35_YOLOX网络详解
江畔柳前堤 2024-10-02 13:37:01 阅读 84
1.1 简介
YOLOX是YOLO系列(You Only Look Once)目标检测模型的一个最新变种,由阿里云团队和旷视科技在2021年提出。YOLO系列以其快速、准确的目标检测能力而闻名,而YOLOX在此基础上进行了多方面的改进和优化,旨在提供一个更灵活、可扩展且性能更强的检测框架。以下是关于YOLOX的全面详细讲解:
1. 设计理念
统一架构:YOLOX设计了一个统一的基础网络结构,使得模型可以在训练和推理阶段共享相同的网络架构,这简化了模型的部署流程并提高了效率。可扩展性:通过模块化设计,YOLOX允许研究人员轻松地插入或替换不同的组件,比如 Backbone(主干网络)、Neck(颈部网络)以及Head(头部网络),以适应不同任务需求或进行算法创新。高性能与实时性:优化了模型结构和训练策略,确保在保持高检测精度的同时,也能实现实时或接近实时的处理速度。
2. 技术亮点
Decoupled Head:YOLOX引入了解耦头(Decoupled Head)的设计,将分类分支和框回归分支分开,这有助于模型更好地学习这两种不同类型的任务特征,提升检测性能。SimOTA (Similarity-based One-Stage Object Detection Assignment):这是一种新颖的动态锚框分配策略,它根据预测框与真实框之间的相似度来动态分配正负样本,从而解决了传统方法中手工设置阈值的问题,提高了训练效率和检测精度。Mosaic Data Augmentation:采用马赛克数据增强技术,通过随机裁剪和拼接图像,增加了训练数据的多样性,有助于模型泛化能力的提升。YOLOX also uses other common practices in modern object detection models, such as:
