【深度学习】GAN生成对抗网络原理推导+代码实现(Python)
篝火者2312 2024-06-19 11:05:04 阅读 71
1、前言
本文将讲近些年来挺火的一个生成模型 G A N 生成对抗网络 \boxed{\mathbf{GAN生成对抗网络}} GAN生成对抗网络,其特殊的思路解法实在让人啧啧称奇。
数学基础:【概率论与数理统计知识复习-哔哩哔哩】
视频:【生成对抗网络GAN原理解析-哔哩哔哩】
2、原理
2.1、GAN的运行机理
在传统的生成模型中,我们总是对我们的训练数据(或观测变量和隐变量)进行建模,得到概率分布,然后进行数据的生成。可GAN却不是这样,其利用神经网络这个函数逼近器,求解出了模型中概率分布的参数 在不知道概率分布是什么的情况下 \boxed{在不知道概率分布是什么的情况下} 在不知道概率分布是什么的情况下。
其主要思想是,从一个简单的概率分布中采样,得到样本经过神经网络变换,得到一个新的样本,我们就假设这个样本就来自我们需要求解的概率分布中。然后用神经网络去辨别其是来自真实分布,还是我们要求解的概率分布。
先来看模型图
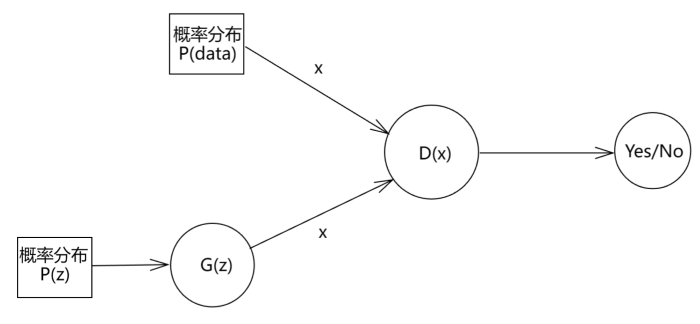
我们的训练数据 x x x是来自真实分布 对应图中 P ( d a t a ) \boxed{\mathbf{对应图中P(data)}} 对应图中P(data),我们记作 P d a t a P_{data} Pdata,训练数据都是从 P d a t a P_{data} Pdata中采样得来(图中上半部分的x)。
而我们从简单的概率分布中抽样 P ( z ) P(z) P(z) 如正态分布 \boxed{\mathbf{如正态分布}} 如正态分布,让所得的样本经过一个神经网络 G ( z ) G(z) G(z),得到一个新的样本 x x x,这个样本就来自我们的需要求解的概率分布,我们记作 P g P_{g} Pg。
然后将两个x给神经网络 D ( x ) D(x) D(x)判断真伪,让它区分这个x是来自 P d a t a P_{data} Pdata还是 P g P_g Pg,其输出样本来自 P d a t a P_{data} Pdata的概率。依据所得信息使用梯度下降更新神经网络参数, G ( z ) G(z) G(z)也是如此。
而 G ( z ) G(z) G(z)被称为生成器 ( 用于生成样本 ) \boxed{\mathbf{(用于生成样本)}} (用于生成样本), D ( x ) D(x) D(x)被称为判别器 用于判别样本真伪 \boxed{\mathbf{用于判别样本真伪}} 用于判别样本真伪。
2.2、目标函数
损失函数来自判别器和生成器 \boxed{\mathbf{损失函数来自判别器和生成器}} 损失函数来自判别器和生成器
对于判别器 \boxed{对于判别器} 对于判别器
当样本来自 P d a t a P_{data} Pdata,我们要让所得的概率越大越好;当样本来自 p g p_g pg,我们要让其概率越小越好,即
① max D D ( x i ) ② min D D ( G ( z i ) ) ①\max\limits_{D}D(x_i)\\ ②\min\limits_{D}D(G(z_i)) ①DmaxD(xi)②DminD(G(zi))
将最小化换成最大化
max D [ 1 − D ( G ( z i ) ) ] \max\limits_{D}[1-D(G(z_i))] Dmax[1−D(G(zi))]
所以单个样本判别器的损失函数可以写成
max D { D ( x i ) + [ 1 − D ( G ( z i ) ) ] } \max\limits_{D}\left\{D(x_i)+[1-D(G(z_i))]\right\} Dmax{ D(xi)+[1−D(G(zi))]}
对于所有样本N,我们希望均值最大
max D { 1 N ∑ i = 1 N D ( x i ) + 1 N ∑ i = 1 N [ 1 − D ( G ( z i ) ) ] } \max_D\left\{\frac{1}{N}\sum\limits_{i=1}^ND(x_i)+\frac{1}{N}\sum\limits_{i=1}^N[1-D(G(z_i))]\right\} Dmax{ N1i=1∑ND(xi)+N1i=1∑N[1−D(G(zi))]}
写成期望形式(并取log最大 不改变最大值 \boxed{不改变最大值} 不改变最大值),得到判别器的损失函数( x ∼ p d a t a x\sim p_{data} x∼pdata表示样本来自真实分布, P z P_z Pz表示正态分布)
