Linux:基础IO
✿༺小陈在拼命༻✿ 2024-10-22 14:37:02 阅读 51

一、文件fd
1.1 共识原理
1、文件=内容+属性
2、文件分为打开的文件和没打开的文件 (如c中的fopen和fclose)
可以用以下的例子去理解:快递(文件) 有被人(进程)取走的快递(打开的文件)和没被取走的快递(没打开的文件),被人取走的快递研究的是人和快递的关系(进程和文件的关系) ,而没被人取走的快递,他会被暂时安防在菜鸟驿站(磁盘) 他的数量很多(文件非常多) 所以我们打算去取的时候其实我们是会收到一个取件码的(查找该文件的信息) 然后我们根据这个号码比方说3-1113 我们会找到这个区域 然后再去找号码 所以最关键的是快递如何被按照区域划分好(对文件分门别类地存储) 这样才能方便人去取(方便我们快速找到文件并对文件的增删查改)
3、打开的文件是由进程打开的,所以研究打开的文件本质上就是研究进程和文件的关系!!
4、没打开的文件有特别多,并且在磁盘上放着,所以研究没打开的文件关键在于文件如何被分门别类地放置好从而方便用户快速找到文件并进行相关的增删查改工作!!
1.2 被打开的文件
由于:
(1)文件要被打开,必然要先被加载到内存中。
(2)一个进程可能打开多个文件,一个文件也可能被多个进程打开。
——>在操作系统内部一定存在大量被打开的文件 !!
——>操作系统必须按照先描述再组织的方式把被打开的文件管理起来!!
1.3 回忆C的文件操作接口
1.3.1 文件的打开和关闭
问题1:为什么我们默认会新建在当前路径,凭什么???
——>当前路径,其实就是进程的路径,因为进程在执行的过程中,他需要知道自己从哪来,也要知道如果自己产生一些临时性的文件时应该放在哪里,所以他需要一个默认路径cwd。表明的是他当前的工作目录。
——>因为进程PCB结构体内部有一个cwd属性,如果我们更改了进程的,cwd属性,就可以将文件新建到别的地方!!
问题2: 先被加载到内存的是文件的属性还是文件的内容??
——>当你fopen的时候,其实就需要创建一个文件的内核数据结构,里面包含了文件的一些必要属性,所以是属性先被加载进去了!! 至于内容需不需要被加载,关键看你有没有通过一些接口来对该文件进程增删查改!!
1.3.2 文件的增删查改

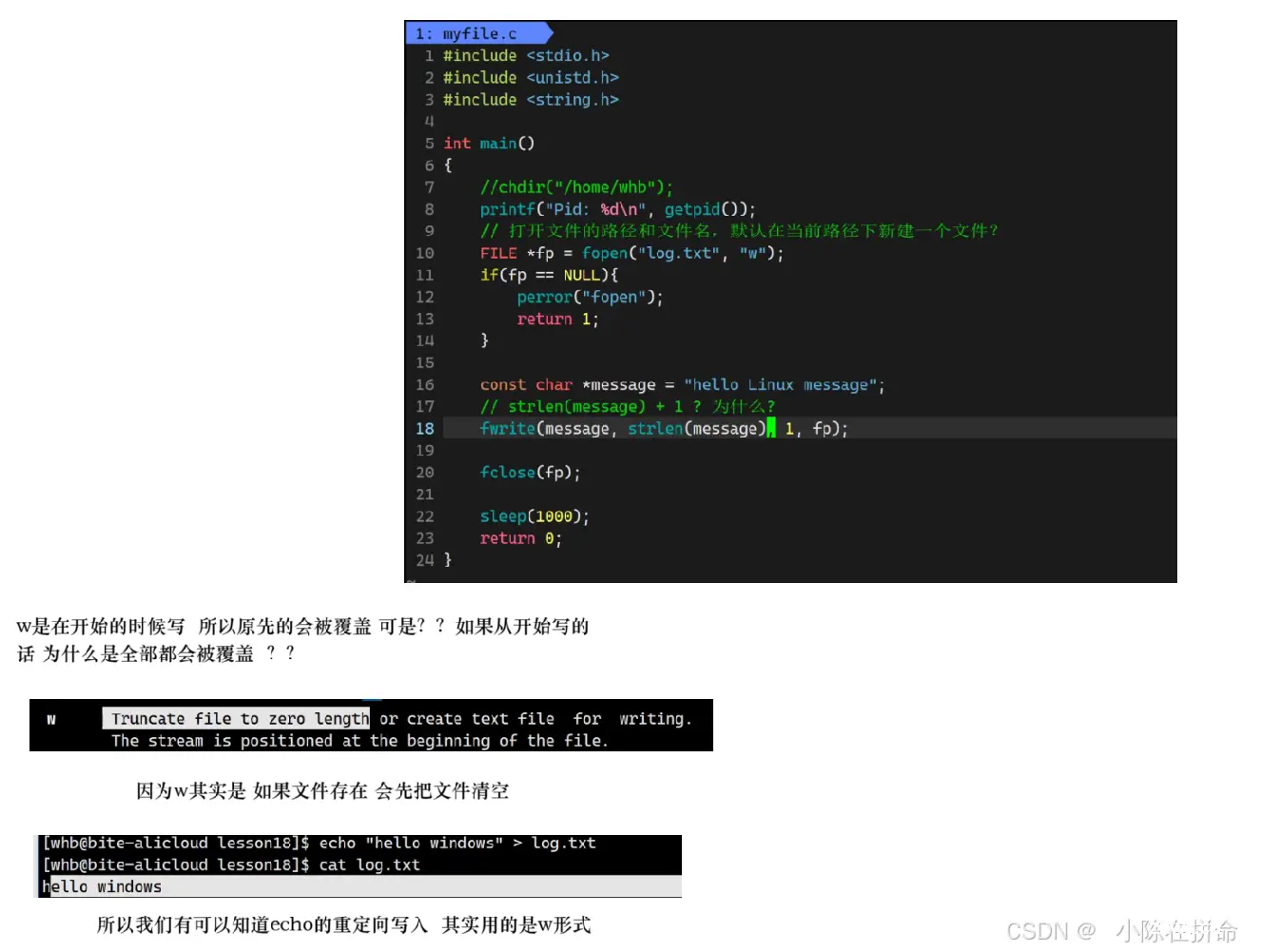
w:在写入之前,会对文件进行清空处理!! 所以我们可以知道echo重定向方式写入也会先清空文件,所以底层必然也是w形式!!

strlen默认是不加/0,如果我们+1带上/0,此时会打出一个乱码,但是这个乱码是什么并不重要,重要的是我们发现/0也是一个可以被写进去的字符!!
为什么???——>因为字符串以/0结尾,是C语言的规定,跟文件、跟操作系统没有任何关系!!
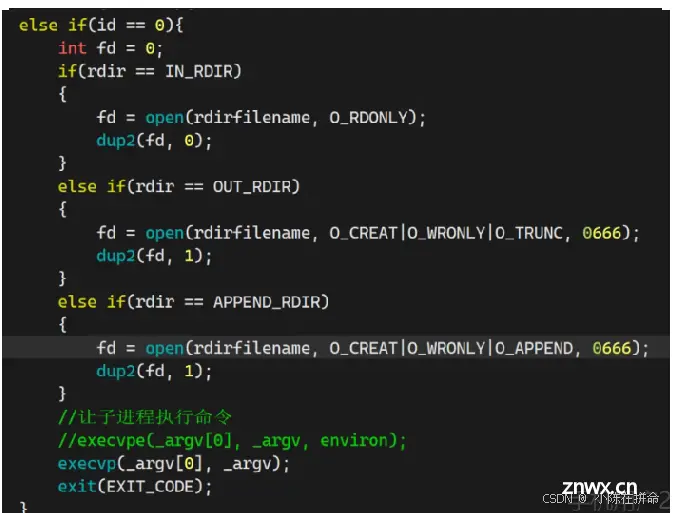
a:在文件的结尾追加写!!
1.4 过渡文件系统调用
因为文件在硬盘上,所以我们想要访问文件其实就是访问硬件,因此几乎所有的库想要访问硬件设备,就必须封装系统调用!!

