浅谈 Linux 中的 core dump 分析方法
Grayson Zheng 2024-08-31 16:37:01 阅读 87
文章目录
一、什么是 core dump二、发生 core dump 的原因1. 空指针或非法指针引起 core dump2. 数组越界或指针越界引起的 core dump3. 数据竞争导致 core dump4. 代码不规范
三、core dump 分析方法1. 启用 core dump2. 触发 core dump2-1. 因空指针解引用而崩溃2-2. 通过 SIGSEGV 信号触发 core dump
3. gdb 分析 core dump
总结
在 Linux 系统开发领域中,core dump(核心转储)是一个不可或缺的工具,它为我们提供了在程序崩溃时分析程序状态的重要线索。当程序因为某种原因(如段错误、非法指令等)异常终止时,Linux 系统会尝试将程序在内存中的映像、程序计数器、寄存器状态等信息写入到一个名为 core 的文件中,这个文件就是所谓的 core dump。
对于开发者而言,core dump 文件如同一块宝藏,其中蕴含着程序崩溃时的现场信息。通过对 core dump 文件的分析,我们可以了解到程序在崩溃时的内存布局、函数调用栈、变量值等重要信息,从而帮助我们快速定位问题原因,优化代码,提高程序的健壮性。
在本文中,我们将探讨 Linux 中 core dump 的分析方法。通过一些简单的案例来演示 core dump 分析的实际应用,帮助读者更好地理解和掌握这一技术。
一、什么是 core dump
核心转储(core dump),在汉语中有时戏称为吐核,是操作系统在进程收到某些信号而终止运行时,将此时进程地址空间的内容以及有关进程状态的其他信息写出的一个磁盘文件。这种信息往往用于调试。
在 UNIX 系统中,常将“主内存称为核心(core),因为在使用半导体作为内存材料之前,便是使用核心(core)。而核心映像(core image)就是 “进程”(process)执行当时的内存内容。当进程发生错误或收到 “信号”(signal)而终止执行时,系统会将核心映像写入一个文件,以作为调试之用,这就是所谓的核心转储(core dump)。
有时程序并未经过彻底测试,这使得它在执行的时候一不小心就会找到破坏。这可能会导致核心转储(core dump)。幸好,现行的 UNIX 系统极少会面临这样的问题。即使遇到,程序员可以通过核心映像(core image)调试程序来找到错误原因。
——引用:核心转储_百度百科 (baidu.com)
可以这样去理解,core dump 是程序运行时在突然崩溃的那一刻的一个内存快照。操作系统在程序发生异常而异常在进程内部又没有被捕获的情况下,会把进程此刻内存、寄存器状态、运行堆栈等信息转储保存在一个 core 文件里。这个 core 文件是二进制文件,可以使用 gdb、elfdump、objdump 或者 Windows 下的 windebug 进行打开此文件,并分析里面的具体内容,找出 core dump 的具体原因,并解决问题。
[!NOTE]
core 是在半导体作为内存材料前的线圈,当时用线圈当做内存材料,线圈叫做 core。用线圈做的内存叫做 core memory。故 core dump 也可称为 core memory dump,真是个充满历史味道的词。
在 Linux 系统下开发,时常会遇到程序突然崩溃了,且没有留下任何日志的情况,这时就可以查看 core 文件。从 core 文件中分析原因,通过 gdb 看出程序挂在哪里,分析前后的变量,找出问题的原因。
二、发生 core dump 的原因
C/C++ 程序员遇到的比较常见的一个问题,就是自己编写的代码, 在运行过程中出现了意想不到的 core dump。程序发生 core dump 的原因是多方面的,不同的 core dump 问题有着不同的解决办法。同时,不同的 core dump 问题解决的难易程度也存在很大的区别。有些在短短几秒钟内就可以定位问题,但是也有一些可能需要花费数天时间才能解决。这种问题是对软件开发人员的极大的挑战。笔者从事 C/C++ 语言的软件开发工作多年,前后解决了许多此类问题,久而久之积累了一定的经验,现把常见 core dump 总结一下。
1. 空指针或非法指针引起 core dump
空指针或非法指针(野指针、悬空指针)引起 core dump 是一种最常见的核心转储,大致可以有 3 种原因导致程序出现异常:
对空指针进行解引用等操作;
声明指针变量后未进行初始化,并直接进行操作,极大概率引发 core dump,此类未经初始化的指针,统称野指针;
对某个指针,调用了 <code>free 函数或者 delete 函数,该指针指向的空间已经被释放,但未将该指针重新指向 NULL,此类指针成为悬空指针。对悬空指针再次操作,也会引发 core dump;
此类问题通常是代码编写时的疏漏造成的,属于低级 bug,也比较容易解决的问题。Linux 平台常用的 core dump 文件分析工具是 gdb,调试一下产生的 core 文件,对照代码定位问题出现的原因,可以轻松解决问题。
2. 数组越界或指针越界引起的 core dump
提到这个,笔者不由得想起互联网大厂百度的一道 C 语言面试题,如下代码:
#include <stdio.h>
int main()
{
int i;
int array[6];
for (i = 0; i < 8; i++) {
array[i] = 0;
printf("Grayson Zheng\n");
}
return 0;
}
问:以上代码中的 printf 函数会执行多少次?
