分享Python7个爬虫小案例(附源码)
艾派森 2024-06-28 08:05:03 阅读 86
本次的7个python爬虫小案例涉及到了re正则、xpath、beautiful soup、selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习。注:若涉及到版权或隐私问题,请及时联系我删除即可。
1.使用正则表达式和文件操作爬取并保存“某吧”某帖子全部内容(该帖不少于5页。
本次选取的是某吧中的NBA吧中的一篇帖子,帖子标题是“克莱和哈登,谁历史地位更高”。爬取的目标是帖子里面的回复内容。
源程序和关键结果截图:
import csv
import requests
import re
import time
def main(page):
url = f'https://tieba.baidu.com/p/7882177660?pn={page}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
}
resp = requests.get(url,headers=headers)
html = resp.text
# 评论内容
comments = re.findall('style="display:;"> (.*?)</div>',html)
# 评论用户
users = re.findall('class="p_author_name j_user_card" href=".*?" target="_blank">(.*?)</a>',html)
# 评论时间
comment_times = re.findall('楼</span><span class="tail-info">(.*?)</span><div',html)
for u,c,t in zip(users,comments,comment_times):
# 筛选数据,过滤掉异常数据
if 'img' in c or 'div' in c or len(u)>50:
continue
csvwriter.writerow((u,t,c))
print(u,t,c)
print(f'第{page}页爬取完毕')
if __name__ == '__main__':
with open('01.csv','a',encoding='utf-8')as f:
csvwriter = csv.writer(f)
csvwriter.writerow(('评论用户','评论时间','评论内容'))
for page in range(1,8): # 爬取前7页的内容
main(page)
time.sleep(2)

