集群及分布式定时任务中间件MEE_TIMED
cnblogs 2024-07-20 08:09:00 阅读 91
集群及分布式定时任务中间件MEE_TIMED
转载请著名出处:https://www.cnblogs.com/funnyzpc/p/18312521
<code>MEE_TIMED一套开源的定时任务中间件,MEE_TIMED 简化了 scheduled及shedlock的配置,同时也升级了这两种中间件的能力 ,使定时任务开发更具灵活性的同时
具备集群及分布式节点的管理,同时也增加了传参,使之更加强大💪
开发初衷
目前 java 语言下可用的定时任务基础组件无非这俩: spring scheduled 以及 quartz,其中 scheduled 属于轻量级的设计 默认集成在 spring-context 包中,所以springboot使用 scheduled 简单快捷,
既然简单也必有简单的局限(后面会聊),quartz 则属于重量级的设计,内部提供了 RMI 及 JMX 支持 以及使用基于DB的行锁使之支持集群,这都很好,不过内部代码设计及扩展似乎过于臃肿,不使用表又会退化为 scheduled ~
有时,项目不大不小,但是有集群需求并且需要保证任务不重复执行,这时就需要 scheduled+shedlock 这样的搭配,可这样无法动态传参,同时增加了业务代码的复杂度,这是问题;
当然也可以使用 quartz+数据库表 的方式 则管理集群及节点任务会变得比较复杂, 而且任务的启停及关闭操作在分布式环境下使用 quartz 提供的api操作尤其的麻烦,这也是问题...
spring scheduled所面临的问题:CRON表达式过于简单,不支持复杂的表达式,比如每月最后一天,虽然提供zone支持但在特殊的国度,如在美国,无法计算夏令时及冬令时的偏差- 当
@Schedules与@SchedulerLock配合时 多执行时间 会存在被锁定的问题 scheduled如果不指定线程池时 默认是单线程执行,不管应用下有多少定时任务都会是单线程,这是瓶颈...scheduled不支持传参,函数使用时必须是void的函数返回且不可有形参- 部分api可能存在
spring版本迭代时不兼容问题,这是二开可能的问题
shedlock的不足之处:- 无法做集群及分布式节点管理,除非key定义的十分小心
- 不太好通过锁的控制做任务及节点的启停控制(可以通过特殊方法 比较另类)
- 任务执行时的关键信息默认不记录(IP、时间、CRON、应用信息等等)
- 加锁过程可能存在不必要的更新操作(这是代码问题)
基于现有情况我改造了 scheduled,用较少的更改 做出了处于 scheduled 及 quartz 中间的定时任务组件,这就是 MEE_TIMED 🌹.
MEE_TIMED 所做的改进
- 新增
app表(SYS_SHEDLOCK_APP),提供集群及多节点控制支持 - 扩展
job(SYS_SHEDLOCK_JOB)表data字段,提供传参及参数修改支持 @Schedule与@SchedulerLock二合一并简化注解配置spring scheduled的CronExpression替换为quartz的CronExpression,支持更灵活更复杂的CRON表达式- 修改掉
scheduled内部默认单线程的问题,提供线程池支持 - 固定于spring强绑定的api,尽量与
springboot兼容性做到最佳 - 任务信息落表 等等
基本使用
详细配置代码及后台集成在mee-admin有实例 👊(,)👊
1.下载 表结构 及 mee_timed-X.X.X.jar 依赖 依赖 并存放于项目或nexus私服中
2.POM中定义dependency依赖:
<dependency><groupId>com.mee.timed</groupId><artifactId>mee_timed</artifactId><version>1.0.1</version><scope>system</scope><systemPath>${pom.basedir}/src/main/resources/lib/mee_timed-1.0.1.jar</systemPath></dependency>3.导入表结构(SQL)
根据所使用的
db,按需导入对应厂商所支持的表结构,目前仅提供mysql、oracle、postgresql支持:table_mysql.sqltable_oracle.sqltable_postgresql.sql4.定义配置及bean
目前配置仅有三项:
spring.mee.timed.shed=${spring.application.name}spring.mee.timed.table-name=SYS_SHEDLOCK_JOBspring.mee.timed.table-app-name=SYS_SHEDLOCK_APP其中配置项
spring.mee.timed.table-app-name是管理集群及节点用的,如不需要可不配置应用启动时会自动写入必要的初始化参数,也可提前将初始数据提前导入
配置bean: 这一步是非必须的,只是内部线程池的配置较为保守,如需自定义可以以下配置指定线程数及线程名前缀:
/*** 设置执行线程数* @return*/@Beanpublic ThreadPoolTaskScheduler threadPoolTaskScheduler() {ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();scheduler.setPoolSize(PROCESSOR*2);scheduler.setThreadNamePrefix("SHEDLOCK-");scheduler.initialize();return scheduler;}5.定义定时任务