这个问题的答案在不同操作系统下有不同的答案,当下只讨论 Linux 系统的结果,执行该程序,结果如下:
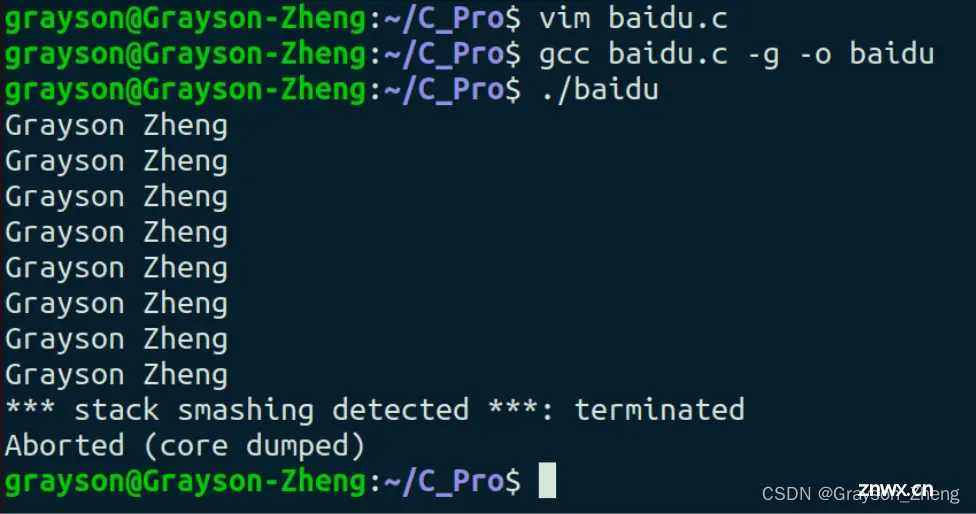
可以看出,在打印了 8 次之后,程序结束,但这并不是一次正常的结束,而是一次 core dump。不难看出这是数组越界导致的内存踩踏,数组定义了 6 个元素,遍历完 6 个元素之后,还对数组之外的内存进行了操作,从而引发了这次的 core dump。
这种情况还相对简单,而指针越界引发的 core dump,有的是就比较简单,有的就属于一种隐藏比较深的 core dump 了。遇到这种问题时,在调试 core 文件,尽管也能定位到代码行,但是有可能呗定位到的那行代码本身并没有什么问题,它只是一个 “被陷害者”。
根据经验,这种 core dump 问题很可能是其他代码处理过程中的内存越界造成的(亲身经历:一个指针越界导致内存踩踏,让 7.5 万台机器拆包重流,经济损失估计超过 40 w。当然,我不是那个写 bug 的人,哈哈),通常由以下两个原因引起:
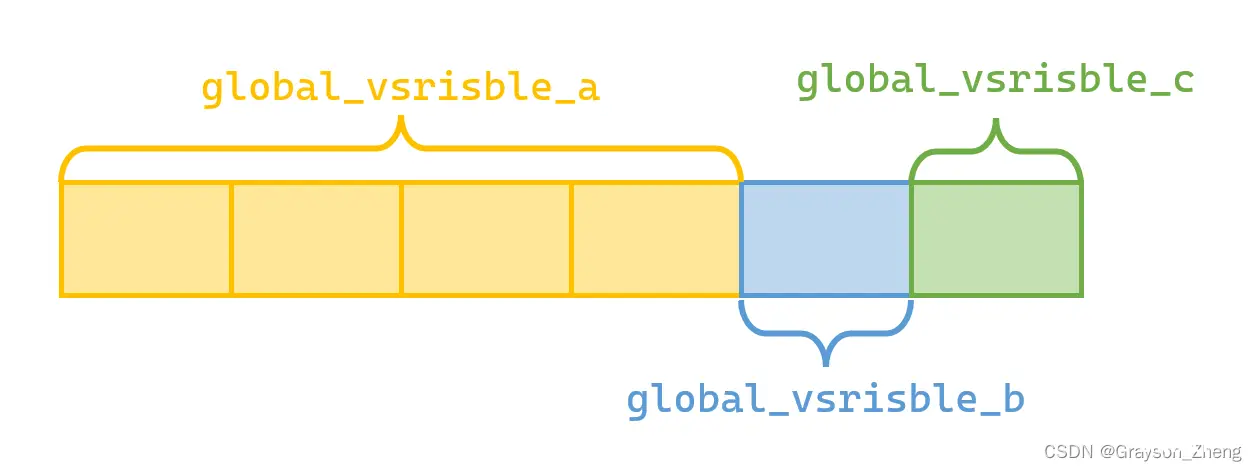
假如有以下三个全局变量:
<code>int global_vsrisble_a;
char global_vsrisble_b;
char global_vsrisble_c;
在不同操作系统中,这个三个全局变量在内存的位置可能不一样,以 Ubuntu 为例,三个全局变量的内存位置分布如下图所示:
假设在某些做了如下代码所作的事:
<code>#include <stdio.h>
int global_vsrisble_a = 0x11223344;
char global_vsrisble_b = 0x55;
char global_vsrisble_c = 0x66;
int main()
{
printf("%p = 0x%X\n%p = 0x%X\n%p = 0x%X\n", &global_vsrisble_a,
global_vsrisble_a, &global_vsrisble_b, global_vsrisble_b,
&global_vsrisble_c, global_vsrisble_c);