max D { E x ∼ p d a t a [ log D ( x ) ] + E z ∼ P z [ log ( 1 − D ( G ( z ) ) ) ] } \boxed{\max\limits_{D}\left\{\mathbb{E}_{x\sim p_{data}}\left[\log D(x)\right]+\mathbb{E}_{z\sim P_z}\left[\log(1-D(G(z)))\right]\right\}} Dmax{ Ex∼pdata[logD(x)]+Ez∼Pz[log(1−D(G(z)))]}
接着,我们在上面讲到过,G(z)表示的是,采用一个z,经过一个神经网络,得到一个伪造出来的x。这个伪造的x服从分布 P g P_g Pg。那么我们就可以把第二个期望改写成x的表达式,于是便可得到
max D { E x ∼ p d a t a [ log D ( x ) ] + E x ∼ P g [ log ( 1 − D ( x ) ) ] } \boxed{\max\limits_{D}\left\{\mathbb{E}_{x\sim p_{data}}\left[\log D(x)\right]+\mathbb{E}_{x\sim P_g}\left[\log(1-D(x))\right]\right\}} Dmax{ Ex∼pdata[logD(x)]+Ex∼Pg[log(1−D(x))]}
对于生成器 \boxed{对于生成器} 对于生成器
它希望生成的样本让判别器判别为真的概率越大越好,所以直接设计成(将最大写成最小)
min G E x ∼ P g [ log ( 1 − D ( x ) ) ] \boxed{\min\limits_{G}\mathbb{E}_{x\sim P_g}\left[\log(1-D(x))\right]} GminEx∼Pg[log(1−D(x))]
所以最终的目标函数可以写成
min G max D { E x ∼ p d a t a [ log D ( x ) ] + E x ∼ P g [ log ( 1 − D ( x ) ) ] } \min\limits_{G}\max\limits_{D}\left\{\mathbb{E}_{x\sim p_{data}}\left[\log D(x)\right]+\mathbb{E}_{x\sim P_g}\left[\log(1-D(x))\right]\right\} GminDmax{ Ex∼pdata[logD(x)]+Ex∼Pg[log(1−D(x))]}
3、最优解求解
得到了目标函数,我们很显然还需要证明其存在最优解。并且最优解的 P g P_g Pg是否和 P d a t a P_{data} Pdata无限接近
先求里层(关于 D 求最大) \boxed{先求里层(关于D求最大)} 先求里层(关于D求最大)
E x ∼ p d a t a [ log D ( x ) ] + E x ∼ P g [ log ( 1 − D ( x ) ) ] = ∫ x log D ( x ) P d a t a ( x ) d x + ∫ x log ( 1 − D ( x ) ) P g ( x ) d x = ∫ x [ log D ( x ) P d a t a ( x ) + log ( 1 − D ( x ) ) P g ( x ) ] d x \begin{aligned} &\mathbb{E}_{x\sim p_{data}}\left[\log D(x)\right]+\mathbb{E}_{x\sim P_g}\left[\log(1-D(x))\right] \\=&\int_x\log D(x)P_{data}(x)dx+\int_x\log(1-D(x))P_g(x)dx \\=&\int_x\left[\log D(x)P_{data}(x)+\log(1-D(x))P_g(x)\right]dx \end{aligned} ==Ex∼pdata[logD(x)]+Ex∼Pg[log(1−D(x))]∫xlogD(x)Pdata(x)dx+∫xlog(1−D(x))Pg(x)dx∫x[logD(x)Pdata(x)+log(1−D(x))Pg(x)]dx
要求积分最大,就是要求里面的每一个最大
max D [ log D ( x ) P d a t a ( x ) + log ( 1 − D ( x ) ) P g ( x ) ] \max_D \left[{\log D(x)P_{data}(x)+\log(1-D(x))P_g(x)}\right] Dmax[logD(x)Pdata(x)+log(1−D(x))Pg(x)]
求导
