C语言:深入理解指针(2)
✿༺小陈在拼命༻✿ 2024-06-21 15:35:02 阅读 97

创作不易,友友们给个三连吧!
通过深入理解指针(1),我们对指针有了一个初步的了解,还了解了指针变量类型的意义、指针的运算、assert断言、const修饰变量、野指针………………下面我们继续深入学习。
一、数组名的理解
通过深入理解指针(1),我们对于数组名arr的理解是数组首元素的地址,但其实这有两个例外。这里先引入结论,然后再去证实
· sizeof(数组名),sizeof中单独放数组名,这⾥的数组名表⽰整个数组,计算的是整个数组的⼤⼩, 单位是字节。
· &数组名,这⾥的数组名表⽰整个数组,取出的是整个数组的地址(整个数组的地址和数组⾸元素 的地址是有区别的)
下面观察这段代码
int main(){int arr[10];for (int i = 0; i < 10; i++){arr[i] = i + 1;//赋给1 2 3 4 5 6 7 8 9 10}printf("sizeof(arr)=%d\n\t", sizeof(arr));printf("&arr[0]=%d\n\t", &arr[0]);printf("arr=%d\n\t", arr);printf("&arr=%d\n\t", &arr);}
运行结果第1行证实了sizeof(arr)传入的arr是整个arr数组的大小
sizeof(arr)=40
&arr[0]=-488703448
arr=-488703448
&arr=-488703448
在理解运行结果第2、3、4行时,要先区别&arr[0],arr,&arr
·&arr[0]:取arr数组第一个元素的地址
·arr:数组名代表数组首元素的地址
·&arr:&数组名表示取出整个数组的地址
为什么&arr是取出整个数组的地址,打印出来的地址还是和&arr[0]、arr一样呢?
原因是由于数组在内存中的连续存放的,所以&arr的底层逻辑也是通过取得首元素地址,再顺腾摸瓜地找到其他元素的地址,所以直接打印的话结果是一样的。
那从哪里可以体现出&arr传入的是整个数组的地址呢??就需要指针运算来理解。
int main(){int arr[10];for (int i = 0; i < 10; i++){arr[i] = i+1;//赋给1 2 3 4 5 6 7 8 9 10}printf("sizeof(arr)=%d\n\t",sizeof(arr));printf("&arr[0]=%d\n\t", &arr[0]);printf("&arr[0]+1=%d\n\t", &arr[0]+1);printf("arr=%d\n\t", arr);printf("arr+1=%d\n\t", arr+1);printf("&arr=%d\n\t", &arr);printf("&arr+1=%d\n\t", &arr+1);}
sizeof(arr)=40
&arr[0]=-472712616
&arr[0]+1=-472712612
arr=-472712616
arr+1=-472712612
&arr=-472712616
&arr+1=-472712576
对于arr和&arr[0]来说,由于元素的数据类型是int类型,所以+1会导致指针偏移4个字节,而对于arr来说,由于传入的是整个数组,所以+1会跳过整个数组!
二、使用指针访问数组
为什么可以通过指针去访问数组呢?