char *p_1 = (char *)(&global_vsrisble_a);
p_1 += 2;
int *p_2 = (int *)p_1;
*p_2 = 0x09ABCDEF;
printf("%p = 0x%X\n%p = 0x%X\n%p = 0x%X\n", &global_vsrisble_a,
global_vsrisble_a, &global_vsrisble_b, global_vsrisble_b,
&global_vsrisble_c, global_vsrisble_c);
return 0;
}
[!CAUTION]
以上代码只是为了示范,现实情况并不可能如此。
执行代码后如下:
0x6447cc49a010 = 0x11223344
0x6447cc49a014 = 0x55
0x6447cc49a015 = 0x66
0x6447cc49a010 = 0xCDEF3344
0x6447cc49a014 = 0xFFFFFFAB
0x6447cc49a015 = 0x9
从执行结果来看,global_vsrisble_b 和 global_vsrisble_c 的值被破环。
举这个例子是为了说明,如果通过调试工具定位到是因为 global_vsrisble_b 的值被破坏了,很可能不是操作 global_vsrisble_b 的代码有问题,而是操作 global_vsrisble_a 或者 global_vsrisble_c 失误,导致了 global_vsrisble_b 的出错,进而引发 core dump。
内存变量的值莫名其妙出现奇怪的值。跟上面的情况有点类似,也是因为有些变量相邻问题被覆盖原有的值。例如,执行了 memcpy、strcpy 等函数(string.h 涉及到复制功能的函数,在复制过程中是不会检查是否有越界的风险的)引起的 core dump。对于这类问题,肯定是代码走到了某个特殊的逻辑里面,代码处理缺少必要的保护而引起的。
此类 core dump 可以通过复现 bug,对比前后两次的 core 文件,找出内存变量存在的某种共性特征,根据这个特征来分析解决问题。
[!NOTE]
