PyTorch 深度学习实战 | 基于生成式对抗网络生成动漫人物
CSDN 2024-08-10 16:31:01 阅读 96

生成式对抗网络(Generative Adversarial Network, GAN)是近些年计算机视觉领域非常常见的一类方法,其强大的从已有数据集中生成新数据的能力令人惊叹,甚至连人眼都无法进行分辨。本文将会介绍基于最原始的DCGAN的动漫人物生成任务,通过定义生成器和判别器,并让这两个网络在参数优化过程中不断“打架”,最终得到较好的生成结果。
01、生成动漫人物任务概述
日本动漫中会出现很多的卡通人物,这些卡通人物都是漫画家花费大量的时间设计绘制出来的,那么,假设已经有了一个卡通人物的集合,那么深度学习技术可否帮助漫画家们根据已有的动漫人物形象,设计出新的动漫人物形象呢?
本文使用的数据集包含已经裁减完成的头像如图1所示,每张图像的大小为96*96*3像素,总数为51000张。
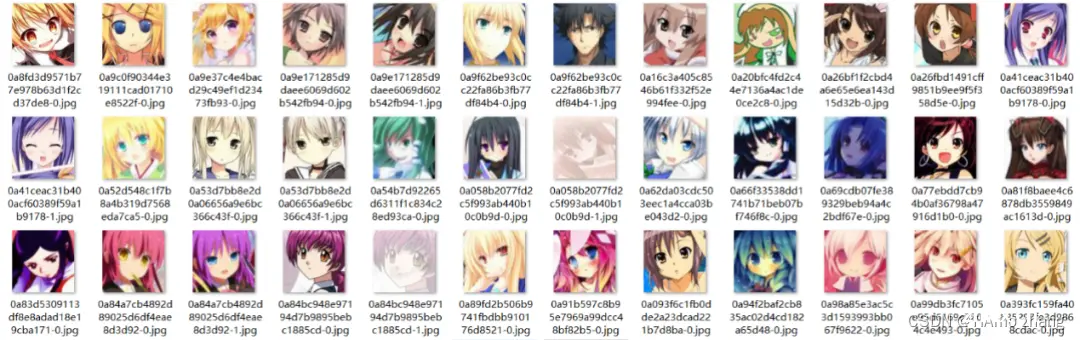
图 1 动漫人物数据集
这项任务与之前的有监督任务不同之处在于,监督任务是有明确的输入和输出来对模型进行优化调整,而这一项任务是基于已有的数据集生成新的与原有数据集相似的新的数据。这是一个典型生成式任务,即假设原始数据集中所有的动漫图像都服从于某一分布,数据集中的图片是从这个分布随机采样得到的,倘若可以获得这个分布是什么,那么就可以获得与数据集中图片分布相同但完全不同的新的动漫形象。因此,生成式任务最重要核心任务就在于如何去获得这个分布。现有的基于图像的生成式框架有VAE和GAN两大分支,GAN的大名想必很多人都有所耳闻,其实验效果也是要由于VAE分支,本文将介绍基于GAN的动漫人物生成任务。
02、反卷积网络
反卷积层是GAN网络的非常重要的一个部件。大多数卷积层会使特征图的尺寸不断变小,但反卷积层是为了使得特征图逐渐变大,甚至与最初的输入图片一致。反卷积层最开始用于分割任务,后来也被广泛应用于生成式任务中,如图2所示,为一个反卷积层的正向传播时的计算过程,下层蓝色色块的为输入,白色虚线色块为padding的部分,上层绿色的为反卷积层的输出,原本3×3大小的特征图经过反卷积可以得到5×5的输出。本文的网络结构中也使用了反卷积层作为重要的一环。

图2 反卷积示意图
在分类或者分割等计算机视觉的任务当中,最终损失函数都需要对网络的输出与标签的差异进行量化,比如常见的L1、L2、交叉熵等损失函数,那么在生成式任务当中,当网络输出一张新的图片,如何去评判这张图片与原始数据集的分布是否一致?这是非常困难的一项事情,而GAN用很巧妙的思路规避了直接去判断分布是否一致,通过引入另一个网络(判别器)实现了判断两张图片是否一致这一任务。
具体来说,假设原始的分布为Pdata(X) ,PG(X;θ) 指参数值为θ的卷积网络,其以随机数x作为初入,输出一张图像,该卷积网络称为生成器,根据最大似然定理,希望每个样例出现的概率的乘积最大,即最大化:

对 θ 进行求解,可得:
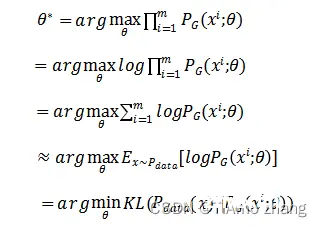
即GAN的生成器目标是找到PG(X;θ)的一组参数,使其接近Pdata(X)分布,从而最小化生成器G生成结果与原始数据之间的差异
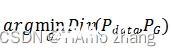
为了解决这个问题,GAN引入了判别器的概念,使用判别器D(X),来判断PG(X;θ)生成的结果与Pdata(X)分布是否一致,判别器的目标是给真样本奖励,假样本惩罚,判别器的目的在于尽可能的区分生成器生成的样本与数据集的样本,当输入为数据集的样本时,判别器输出为真,当输入为生成器生成的样本时,判别器输出为假,GAN的结构如图 3所示。
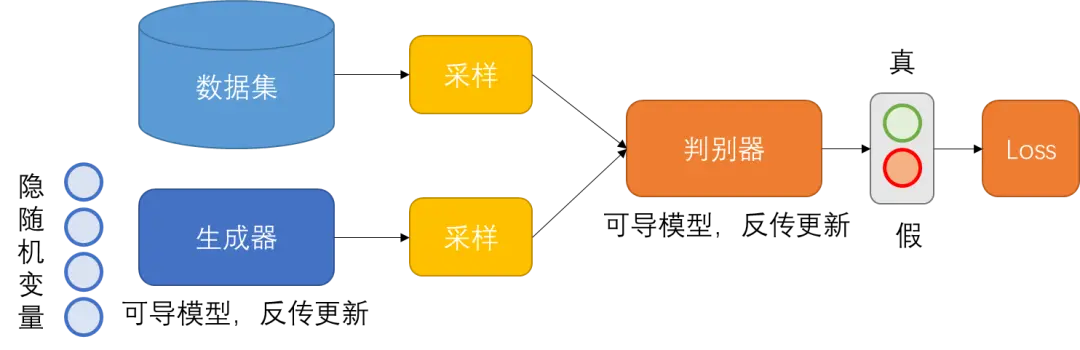
图3 GAN模型结构
判别器希望最大化的目标函数,就是

这一优化目标与交叉熵函数的形式非常相似,需要注意的是,在优化判别器时,生成器中的参数是不变的。生成器与判别器的目标不同,由于没有像监督学习那样的标签用于生成器,因此,生成器的目标为尽可能的骗过判别器,使判别器认为生成器生成的样本与原始数据集分布一致,即生成器的目标函数为
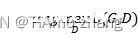
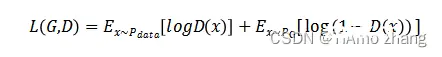
至此,GAN的损失函数可写为