1.数组在内存中是连续存放的。
2.数组名就是首元素地址(很容易就可以找到首元素地址)。
3.结合1和2,以及指针计算的特点,我们可以很容易通过起始位置向下访问找到后面的值。
int main(){int arr[10];int sz = sizeof(arr) / sizeof(arr[0]);//计算数组元素个数for (int i = 0; i < sz; i++) arr[i] = i+1;//赋给1 2 3 4 5 6 7 8 9 10int* p = arr;//p指针变量接受数组首元素地址//输出for (int i = 0; i < sz; i++)printf("%d ", arr[i]);printf("\n");for (int i = 0; i < sz; i++)printf("%d ", *(p + i));printf("\n");for (int i = 0; i < sz; i++)printf("%d ", *(arr + i));printf("\n");for (int i = 0; i < sz; i++)printf("%d ", i[arr]);printf("\n");for (int i = 0; i < sz; i++)printf("%d ", i[p]);}
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10
通过上面的代码的运行结果,我们来分析指针访问数组的特点。
1、运行结果第一行:在没有学习指针之前,我们想要打印数组中的元素,是用arr[i]去访问,其实就是通过数组下标去访问数组中的元素。
2、运行结果第二行:学习了指针之后,我们可以通过数组连续存放的特点,创建了指针变量p去接收首元素的地址,然后通过指针计算的特点,p+1可以跳过对应数据类型的字节从而访问到下一个元素的地址,再通过解引用得到对应的元素,所以*(p+i)是可行的。
3、运行结果第三行:通过本章节的学习,我们知道arr就是首元素地址大小,那么p接受的是首元素的地址,所以arr和p是等价的,所以*(p+i)可以改写成*(arr+i),在这里,我们发现arr[i]=*(arr+i)其实就是访问数组元素的底层逻辑,编译器在处理时,转换成首元素地址+偏移量求出元素的地址,再通过解引用来访问。其中arr代表的是数组首元素地址,而i代表的是地址(指针)偏移量。
4.运行结果第四行:根据加法交换律,*(i+arr)又可以反推成i[arr]的形式,我们发现这种形式时成立的,这与们以往的认知有偏差,按道理来说[ ]中应该写的时数组的元素下标,但这里却将首元素地址写在了[ ]里面。这里可以得到一个结论:无论是i[arr]还是arr[i],其本质都是*(arr+i),这说明其实[ ]就仅仅只是一个操作符,可以理解成数组中一个特殊的解引用操作符,下标的多少本质其实就是相对于首元素地址的指针偏移量的多少。
5.运行结果第五行:通过3和4,第五行就很好理解了,i[p]的本质是*(i+p),所以一样可以得到打印的结果,再一次证实了4中的结论。
通过分析这个运行结果,我们知道了访问数组元素的几种书写形式,以及访问数组的一些底层逻辑,那么我们在书写时就有多种选择,我们还是要按照便于他人理解的角度去写代码,但是无论形式是如何的,本质上是要理解指针的逻辑,才能一通百通。
三、一维数组的传参本质
void test(int arr[]){int sz2 = sizeof(arr) / sizeof(arr[0]);printf("sz2=%d\n", sz2);}int main(){int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };int sz1 = sizeof(arr) / sizeof(arr[0]);printf("sz1=%d\n", sz1);test(arr);return 0;}
sz1=10
sz2=2
分析上面这段代码,我们发现在main函数内部计算sz1,得到的是10,在main函数外得到的sz2得到的结果是2,这说明在test函数中没有得到正确的元素个数,原因就是:数组名是数组的首元素地址,那么数据在传参的时候传递的是数组名,也就是说本质上数组传参传递的是数组首元素的地址。sz2是怎么得到的呢?我发现在x64环境下sz2等于2,而在x86环境下sz2=1,这说明传入的arr虽然是首元素的地址,其本质是一个指针,大小是一个指针的大小,而指针取决于操作平台,x64是8个字节,x86是4个字节。
所以正因为sizeof(arr)需要计算的是整个数组的大小,而函数内部计算的是一个地址的大小而不是整个数组的大小,正是因为函数的参数部分本质是指针,所以无法在函数内部求数组元素的个数。
我们其实知道这个元素的个数是10个,却还要通过sz来接受sizeof(arr)/sizeof(arr[0]),原因就是为了方便代码的修改,比方说把元素个数从10个改变成100个,只需要在创建数组的那行代码进行修改,其他的地方就不需要修改,比较快捷。