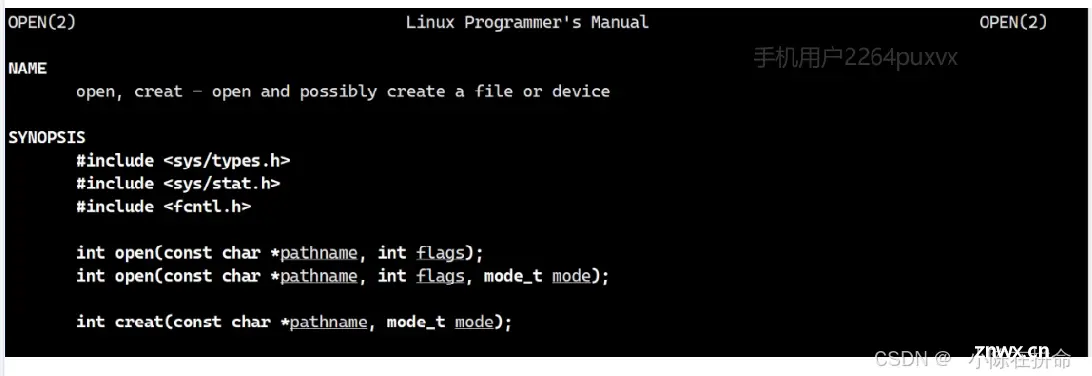
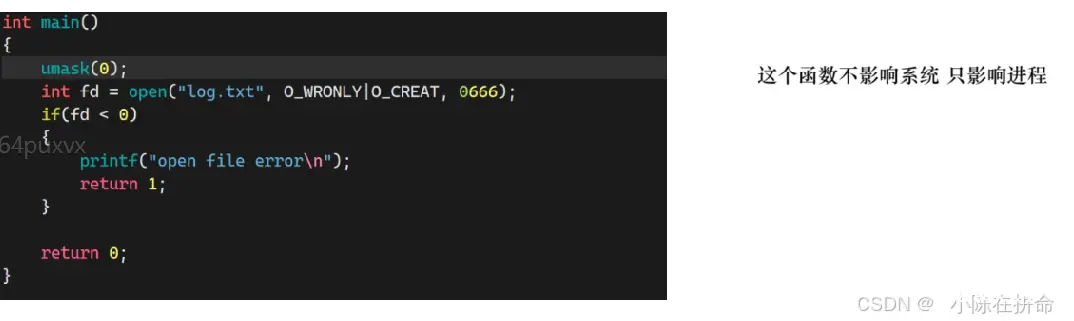
参数pathname是文件名,参数flags是打开的模式,而mode是权限设置 因此第一个open是用来打开一个已经存在的文件,而第二个open打开的是新建的文件(因为我们需要给新建的文件设置权限!)
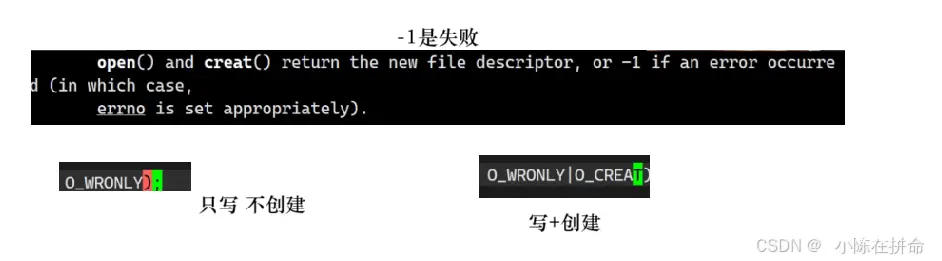
如果用第一个open去新建不存在的文件,会出现文件的权限错误!!所以必须用第二个open!
关于文件权限的传递,我们要记得因为有粘滞位umask 所以我们想要设置的权限可能并不是我们最终想要的,所以我们要向用umask把该进程的粘滞位变成0!!

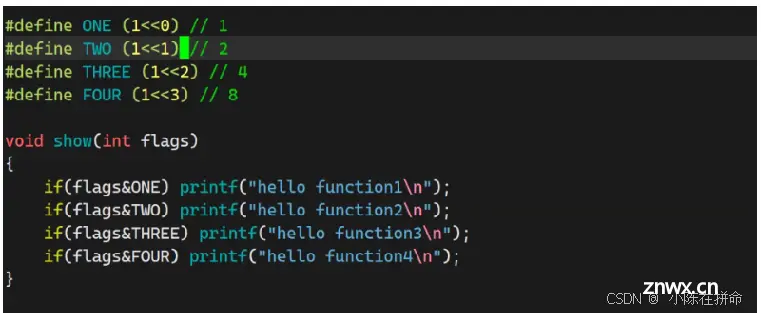
1.4.1 比特位方式的标志位传递原理
状态的组合方式有很多种,但是为什么操作系统只用一个int类型就可以表明这些情况??
——>以往我们需要很多标记位的时候我们本能想到的是多创建几个参数来表示,但当位图出现后,我们想到了可以用int类型的32个bit位来表示各种不同的组合。
模拟实现:

通过位图的方式一次向一个调用传递多个标记位,这是操作系统传递参数的一种方式!!
——>本质上是在外部用 | 的方式组合 在内部的方式用& 的方式检测!!
1.4.2 访问文件的本质
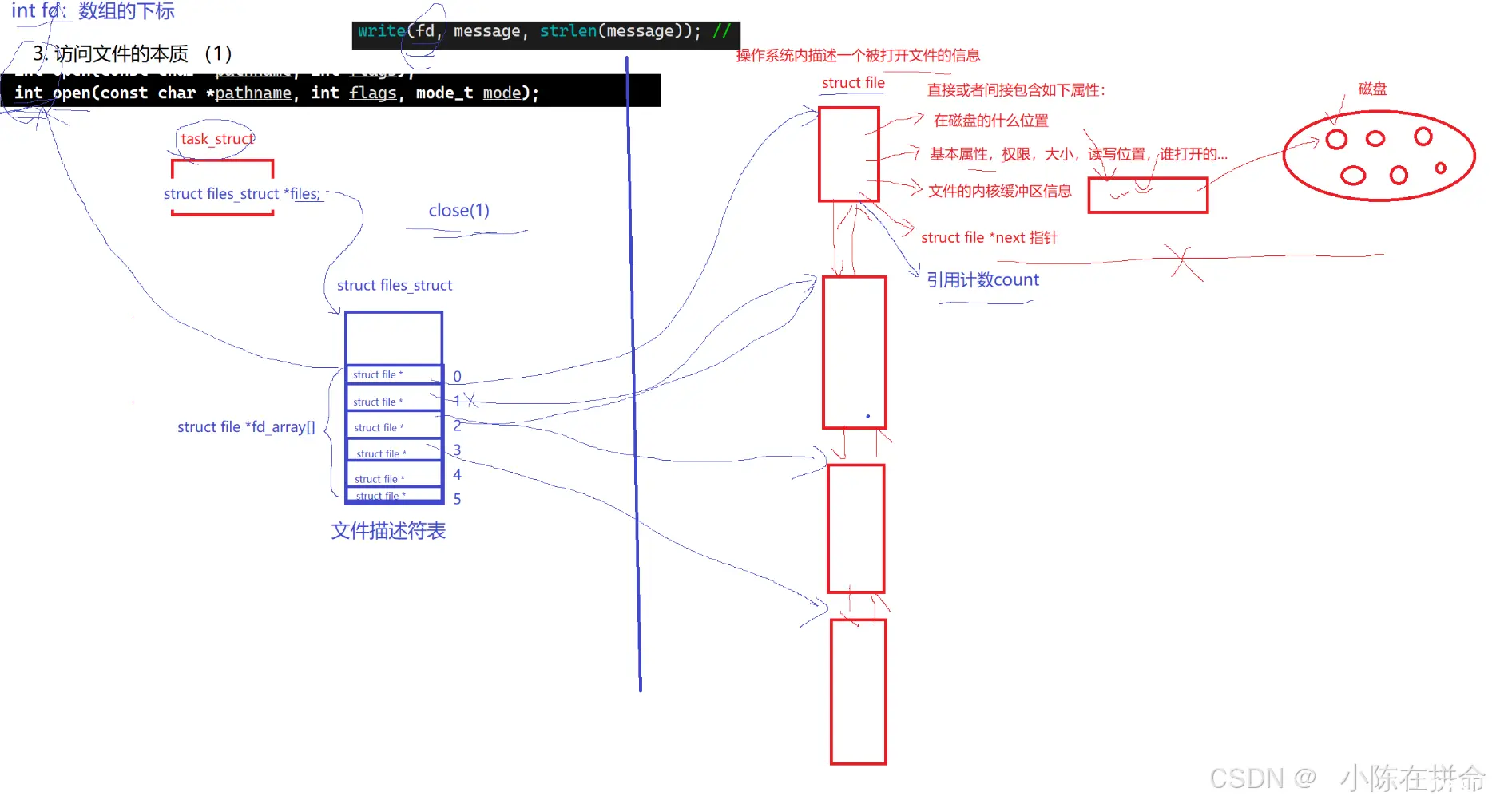
问题1:以前我们学C语言的时候,fopen的返回值是一个FILE* 那个时候我们知道这个是C库封装的一个结构体,但是为什么系统调用解决ooen的返回值是一个整形呢???
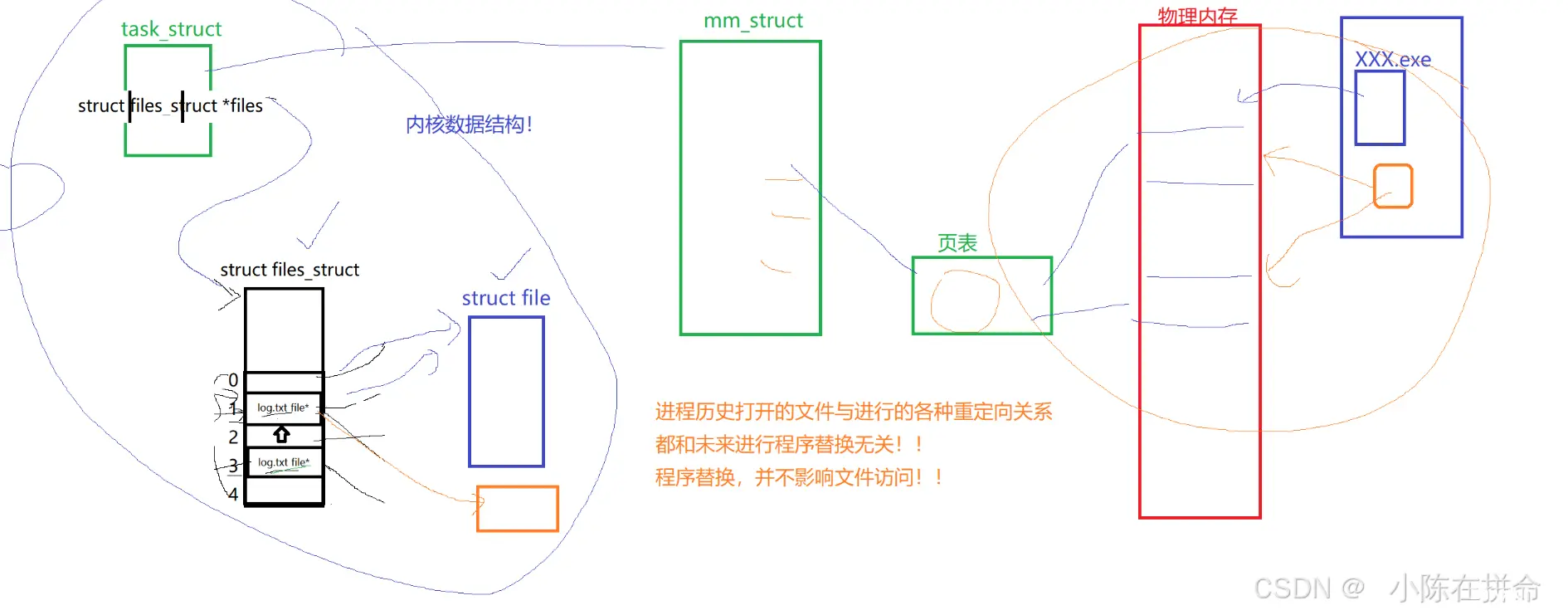
因为一个进程可能打开多个文件,那么我们想要快速地找到任意一个文件,如果仅仅是用链表的方式组织,确实太慢了!!
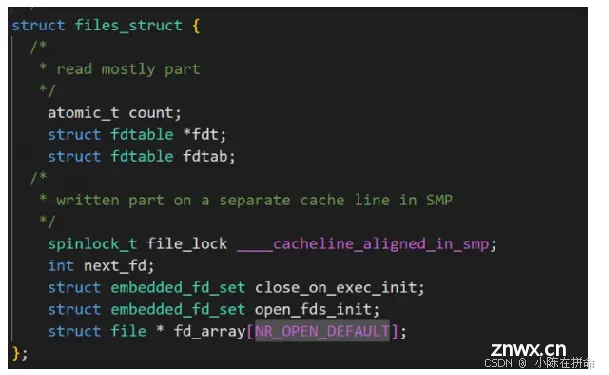
所以在PCB结构体内部,其实有一个file_struct*指针,该指针指向一个file_struct结构体,该结构体就是操作系统给该进程提供的一个文件描述符表,里面除了一些必要的字段信息,还有一个存放file*指针的指针数组,这些file*指针分别指向一个个被该进程打开的文件!!