Weighted Boxes Fusion (WBF):在多尺度测试中融合预测框,提高检测边界框的精确度。Cosine Annealing with Warmup:使用余弦退火学习率调度,并结合预热策略,优化模型训练过程中的学习率调整,促进模型收敛。Auto-Augment:自动数据增强策略,根据算法搜索最优的数据增强策略,进一步提升模型鲁棒性。
3. 训练与推理流程
训练:YOLOX在训练过程中,首先通过解耦头分别优化分类和定位任务,同时利用SimOTA策略动态分配样本,结合丰富的数据增强技术,以及精心设计的学习率策略,使得模型能够高效学习。推理:YOLOX在推理时,由于其统一的架构设计,可以快速输出物体检测结果。通过解耦头生成类别预测和边界框预测,然后依据一定的阈值筛选出最终的检测结果。
4. 性能表现
YOLOX在多个标准数据集上(如COCO、PASCAL VOC等)展示了优越的性能,不仅在精度上取得了显著提升,同时保持了高效的推理速度,适合于实际应用中的实时目标检测任务。
5. 应用场景
因其出色的性能表现,YOLOX广泛应用于各种领域,包括但不限于视频监控、自动驾驶、无人机巡检、智能安防、医疗影像分析等需要快速准确目标检测的场景。
总之,YOLOX作为YOLO系列的最新成员,凭借其创新的设计思路和优化策略,在目标检测领域展现了强大的竞争力,为研究人员和开发者提供了一个高效、灵活且高性能的检测框架。
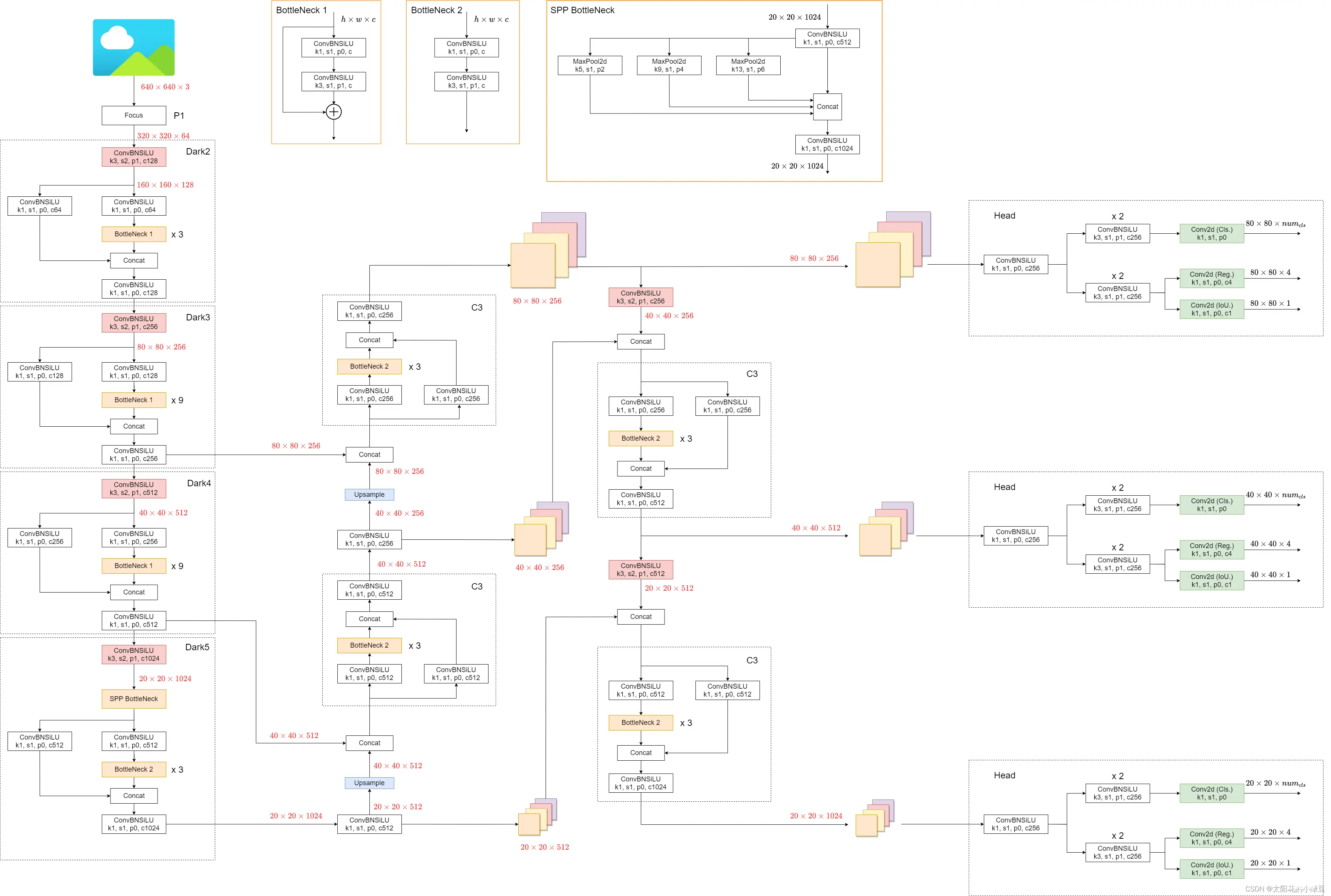
1.2 网络结构
YOLOX是在YOLOV5的结构基础上进行构建的。
参考:https://blog.csdn.net/qq_37541097/article/details/125132817
YOLOX的左侧和YOLOV5是一模一样的,只有最右侧虚线框的head不一样而已。
(注意这里的YOLOV5是V5.0版本,backbone部分和V6.1有区别,
图中的focus模块在6.1版本中已经替换为6x6卷积核)

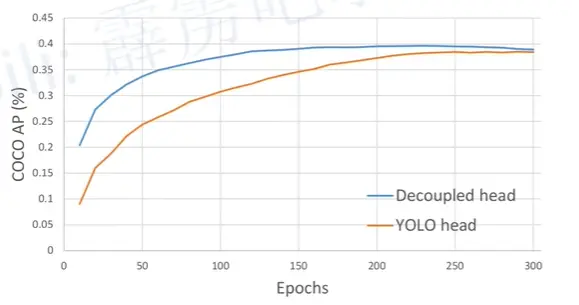
YOLOX的检测头: YOLOX采用了解耦的检测头,提升了AP加速了收敛。