2.实现多线程爬虫爬取某小说部分章节内容并以数据库存储(不少于10个章节。
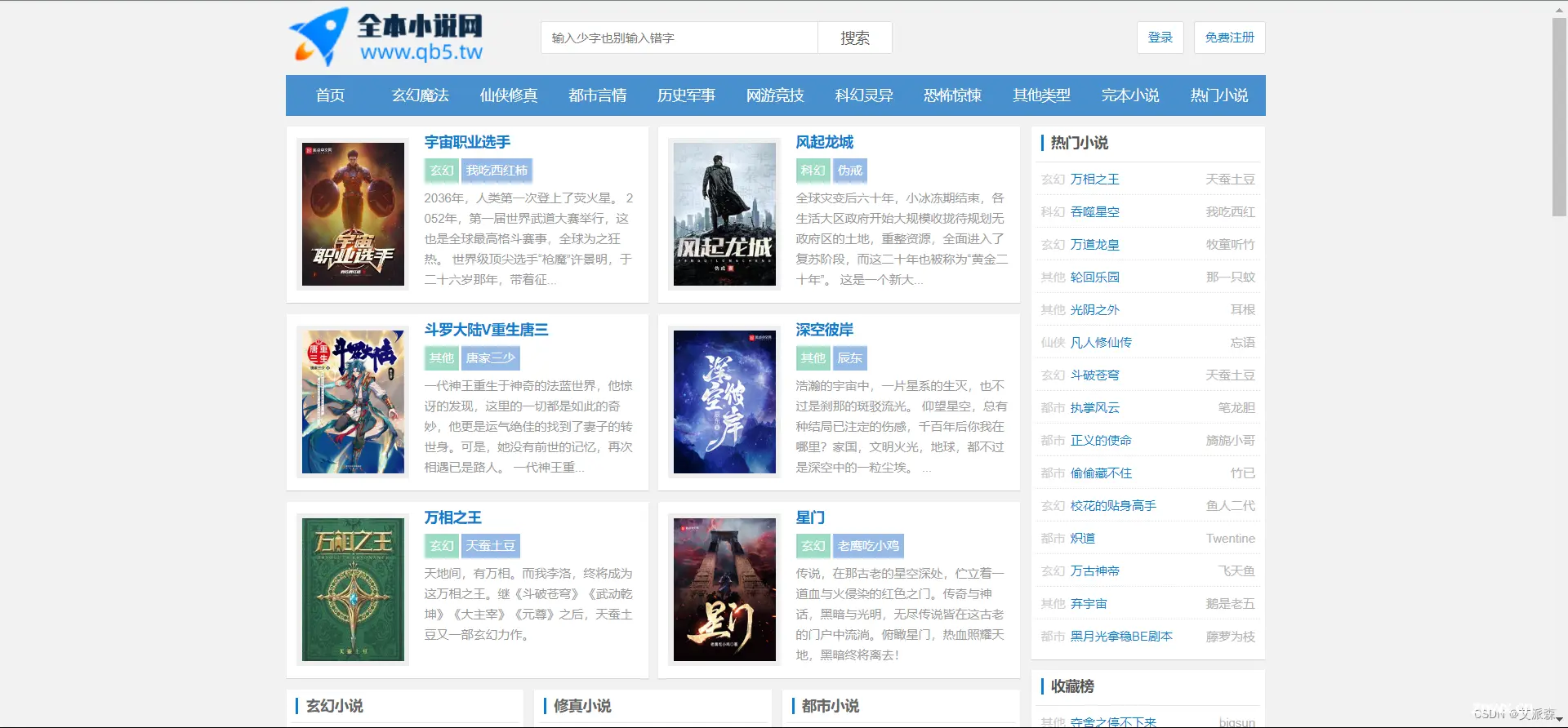
本次选取的小说网址是某小说网,这里我们选取第一篇小说进行爬取
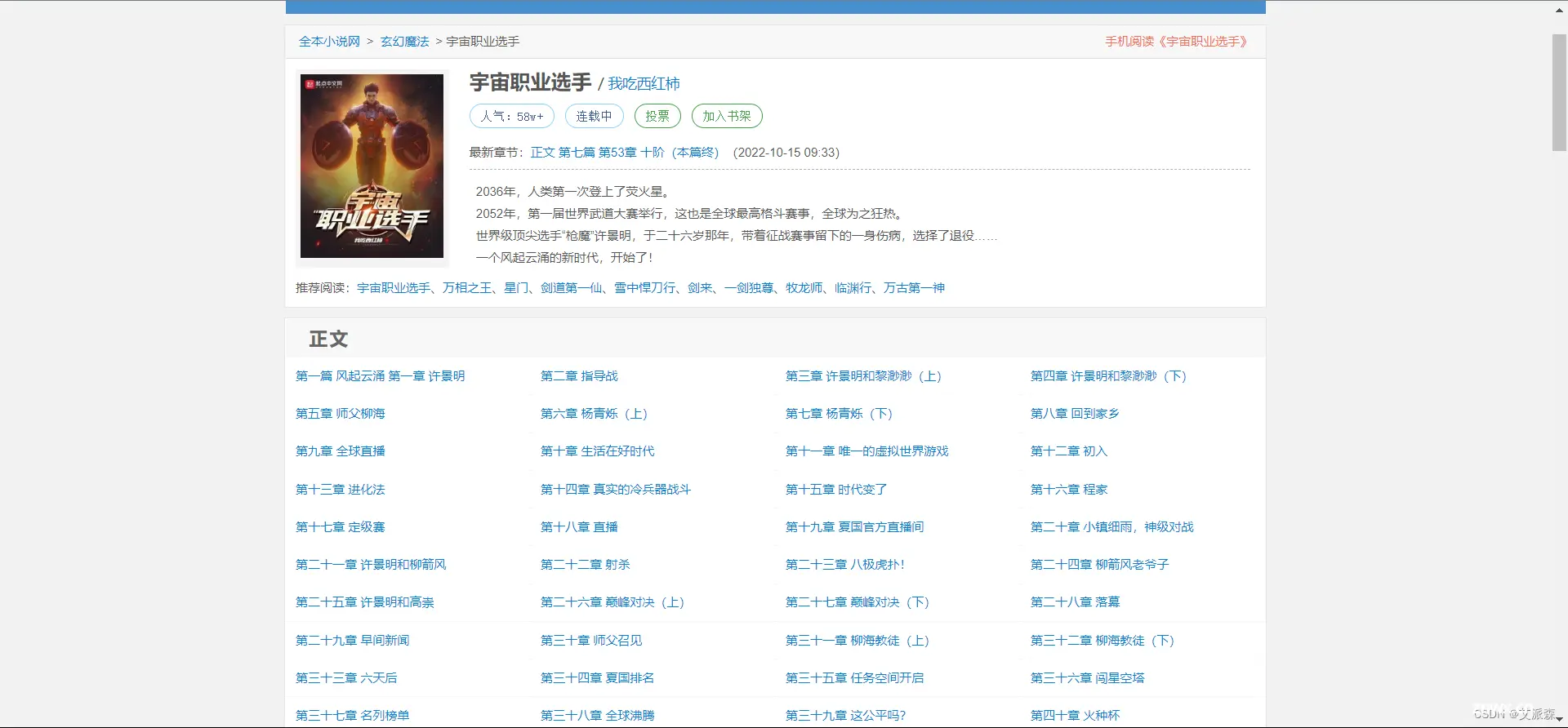
然后通过分析网页源代码分析每章小说的链接