——>所以fd我们称之为文件描述符,他的本质就是文件描述符表的下标,我们可以通过这个下标里存储的file指针找到我们想操作的被打开的文件!!
问题2:file结构体里面有什么呢??
——>肯定直接或者间接(间接的意思是可能内部还有别的结构对象)包含如下属性:
(1)在磁盘的什么位置
(2)基本的属性:权限、大小、读写位置、谁打开的)
(3)文件的内核缓冲区
(4)引用计数(因为一个文件可能会被多个进程打开,所以当一个进程关闭该文件的时候不代表这个文件的结构体就被释放了,而是要引用计数为0时才释放)
(5)file* next:链表节点结构,可以跟其他的文件链接成双链表的形式做管理!
……
1.4.3 理解文件描述符fd
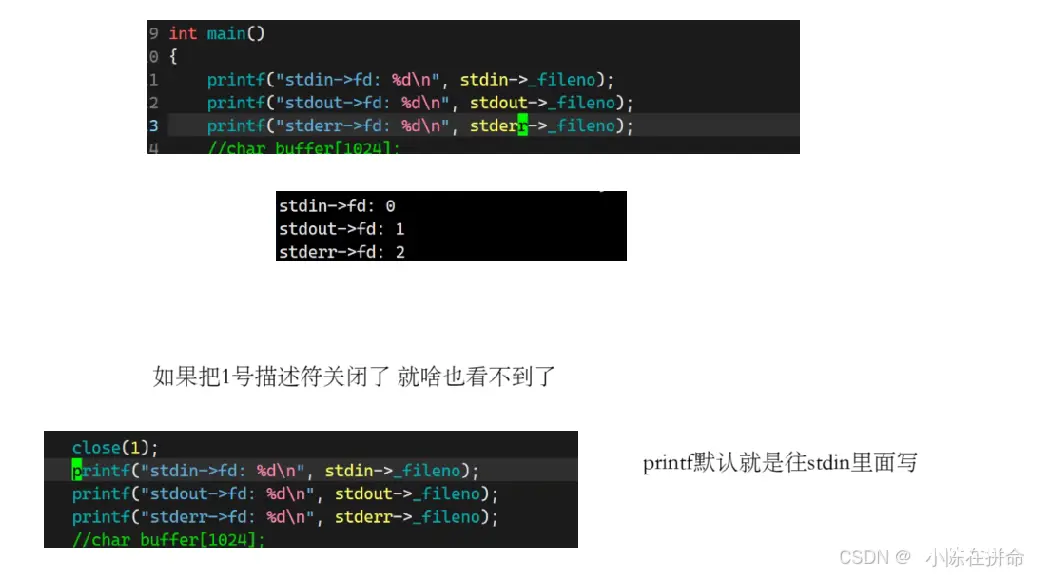
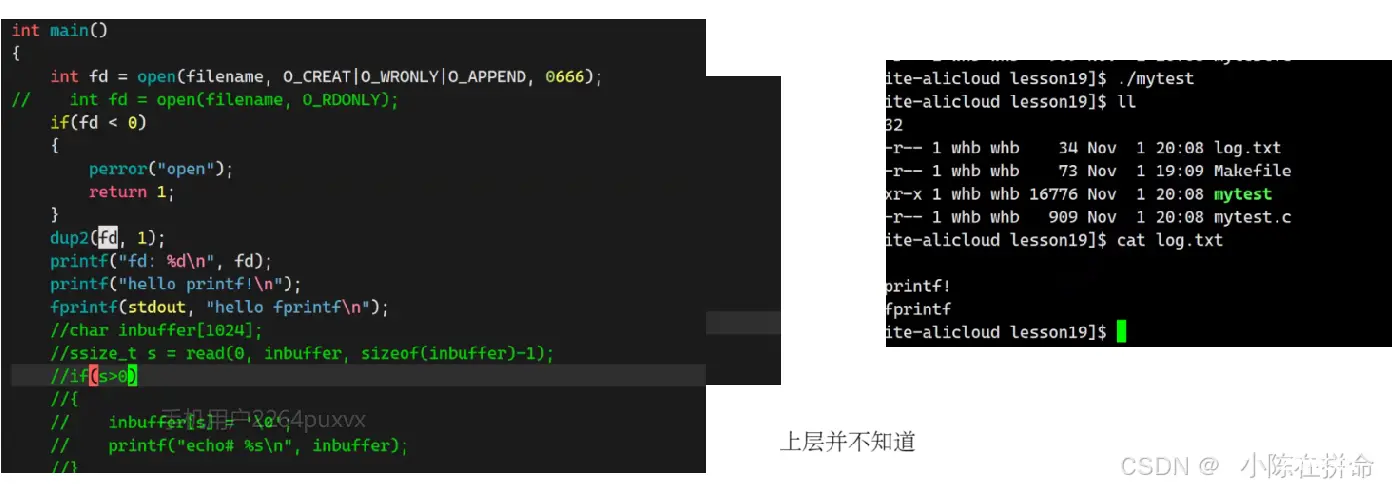
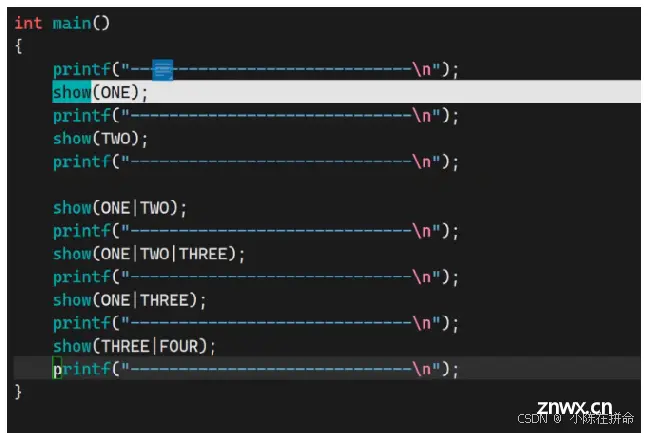
一个进程在打开的时候默认会打开3个文件:标准输入文件(键盘)、标准输出文件(显示器)、标准错误文件(显示器)…… 他们的fd分别为 0 1 2
问题1:有没有觉得很眼熟??因为我们在学C语言的时候也知道C程序会默认打开3个流!有什么关系??
——> 标准输入流、标准输出流、标准错误流其实并不是C语言的特性!!而是操作系统的特性!!