那么什么是解耦的检测头呢?在1x1卷积之后并行了两个3x3卷积,然后下面的3x3卷积又并行两个1x1卷积,这三个1x1卷积分别用来预测目标类别(图中的cls)、预测预测框的回归参数(reg)、预测置信度(Iou)。
注意检测头之间的参数是不共享的。

1.3 Anchor-free
YOLOX在其更新的版本中引入了anchor-free(无锚点)的检测方法,这是一种不同于传统YOLO系列及其他一些目标检测模型中使用固定anchor boxes的设计。在anchor-free方法中,模型直接预测目标物体的中心点及其宽高,而不是基于预设的anchor boxes进行偏移和尺寸调整。这一改变简化了模型结构,降低了超参数调优的复杂性,并有可能提升模型的灵活性和准确性。
具体到YOLOX中的anchor-free机制,主要特点包括:
直接预测边界框: 模型直接预测每个候选区域(通常是网格或像素点)上的物体边界框的四个参数,通常是中心点坐标(x, y)和框的宽度(w)、高度(h),而不是像anchor-based方法那样预测相对于预设anchor的偏移量。
中心点密集采样: 为了覆盖整个图像区域并提高检测精度,YOLOX可能采用在特征图上对每个像素或每隔一定步长的像素进行中心点候选采样,这些候选点都有潜力成为预测框的中心。
损失函数调整: 由于不使用anchor boxes,损失函数的设计也会有所不同,通常需要直接衡量预测框与真实框之间的距离,如使用IoU(Intersection over Union)作为损失函数的一部分,来优化预测框的位置和尺寸。
简化训练流程: Anchor-free设计减少了对anchor boxes的敏感性和调优需求,使得模型训练流程更加简洁,降低了过拟合的风险,并可能加快收敛速度。
提高适应性: 无锚点设计使得模型对不同尺寸和比例的目标更加公平对待,避免了因anchor配置不当导致的检测偏差,提高了模型在多样本、多尺度目标检测任务中的适应性和准确性。