03、DCGAN
本文中使用DCGAN作为网络模型,其核心思想与GAN一致,只是将原始GAN的多层感知器替换为了卷积神经网络,从而更符合图像的性质。下面介绍DCGAN的结构。
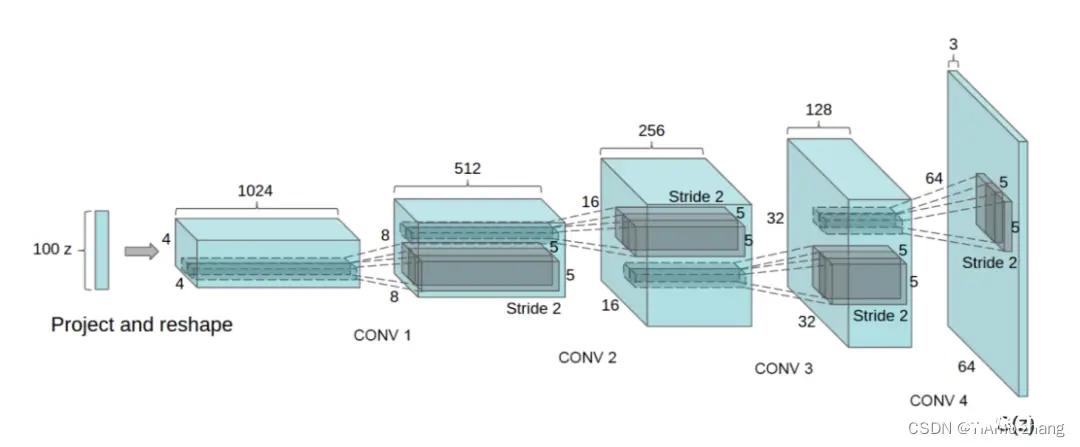
图4 DCGAN生成器网络结构
如图4可知,DCGAN的生成器从一个100维的随机变量开始,不断叠加使用反卷积层,最终得到的64*64*3的输出层。
其判别器为一个5层的卷积结构,以64*64*3大小作为输入,单独一个值作为输出,为输入判别器的图像与数据集图像同分布的概率。
训练步骤与损失函数与上文中GAN的一致,通过交替更新参数的方式,使生成器和判别器逐渐收敛。在下文中将具体介绍如何构建DCGAN并实现动漫人物生成。
04、基于DCGAN的动漫人物生成
新建GanModel.py文件,并在这个脚本中构建DCGAN的生成器和判别器模型,首先是生成器模型,由于本数据集的图片大小为96*96,因此对原始DCGAN的参数做了一些调整,使得最终经过生成器得到的图片大小也是96*96。
如代码清单1所示为经过调整后的生成器网络,同样包含有5层,出去最后一层,每层中都有一个卷积层、一个归一化层以及一个激活函数。
代码清单1 调整后的生成器网络
<code>1.import torch.nn as nn
2.# 定义生成器网络G
3.class Generator(nn.Module):
4. def __init__(self, nz=100):
5. super(Generator, self).__init__()
6. # layer1输入的是一个100x1x1的随机噪声, 输出尺寸1024x4x4
7. self.layer1 = nn.Sequential(
8. nn.ConvTranspose2d(nz, 1024, kernel_size=4, stride=1, padding=0, bias=False),
9. nn.BatchNorm2d(1024),
10. nn.ReLU(inplace=True)
11. )
12. # layer2输出尺寸512x8x8
13. self.layer2 = nn.Sequential(
14. nn.ConvTranspose2d(1024, 512, 4, 2, 1, bias=False),
15. nn.BatchNorm2d(512),
16. nn.ReLU(inplace=True)
17. )
18. # layer3输出尺寸256x16x16
19. self.layer3 = nn.Sequential(
20. nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
21. nn.BatchNorm2d(256),
22. nn.ReLU(inplace=True)
23. )
24. # layer4输出尺寸128x32x32
25. self.layer4 = nn.Sequential(
26. nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
27. nn.BatchNorm2d(128),
28. nn.ReLU(inplace=True)
29. )
30. # layer5输出尺寸 3x96x96
31. self.layer5 = nn.Sequential(
32. nn.ConvTranspose2d(128, 3, 5, 3, 1, bias=False),
33. nn.Tanh()
34. )
35.
36. # 定义Generator的前向传播
37. def forward(self, x):
38. out = self.layer1(x)
39. out = self.layer2(out)
40. out = self.layer3(out)
41. out = self.layer4(out)
42. out = self.layer5(out)
43. return out
定义判别器模型及前向传播过程如代码清单2所示。
代码清单2 判别器模型的定义与前向传播过程
1.# 定义鉴别器网络D
2.class Discriminator(nn.Module):
3. def __init__(self):
4. super(Discriminator, self).__init__()
5. # layer1 输入 3 x 96 x 96, 输出 64 x 32 x 32
6. self.layer1 = nn.Sequential(
7. nn.Conv2d(3, 64, kernel_size=5, stride=3, padding=1, bias=False),
8. nn.BatchNorm2d(64),
9. nn.LeakyReLU(0.2, inplace=True)
10. )
11. # layer2 输出 128 x 16 x 16
12. self.layer2 = nn.Sequential(
13. nn.Conv2d(64, 128, 4, 2, 1, bias=False),
14. nn.BatchNorm2d(128),
15. nn.LeakyReLU(0.2, inplace=True)
16. )
17. # layer3 输出 256 x 8 x 8
18. self.layer3 = nn.Sequential(
19. nn.Conv2d(128, 256, 4, 2, 1, bias=False),
20. nn.BatchNorm2d(256),
21. nn.LeakyReLU(0.2, inplace=True)
22. )
23. # layer4 输出 512 x 4 x 4
24. self.layer4 = nn.Sequential(
25. nn.Conv2d(256, 512, 4, 2, 1, bias=False),
26. nn.BatchNorm2d(512),
27. nn.LeakyReLU(0.2, inplace=True)
28. )
29. # layer5 输出预测结果概率
30. self.layer5 = nn.Sequential(
31. nn.Conv2d(512, 1, 4, 1, 0, bias=False),
32. nn.Sigmoid()
33. )
34.
35. # 前向传播
36. def forward(self, x):
37. out = self.layer1(x)
38. out = self.layer2(out)
39. out = self.layer3(out)
40. out = self.layer4(out)
41. out = self.layer5(out)
42. return out
定义完模型的基本结构后,新建另一个python脚本DCGAN.py,并将数据集放在同一目录下。如代码清单3所示,首先是引入会用到的各种包以及超参数,将超参数写在最前面方便后续需要修改的时候进行调整。其中超参数主要包含,一次迭代的batchsize大小,这个参数视GPU的性能而定,一般建议8以上,如果显存足够大,可以增大batchsize,batchsize越大,训练的速度也会越快。ImageSize为输入的图片大小,Epoch为训练要在数据集上训练几个轮次,Lr是优化器最开始的学习率的大小,Beta1为Adam优化器的一阶矩估计的指数衰减率,以及DataPath为数据集存放位置,OutPath为最终结果存放位置。