样例一:
import com.mee.timed.Job;import com.mee.timed.JobExecutionContext;import com.mee.timed.annotation.MeeTimed;import com.mee.timed.annotation.MeeTimeds;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.stereotype.Component;import java.util.concurrent.TimeUnit;@Componentpublic class Job01TestService implements Job {private static final Logger LOGGER = LoggerFactory.getLogger(Job01TestService.class);@MeeTimed(fixedRate = 10000,lockAtLeastFor = "PT5S",lockAtMostFor ="PT5S" )public void exec01() throws InterruptedException {LOGGER.info("=====> [exec01] Already Executed! <=====");TimeUnit.SECONDS.sleep(6);}@MeeTimeds({@MeeTimed(cron = "10,20,30,40,50 * * * * ?",lockAtMostFor ="PT5S",lockName = "execute1"),@MeeTimed(cron = "0 0/2 * * * ?",lockAtMostFor ="PT1M",lockName = "execute2"),@MeeTimed(cron = "0 0/4 * ? * MON-FRI",lockAtMostFor ="PT1M",lockName = "execute3"),// 纽约时间每年的7月9号22点2分执行@MeeTimed(cron = "0 2 22 9 7 ?",lockAtMostFor ="PT1M",lockName = "execute4",zone = "America/New_York"),// 每月最后一天的十点半(eg:2024-07-31 10:30:00)@MeeTimed(cron = "0 30 10 L * ?",lockAtMostFor ="PT1M",lockName = "execute5")})@Overridepublic void execute(JobExecutionContext context) {LOGGER.info("=====> proxy job exec! data:"+context.getJobInfo().getName()+" <=====");try {TimeUnit.SECONDS.sleep(8);} catch (InterruptedException e) {throw new RuntimeException(e);}}}样例二:
package com.mee.timed.test.job;import com.mee.timed.annotation.MeeTimed;import com.mee.timed.annotation.MeeTimeds;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.stereotype.Component;@Componentpublic class ScheduledTasks {private static final Logger LOGGER = LoggerFactory.getLogger(ScheduledTasks.class);@MeeTimeds({@MeeTimed(fixedRate = 10000,lockAtLeastFor = "PT5S",lockAtMostFor ="PT5S",lockName = "T1"),@MeeTimed(fixedDelay = 8000,lockAtLeastFor = "PT5S",lockAtMostFor ="PT5S",lockName = "T2"),})public void exec01() {LOGGER.info("=====> [exec01] Already Executed! <=====");}@MeeTimed(cron = "0/20 * * * * ?",lockAtLeastFor = "PT5S",lockAtMostFor ="PT10S" )public void exec02(JobExecutionContext context) {LOGGER.info("=====> proxy job exec! data:"+context.getJobDataJson()+" <=====");}}以上两种方式均可,如果需要传递参数 其函数的形参数 必须是
JobExecutionContext或其实现类如果是同一函数多时间配置(使用
@MeeTimeds配置),其每一项lockName不可为空!
