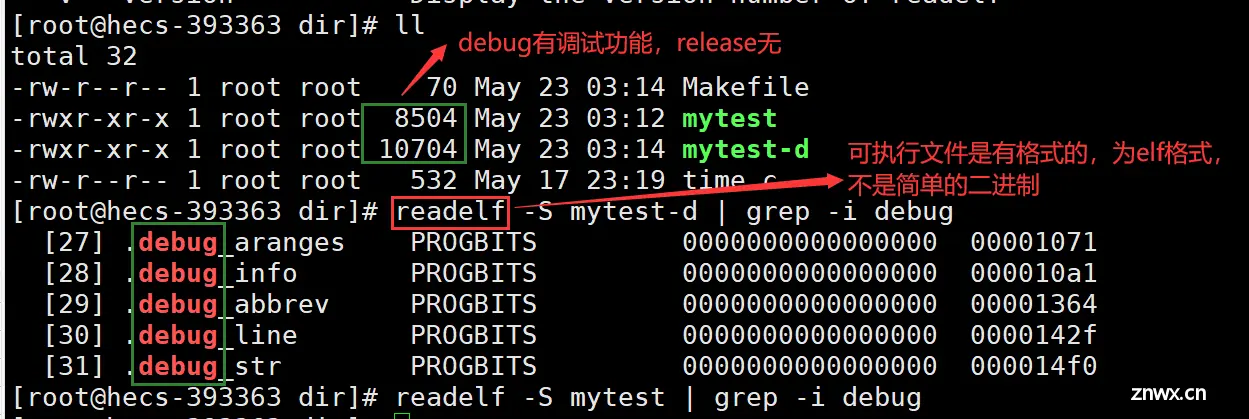
一、程序的发布方式有两种:debug模式、release模式。
在debug模式下形成的可执行程序,添加了调试信息,体积大;在release模式下形成的可执行程序,去除了调试信息,体积小。
debug、release模式在软件开发过程中有着重要的作用,主要为了满足不同阶段的开发需求。debug模式主要用于开发和调试阶段,帮助开发者发现并解决问题;release模式主要用于最终发布和部署,确保产品的稳定性和性能。
二、Linux下gcc/g++编译出来的可执行程序,默认是release模式。
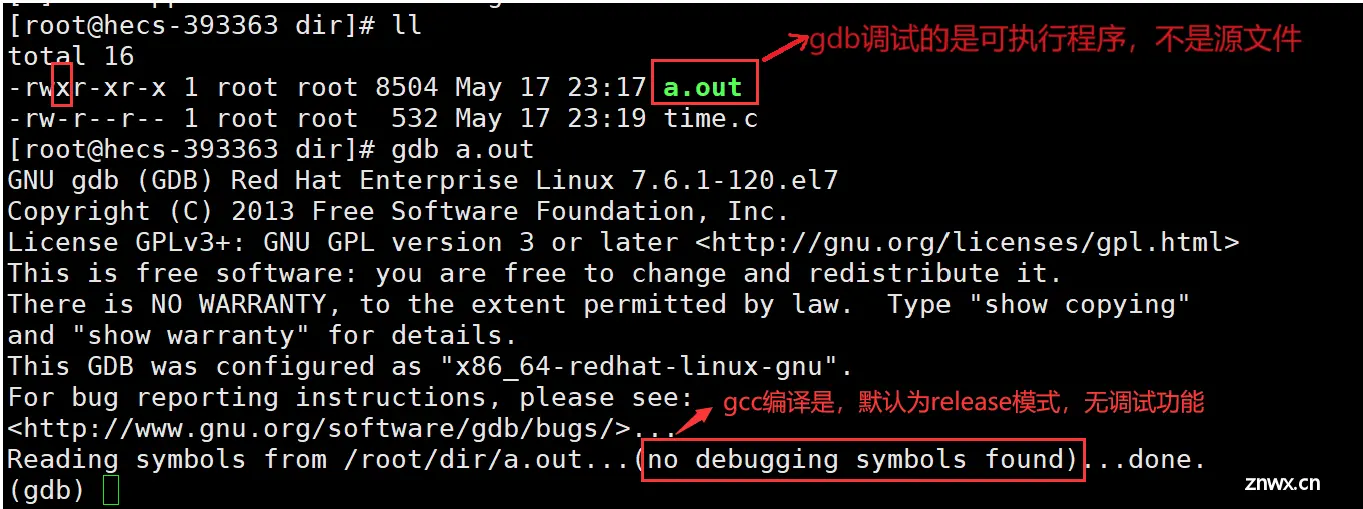
三、如果要使用gdb调试,需要在源代码生成二进制程序时,加上-g选项。
gdb调试的是可执行程序,而不是源代码本身。可执行文件是有格式的,为ELF格式。
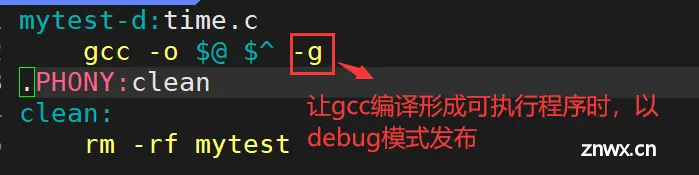
四、相关命令
调试的本质是:找到问题 + 解决问题。
找到问题 —— 查找,范围查找,再进行局部逐行查找。解决问题 —— 根据上下文代码进行分析。
不懂代码逻辑,调试时非常难的。
Tips :gdb具有自动记录最近一条指令的功能。
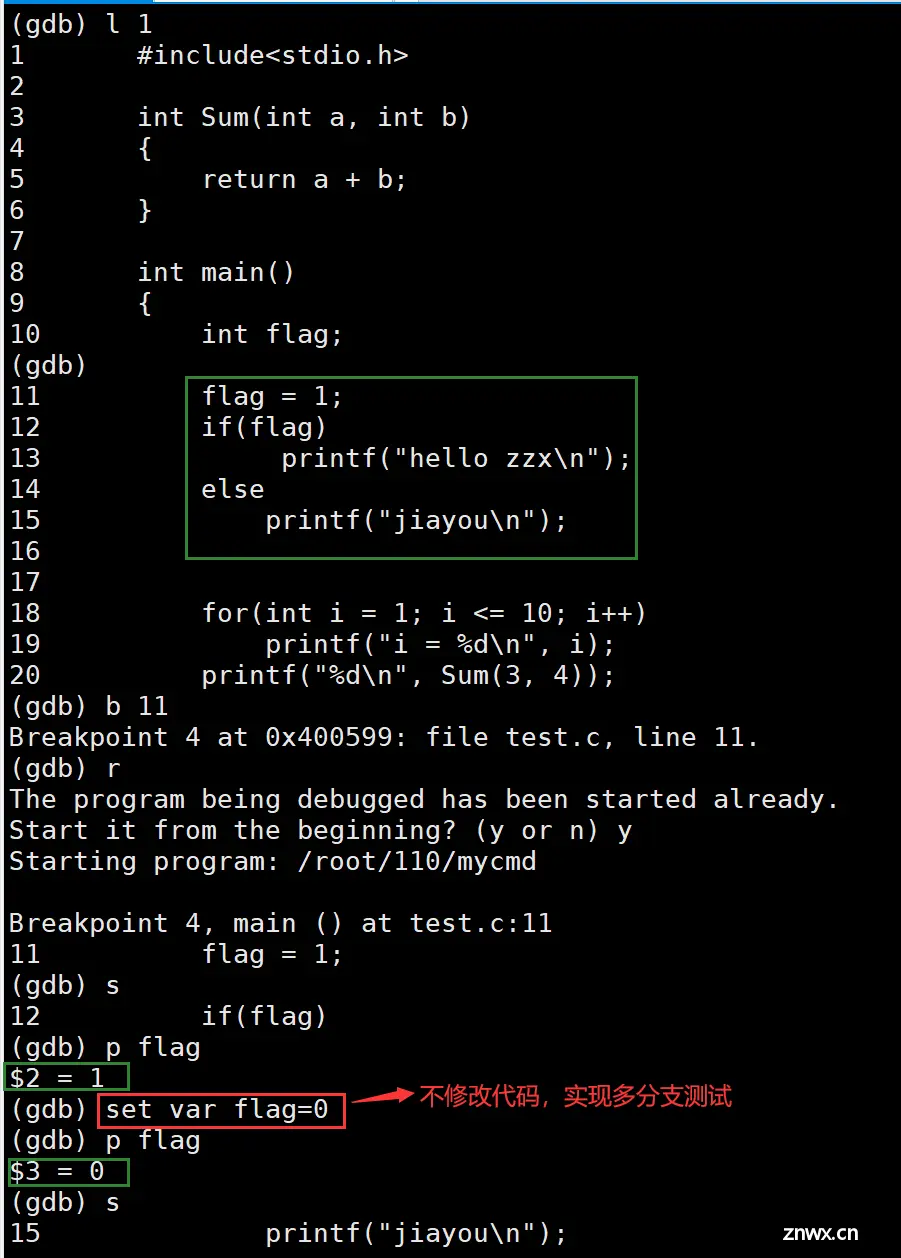
l 行号/文件名:行号/函数名:显示指定行之后的代码。
b 行号/文件名:行号/函数名:对指定的位置打断点。
info b:显示我们所打断点的信息。
d 断点编号:删除断点。
disable/enable 断点编号:使能(开启/禁用)断点。
n:逐过程,不进入函数。相当于VS的F10 (每一行看作一个整体,包括函数)。
s:逐语句,进入函数。相当于VS的F11 (语句是由 ; 组成 , 函数可以由多条语句组成)。
p:显示变量的内容和地址。
display 变量名/&:常显示变量的内容和地址。
undisplay 编号:取消常显示变量的内容和地址。
bt:查看调用堆栈。
r : 重新启动被调试的程序,运行程序。
set var 变量名=值:修改变量的值(不需要修改代码,就可进行多分支测试)。
范围查找:
c:从一个断点运行到下一个断点 (代码中进行局部范围查找) 。
finish:执行到当前函数返回,就停下来 (函数中进行局部范围查找)。
until 行号:在一个范围内,直接运行到指定行 (更小的局部范围查找)。
上一篇: 解决docker一直出现“=> ERROR [internal] load metadata for docker.io/library/xxx“的问题
下一篇: 嵌入式Linux学习: 设备树实验
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。