曾经在工作中遇到过一个 core bump,起因是对一段未初始化的缓冲存储区做字符串搜索(搜索并不会引发 core dump)。但是代码流程走了很长一段之后,对一个与缓冲存储区相邻的变量执行了操作,导致了 core dump。
3. 数据竞争导致 core dump
多线程访问全局变量,如果不进行适当的同步保护,确实可能导致内存值异常,从而引发不可预测的行为,甚至可能导致程序崩溃并生成核心转储文件(core dump)。这种问题通常称为 “数据竞争” 或 “竞态条件”(race condition)。
竞态条件是指两个或多个线程同时访问共享数据,并且至少有一个线程在修改数据时未进行适当的同步。这可能导致以下问题:
数据不一致:多个线程读取和修改全局变量时,可能会导致数据处于不一致的状态。程序崩溃:未同步的访问可能导致非法的内存访问,从而引发段错误(segmentation fault),导致程序崩溃并生成核心转储文件。
4. 代码不规范
初学者有时候编译一个程序,出现了一整页的编译错误,其实这种情况也不用担心,很可能就是某一行代码多了几个字符,当把这些代码删去再编译,几百个编译错误全都消失了。
有些时候,程序发生 core dump 的根本原因还是程序员自己进行程序设计时的编码失误造成的,这种代码失误绝大多数都是因为没有严格遵守相应的代码编写规范(比如用 0 做为除数等)。所以,要从根本上杜绝或者减少程序 core dump 的发生,还是要从严格遵守代码编写规范来做起。
三、core dump 分析方法
1. 启用 core dump
默认情况下,程序运行崩溃导致 core dump,是不会生成 core 文件的,因为系统的 RLIMIT_CORE(核心文件大小)资源限制,默认情况下设置为 0。
使用 ulimit -c 命令可以查看 core 文件的大小,其中 -c 的含义是 core file size,单位是 blocks 也就是 KB 的意思。ulimit -c 命令后面可以写整数,表示生成写入值大小的 core 文件。如果使用 ulimit -c unlimited 设置无限大,则任意情况下都会产生 core 文件。
以下命令可在用户进程触发信号时启用 core dump 生成,并使用合理的名称将核心文件位置设置为 /tmp/。请注意,这些设置不会永久存储。