找到链接的位置后,我们使用Xpath来进行链接和每一章标题的提取

在这里,因为涉及到多次使用requests发送请求,所以这里我们把它封装成一个函数,便于后面的使用

每一章的链接获取后,我们开始进入小说章节内容页面进行分析

通过网页分析,小说内容都在网页源代码中,属于静态数据

这里我们选用re正则表达式进行数据提取,并对最后的结果进行清洗

然后我们需要将数据保存到数据库中,这里我将爬取的数据存储到mysql数据库中,先封住一下数据库的操作

接着将爬取到是数据进行保存
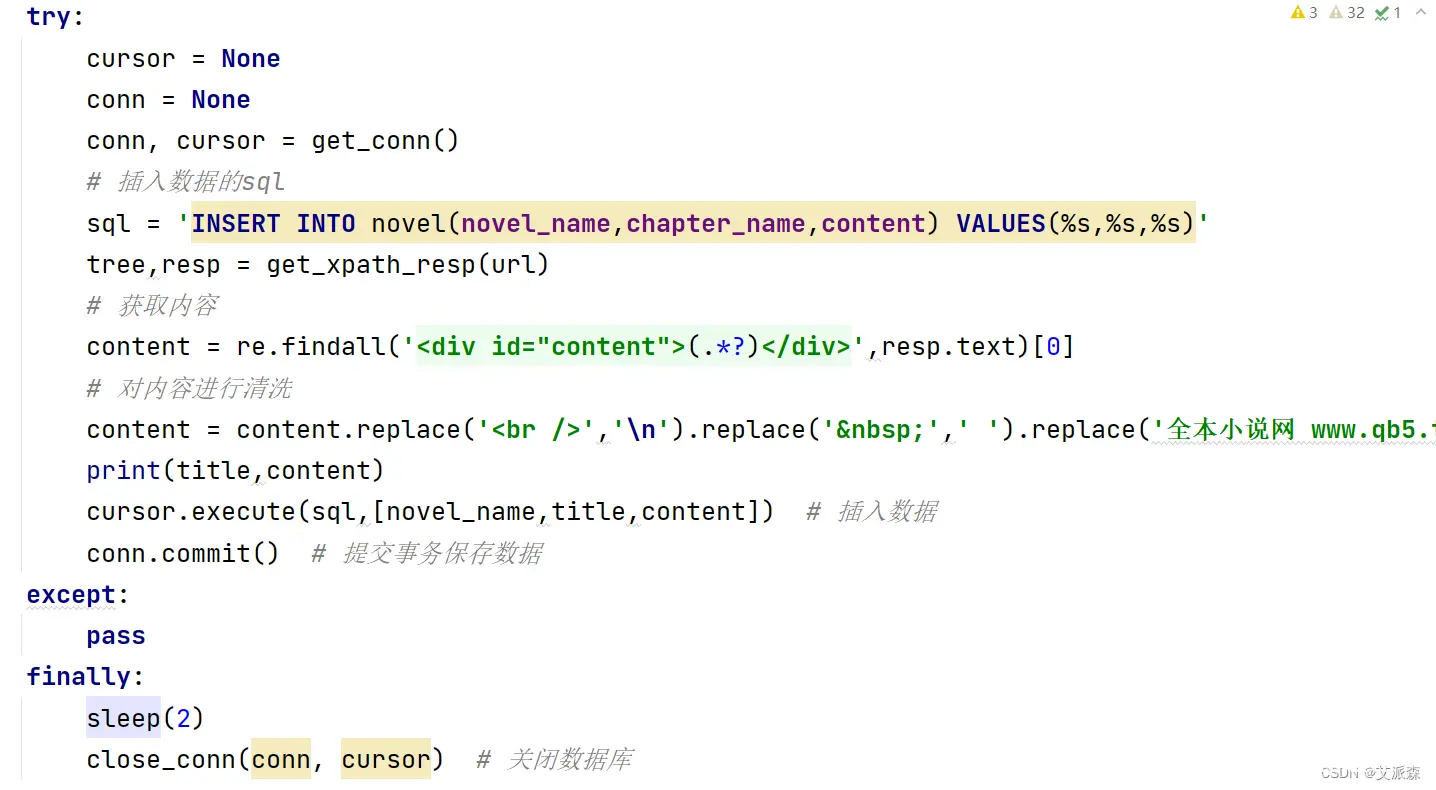
最后一步就是使用多线程来提高爬虫效率,这里我们创建了5个线程的线程池