问题2:FILE* 是什么??如何理解?
——>FILE* 是一个C库自己封装的结构体,由于系统调用接口用的是fd文件描述符来对指定的文件进行操作,所以我们可以知道FILE结构体内部必然封装着文件描述符fd!
问题3:为什么一定要打开这三个流呢??
——> 因为我们的电脑开机的时候,我们的操作系统就默认检测到了显示器、键盘这类的设备,所以进程打开的时候就必然需要有这些,因为我们程序员天然需要通过键盘、显示器来观察结果。
1.4.4 文件描述符的使用
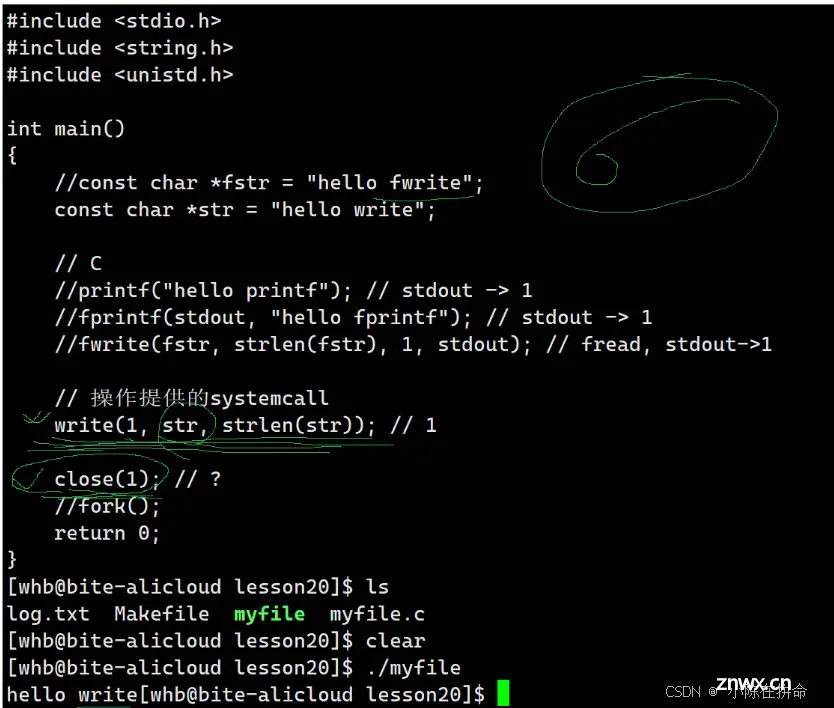
close是在3号手册的系统调用接口,可以把传进去的文件描述符对应的文件给关掉!!
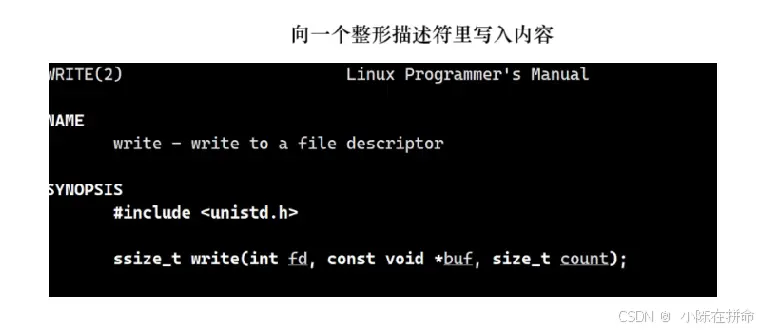
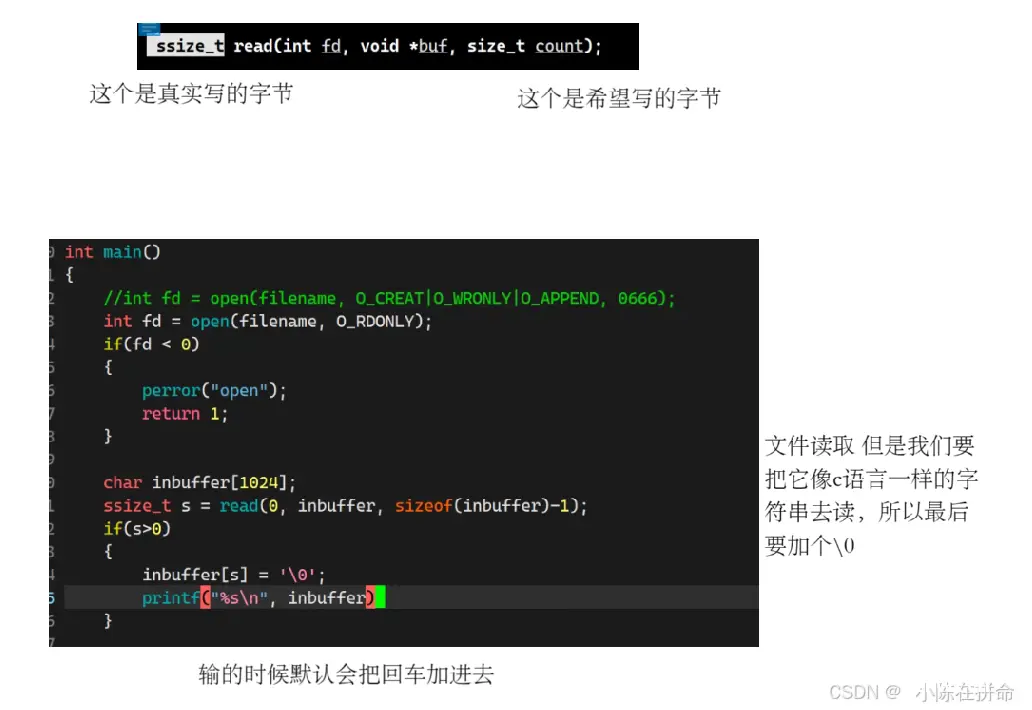
write是系统调用接口,用来向指定的文件描述符文件输出内容,其中
buf:表示我们要写入的内容,是void* 也就是说他并不限制你传什么内容
count:期望(最多)写多少字节的内容
返回值ssize_t:实际写了多少字节的内容


问题1:为什么要在后面+个/0??
——> 因为我们使用的是系统调用接口,并且参数buf也是void*指针,所以他并不知道你传的是什么,只知道默认把一个个字符放在缓冲区里,所以如果我们想让他按照C语言字符串的形式去读取出来,那么就需要加个/0 因为这是C语言的规则。
1.4.5 三个流的理解