既然数组传参传递的是一个地址(指针),那么根据之前学的swap函数交换,我们可以类比出,其实数组传参是一种特殊的值传递,他可以通过访问地址来修改原数组的实际值。
数组传参的过程中发生了“降维”,“降维”的意思就是本该传入整个数组,却只传递了数组首元素的地址,其实这是为了避免拷贝完整数据带来的低效率,因为我们知道,调用函数时形参会创建一份临时空间来接收实参的数据,如果传递的是整个数组,会使得程序运行效率很低,这是作为一个程序员应当考虑的问题,而其实我们访问数组只需要知道首元素地址、数组的数据类型、地址偏移量就可以去访问所有元素了,所以这里数组的“降维”,对应程序的运行来说是高效的。
另外:参数中的[ ]内可以省略数组具体大小的原因是,实际传参为数组首元素的指针,与数组实际大小并无关,因此此处[]内写了跟没写没有区别,只要不要写<=0的数即可。
(int arr[ ]本质是int *arr)
四、冒泡排序
问题:写一个函数,对一个整型数组进行升序排列。
思想:相邻元素比较,不满足就交换。

通过图我们可以知道,从第一个元素开始不断与后面元素做比较,一旦大于最后一个函数就交换,经过一趟冒泡排序后,最大的数字9就来到了数组的最后位置,这时候在进行第二次找到8……最后可以得到我们想要的升序数组,如果sz代表数组的元素个数,那么我们要考虑一次冒泡排序需要进行几次比较,一共需要进行几次冒泡排序。
第一个元素与后面每一个元素比较,一共需要sz-1次,完成一次冒泡排序。而由于第一次冒泡排序已经将数组中最大的元素放在最后了,所以第二次冒泡排序只需要比较sz-2次,以此类推,所以需要比较sz-1-i次,每一次冒泡排序可以找到一个最大的数放后面,那么只需要进行sz-1次冒泡排序,就可以完成该升序序列。所以我们可以写出下面的代码。
int count = 0;void bubble_sort(int arr[], int sz)//实现冒泡排序函数{for (int i = 0; i < sz - 1; i++)//需要进行多少次冒泡排序{for (int j = 0; j < sz - i - 1; j++)//一次冒泡排序需要比较多少次{count++;if (arr[j] > arr[j + 1]){int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}void prinf(int arr[], int sz){for (int i = 0; i < sz; i++)printf("%d ", *(arr + i));}int main(){int arr[] = { 9,0,1,2,3,4,5,6,7,8 };int sz = sizeof(arr) / sizeof(arr[0]);bubble_sort(arr, sz);prinf(arr, sz);printf("\ncount=%d", count);return 0;}
0 1 2 3 4 5 6 7 8 9
count=45
count代表的是完成这次升序一共进行了多少次比较,上述代码有一个缺陷就是,无论数组是怎样的,count都是一样的,但其实有些时候并不一定需要进行sz-1次的冒泡排序,极端一点比如说这个数组本身就是升序的数组,那么其实就没有必要进行冒泡排序,所以我们每做完一次冒泡排序后要去判断是否已经是升序序列,如果是的话就不需要进行后面的冒泡排序了,所以我们需要去考虑这种情况做一个优化,以此来减少程序运行的时间,保证高效。
int count = 0;void bubble_sort(int arr[], int sz)//实现冒泡排序函数{for (int i = 0; i < sz-1; i++)//需要进行多少次冒泡排序{int flag = 1;//假设有序for (int j = 0; j < sz - i - 1; j++)//一次冒泡排序需要比较多少次{count++;if (arr[j] > arr[j + 1]){flag = 0;//发生交换就说明无序int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}if (flag ==1)//说明已经有序break;}}void prinf(int arr[], int sz){for (int i = 0; i < sz; i++)printf("%d ", *(arr + i));}int main(){int arr[] = {9,0,1,2,3,4,5,6,7,8};int sz = sizeof(arr) / sizeof(arr[0]);bubble_sort(arr, sz);prinf(arr, sz);printf("\ncount=%d", count);return 0;}
0 1 2 3 4 5 6 7 8 9
count=17
五、二级指针
指针变量也是变量,是变量就有自己的地址,那么我们如何储存指针变量的地址呢?