综上所述,YOLOX中的anchor-free机制是对目标检测领域的一次创新尝试,它通过消除预设anchor的限制,提升了模型的灵活性和泛化能力,同时也简化了模型结构和训练过程,是现代目标检测算法发展的一个重要趋势。

1.4 损失计算
obj损失的意思是,如果当前这个样本它被划分为正样本的话,那么它的GT标签就为1,如果被分为负样本,GT的标签为0。
Npos代表正样本的个数。
1.5 正负样本匹配SimOTA
YOLOX中的SimOTA,全称Similarity-based One-Stage Object Detection Assignment,是一种先进的目标检测训练样本分配策略。它被设计用来优化目标检测模型在训练阶段的正负样本分配,特别是在单阶段检测器(如YOLO系列)中的应用。SimOTA的关键贡献在于它摒弃了传统基于阈值的硬性正负样本划分方法,转而采用基于预测框与真实框之间相似度的动态分配策略,提高了训练样本的利用率和模型的检测性能。以下是SimOTA的主要特点和工作原理:
工作原理
计算相似度: 首先,对于每一个预测框(无论是anchor-based还是anchor-free设计中的候选框),计算其与所有真实框之间的相似度,这个相似度通常基于两者的交并比(IoU)以及分类置信度。
动态阈值: 不同于固定阈值来区分正负样本,SimOTA根据预测框与真实框之间的相似度分布动态设定阈值。这意味着,模型会自动调整正负样本的划分,以确保每个真实框至少有一个高质量的正样本与之对应,同时合理控制负样本的数量,保持正负样本比例的平衡。
优化匹配: 在确定了正负样本后,SimOTA还会进一步优化正样本的分配,确保每个预测框尽可能与最匹配的真实框关联,即使该预测框可能不是所有预测框中IoU最高的。这种优化旨在提升模型对难检目标的学习能力。
提升训练效率与效果: 通过动态且优化的样本分配,SimOTA不仅提高了训练数据的利用效率,还显著提升了模型的检测精度。它帮助模型在训练初期就能获得更准确的梯度信号,加速收敛过程,同时减轻了对大量负样本或难负样本的依赖,降低了过拟合风险。
优势