ulimit -c unlimited
echo 1 > /proc/sys/kernel/core_uses_pid
echo "/tmp/core-%e-%s-%u-%g-%p-%t" > /proc/sys/kernel/core_pattern
[!IMPORTANT]
后面两条命令在运行时,即使是加了
sudo执行,也可能会被提示权限不足。这可能是由于 shell 的重定向在命令前已经处理完成,因此重定向操作并没有被提升到超级用户权限,这就导致了 “Permission denied” 的错误。可以通过以下命令来解决这个问题:
echo 1 | sudo tee /proc/sys/kernel/core_uses_pid
echo "/tmp/core-%e-%s-%u-%g-%p-%t" | sudo tee /proc/sys/kernel/core_pattern
顺便解释一下 "/tmp/core-%e-%s-%u-%g-%p-%t" 的各个参数的含义:
%e:导致 core dump 的程序的可执行文件名。%s:导致 core dump 的信号编号。%u:导致 core dump 的程序的实际用户 ID。%g:导致 core dump 的程序的实际组 ID。%p:导致 core dump 的程序的进程 ID。%t: core dump 发生时的时间戳(自 epoch 时间以来的秒数)。
因此,/tmp/core-%e-%s-%u-%g-%p-%t 会生成包含如下信息的 core 文件:
/tmp/core-<executable>-<signal>-<uid>-<gid>-<pid>-<timestamp>
举个例子,如果一个进程名为 my_program,用户 ID 为 1000,组 ID 为 1000,进程 ID 为 12345,并且在 1617701234 时间点崩溃于信号 11,则生成的 core 文件名将是:
/tmp/core-my_program-11-1000-1000-12345-1617701234
2. 触发 core dump
我们使用两个简单的 C 程序作为示例。
2-1. 因空指针解引用而崩溃
文件名为 example.c:
#include <stdio.h>