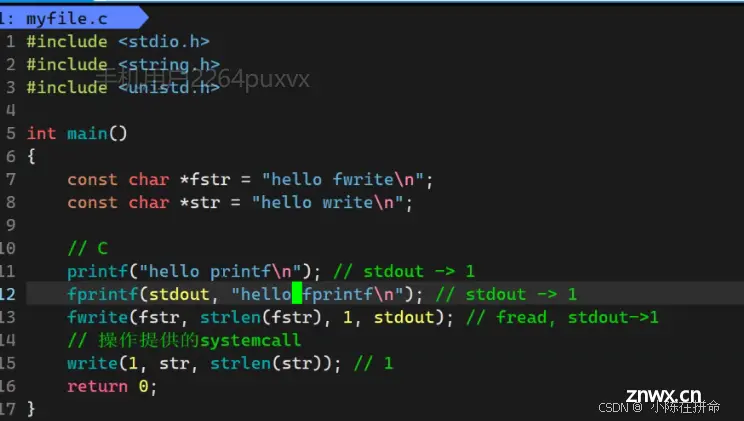
printf是C库函数 底层封装的时候默认向 stdout的1号描述符里写入,所以如果你把1号给关了,printf底层调用write这个函数会失败,但是printf本身并不知道,所以他是有返回值的。而fprintf的优点是可以指定我们想要输出的流,所以当我们想stderr的2号描述符写入的时候,恰好也是指向显示器文件,所以就会被打印出来!!
——>侧面可以证明 文件的file结构体里必然存在引用计数!! 因为在1号描述符关闭之后,显示器文件并没有被关闭,所以close底层的操作就是对count计数--,然后将文件描述符表的指针置空,但是显示器文件还是打开着的,因为2号描述符还指向显示器文件!!
总结:任何一门语言对文件描述符的封装不一样,是千变万化的,比如在C++中可能还会有继承和多态的体系。但是万变不离其中,在底层都是使用的操作系统提供的系统调用接口,对fd文件描述符进行封装。 所以底层理解了,其实任何语言都是学习他的应用而已!!
1.4.6 内核的源码下载


二、重定向再理解
2.1 输出重定向和追加重定向
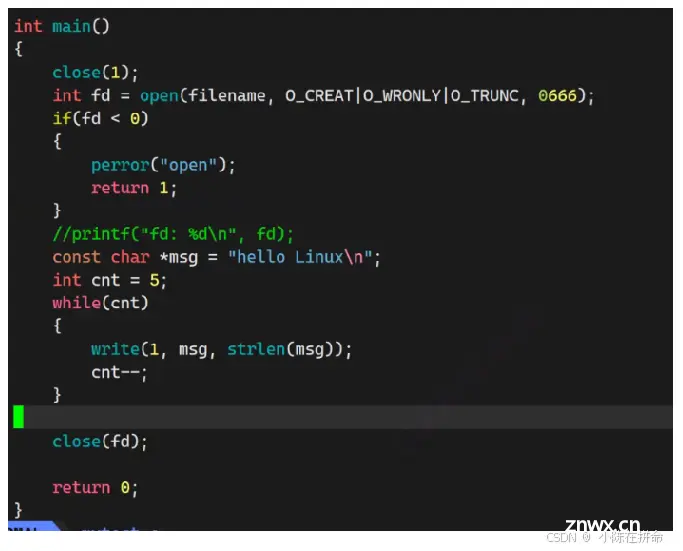
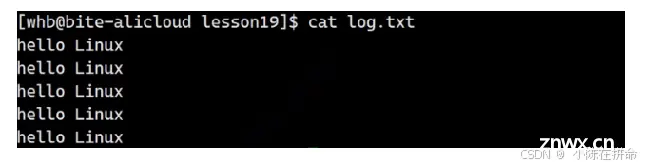
但是我们把他1号关了,然后又打开了一个新的文件, 发现本来应该写到1号的标准输出文件里! 这说明在close将1号位置置空后,该文件就补上了这个位置!! 说明文件描述符的放置规则是从0下标开始,寻找最小的没使用的数组位置,他的下标就是新的文件描述符!!
这不就有点像 我们之前学的输出重定向,所以我们可以发现其实输出重定向的本质就是将文件的输出描述符对应的指针信息替换成文件的指针信息!!
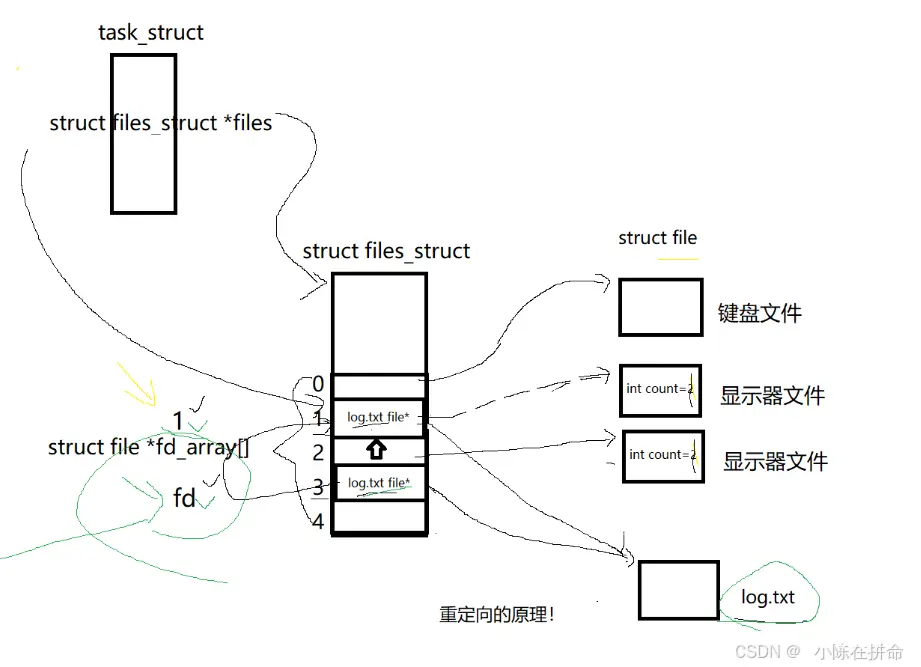
问题1:难道我们必须要先把1号文件关闭了再打开新的文件才能完成重定向吗??
——>其实本质上就是将新文件的指针覆盖掉原来1号位置的指针就行了,系统提供了一个接口叫dup来帮助我们解决这个问题!!所以输出重定向和追加重定向底层肯定使用了dup接口!
他是用oldfd覆盖掉newfd

问题2:进程替换会影响文件的重定向吗??
——>进程历史打开的文件与进行的各种重定向关系都和未来进行的程序替换无关!! 他们是两个模块,程序替换并不影响文件访问!!
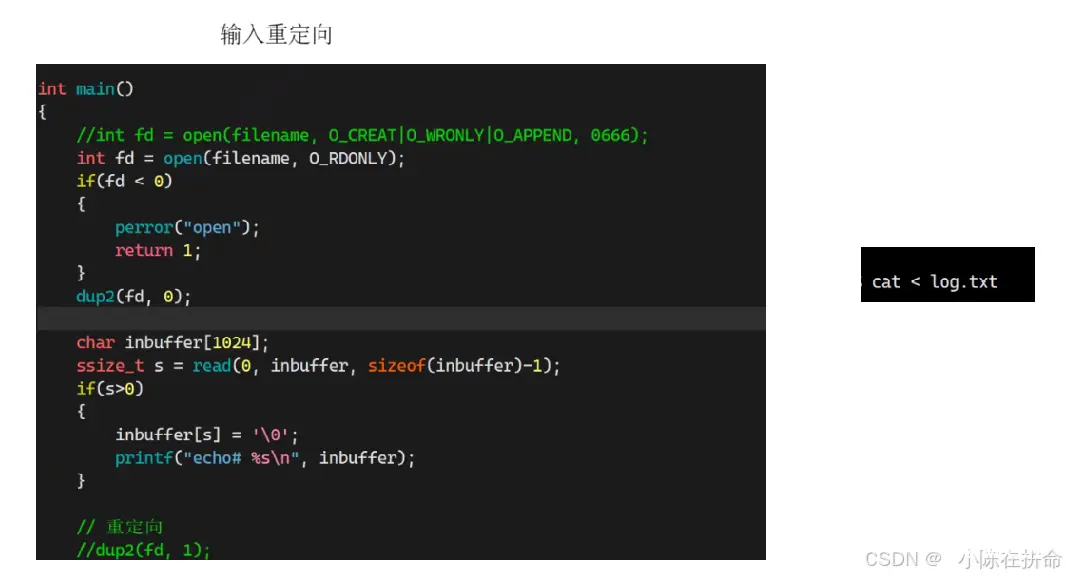
2.2 输入重定向
read的使用:
输入重定向:
2.3 一个测试
我们知道printf默认是向1号文件写入,但如果我们将1号的显示器文件关闭后,然后用一个新的文件去替换该位置,于是printf就变成了向文件打印。
但是我们会发现,我们用fprintf的时候传参写入的是stdout,可是该文件却也写到了文件里面而不是写到了显示器上。
——>这说明了,其实不管是stdin、stdout、stderr都是一个结构体,底层都是封装文件描述符对应的是0、1、2, ——>说明上层只知道要向文件描述符位置写入。即使你通过系统调用将该位置的文件信息改了,他也并不知情。
2.4 shell的重定向封装
所以往后可能我们会遇到这样的指令,所以我们需要在字符串拆分的部分去做一些特殊处理,来判断究竟是输出重定向、追加重定向还是输入重定向!