减少人工干预: 动态阈值设定避免了手动设置正负样本划分阈值,使模型更加自适应。提高样本质量: 确保每个真实框至少有一对应高质量正样本,提升了训练的有效性和精确性。优化资源分配: 根据目标的难易程度和检测框的质量智能分配训练资源,有助于提高训练效率和模型性能。增强模型鲁棒性: 通过优化样本分配,模型在面对复杂场景和尺度变化较大的目标时表现更稳定。
optimal Transport Assignment:最优运输分配

为了方便理解举个例子:五角星是城市,圆圈是牛奶供应基地。现在需要牛奶基地对所有城市进行供应牛奶,那么就需要考虑到一个运输成本的问题,假设运输成本仅仅由距离决定,很显然123由基地A负责,456由基地B负责,这样运输成本是最低的。

那么在我们匹配正负样本的过程中:
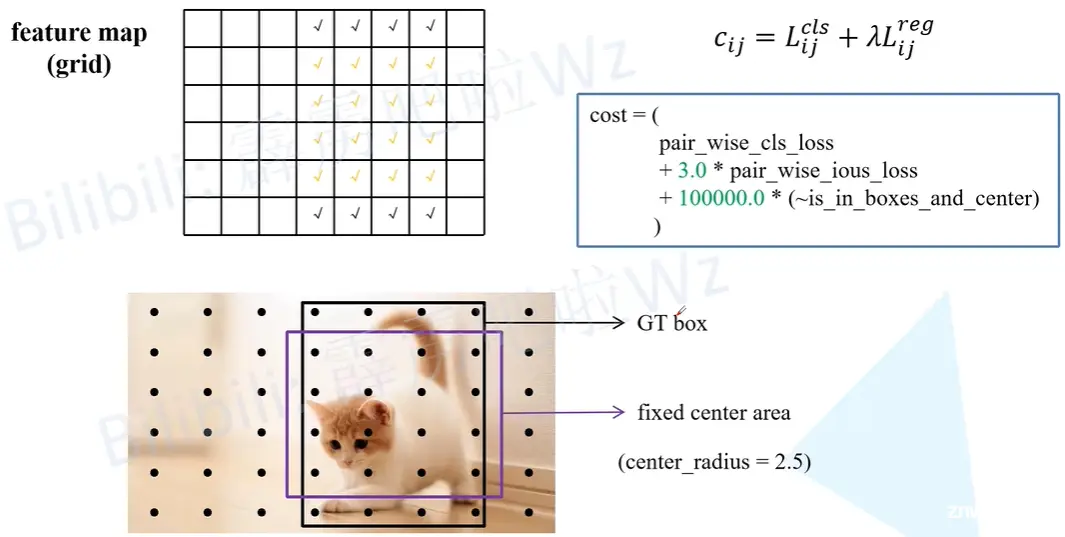
首先我们会对样本做一个预筛选操作。先找出所有落入GT和fixexd center area的anchor point,然后这些又分为两部分,一部分是既在GT也在fixexd center area的anchor point,也就是橙色的钩,一部分是在交集之外的anchor point,也就是用黑色钩标注的部分。
在代码中计算cost时分为三个部分,首先第一部分是分类损失,第二部分是回归损失,第三项在公式中没体现出来,“~“是取反操作,”is in boxes and center“代表交集(橙色的√),那么取反就是不在这个区域内(也就是黑色的√),前面乘上了非常大的系数,那么损失就会非常大。
那么我们在最小化cost过程中,就会逼迫它优先选择交集内的anchor point,如果不够再去取黑色的√。
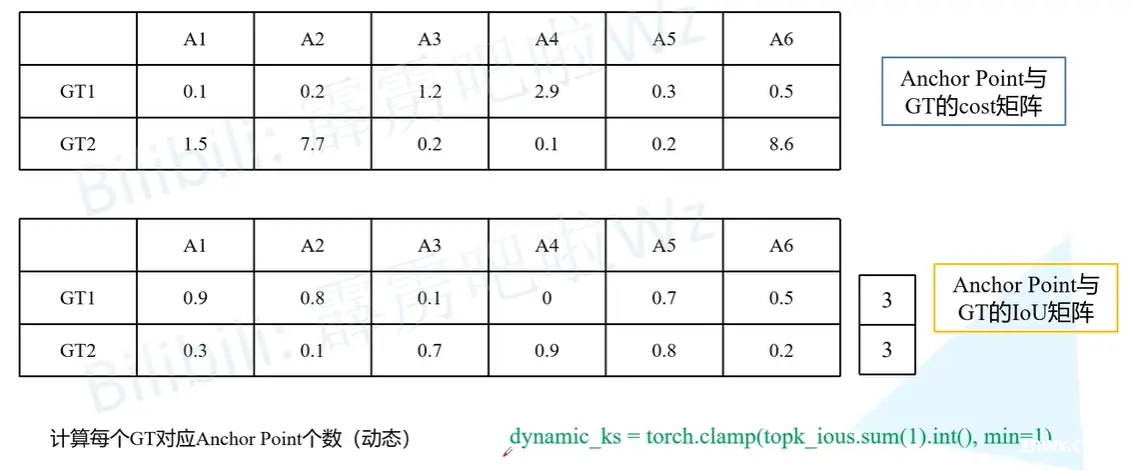
如何利用simOTA去分配正负样本呢?
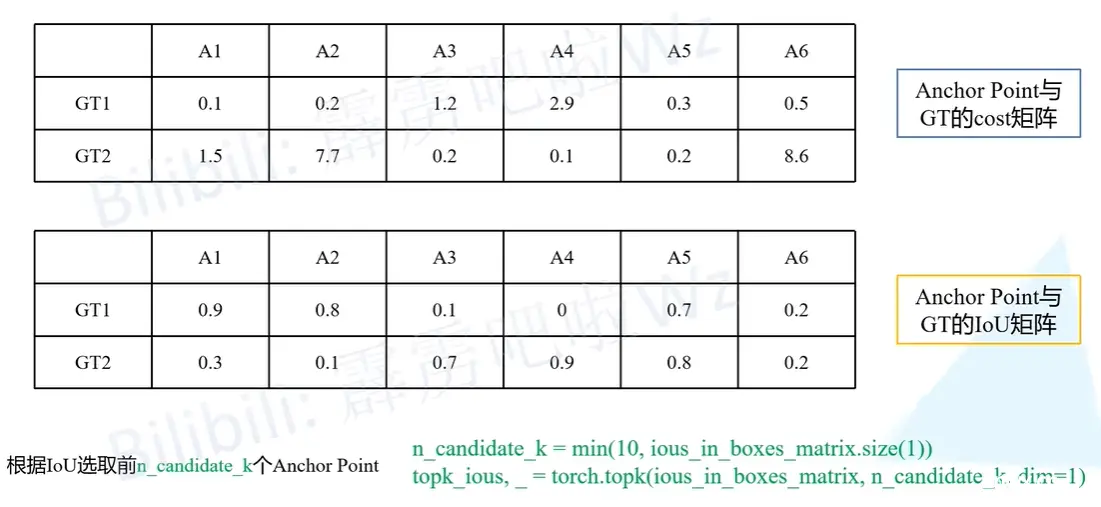