代码清单3 DCGAN超参数定义
1.import torch
2.import torchvision
3.import torchvision.utils as vutils
4.import torch.nn as nn
5.from GanModel import Generator, Discriminator
6.
7.# 设置超参数
8.BatchSize = 8
9.ImageSize = 96
10.Epoch = 25
11.Lr = 0.0002
12.Beta1 = 0.5
13.DataPath = './faces/'
14.OutPath = './imgs/'
15.# 定义是否使用GPU
16.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
接下来定义train函数,如代码清单4所示。以数据集、生成器、鉴别器作为函数输入,首先设置优化器以及损失函数。
代码清单4 train函数定义
1.def train(netG, netD, dataloader):
2. criterion = nn.BCELoss()
3. optimizerG = torch.optim.Adam(netG.parameters(), lr=Lr, betas=(Beta1, 0.999))
4. optimizerD = torch.optim.Adam(netD.parameters(), lr=Lr, betas=(Beta1, 0.999))
5.
6. label = torch.FloatTensor(BatchSize)
7. real_label = 1
8. fake_label = 0
再开始一轮一轮的迭代训练并输出中间结果,方便debug。
代码清单5 鉴别器训练
1.for epoch in range(1, Epoch + 1):
2. for i, (imgs, _) in enumerate(dataloader):
3. # 固定生成器G,训练鉴别器D
4. optimizerD.zero_grad()
5. # 让D尽可能的把真图片判别为1
6. imgs = imgs.to(device)
7. output = netD(imgs)
8. label.data.fill_(real_label)
9. label = label.to(device)
10. errD_real = criterion(output, label)
11. errD_real.backward()
12. # 让D尽可能把假图片判别为0
13. label.data.fill_(fake_label)
14. noise = torch.randn(BatchSize, 100, 1, 1)
15. noise = noise.to(device)
16. fake = netG(noise)
17. # 避免梯度传到G,因为G不用更新
18. output = netD(fake.detach())
19. errD_fake = criterion(output, label)
20. errD_fake.backward()
21. errD = errD_fake + errD_real
22. optimizerD.step()
如代码清单5所示,首先固定生成器的参数,并随机一组随机数送入生成器得到一组假图片,同时从数据集中抽取同样数目的真图片,假图片对应标签为0,真图片对应标签为1,将这组数据送入判别器进行参数更新。
代码清单 6 生成器训练
1. # 固定鉴别器D,训练生成器G
2. optimizerG.zero_grad()
3. # 让D尽可能把G生成的假图判别为1
4. label.data.fill_(real_label)
5. label = label.to(device)
6. output = netD(fake)
7. errG = criterion(output, label)
8. errG.backward()
9. optimizerG.step()
10. if i % 50 == 0:
11. print('[%d/%d][%d/%d] Loss_D: %.3f Loss_G %.3f'
12. % (epoch, Epoch, i, len(dataloader), errD.item(), errG.item()))
13.
14.vutils.save_image(fake.data,
15. '%s/fake_samples_epoch_%03d.png' % (OutPath, epoch),
16. normalize=True)
17.torch.save(netG.state_dict(), '%s/netG_%03d.pth' % (OutPath, epoch))
18.torch.save(netD.state_dict(), '%s/netD_%03d.pth' % (OutPath, epoch))
如代码清单6所示,接下来固定判别器参数,训练生成器,生成器的目标是根据随机数生成得到的图片能够骗过判别器,使之认为这些图片为真,因此将生成得到的假图经过判别器得到判别结果,并设置标签全部为1,计算损失函数并反向传播对生成器参数进行更新。
在训练过程中,不断打印生成器和判别器Loss的变化情况,从而方便进行观察并调整参数。每训练完一个Epoch,则将该Epoch中生成器得到的假图保存下来,同时存储生成器和判别器的参数,防止训练过程突然被终止,可以使用存储的参数进行恢复,不需要再从头进行训练。
最后完成mian函数主程序入口代码的编写,其包含了加载数据集、定义模型、训练等步骤,如代码清单 7所示。
Transforms定义了对数据集中输入图片进行预处理的步骤,主要包含scale对输入图片大小进行调整,ToTensor转化为PyTorch的Tensor类型以及Normalize中使用均值和标准差来进行图片的归一化。
代码清单7 主程序
1.if __name__ == "__main__":
2. # 图像格式转化与归一化
3. transforms = torchvision.transforms.Compose([
4. torchvision.transforms.Scale(ImageSize),
5. torchvision.transforms.ToTensor(),
6. torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
7. dataset = torchvision.datasets.ImageFolder(DataPath, transform=transforms)
8.
9. dataloader = torch.utils.data.DataLoader(
10. dataset=dataset,
11. batch_size=BatchSize,
12. shuffle=True,
13. drop_last=True,
14. )
15.
16. netG = Generator().to(device)
17. netD = Discriminator().to(device)
18. train(netG, netD, dataloader)
开始训练后,在命令行可得类似于如图5的输出。