void func()
{
int *p = NULL;
*p = 13;
}
int main()
{
func();
return 0;
}
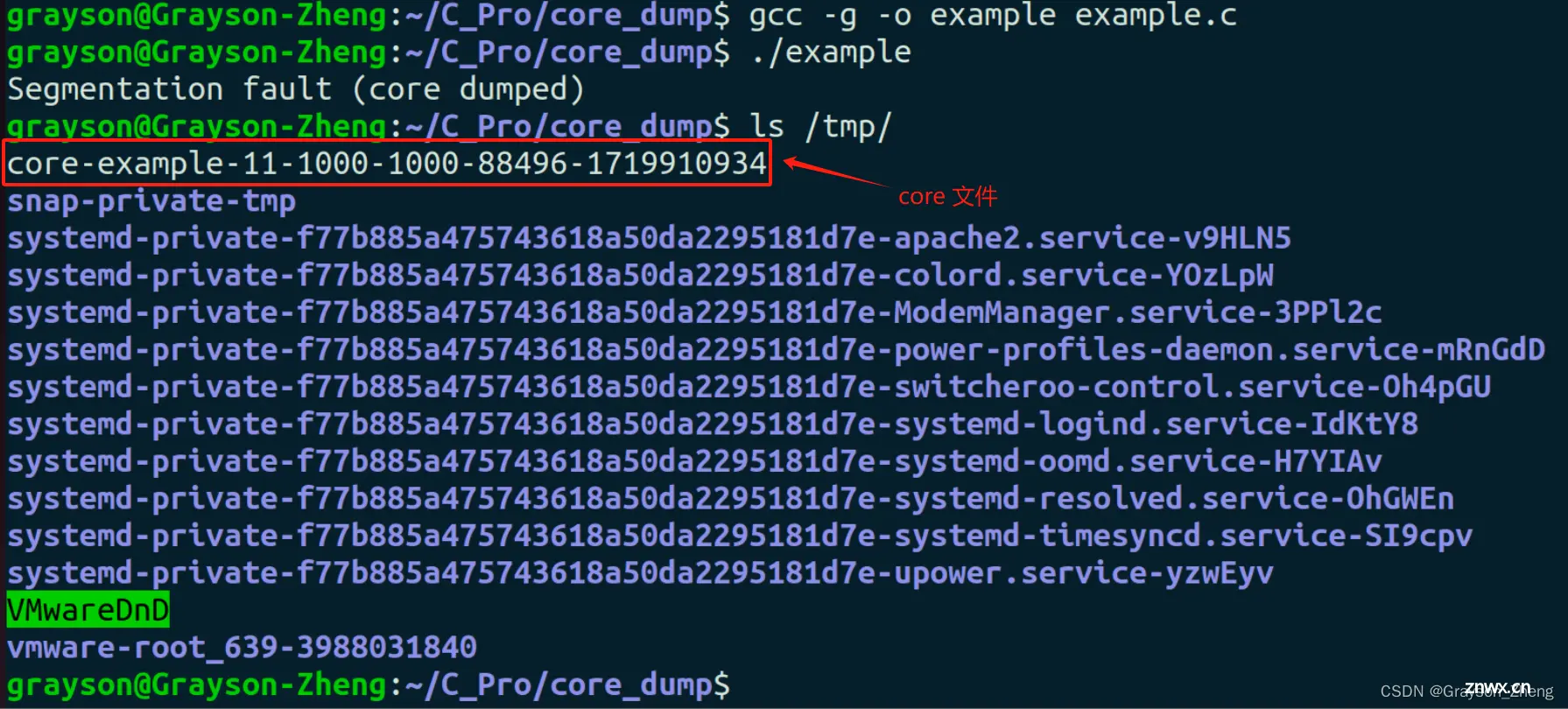
编译并运行程序:
gcc -g -o example example.c
./example
运行程序时后,会在 /tmp/ 文件夹下生成一个 core 文件。
2-2. 通过 SIGSEGV 信号触发 core dump
文件名为 <code>example2.c:
#include <stdio.h>
#include <unistd.h>
int global_num;
int main()
{
while(1) {
printf("global_num = %d\n", global_num++);
sleep(1);
}
return 0;
}
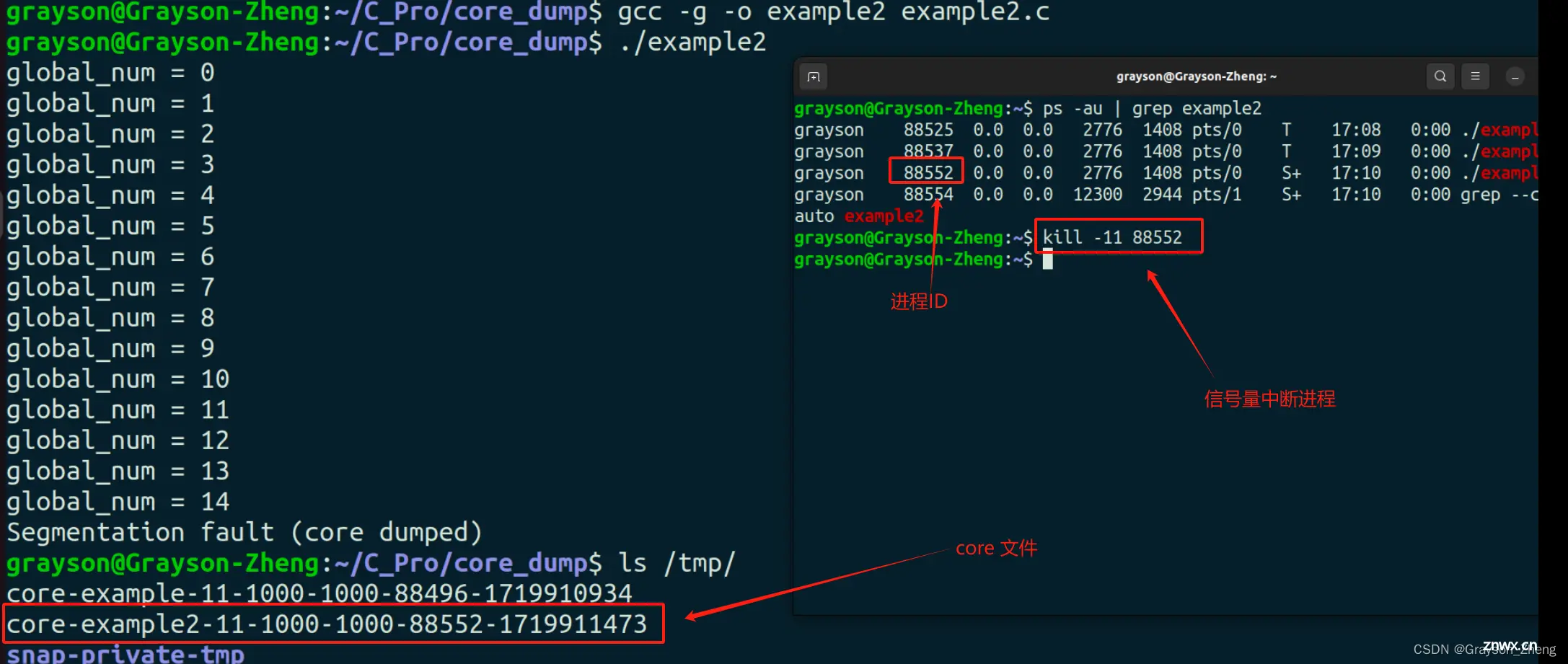
编译并运行程序:
gcc -g -o example2 example2.c
./example2
运行程序时后,在另一个终端查找进程的 PID,并用 kill -11 加上 PID,向进程发送段错误信号,结束掉进程。之后会在 /tmp/ 文件夹下生成一个 core 文件。
3. gdb 分析 core dump
两个例子都是段错误导致的 core dump,所以用 gdb 调试的方法也是一样的,命令格式如下:
<code>gdb <program_name> <core_dump_file>
比如先调试第一个例子的 core 文件,则输入 gdb example,再加上 core 文件名,命令如下(建议先提前复制 core 文件名,不知道为什么,按 Tab 键不给补齐):
gdb example /tmp/core-example-11-1000-1000-88496-1719910934
随后可以看到,gdb 提示在代码第 6 行的地方出现了段错误,如下图:
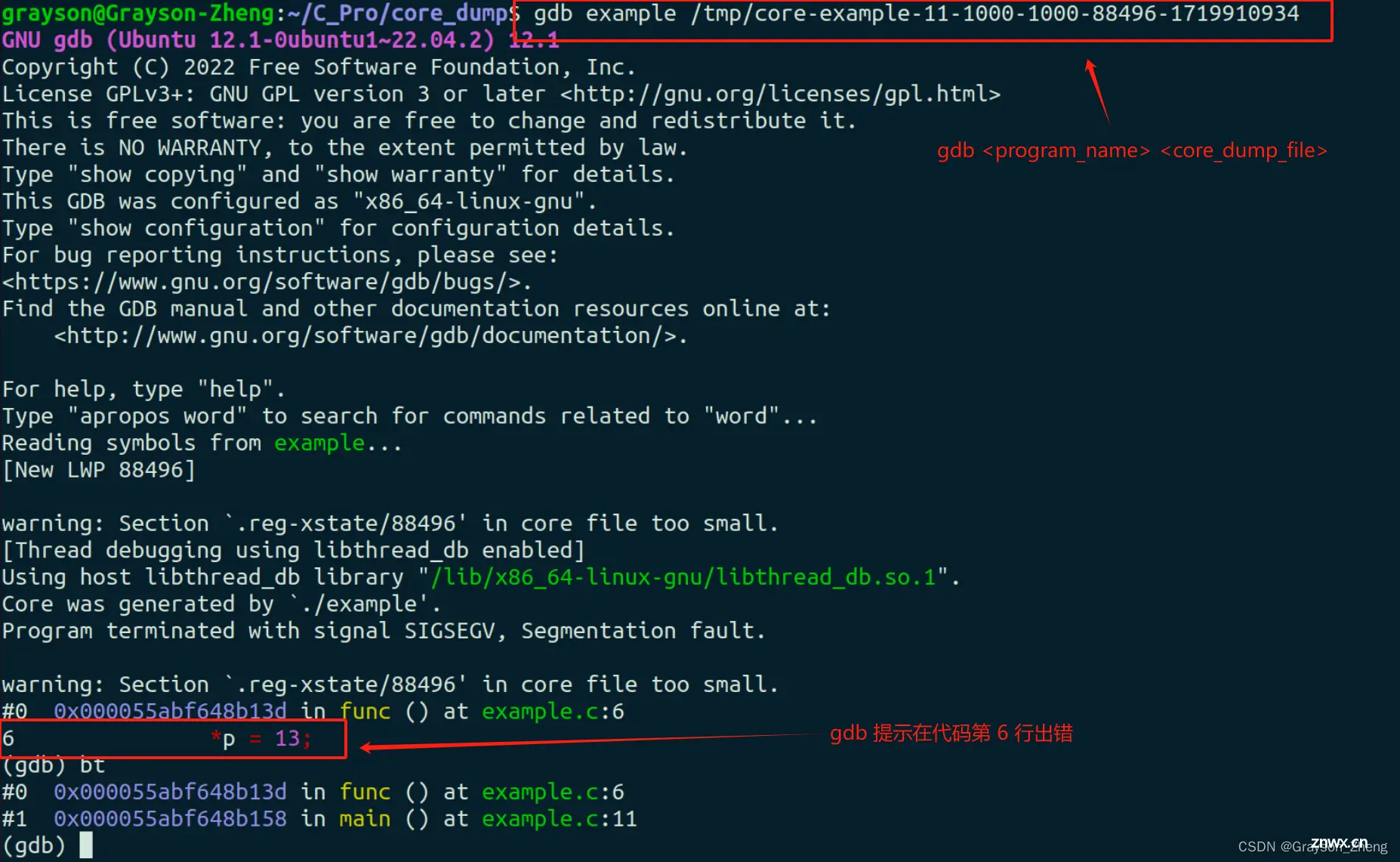
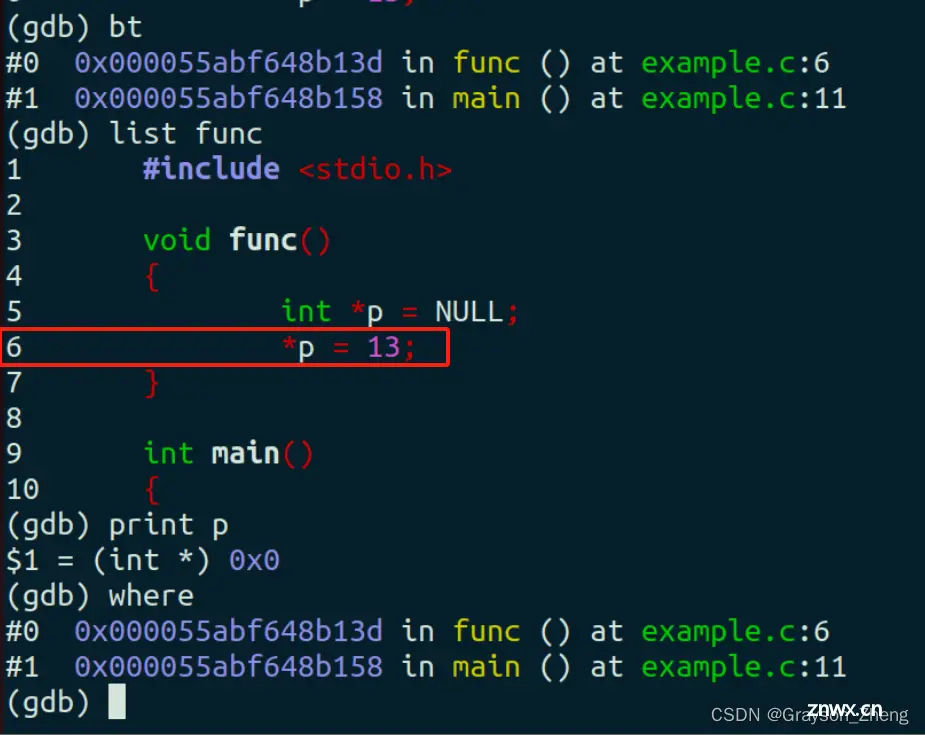