∂ ∂ D l o g D ( x ) P d a t a ( x ) + log ( 1 − D ( x ) ) P g ( x ) = 1 D ( x ) P d a t a ( x ) − 1 1 − D ( x ) P g ( x ) \begin{aligned} &\frac{\partial }{\partial D}{log D(x)P_{data}(x)+\log(1-D(x))P_g(x)} \\=&\frac{1}{D(x)}P_{data}(x)-\frac{1}{1-D(x)}P_g(x) \end{aligned} =∂D∂logD(x)Pdata(x)+log(1−D(x))Pg(x)D(x)1Pdata(x)−1−D(x)1Pg(x)
整理得
D ( x ) = P d a t a ( x ) P g ( x ) + P d a t a ( x ) \boxed{D(x)=\frac{P_{data}(x)}{P_{g}(x)+P_{data}(x)}} D(x)=Pg(x)+Pdata(x)Pdata(x)
将其代入目标函数,并且关于外层 G 求最小 \boxed{将其代入目标函数,并且关于外层G求最小} 将其代入目标函数,并且关于外层G求最小
min G ∫ x [ log P d a t a ( x ) P g ( x ) + P d a t a ( x ) P d a t a ( x ) + log ( 1 − P d a t a ( x ) P g ( x ) + P d a t a ( x ) ) P g ( x ) ] d x = min G [ ∫ x log ( P d a t a ( x ) P g ( x ) + P d a t a ( x ) 2 ∗ 1 2 ) P d a t a ( x ) d x + ∫ x log ( P g ( x ) P g ( x ) + P d a t a ( x ) 2 ∗ 1 2 ) P g ( x ) d x ] = min G [ ∫ x log ( P d a t a ( x ) P g ( x ) + P d a t a ( x ) 2 ) P d a t a ( x ) d x + ∫ x log ( P g ( x ) P g ( x ) + P d a t a ( x ) 2 ) P g ( x ) d x + ∫ log 1 2 P d a t a ( x ) d x + ∫ log 1 2 P g ( x ) d x ] = min G [ ∫ x log ( P d a t a ( x ) P g ( x ) + P d a t a ( x ) 2 ) P d a t a ( x ) d x + ∫ x log ( P g ( x ) P g ( x ) + P d a t a ( x ) 2 ) P g ( x ) d x + log 1 2 ∫ P d a t a ( x ) d x + log 1 2 ∫ P g ( x ) d x ] = min G [ ∫ x log ( P d a t a ( x ) P g ( x ) + P d a t a ( x ) 2 ) P d a t a ( x ) d x + ∫ x log ( P g ( x ) P g ( x ) + P d a t a ( x ) 2 ) P g ( x ) d x + log 1 2 + log 1 2 ] = min G [ ∫ x log ( P d a t a ( x ) P g ( x ) + P d a t a ( x ) 2 ) P d a t a ( x ) d x + ∫ x log ( P g ( x ) P g ( x ) + P d a t a ( x ) 2 ) P g ( x ) d x + log 1 4 ] = min G K L ( P d a t a ( x ) ∣ ∣ P d a t a ( x ) + P g ( x ) 2 ) + K L ( P g ( x ) ∣ ∣ P d a t a ( x ) + P g ( x ) 2 ) − log 4 \begin{aligned} &\min_G \int_x\left[{\log \frac{P_{data}(x)}{P_{g}(x)+P_{data}(x)}P_{data}(x)+\log(1-\frac{P_{data}(x)}{P_{g}(x)+P_{data}(x)})P_g(x)}\right]dx \\=&\min\limits_{G}\left[\int_x\log\left(\frac{P_{data}(x)}{\frac{P_{g}(x)+P_{data}(x)}{2}}*\frac{1}{2}\right)P_{data}(x)dx+\int_x\log\left(\frac{P_g(x)}{\frac{P_g(x)+P_{data}(x)}{2}}*\frac{1}{2}\right)P_g(x)dx\right] \\=&\min\limits_{G}\left[\int_x\log\left(\frac{P_{data}(x)}{\frac{P_{g}(x)+P_{data}(x)}{2}}\right)P_{data}(x)dx+\int_x\log\left(\frac{P_g(x)}{\frac{P_g(x)+P_{data}(x)}{2}}\right)P_g(x)dx+\int \log\frac{1}{2}P_{data}(x)dx+\int\log\frac{1}{2}P_{g}(x)dx\right]\\=&\min\limits_{G}\left[\int_x\log\left(\frac{P_{data}(x)}{\frac{P_{g}(x)+P_{data}(x)}{2}}\right)P_{data}(x)dx+\int_x\log\left(\frac{P_g(x)}{\frac{P_g(x)+P_{data}(x)}{2}}\right)P_g(x)dx+\log\frac{1}{2}\int P_{data}(x)dx+\log\frac{1}{2}\int P_{g}(x)dx\right]\\=&\min\limits_{G}\left[\int_x\log\left(\frac{P_{data}(x)}{\frac{P_{g}(x)+P_{data}(x)}{2}}\right)P_{data}(x)dx+\int_x\log\left(\frac{P_g(x)}{\frac{P_g(x)+P_{data}(x)}{2}}\right)P_g(x)dx+\log\frac{1}{2}+\log\frac{1}{2}\right]\\=&\min\limits_{G}\left[\int_x\log\left(\frac{P_{data}(x)}{\frac{P_{g}(x)+P_{data}(x)}{2}}\right)P_{data}(x)dx+\int_x\log\left(\frac{P_g(x)}{\frac{P_g(x)+P_{data}(x)}{2}}\right)P_g(x)dx+\log\frac{1}{4}\right] \\=&\min\limits_{G}KL\left(P_{data}(x)||\frac{P_{data}(x)+P_{g}(x)}{2}\right)+KL\left(P_{g}(x)||\frac{P_{data}(x)+P_{g}(x)}{2}\right)-\log4 \end{aligned} ======Gmin∫x[logPg(x)+Pdata(x)Pdata(x)Pdata(x)+log(1−Pg(x)+Pdata(x)Pdata(x))Pg(x)]dxGmin[∫xlog(2Pg(x)+Pdata(x)Pdata(x)∗21)Pdata(x)dx+∫xlog(2Pg(x)+Pdata(x)Pg(x)∗21)Pg(x)dx]Gmin[∫xlog(2Pg(x)+Pdata(x)Pdata(x))Pdata(x)dx+∫xlog(2Pg(x)+Pdata(x)Pg(x))Pg(x)dx+∫log21Pdata(x)dx+∫log21Pg(x)dx]Gmin[∫xlog(2Pg(x)+Pdata(x)Pdata(x))Pdata(x)dx+∫xlog(2Pg(x)+Pdata(x)Pg(x))Pg(x)dx+log21∫Pdata(x)dx+log21∫Pg(x)dx]Gmin[∫xlog(2Pg(x)+Pdata(x)Pdata(x))Pdata(x)dx+∫xlog(2Pg(x)+Pdata(x)Pg(x))Pg(x)dx+log21+log21]Gmin[∫xlog(2Pg(x)+Pdata(x)Pdata(x))Pdata(x)dx+∫xlog(2Pg(x)+Pdata(x)Pg(x))Pg(x)dx+log41]GminKL(Pdata(x)∣∣2Pdata(x)+Pg(x))+KL(Pg(x)∣∣2Pdata(x)+Pg(x))−log4
K L ( p ∣ ∣ q ) = ∫ x p log p q d x KL(p||q)=\int_xp\log\frac{p}{q}dx KL(p∣∣q)=∫xplogqpdx,KL散度是衡量概率分布 p p p和 q q q的相似程度,其大于等于0,当其相似程度一样时,则散度为0,也就是我们要求的最小值。
小补充 \boxed{小补充} 小补充