图5 训练过程命令行输出
与手写数字识别不同在于,可以发现生成器和判别器的Loss值都在一会高一会低的状态,这种状态是我们想要的结果吗?如果大家注意观察,会发现很多情况下当判别器的Loss值下降时,生成器的Loss值会上升,而判别器的Loss出现了上升,生成器Loss会出现下降。这是由于判别器和生成器一直处于一种互相“打架”的状态,生成器想要骗过判别器,而判别器则努力不去被生成器骗过,才会有Loss值出现如此状况。两个网络在循环打架过程中不断增强,最终就可以得到一个甚至能骗过人眼的生成器。
让我们来看一下经过一个Epoch迭代后的生成器得到的结果如图6所示。

图6 Epoch1测试结果可视化
好像已经有了那么一些轮廓,但又像戴了近视镜一样看不清,颇有些印象派作家的画风,继续训练网络,如图7所示,等到第5,第10个Epoch,会发现生成器生成的质量越来越高。

图7 Epoch15测试结果可视化
一直到第25个Epoch,得到的结果如图 8所示,尽管生成的图片中还是存在一些结构性问题,但也有一些图片逐渐开始接近于我们的期待。当然,本文迭代次数较少,仅有25次,若进一步升高迭代次数,最终可获得更加真实的动漫头像。

图8 Epoch25测试结果可视化
05、文末送书

今天给大家送出的是由冀俊峰著【作者简介】北京大学出版社出版的《数字身份与元宇宙信任治理》!
解析元宇宙框架及其信任治理底层逻辑,讨论数字身份模式的发展趋势,分解元宇宙数字身份的技术要素,建设元宇宙信任环境,助力未来元宇宙数字身份构建、管理、应用赋能及零信任安全管理。
内容简介
本书是一本介绍数字身份和元宇宙的普及型书籍,力求专业性与通俗性相平衡。全书共八章,其中前四章主要介绍数字身份管理及应用,包括数字身份的相关概念及特性;身份认证管理、应用赋能及零信任安全管理;各国的数字身份实施;讨论数字身份在公共治理、商业服务等领域的应用价值。后面四章主要探究元宇宙框架及其信任治理,从Web技术架构的演变,介绍元宇宙的网络技术基础Web 3.0,以及相关的数字身份模式的发展趋势;讨论元宇宙中的数字身份技术要素及形态特征,以及数字身份、数字分身等关键特征要素;探讨利用数字身份对元宇宙的信任环境进行治理的方法和技术;探讨如何构建元宇宙的信任治理规则。
作者简介
冀俊峰,中科院软件所博士,高级工程师,论文曾获得国际计算机图形学会议CGI'2005 最佳论文。自2005 年以来,作者一直在国家信息中心及国家电子政务外网管理中心从事网络规划及数字经济等方面的发展研究工作,撰写论文曾多次获得国家发改委中青年经济论坛优秀论文。主要做图形学VR\AR\区块链等。
参与方式:点击文章置顶评论红包,手气王自动获得北京大学出版社《数字身份与元宇宙信任治理》1本。
上一篇: 国内AI领域领航者:讯飞星火、通义千问、Kimi、豆包AI、商汤AI、文心一方等12大AI模型谁最厉害?(都附链接)
下一篇: 探索AI前沿:本地部署GPT-4o,打造专属智能助手!
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。