源代码及结果截图:
import requests
from lxml import etree
import re
import pymysql
from time import sleep
from concurrent.futures import ThreadPoolExecutor
def get_conn():
# 创建连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="root",
db="novels",
charset="utf8")
# 创建游标
cursor = conn.cursor()
return conn, cursor
def close_conn(conn, cursor):
cursor.close()
conn.close()
def get_xpath_resp(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
resp = requests.get(url, headers=headers)
tree = etree.HTML(resp.text) # 用etree解析html
return tree,resp
def get_chapters(url):
tree,_ = get_xpath_resp(url)
# 获取小说名字
novel_name = tree.xpath('//*[@id="info"]/h1/text()')[0]
# 获取小说数据节点
dds = tree.xpath('/html/body/div[4]/dl/dd')
title_list = []
link_list = []
for d in dds[:15]:
title = d.xpath('./a/text()')[0] # 章节标题
title_list.append(title)
link = d.xpath('./a/@href')[0] # 章节链接
chapter_url = url +link # 构造完整链接
link_list.append(chapter_url)
return title_list,link_list,novel_name
def get_content(novel_name,title,url):
try:
cursor = None
conn = None
conn, cursor = get_conn()
# 插入数据的sql
sql = 'INSERT INTO novel(novel_name,chapter_name,content) VALUES(%s,%s,%s)'
tree,resp = get_xpath_resp(url)
# 获取内容
content = re.findall('<div id="content">(.*?)</div>',resp.text)[0]
# 对内容进行清洗
content = content.replace('<br />','\n').replace(' ',' ').replace('全本小说网 www.qb5.tw,最快更新<a href="https://www.qb5.tw/book_116659/">宇宙职业选手</a>最新章节!<br><br>','')
print(title,content)
cursor.execute(sql,[novel_name,title,content]) # 插入数据
conn.commit() # 提交事务保存数据
except:
pass
finally:
sleep(2)
close_conn(conn, cursor) # 关闭数据库
if __name__ == '__main__':
# 获取小说名字,标题链接,章节名称
title_list, link_list, novel_name = get_chapters('https://www.qb5.tw/book_116659/')
with ThreadPoolExecutor(5) as t: # 创建5个线程
for title,link in zip(title_list,link_list):
t.submit(get_content, novel_name,title,link) # 启动线程


3. 分别使用XPath和Beautiful Soup4两种方式爬取并保存非异步加载的“某瓣某排行榜”如https://movie.douban.com/top250的名称、描述、评分和评价人数等数据。
先分析:
首先,来到某瓣Top250页面,首先使用Xpath版本的来抓取数据,先分析下电影列表页的数据结构,发下都在网页源代码中,属于静态数据