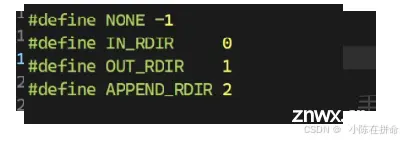
先对这些情况做一个宏的定义,为了后期在普通命令执行的时候做区分
封装一个函数检查一下字符串是否涉及到重定向的问题(往后检测看看会不会遇到>或者<),如果是的话判断是哪种类型。

在普通命令的执行这边根据宏进行判断

2.5 重定向的本质写法(为什么要有stderr)

1、将程序的运行结果分别重定向到两个不同的文件(这样我们可以把运行结果放到我们的正常文件里,然后把错误的一些信息放到我们的错误文件里,方便我们观察——>这就是为什么要有stderr的原因)。

这才是重定向的正确写法,只不过我们平常不写fd的话默认就是将1号文件的内容重定向。
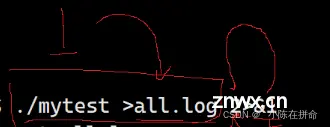
2、将两个文件的结果都写到一个文件

这个意思是1号文件的地址变成了all.log 然后2也被写入到原来1的位置,所以最后其实都被写到了all.log文件里面
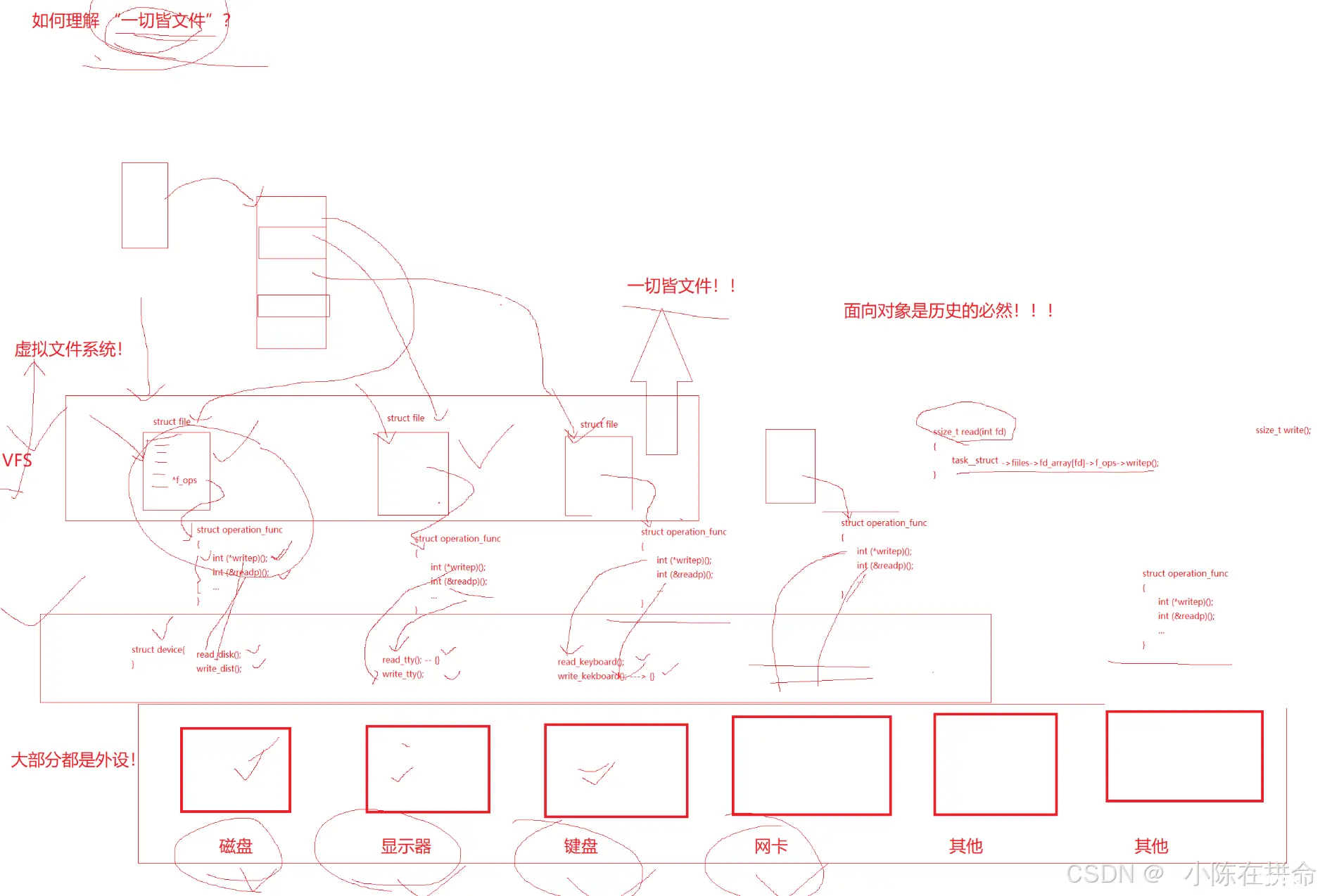
三、如何理解一切皆文件
1、计算机上进行的所有操作,所有任务都会被系统检测成进程,所以进程是操作系统帮助用户完成任务的主要渠道,几乎没有之一
——>因此我们目前对文件的所有操作其实都依赖于进程操作!!
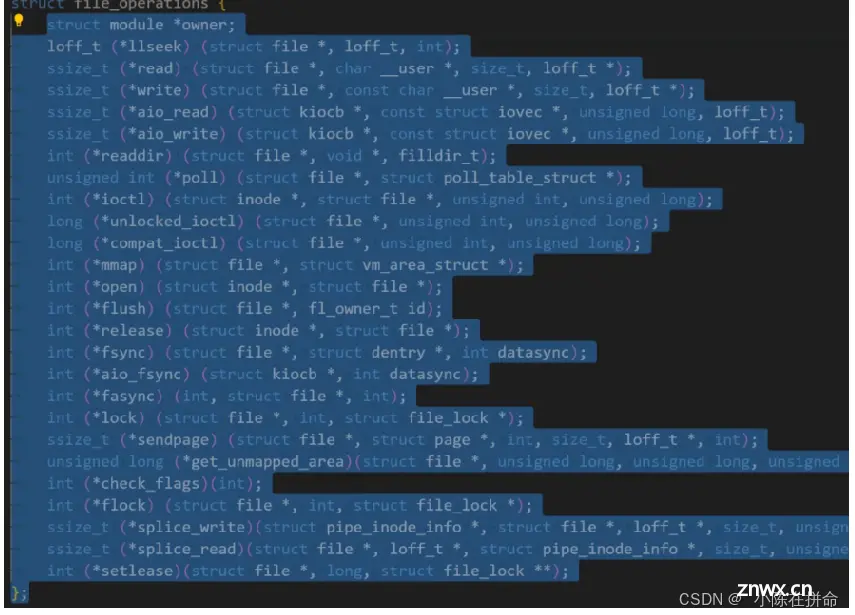
2、而我们所有的外设都需要提供相应的读写方法 (跟文件有点类似)!所以我们会尝试把外设也当成是文件来处理,在使用的时候在内核层面搞一个file结构体, 但是这样会遇到一个问题就是,并不是所有的外设都有读写方法的!!比如说键盘只有写方法,而显示器只有读方法,那我们的file要如何做区分呢??
——>所以操作系统还给这些文件提供了一个 方法 结构体 里面保存了读方法和写方法的指针
这俩函数指针指向的是各个外设的读写方法。(就比如说我当前想要打开显示器,在创建file结构体的时候顺便创建了方法结构体,里面的读写的函数指针分别指向显示器的读方法和写方法,所以因为显示器只有写方法,读方法是空,于是在调用的时候就自然区分得出来了)

