【进阶篇】Java 项目中对使用递归的理解分享
cnblogs 2024-07-02 08:39:00 阅读 95
笔者在最近的项目开发中,遇到了两个父子关系紧密相关的场景:评论树结构、部门树结构。具体的需求如:找出某条评论下的所有子评论id集合,找出某个部门下所有的子部门id集合。
【进阶篇】Java 项目中对使用递归的理解分享
目录
- 【进阶篇】Java 项目中对使用递归的理解分享
- 前言
- 一、什么是递归
- 1.1基本概念
- 1.2优缺点
- 1.3与迭代的区别
- 二、实际案例
- 三、改进方案
- 3.1控制递归层数
- 3.1用 Stream 遍历
- 四、文章小结
前言
笔者在最近的项目开发中,遇到了两个父子关系紧密相关的场景:评论树结构、部门树结构。具体的需求如:找出某条评论下的所有子评论id集合,找出某个部门下所有的子部门id集合。
在之前的项目开发经验中,递归使用得是较少的,但作为一个在数据结构操作中遍历树节点的解决方案,我还是拿出来作为技术积累进行记录以及分享。
一、什么是递归
1.1基本概念
这里就有必要简单介绍一下关于递归的基本概念了。
在 Java 中,递归是指在方法的定义中调用自身的过程,递归是基于方法调用栈的原理实现的:当一个方法被调用时,会在调用栈中创建一个对应的栈帧,包含方法的参数、局部变量和返回地址等信息。在递归中,方法会在自身的定义中调用自身,这会导致多个相同方法的栈帧依次入栈。当满足终止条件时,递归开始回溯,栈帧依次出栈,方法得以执行完毕。
递归的关键是定义好递归的终止条件和递归调用的条件。如果没有适当的终止条件或递归调用的条件不满足,递归可能会陷入无限循环,导致栈内存溢出。
1.2优缺点
优点:
- 简化问题:递归能够将复杂问题分解成更小规模的子问题,简化了问题的解决过程;
- 实现高效算法:递归在某些算法中能够实现高效的解决方法,如数据结构操作中遍历树节点等。
缺点:
- 栈溢出风险:递归可能导致方法调用栈过深,造成栈内存溢出;
- 性能损耗:递归调用需要创建多个栈帧,对系统资源有一定的消耗;
- 可读性不高:递归的使用需要谨慎,不合理地使用可能造成代码难以理解和调试。
1.3与迭代的区别
迭代(Iteration)
迭代常见于 for 循环中:比如有一个集合 A,对 A 进行 foreach,在内部设置条件,符合条件后将集合中某个元素的值替换成别的值。
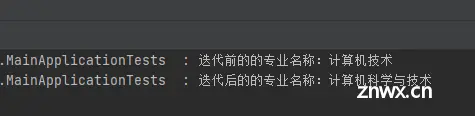
@Test
public void iterationTest(){
ArrayList<String> list = new ArrayList<>();
list.add("计算机技术");
list.add("土木工程");
list.add("市场营销");
list.forEach(val -> {
if (val.contains("计算机")){
log.info("迭代前的的专业名称:{}", val);
String str = val.replace(val, "计算机科学与技术");
log.info("迭代后的的专业名称:{}", str);
}
});
}
结果为:
递归(Recursion)
递归的例子会在下一小节详细给出。
二、实际案例
下面笔者以递归获取某个评论id下面所有的子级评论id为例子,向大家介绍这个递归的过程。
首先,这里给出一个简单的数据库评论表的 demo,id 是主键id 也是评论唯一 id,parent_id 是该条评论的父评论 id,status 为1表示审核通过的状态。
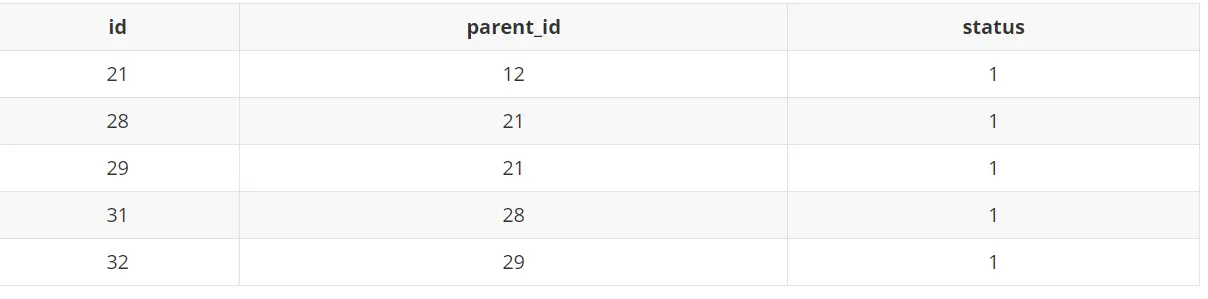
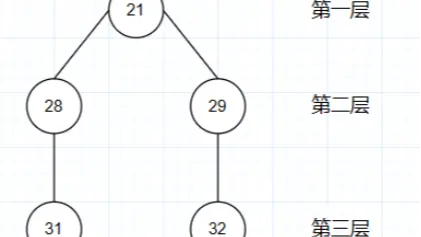
其中,我们可以简单发现:这里21为第一层,28和29为第二层、31和32为第三层,草图如下所示:
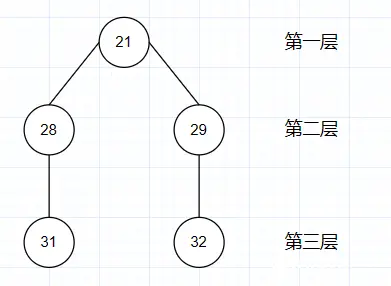
那么,我们如何将21、28、29、31、32都放进一个集合里返回呢?下面的代码示例可以给你一个参考。
但是,在看代码之前,有个问题请你思考一下:
从21开始后,遍历的路线是21-28-29?还是21-28-31?还是21-29-32?或者是21-28-31-29-32?
下面是经过脱敏处理后的参看代码示例,注释都写得比较清楚了:
/**
* 这里可以看作是外部接口的调用,会得到递归的结果
* @param id
*/
private List<Integer> getIdListMethod(Integer id){
ArrayList<Integer> idList = new ArrayList<>();
this.getAllIdByRecursion(id, idList);
log.info("递归后得到的id集合:{}", idList);
return idList;
}
/**
* 这里是递归的过程
* @param id
* @param idList
*/
private void getAllIdByRecursion(Integer id, List<Integer> idList){
LambdaQueryWrapper<Comment> wrapper = new LambdaQueryWrapper<>();
//先把该id下所有的第一级子id找到
wrapper.eq(Comment::getParentId, id).eq(Comment::getStatus, NumberUtils.INTEGER_ONE);
List<Comment> commentList = this.list(wrapper);
for (Comment children : commentList){
this.getAllIdByRecursion(children.getId(), idList);
}
log.info("放入集合的id为:{}", id);
idList.add(id);
}
上面问题的答案是:递归后得到的id集合:[21,28,31,29,32],原因就是:迭代会从一棵树开始遍历到底,没有元素了再从头开始遍历,依次迭代,类似于深度优先遍历。
比如:21下面有两个子id:28和29,那么会先走21-28-31这棵树,到底了后接着按照29-32遍历。
三、改进方案
我根据自己的开发经验,可以从控制递归层数和改用 Stream 这两种办法来对递归进行改进。
3.1控制递归层数
JVM 默认控制的递归最大深度限制在 1000 层,可以通过设置 JVM 参数来控制其深度,如:
java -Xss5m #表示将每个线程的栈内存大小设置为5MB,已经是比较大了
或者在代码层面对递归的层数进行控制:
int depth = 0;
//递归方法调用
for (int i = 0; i < 20; i++) {
depth++;
}
if (depth > 100){
//其它操作
}
3.1用 Stream 遍历
核心思路是:先数据库全量查询(10万条以内),内存中使用 Stream 流操作、Lambda 表达式、Java 地址引用进行筛选。
适用于数据总量不多的情况,如:部门树,部门数量一般情况是比较固定的,一个组织或者公司最多也就几百上千个部门。
详情可以看我这篇文章:https://www.cnblogs.com/CodeBlogMan/p/17965824
四、文章小结
笔者确实不推荐在项目中过度使用递归,但是合理使用的话也能成为解决特定问题的一个利器,至于怎么拿捏这个度,那就要看大家的具体情况了。
Java 项目中对使用递归的理解分享到这里就结束了,文章如有不足和错误,或者你有更好的解决思路,欢迎大家的指正和交流!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。