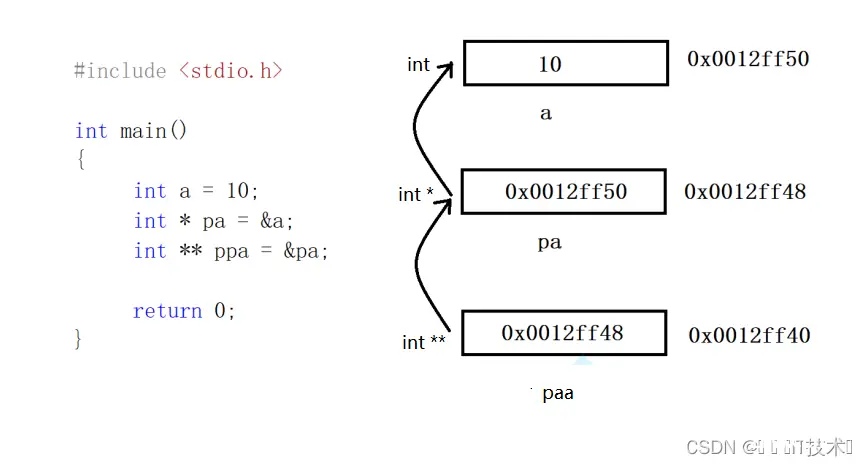
我们知道int *pa=&a;*说明pa是一个指针变量,而int说明pa指向对象的数据类型a是一个整型变量,故int **ppa=&pa;*说明pa是一个指针变量,而int*说明pa指向对象的数据类型pa是一个指针变量我们把ppa称之为二级指针,同样可以根据这个方法推出三级指针的写法int ***pppa=&ppa,但实际应用时很少用到三级指针。同时该图还可以说明:指针变量(一级指针)也是变量,有自己的地址,只不过时用来存放地址的,二级指针也同样时变量,只不过时用来存放一级指针的地址。
一级指针解引用,因为int*pa=&a,所以*pa找到的是a。
二级指针解引用,因为int **ppa=&pa,所以*ppa找到的是pa,**ppa找到的是a。
六、指针数组模拟二维数组
指针数组,就是存放指针的数组。

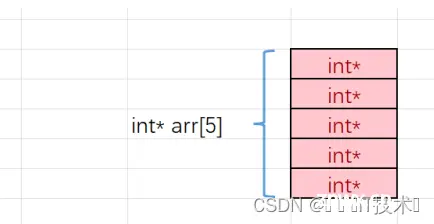
指针数组的每个元素是用来存放地址的,并且指针数组的每个元素也是地址,又可以指向一个区域。
int main(){int arr1[] = { 1,2,3,4,5 };int arr2[] = { 2,3,4,5,6 };int arr3[] = { 3,4,5,6,7 };//数组名是数组?元素的地址,类型是int*的,就可以存放在parr数组中int* parr[3] = {arr1,arr2,arr3};//整型指针数组int i = 0;int j = 0;for (i = 0; i < 3; i++)//当i=0,相当于拿到arr1的首元素地址,接下去访问的是arr1的数组{for (j = 0; j < 5; j++)//访问改行对应的元素{printf("%d ", parr[i][j]);//parr[i][j]=*(*(parr+i)+j)}printf("\n");}return 0;}
1 2 3 4 5
2 3 4 5 6
3 4 5 6 7

二维数组的每一行是一个一维数组。
parr[i]是访问parr数组的元素,parr[i]找到的数组元素指向了整型⼀维数组,parr[i][j]就是整型⼀维数 组中的元素。([实际上就是一个特殊的解引用操作符,parr[i][j]其实就是*(*(parr+i)+j)
上述的代码模拟出⼆维数组的效果,实际上并⾮完全是⼆维数组,因为每⼀⾏并⾮是连续的。
七、sizeof和strlen的对比
7.1 sizeof
izeof的作用是计算对应变量所占内存空间的大小,如果操作数是类型的话,计算的是使用该类型创建的变量所占内存空间的大小。
sizeof只关心占用内存空间的大小,不在乎内存中存放了什么数据。
int main(){int a = 10;printf("%zd\n", sizeof(a));printf("%zd\n", sizeof(int));printf("%zd\n", sizeof a );//printf("%zd\n", sizeof int);}
4 4 4
通过这段代码可以发现,当创建了一个int类型的变量a时,我们要用sizeof去计算a所占空间大小,可以有三种形式 sizeof(变量)、sizeof(数据类型)、sizeof 变量。但 sizeof 数据类型是不行的。(sizeof类型的占位符是zd%)
注意事项:
sizeof 后边的表达式是不真实参与运算的,根据表达式的类型来得出大小!