3、其实这就是VFS 虚拟文件系统,所以可以理解Linux一切皆文件。
——>其实我们还可以发现 这个文件其实就是基类,而外设就是派生类,然后指针指向什么就调用什么对象,这就是多态,只不过Linux必须用C语言写,所以只能用函数指针来完成这个工作!!
4、理解了Linux的一切皆文件后,懂得了文件操作的底层,即使以后在使用其他语言的文件操作时对接口不熟,但只要给时间查一下,很快就会懂得怎么用了!!(没有太多的恐惧),这就是理论知识所带给我们的力量和底气!!
四、理解为什么会有面向对象
如果面向对象是C++的专属,那么他只能算是一种特性,但是当你发现大部分主流语言都是支持面向对象的,那么这就说明面向对象不是一两门语言的特性,而是历史的必然!!
为什么会有人能凭空想出来面向对象的语言呢??
——>因为人们在经过大量的工程实验后,发现我们总是或多或少要使用一些多态的特性,比如说写操作系统的人必然也是有可能开发语言的人,他在写的时候就意识到Linux里面很多虚拟化的东西,要不是你必须拿C去写,我早就发明出一门面向对象的语言了,直接搞个基类派生类出来就很快了!! ——>因为很多地方需要对软件做分层,设置出各种虚拟化的场景(比如刚刚提到的文件虚拟系统就是,只不过Linux必须用C写,否则肯定用C++写更方便) ——>封装、继承、多态!
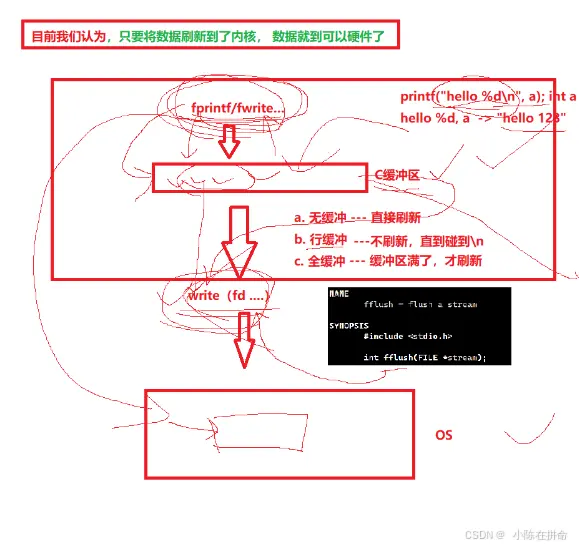
五、缓冲区深入理解
5.1 引入一些奇怪的现象
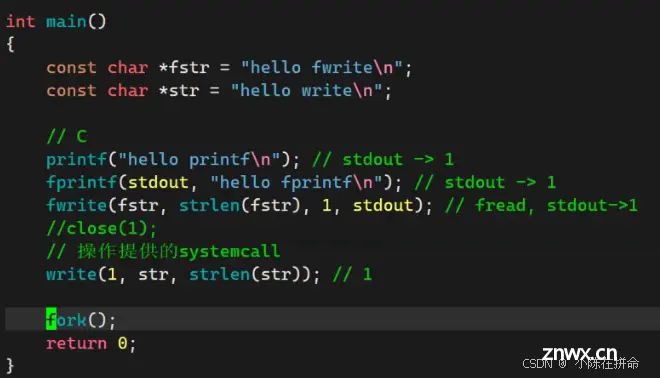
现象1:为什么向文件写入的时候 write会先被打印出来??
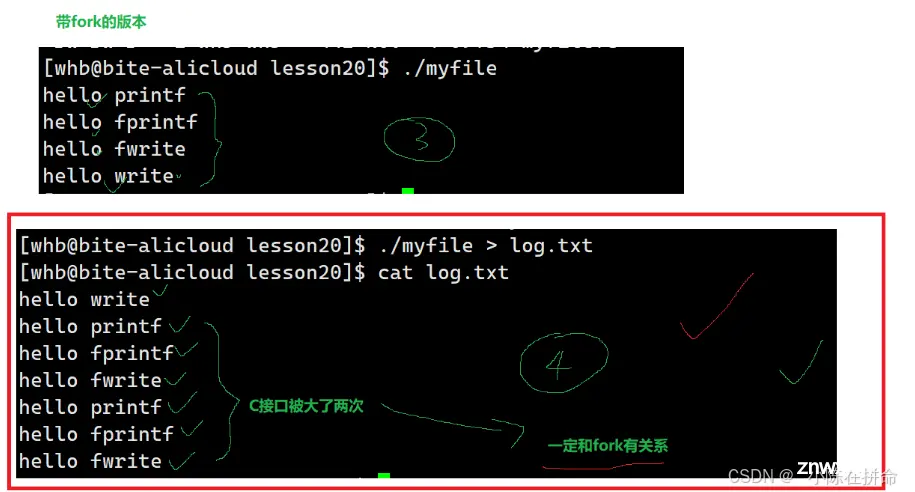
现象2、为什么加了fork之后,向文件写入时C接口会被调了两次??且向文件写入时write先被打印?

现象3、close1号文件后,为什么就没有结果了??

5.2 缓冲区不在操作系统内部!
通过现象3,我们发现一旦close之后,内容就不见了!! 因为现代操作系统不做浪费空间和时间的问题,所以close作为系统调用接口不可能不在关闭文件之前刷新缓冲区,所以这说明他根本看不到这个缓冲区!!

所以我们的库函数接口是先把内容放到一个C提供的缓冲区,当需要刷新的时候,才会去调用write函数进行写入!!
——>所以close后刷新不出来的原因就是:进程退出后想要刷新的时候,文件描述符被关了,所以即使调了write也写不进去,缓冲区的数据被丢弃了
(注意:进程退出的时候是会刷新缓冲区的!!)
5.3 缓冲区的刷新策略
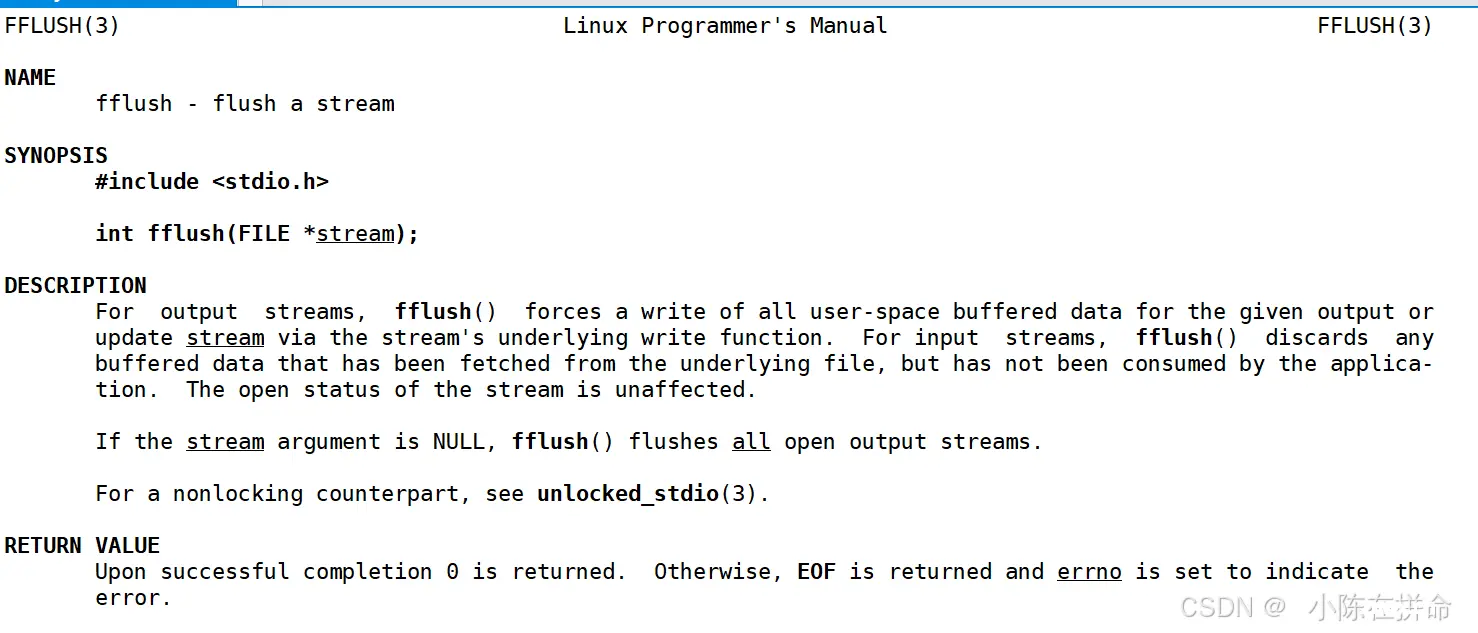
1、无缓冲——>直接刷新——>fflush函数
2、 行缓冲——>遇到/n刷新——>显示器文件
3、全缓存——>写满才刷新——>普通文件
问题1:为什么要有这些不同的方案??
——>一般来说写满再刷新效率高,因为这样可以减少调用系统接口的次数,而显示器之所以是行刷新,因为显示器是要给人给的,按行看符合我们的习惯,而文件采用的就是全缓存策略,因为用户不需要马上看到这些信息,所以这样可以提高效率。 而对于一些特殊情况我们就可以用fllush之前强制刷新出来。 ——>所以方案是根据不同的需求来的!
问题2:解释现象1
——>当我们从向显示器写入转变为向普通文件打印时,此时刷新策略从行刷新转变为全刷新,所以前三个C接口并没有直接写入,而是暂时保存在了缓冲区里面,而write是系统调用接口优先被打印了出来,之后当进程退出的时候,缓冲区的内容才被刷新出来。
问题3:解释现象2
——>跟现象1一样,前三个C接口的数据暂时被存在了缓冲区,而write的调用先被打了出来。当fork的时候,子进程会和父进程指向相同的代码和数据,当其中一方打算刷新缓冲区时,其实就相当于要修改数据,操作系统检测到之后就会发生写时拷贝,于是缓冲区的数据被多拷贝了一份,而后该进程退出时就会再刷新一次,因此C接口写入的数据被调了2次!!
5.4 为什么要有缓冲区呢??
举个例子,比方说你和你的好朋友相隔千里,而你想要给他送个键盘,如果没有快递公司和菜鸟驿站(缓冲区)的话,那么你可能得坐车好几天才能到他那里,但如果你的楼下有菜鸟驿站和快递公司,那么你只需要下楼付点钱填个单子就行了,接着你可以去忙你自己的事情,当旁边的人问你键盘去哪里的时候,你会说已经寄给朋友了,其实这个时候你的键盘可能还在快递公司放着。
——>
1、从总体来看东西是你送还是快递公司送其实都差不多,区别就是你不需要操太多心。因此缓冲区方便了用户!!
2、快递公司可以有不同的策略来提高整体的效率,比方说你这个快递不急,那么我就等快递车装满了再送(全刷新) ,如果比较急,我就装满一个袋子就送(行刷新),如果你特别急,可以通过加钱(fllus强制刷新)来加急。 所以缓冲区解决了效率问题
3、 配合格式化!比方说C语言经常需要%d这样的格式化,我们的数字123 最后被打印的时候也是要转化成字符串的123 才能调用write写入,因此我们可以将这个解格式化的工作放在缓冲区去完成!!
5.5 用户缓冲区在哪?
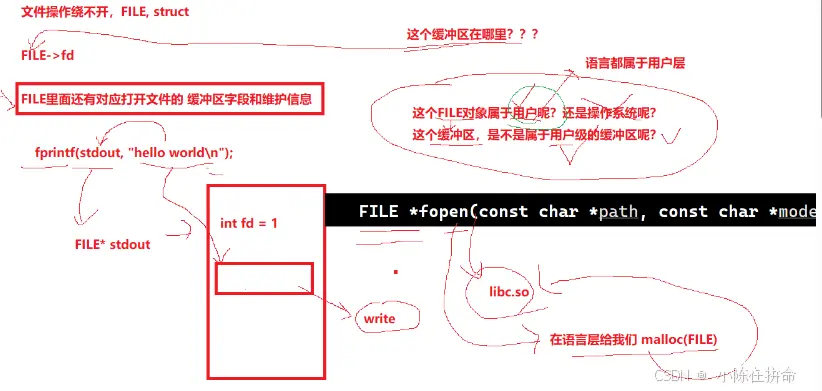
我们回忆一下exit和_exit 区别就是exit会先调用一次fllush把缓冲区的数据刷新出来。