举个例子:假设我们在之前先预选了一部分anchor point(黑色和橙色),然后与每个GT都去计算一个cost,结果会得到一个cost矩阵,然后我们用anchor point与GT计算IOU得到IOU矩阵(这里记录的是每个anchor point 预测的目标边界框和每个GT之间的IOU),这个IOU矩阵不用单独计算,在之前计算回归损失(采用IOULOSS)的时候计算过了。
然后我们会计算一个n_candidate_k,这个值是从10和橙色√anchor point个数中取最小值。这里的值是6所以n_candidate_k取6。然后再选取前n_candidate_k个anchor point,因为前面值是6所以这里就取6个,也就是全取了。
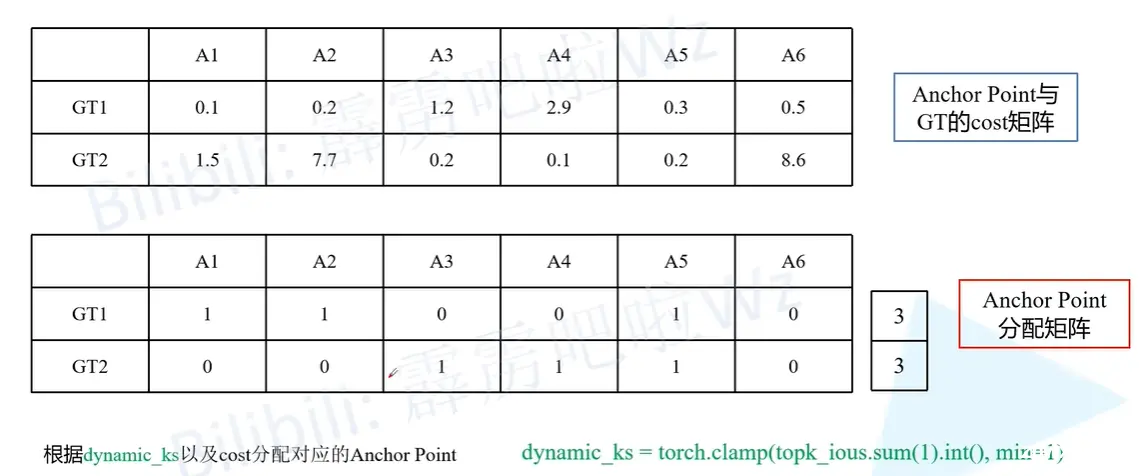
然后我们再看通过筛选之后的IOU矩阵,接下来会计算一个dynamic_ks参数。这个参数对应论文中的dynamic k estimation strategy。也就是说我们针对每一个GT所分配的正样本的个数是一不一样的,是动态计算得到的。
代码的实现就是将每一行求和然后向下取整。比如GT1是3,GT2也等于3,就是说对GT1和GT2分配三个anchor point

然后我们分配dynamic_ks个anchor point,根据cost最小的原则选择cost最小的前三个。如下图所示。然后根据上面的cost矩阵构建了一个分配矩阵。
那么现在又有一个问题:为啥A5对应两个GT啊?它到底是GT1还是GT2啊?
作者为了解决这个问题又加了一步。对于这种情况,我们再来比较A5相对于GT1和GT2的损失,然后将这个A5分配给较小cost的那个GT.
那么现在我们已经找到全部的正样本了,那么除了正样本以外其他的全部都是负样本,然后我们就可以结合损失计算的公式取计算YOLOX对应的总损失了。
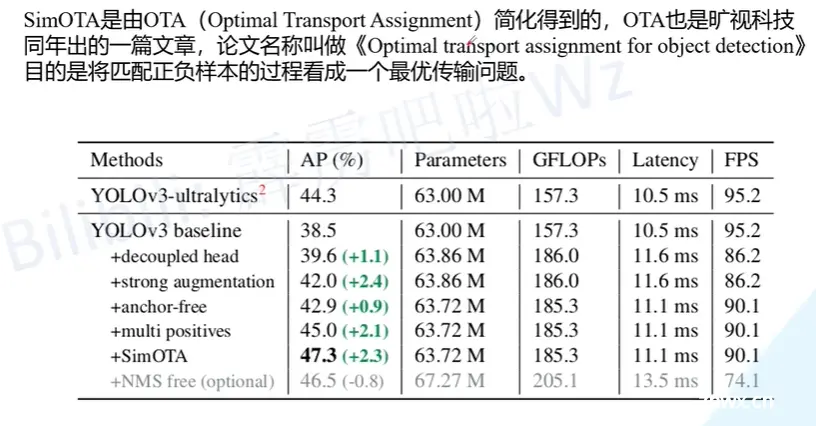
1.6 模型性能
La tency指的是推理时间。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。