2 J S ( P d a t a ( x ) ∣ ∣ P g ( x ) ) = K L ( P d a t a ( x ) ∣ ∣ P d a t a ( x ) + P g ( x ) 2 ) + K L ( P g ( x ) ∣ ∣ P d a t a ( x ) + P g ( x ) 2 ) \boxed{\mathbf{2JS\left(P_{data}(x)||P_g(x)\right)=KL\left(P_{data}(x)||\frac{P_{data}(x)+P_{g}(x)}{2}\right)+KL\left(P_{g}(x)||\frac{P_{data}(x)+P_{g}(x)}{2}\right)}} 2JS(Pdata(x)∣∣Pg(x))=KL(Pdata(x)∣∣2Pdata(x)+Pg(x))+KL(Pg(x)∣∣2Pdata(x)+Pg(x))
J S ( p ∣ ∣ q ) JS(p||q) JS(p∣∣q)被称为JS散度,其仍然是大于等于0的。所以是一样的。
所以
P d a t a ( x ) = P g ( x ) + P d a t a 2 → P d a t a = P g ( x ) P_{data}(x)=\frac{P_g(x)+P_{data}}{2} \rightarrow P_{data}=P_g(x) Pdata(x)=2Pg(x)+Pdata→Pdata=Pg(x)
由此可见,目标函数最优值能够让 P g 逼近 P d a t a \boxed{\mathbb{由此可见,目标函数最优值能够让P_g 逼近P_{data}}} 由此可见,目标函数最优值能够让Pg逼近Pdata,并且当其相等时,有
D ( x ) = P d a t a ( x ) P g ( x ) + P d a t a ( x ) = 1 2 \boxed{D(x)=\frac{P_{data}(x)}{P_{g}(x)+P_{data}(x)}}=\frac{1}{2} D(x)=Pg(x)+Pdata(x)Pdata(x)=21
也就是判别器再也无法判断出样本是来自 P d a t a P_{data} Pdata还是 P g P_g Pg
4、代码实现
结果如下

效果一般,在其他变种优化有很多比这个好的,感兴趣的读者自行查阅。
import torchfrom torchvision.datasets import MNISTfrom torchvision import transformsfrom torch.utils.data import DataLoaderfrom tqdm import tqdmimport matplotlib.pyplot as pltclass Generate_Model(torch.nn.Module): ''' 生成器 ''' def __init__(self): super().__init__() self.fc=torch.nn.Sequential( torch.nn.Linear(in_features=128,out_features=256), torch.nn.Tanh(), torch.nn.Linear(in_features=256,out_features=512), torch.nn.ReLU(), torch.nn.Linear(in_features=512,out_features=784), torch.nn.Tanh() ) def forward(self,x): x=self.fc(x) return xclass Distinguish_Model(torch.nn.Module): ''' 判别器 ''' def __init__(self): super().__init__() self.fc=torch.nn.Sequential( torch.nn.Linear(in_features=784,out_features=512), torch.nn.Tanh(), torch.nn.Linear(in_features=512,out_features=256), torch.nn.Tanh(), torch.nn.Linear(in_features=256,out_features=128), torch.nn.Tanh(), torch.nn.Linear(in_features=128,out_features=1), torch.nn.Sigmoid() ) def forward(self,x): x=self.fc(x) return xdef train(): device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #判断是否存在可用GPU transformer = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(mean=0.5, std=0.5) ]) #图片标准化 train_data = MNIST("./data", transform=transformer,download=True) #载入图片 