我们会注意到他传递的参数是FILE* 类型
——>FILE* 不仅封装了fd的信息,还维护了对应文件的缓冲区字段和文件信息!!
——>FILE*是用户级别的缓冲区(任何语言都属于用户层),当我们打开一个文件的时候语言层给我们malloc(FILE),同时也会维护一个专属于该文件的缓冲区!! 所以如果有10个文件就会有10个缓冲区!!

5.6 内核缓冲区在哪?
内核缓冲区也是由操作系统的file结构体维护的一段空间,和语言的缓冲区模式是类似的,作为用户我们不需要太关心操作系统什么时候会刷新,我们只需要认为数据只要刷新到了内核,就必然可以到达硬件,因为现代操作系统不做任何浪费空间和时间的事情。!!!!
六、模拟实现C库文件接口
6.1 Mystdio.h
<code>//#pragma once
#ifndef __MYSTDIO_H__
#define __MYSTDIO_H__ //类似#pragma once的功能 防止头文件被重复包含
#include <string.h>
#define SIZE 1024 //缓冲区的大小
#define FLUSH_NOW 1 //立刻刷新
#define FLUSH_LINE 2 //行刷新
#define FLUSH_ALL 4 //全刷新
typedef struct IO_FILE{ //自定义的FILE对象
int fileno;//文件描述符
int flag; //当前的刷新策略
//char inbuffer[SIZE];//输入缓冲区
//int in_pos;//当前用了多少位置
char outbuffer[SIZE]; //输出缓存区
int out_pos;//当前用了多少位置
}_FILE;
_FILE * _fopen(const char*filename, const char *flag);
int _fwrite(_FILE *fp, const char *s, int len);
void _fclose(_FILE *fp);
#endif
6.2 Mystdio.c
#include "Mystdio.h"
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include <assert.h>
#define FILE_MODE 0666//默认新建文件的权限
// "w", "a", "r"
_FILE * _fopen(const char*filename, const char *flag)
{
assert(filename); //防止你传空
assert(flag);//防止你传空
int f = 0;
int fd = -1;
if(strcmp(flag, "w") == 0) {
f = (O_CREAT|O_WRONLY|O_TRUNC);//新建、只写、清空
fd = open(filename, f, FILE_MODE);
}
else if(strcmp(flag, "a") == 0) {
f = (O_CREAT|O_WRONLY|O_APPEND);//新建、只写、追加
fd = open(filename, f, FILE_MODE);
}
else if(strcmp(flag, "r") == 0) {
f = O_RDONLY;//只读
fd = open(filename, f);
}
else
return NULL;//防止你传一些乱七八糟的东西
if(fd == -1) return NULL;//说明打开失败
_FILE *fp = (_FILE*)malloc(sizeof(_FILE));
if(fp == NULL) return NULL;//说明malloc失败
//初始化
fp->fileno = fd;
//fp->flag = FLUSH_LINE;
fp->flag = FLUSH_ALL;
fp->out_pos = 0;
return fp;
}
// FILE中的缓冲区的意义是什么????
int _fwrite(_FILE *fp, const char *s, int len)
{
// "abcd\n"
memcpy(&fp->outbuffer[fp->out_pos], s, len); // 没有做异常处理, 也不考虑局部问题
fp->out_pos += len;
if(fp->flag&FLUSH_NOW)//立刻刷新策略
{
write(fp->fileno, fp->outbuffer, fp->out_pos);
fp->out_pos = 0;
}
else if(fp->flag&FLUSH_LINE) //行刷新策略
{
if(fp->outbuffer[fp->out_pos-1] == '\n'){ // 不考虑其他情况
write(fp->fileno, fp->outbuffer, fp->out_pos);
fp->out_pos = 0;
}
}
else if(fp->flag & FLUSH_ALL) //全刷新策略
{
if(fp->out_pos == SIZE){
write(fp->fileno, fp->outbuffer, fp->out_pos);
fp->out_pos = 0;
}
}
return len;
}
void _fflush(_FILE *fp) //立即刷新
{
if(fp->out_pos > 0){
write(fp->fileno, fp->outbuffer, fp->out_pos);
fp->out_pos = 0;
}
}
void _fclose(_FILE *fp)
{
if(fp == NULL) return;
_fflush(fp);//文件关闭前都刷新一次
close(fp->fileno);
free(fp);
}
6.3 main.c
#include "Mystdio.h"
#include <unistd.h>
#define myfile "test.txt"
int main()
{
_FILE *fp = _fopen(myfile, "a");
if(fp == NULL) return 1;
const char *msg = "hello world\n";
int cnt = 10;
while(cnt){
_fwrite(fp, msg, strlen(msg));
// fflush(fp);
sleep(1);
cnt--;
}
_fclose(fp);
return 0;
}
6.4 反思
1、 不同操作系统,比如Linux和windows底层的系统调用接口肯定是不一样的,但是我们在语言层面使用的库函数是一样的!说明在C库底层实现这些接口的时候,不仅写了Linux系统接口的C函数,也写了windows系统接口的C函数,然后通过条件编译的方式在不同的平台裁掉另外一部分,这样我们无论在什么平台都可以使用被封装好的C接口!!
——>C语言具有跨平台性、可移植性(对底层做了封装,虽然不同平台底层都不一样,但是上层的接口一模一样的 ,库帮我们解决了移植性的问题)
2、通过系统调用把数据拷贝到操作系统是有时间成本的,所以缓冲区的存在可以让我们尽量减少和操作系统的交互,就能提高我们使用C库函数的效率,因为很多时候只是单纯地把数据拷贝到自己目前的缓冲区。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。