集成后台管理
具体效果及代码集成 具体见: mee-admin
后台配置及管理
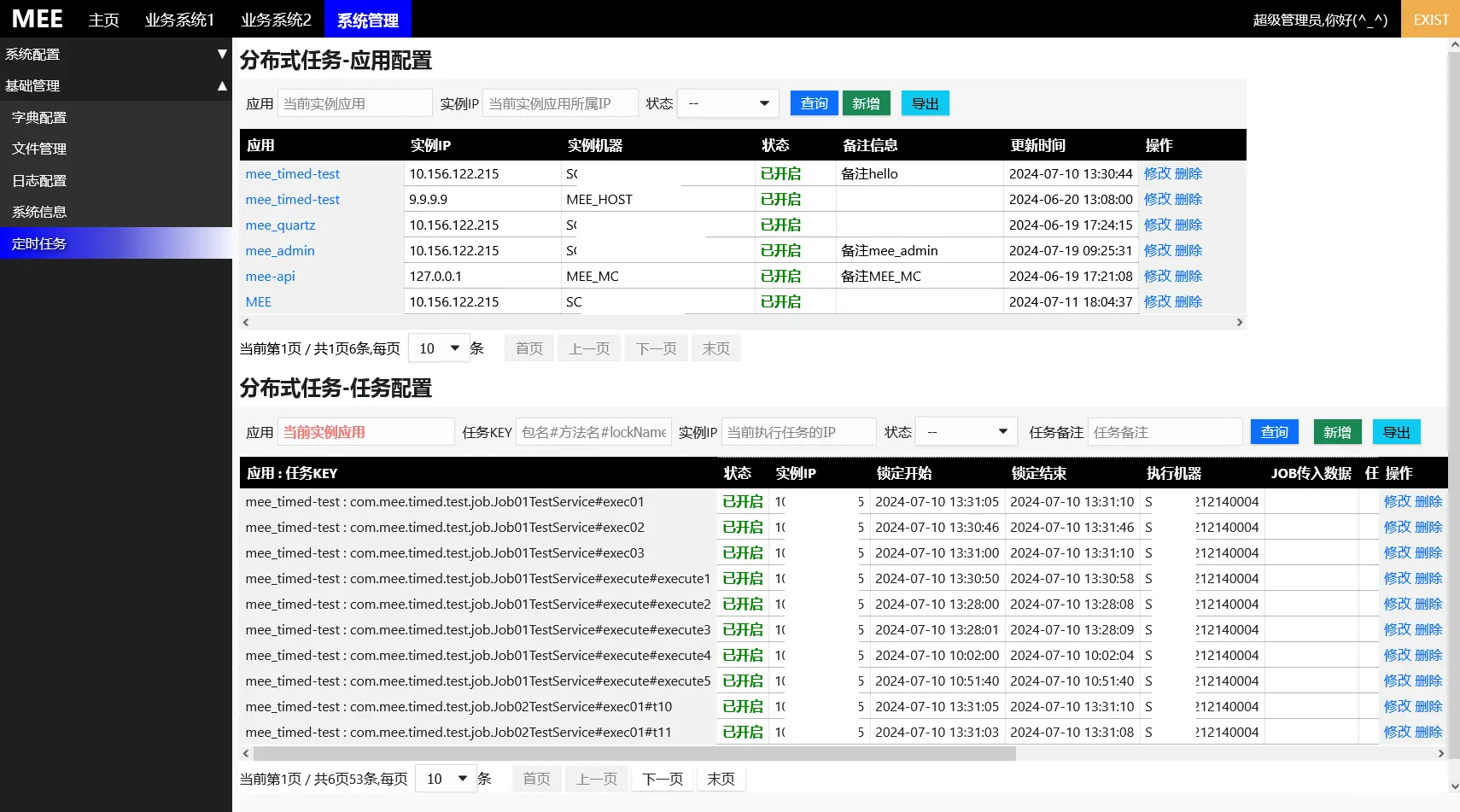
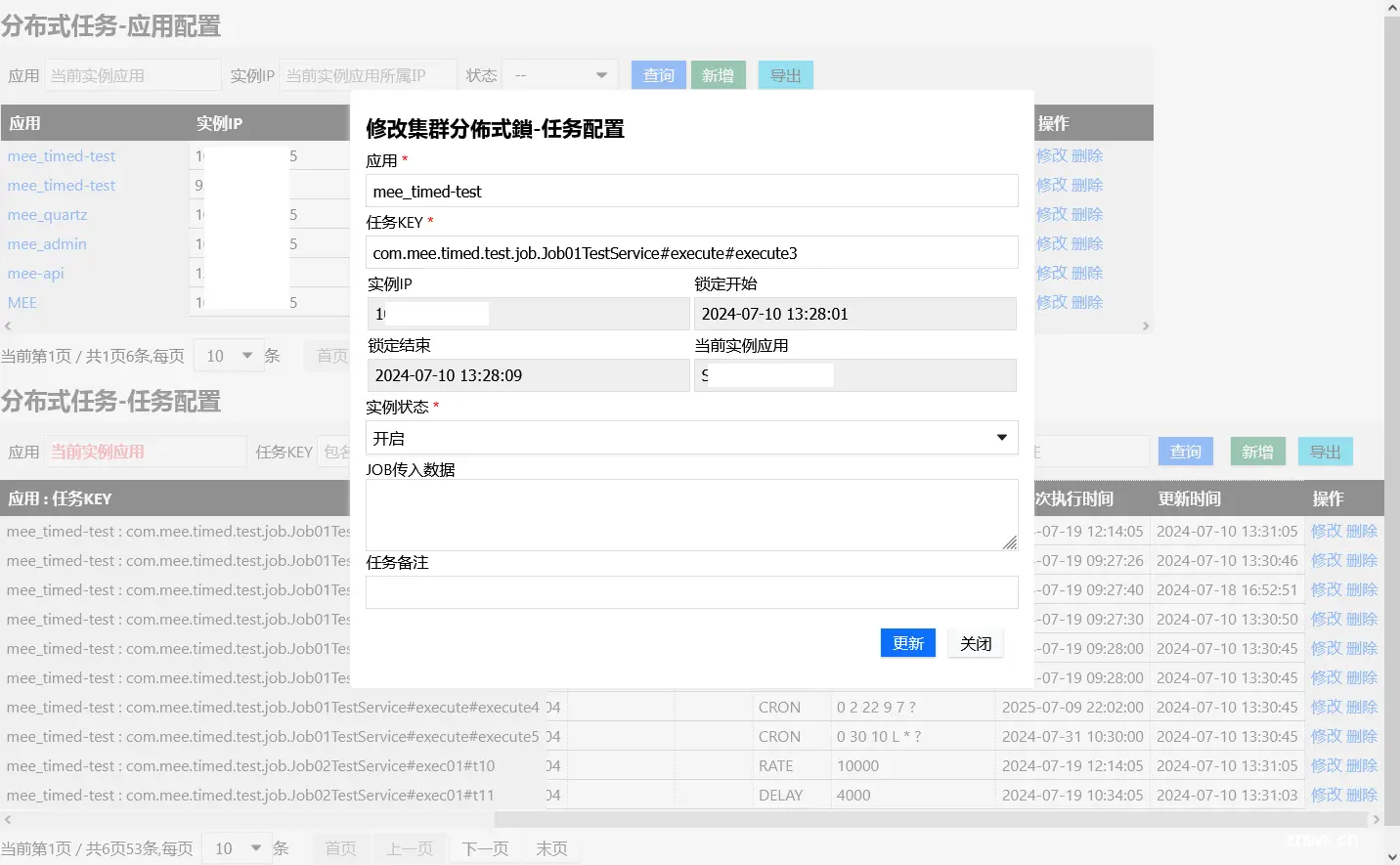
实际执行效果

<code>2024-07-18 09:59:20.006 -> [MEE_TIMED-7] -> INFO com.mee.cron.JobTimedService:25 - =====> proxy job exec! data:{"key":"执行数据"} <=====
2024-07-18 09:59:40.020 -> [MEE_TIMED-7] -> INFO com.mee.cron.JobTimedService:25 - =====> proxy job exec! data:{"key":"执行数据"} <=====
2024-07-18 09:59:59.993 -> [MEE_TIMED-1] -> INFO com.mee.cron.DefaultTimerService:27 - ===>testTask2執行時間: 2024-07-18 09:59:59
2024-07-18 10:00:00.003 -> [MEE_TIMED-5] -> INFO com.mee.cron.DefaultTimerService:21 - ===>testTask1執行時間: 2024-07-18 10:00:00
2024-07-18 10:00:00.009 -> [MEE_TIMED-4] -> INFO com.mee.cron.JobTimedService:25 - =====> proxy job exec! data:{"key":"执行数据"} <=====
2024-07-18 10:00:20.014 -> [MEE_TIMED-4] -> INFO com.mee.cron.JobTimedService:25 - =====> proxy job exec! data:{"key":"执行数据"} <=====
2024-07-18 10:00:40.015 -> [MEE_TIMED-4] -> INFO com.mee.cron.JobTimedService:25 - =====> proxy job exec! data:{"key":"执行数据"} <=====
2024-07-18 10:01:00.019 -> [MEE_TIMED-4] -> INFO com.mee.cron.JobTimedService:25 - =====> proxy job exec! data:{"key":"执行数据"} <=====
后续计划
首先是传参考虑做反序列化处理,在必要场景下这是需要的
fix bug,当然这需要码友多多支持啦
动态修改执行时间,尤其是
cron,这功能是与quartz的差距的缩小是决定性的执行日志支持,并提供扩展支持
其他待定
最后
再次感谢 spring scheduled 及 shedlock 的开源,MEE_TIMED 在 github 有开源,详见: https://github.com/funnyzpc/mee_timed_parent 🎈
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。