如果函数关系调用关系很复杂,可以用 <code>bt 命令(全称 backtrace,堆栈的意思)查看调用堆栈(where 命令也有同样功能),如下图可知是在调用 func 函数时产生的段错误,可用 list 命令查看,具体就是 list 加函数名,如下图。找到提示错误的那一行代码,print 命令可以打出 p 的值,由下图可知,p 是空指针,不能进行解引用操作。
输入 quit 或 exit 可以退出 gdb。
第二个例子,也是同样用 gdb 打开 core 文件:
<code>gdb example2 /tmp/core-example2-11-1000-1000-88552-1719911473
执行结果如下图:
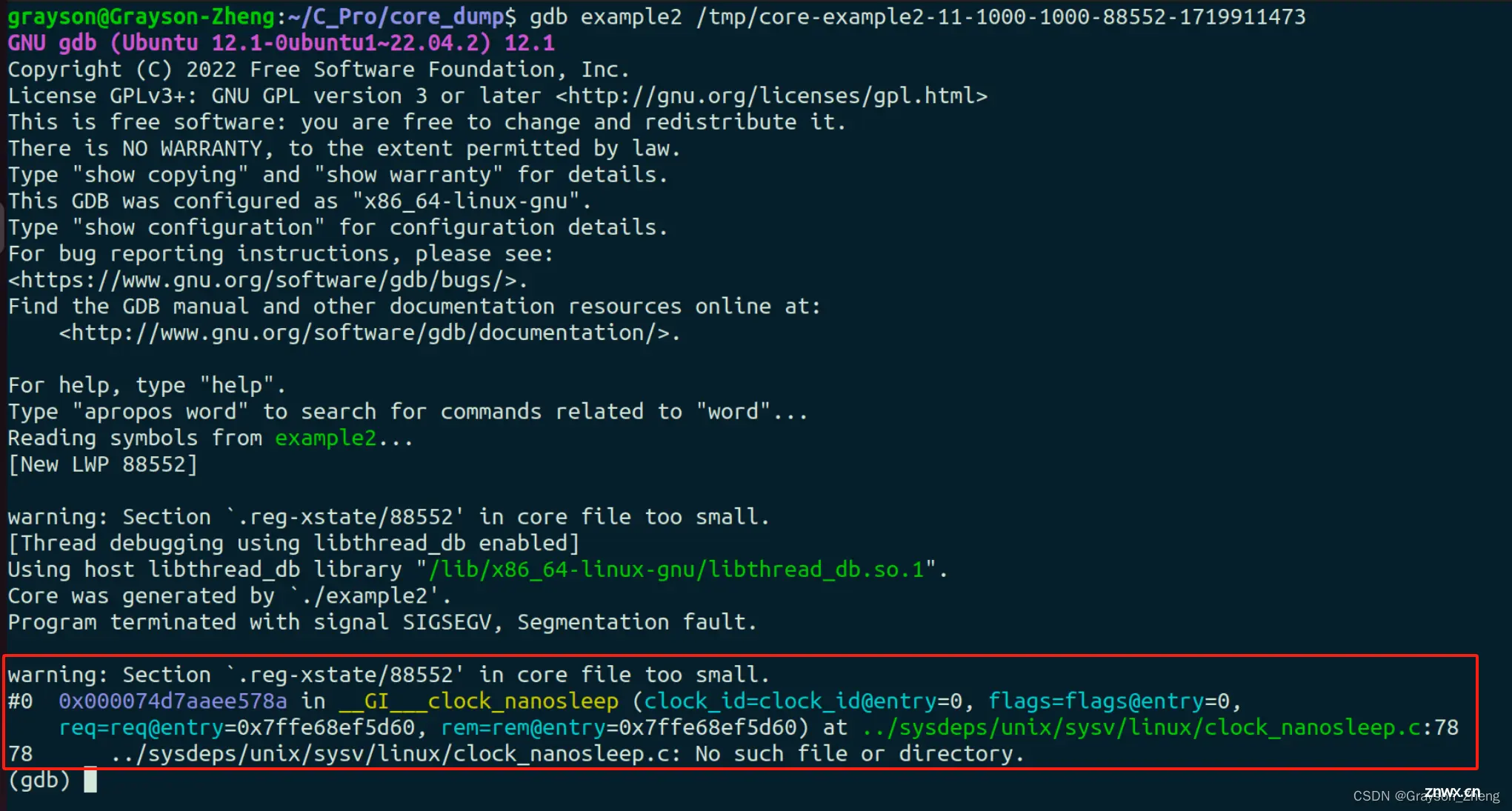
虽然这个段错误是因为我们人为地发送了 <code>SIGSEGV 信号,导致了程序地段错误,而在打开 core 文件后,可以看出在执行 __GI___clock_nanosleep 函数时,遇到了段错误。
[!NOTE]
通常情况下,分析 core dump 问题,除了 core 文件之外,还会结合程序的 log 信息和系统的 log 信息(包括 kernel log、systemd log 等)一起分析。
当然人为故意制造出来的 core dump,有时候是分析不出来的。所以这个例子的作用在于分析的过程,也顺便告诉大家,不是所有的 core dump 都可以分析出具体原因。
如果我们不事先知道是由 SIGSEGV 信号导致段错误的,首先要用 bt 命令找到函数的调用关系链:

由上图可知,先是在 <code>main 函数调用了 __sleep 函数,接着 __sleep 函数调用了 __GI___nanosleep 函数,__GI___nanosleep 函数调用了 __GI___clock_nanosleep 函数,到这里,执行到了 __GI___clock_nanosleep 函数的第 78 行时,发生了段错误,使程序崩溃。
此时,我们是没办法通过 list 命令去找出问题的,因为栈区的那三个函数是封装后的库函数,根本看不到源码:
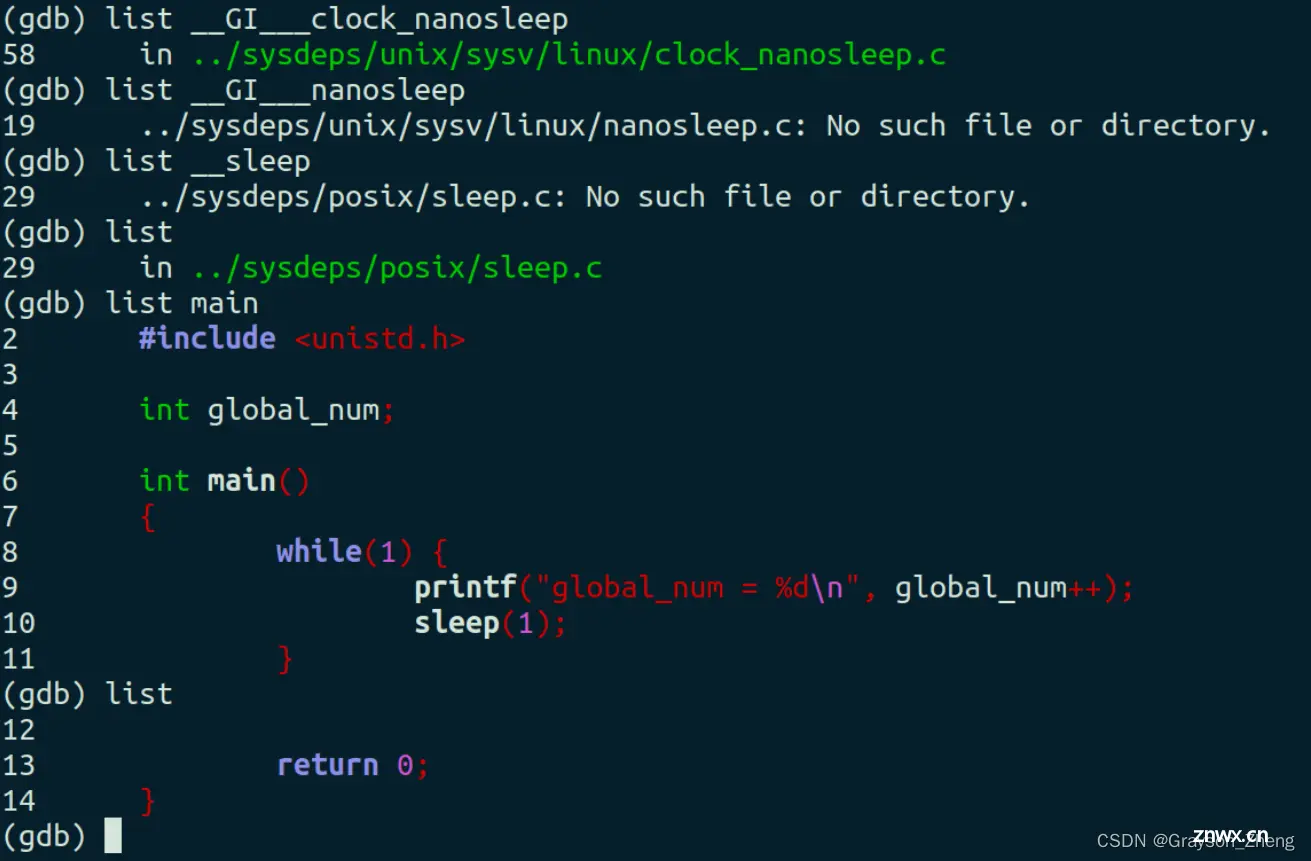
