第三章线性模型
城府阳光 2024-07-16 12:37:07 阅读 96
3.1 线性回归
线性模型的目的是通过学习得到一个属性线性组合的预测函数,基本形式为:f(x) = w1x1 + w2x2 + ... + wnxn + b
机器学习中一般用向量形式表示,即:f(x) = wTx + b,通过学习得到w和b,模型即得以确定。
那么什么样的w和b是我们想要的呢?也就是我们想通过学习得到怎样的w和b呢?
假设yi是第i个样本的真实结果,f(xi) = wxi + b是计算得到的预测结果,显然,使得f(xi)最接近yi的w和b就是我们想要的,对于总体样本来说,使得n个样本的总体预测结果最接近总体真实结果的w和b,自然就是我们想要学习得到的最终结果。
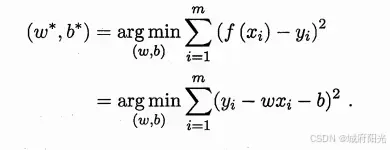
3.2 线性几率回归
对于二分类任务来说,我们一般使用sigmoid函数,也即对数几率函数(也就是神经网络中经常使用的逻辑回归):
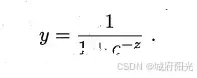
它的图形为:
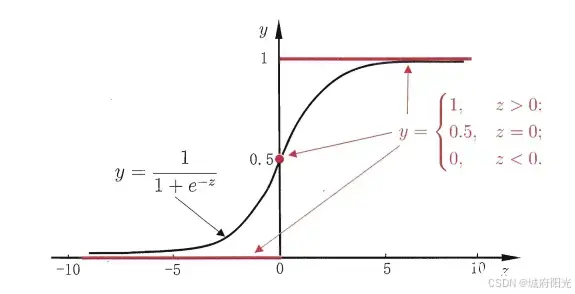
在神经网络中,经常用到sigmoid函数作为激活函数或解决二分类问题,对于多分类,则较多使用softmax函数。
3.3 线性判别分析
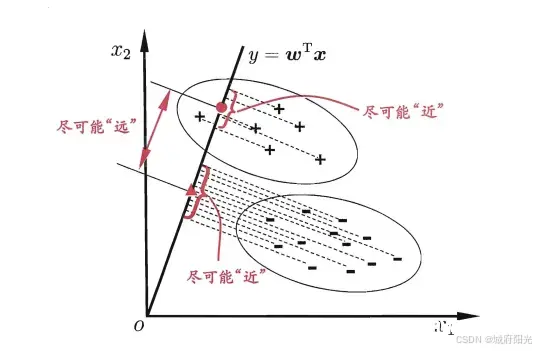
线性判别分析LDA的原理是将样例肉应到一条直线上,使同类样例的投影点尽可能接近,而异类样例的投影点则尽可能远,对于新样例来说,将它投影到直线上,根据投影点的位置远近即可完成样例分类,下面是示意图:
3.4 多分类学习
现实中我们经常遇到不只两个类别的分类问题,即多分类问题,在这种情形下,我们常常运用“拆分”的策略,通过多个二分类学习器来解决多分类问题,即将多分类问题拆解为多个二分类问题,训练出多个二分类学习器,最后将多个分类结果进行集成得出结论。最为经典的拆分策略有三种:“一对一”(OvO)、“一对其余”(OvR)和“多对多”(MvM),核心思想与示意图如下所示。
OvO:给定数据集D,假定其中有N个真实类别,将这N个类别进行两两配对(一个正类/一个反类),从而产生N(N-1)/2个二分类学习器,在测试阶段,将新样本放入所有的二分类学习器中测试,得出N(N-1)个结果,最终通过投票产生最终的分类结果。
OvM:给定数据集D,假定其中有N个真实类别,每次取出一个类作为正类,剩余的所有类别作为一个新的反类,从而产生N个二分类学习器,在测试阶段,得出N个结果,若仅有一个学习器预测为正类,则对应的类标作为最终分类结果。
MvM:给定数据集D,假定其中有N个真实类别,每次取若干个类作为正类,若干个类作为反类(通过ECOC码给出,编码),若进行了M次划分,则生成了M个二分类学习器,在测试阶段(解码),得出M个结果组成一个新的码,最终通过计算海明/欧式距离选择距离最小的类别作为最终分类结果。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。