#include <stdio.h>int main(){ short s = 2; int b = 10; printf("%d\n", sizeof(s = b+1)); printf("s = %d\n", s); return 0;}
2 2 s=b+1并没有计算
sizeof 在代码进⾏编译的时候,就根据表达式的类型确定了,类型的常⽤,⽽表达式的执⾏却要在程序运⾏期间才能执⾏,在编译期间已经将sizeof处理掉了,所以在运⾏期间就不会执⾏表达式了。
sizeof 的计算结果是 size_t 类型的。
sizeof 运算符的返回值,C 语言只规定是无符号整数,并没有规定具体的类型,而是留给系统自己去决定, sizeof 到底返回什么类型。不同的系统中,返回值的类型有可能是 unsigned int ,也有可能是 unsigned long ,甚⾄是 unsigned long long , 对应的 printf( ) 占位符分别是 %u 、 %lu 和 %llu 。这样不利于程序的可移植性。 C 语⾔提供了⼀个解决⽅法,创造了⼀个类型别名 size_t ,⽤来统⼀表⽰ sizeof 的返回值类型。对应当前系统的 sizeof 的返回值类型,可能是 unsigned int ,也可能是 unsigned long long 。
7.2 strlen
strlen是C语言的库函数,头文件是<string.h>,功能是求字符串的长度。

strlen的参数类型是char*,str代表的就是该字符串的首元素地址,求字符串长度的方法是从参数str中的这个地址开始往后,统计\0之前字符的个数(字符串的最后都有\0),他会一直向后找\0字符,直到找到为止,因此可能会出现越界访问。
int main(){char arr[] = "abcdefg";printf("%d", strlen(arr));}
7
7.3 sizeof和strlen的对比
int main()//sizeof和strlen的使用对比。{char arr1[3] = { 'a','b','c' };char arr2[] = "abc";char arr3[20] = "abcdef";char arr4[6] = "abcdef";printf("sizeof(arr1)=%zd", sizeof(arr1));printf("\tstrlen(arr1)=%d\n", strlen(arr1));printf("sizeof(arr2)=%zd", sizeof(arr2));printf("\tstrlen(arr2)=%d\n", strlen(arr2));printf("sizeof(arr3)=%zd", sizeof(arr3));printf("\tstrlen(arr3)=%d\n", strlen(arr3));printf("sizeof(arr4)=%zd", sizeof(arr4));printf("\tstrlen(arr4)=%d\n", strlen(arr4)); }
sizeof(arr1)=3 strlen(arr1)=35
sizeof(arr2)=4 strlen(arr2)=3
sizeof(arr3)=20 strlen(arr3)=6
sizeof(arr4)=6 strlen(arr4)=33
为了能够理清使用sizeof和strlen的一些注意事项,我创建了如图的四个数组进行分析。
数组1:sizeof(arr1)=3,很好理解,但是为什么strlen(arr1)=35呢?因为strlen的运行逻辑是统计\0前的字符个数,而arr1并没有\0,出现了越界访问,所以算出来是一个随机数。
数组2:sizeof(arr2)=4,是因为arr2里存放的是一个字符串,而字符串本身是隐藏着一个\0的,sizeof并不关心存储了什么数据。strlen(arr2)=3,很好理解。
数组3:sizeof(arr3)=20,因为arr3有20个元素,很好理解,而strlen(arr3)=6,是因为数组里面存放的是一个字符串,strlen同样只会访问到\0就停止。
数组4:sizeof(arr4)=6,根据数组2的结论,sizeof也会计算字符串中的\0,但是为什么不是7呢?因为创建该数组的时候标明了只能存放6个元素,实际上这个数组是存放不下这个字符串的,所以实际大小也只有6,为什么strlen(arr4)=33呢,因为这个数组只能存放6个元素,而abcdef已经占用了6个位置了,所以\0并没有存放进去,因此strlen找不到\0,出现了越界访问,得到的是随机值。所以我们平时给数组赋值的时候一定要注意该数组能否存放得下!
接下来我们可以对sizeof和strlen进行一个全面得总结
sizeof:
1.sizeof是操作符
2.sizeof计算操作数所占内存空间的大小,单位是字节
3.sizeof并不关心存放了什么数据。
4.sizeof 后边的表达式是不真实参与运算的,根据表达式的类型来得出大小!
strlen:
1.strlen是一个库函数,头文件是string.h
2.strlen统计的是\0前面的元素个数,所以一般只适用于字符串,因为字符串的结尾隐藏着一个\0
3.strlen的使用过程中一定要关注是否有\0,如果没有,就很可能出现越界访问,此时会得到一个随机值。
注意事项:在给数组的元素赋值的时候一定要确保该数组能够存放的下这些数据!!

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。