在输入 <code>bt 命令查看堆栈情况时,有出现了两个变量,分别是 req 和 rem。使用过nanosleep 函数的小伙伴可能会很眼熟这两个变量,因为这个两个变量是 nanosleep 函数的形参,原型是 int nanosleep(const struct timespec *req, struct timespec *rem)。
用 print 命令打印出两个变量的地址:
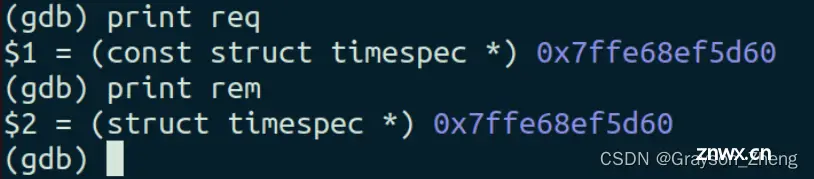
使用 <code>info registers 命令查看寄存器状态,检查程序在崩溃时的上下文:
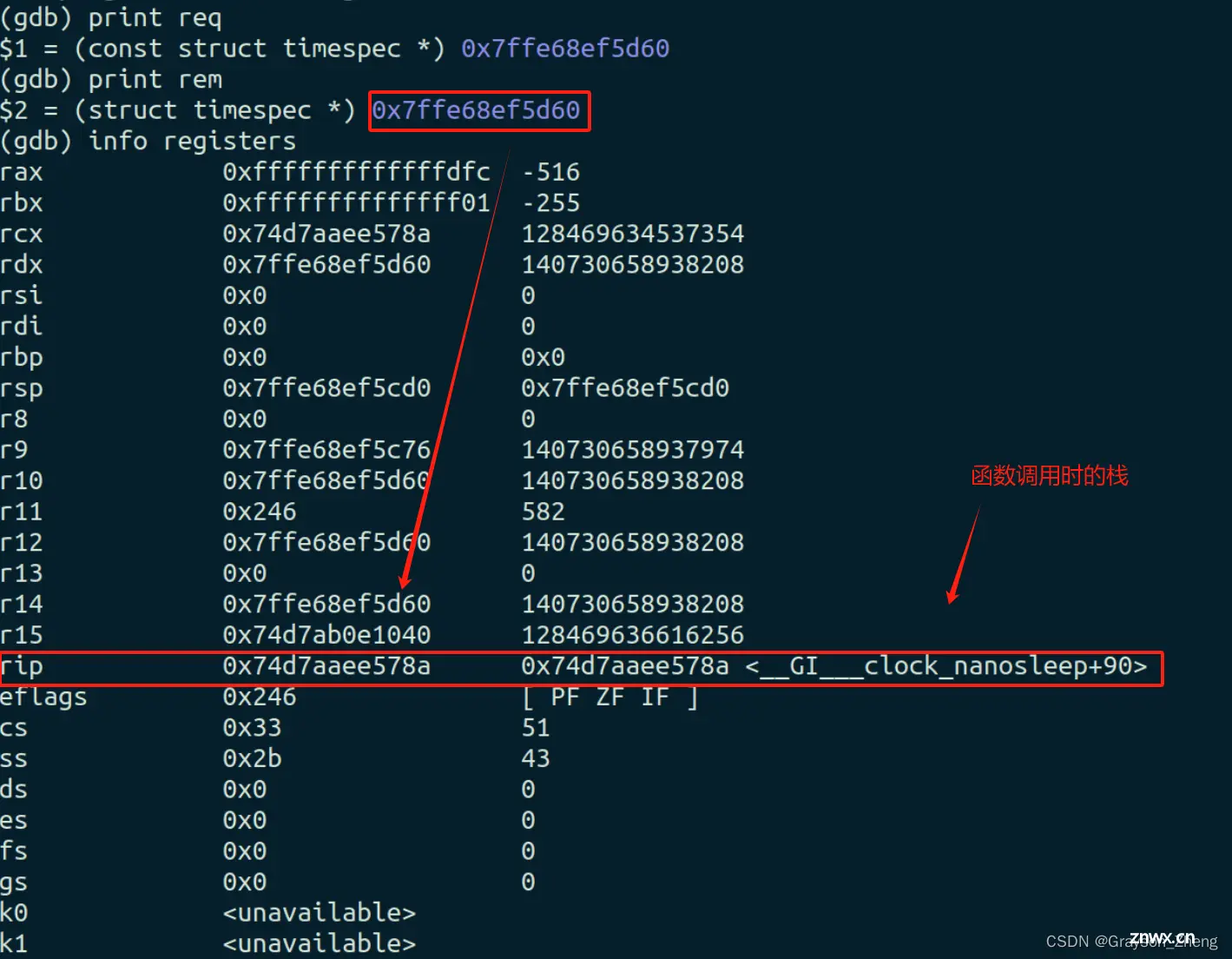
从寄存器状态来看,没有明显的错误迹象,函数的栈帧空间没什么问题,形参的位置和值也没什么问题,所有值看起来都在正常范围内。
当下是没办法直接了当的判断为人为干预造成 core dump,如果此时想到了信号会引发段错误,可以用 <code>info signals 命令查看信号情况:
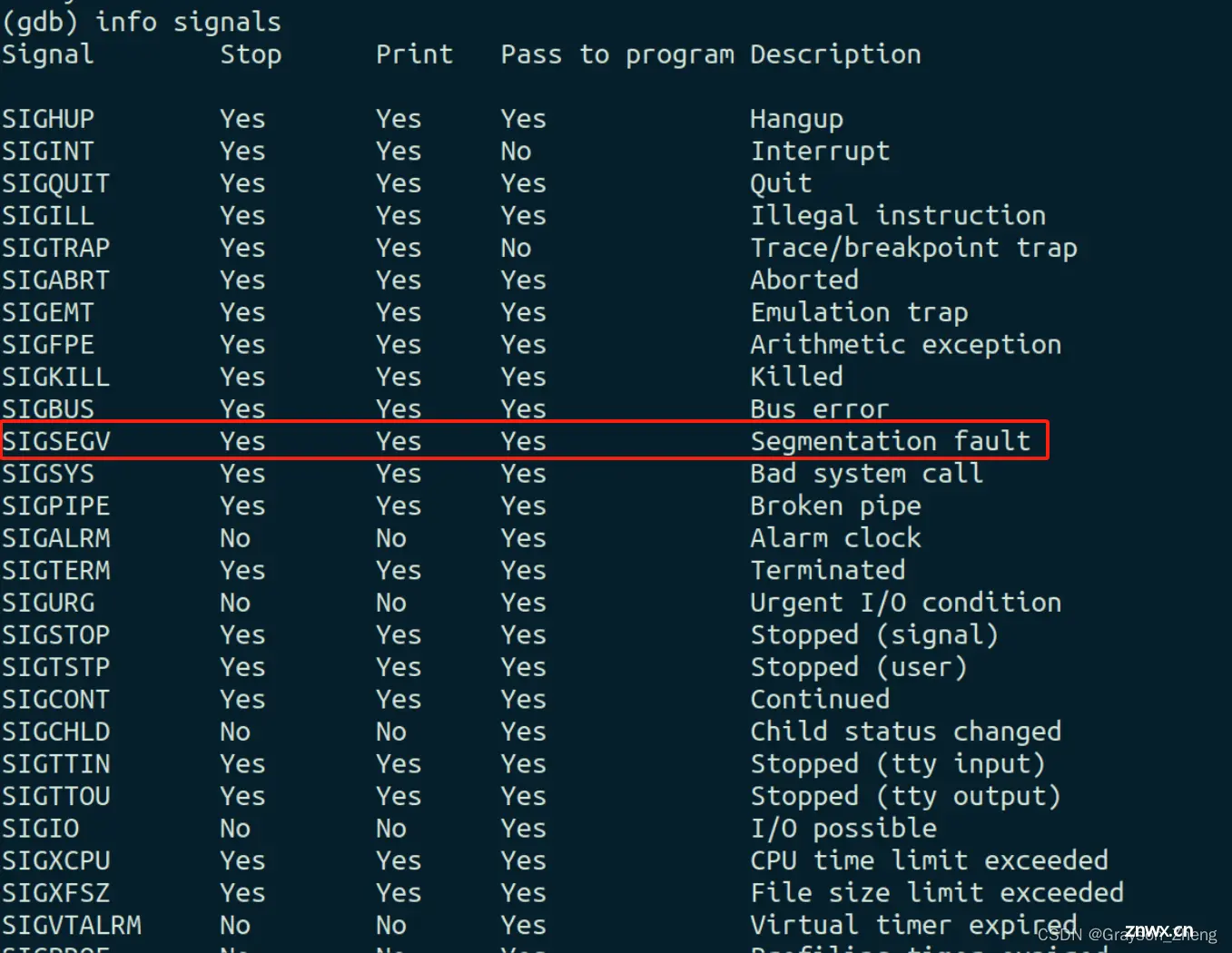
从 <code>info signals 的输出中可以看出,SIGSEGV(Segmentation fault)信号是设置为在程序接收到该信号时停止执行并打印信息的。也就说,可以人为地使用 kill -11 发送了 SIGSEGV 信号来终止程序并生成 core dump。
总结
分析 core dump 的具体原因不可能仅凭两个案例就学会,本文只是提供一个基本的排除思路和方法。通过查看调用堆栈、源代码和变量的值,可以逐步确定程序崩溃的原因。通过向程序发送 SIGSEGV 信号来生成 core 文件是一个有效的调试手段。通过 gdb,可以详细分析程序在崩溃时的状态,并确定具体的崩溃原因。确保在信号触发时,检查程序的变量和内存状态,能够帮助你更好地理解和解决程序中的问题。
之后如果遇到一个实际工作中产生的 core dump,且具有学习价值,我一定会总结这个分析过程,并输出成文档的形式,分享给大家,共勉,respect~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。