dataloader = DataLoader(train_data, batch_size=64,num_workers=4, shuffle=True) #将图片放入数据加载器 D = Distinguish_Model().to(device) #实例化判别器 G = Generate_Model().to(device) #实例化生成器 D_optim = torch.optim.Adam(D.parameters(), lr=1e-4) #为判别器设置优化器 G_optim = torch.optim.Adam(G.parameters(), lr=1e-4) #为生成器设置优化器 loss_fn = torch.nn.BCELoss() #损失函数 epochs = 100 #迭代100次 for epoch in range(epochs): dis_loss_all=0 #记录判别器损失损失 gen_loss_all=0 #记录生成器损失 loader_len=len(dataloader) #数据加载器长度 for step,data in tqdm(enumerate(dataloader), desc="第{}轮".format(epoch),total=loader_len): # 先计算判别器损失 sample,label=data #获取样本,舍弃标签 sample = sample.reshape(-1, 784).to(device) #重塑图片 sample_shape = sample.shape[0] #获取批次数量 #从正态分布中抽样 sample_z = torch.normal(0, 1, size=(sample_shape, 128),device=device) Dis_true = D(sample) #判别器判别真样本 true_loss = loss_fn(Dis_true, torch.ones_like(Dis_true)) #计算损失 fake_sample = G(sample_z) #生成器通过正态分布抽样生成数据 Dis_fake = D(fake_sample.detach()) #判别器判别伪样本 fake_loss = loss_fn(Dis_fake, torch.zeros_like(Dis_fake)) #计算损失 Dis_loss = true_loss + fake_loss #真假加起来 D_optim.zero_grad() Dis_loss.backward() #反向传播 D_optim.step() # 生成器损失 Dis_G = D(fake_sample) #判别器判别 G_loss = loss_fn(Dis_G, torch.ones_like(Dis_G)) #计算损失 G_optim.zero_grad() G_loss.backward() #反向传播 G_optim.step() with torch.no_grad(): dis_loss_all+=Dis_loss #判别器累加损失 gen_loss_all+=G_loss #生成器累加损失 with torch.no_grad(): dis_loss_all=dis_loss_all/loader_len gen_loss_all=gen_loss_all/loader_len print("判别器损失为:{}".format(dis_loss_all)) print("生成器损失为:{}".format(gen_loss_all)) torch.save(G, "./model/G.pth") #保存模型 torch.save(D, "./model/D.pth") #保存模型if __name__ == '__main__': # train() #训练模型 model_G=torch.load("./model/G.pth",map_location=torch.device("cpu")) #载入模型 fake_z=torch.normal(0,1,size=(10,128)) #抽样数据 result=model_G(fake_z).reshape(-1,28,28) #生成数据 result=result.detach().numpy() #绘制 for i in range(10): plt.subplot(2,5,i+1) plt.imshow(result[i]) plt.gray() plt.show()
5、结束
以上,就是GAN生成对抗网络的全部内容了,如有问题,还望指出。阿里嘎多

下一篇: 2023南京邮电大学通达学院《数学实验》MATLAB实验答案
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。