接着我们找到数据的规律,使用xpath提取每一个电影的链接及电影名

然后根据链接进入到其详情页
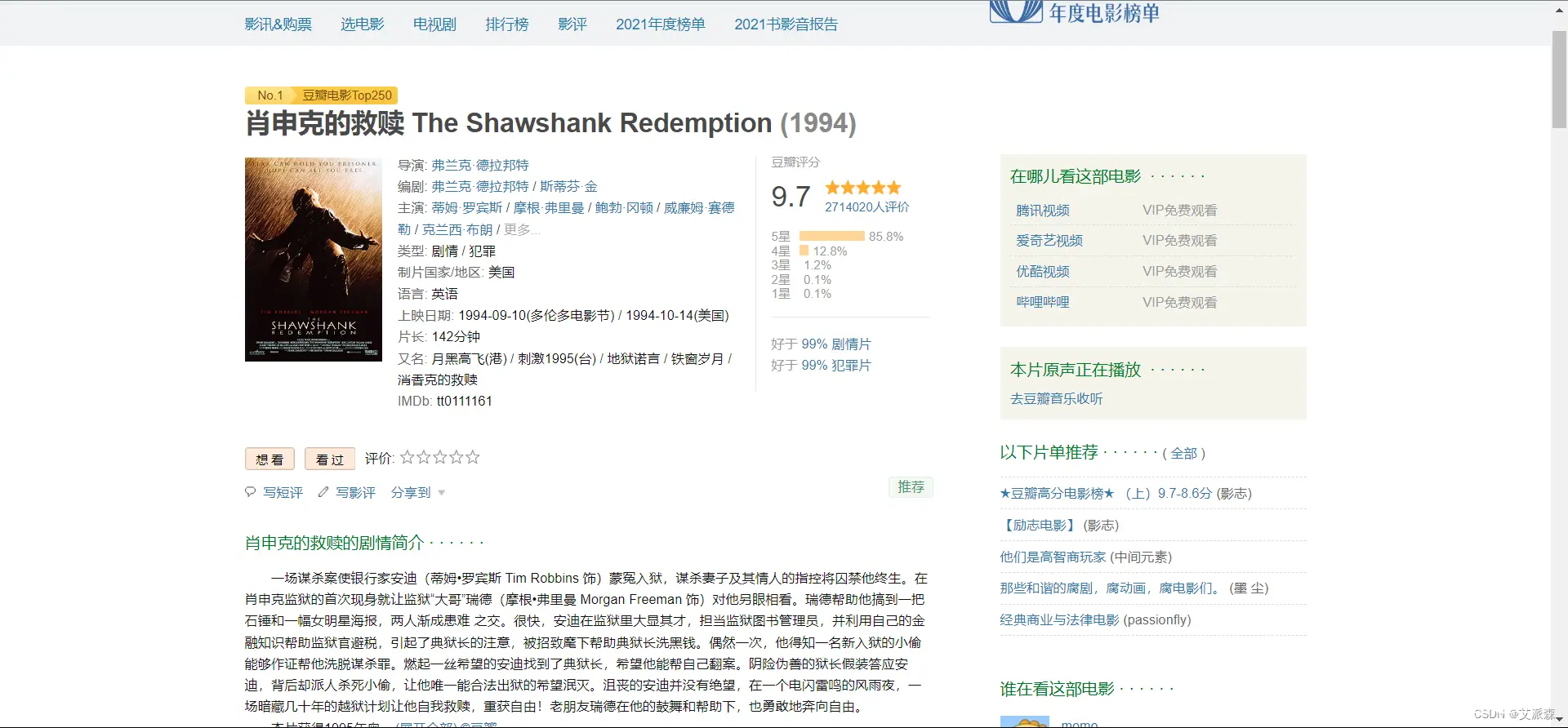
分析详情页的数据,发现也是静态数据,继续使用xpath提取数据

最后我们将爬取的数据进行存储,这里用csv文件进行存储

接着是Beautiful Soup4版的,在这里,我们直接在电影列表页使用bs4中的etree进行数据提取

最后,同样使用csv文件进行数据存储
源代码即结果截图:
XPath版:
import re
from time import sleep
import requests
from lxml import etree
import random
import csv
def main(page,f):
url = f'https://movie.douban.com/top250?start={page*25}&filter='
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',}
resp = requests.get(url,headers=headers)
tree = etree.HTML(resp.text)
# 获取详情页的链接列表
href_list = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[1]/a/@href')
# 获取电影名称列表
name_list = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
for url,name in zip(href_list,name_list):
f.flush() # 刷新文件
try:
get_info(url,name) # 获取详情页的信息
except:
pass
sleep(1 + random.random()) # 休息
print(f'第{i+1}页爬取完毕')
def get_info(url,name):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',
'Host': 'movie.douban.com',
}
resp = requests.get(url,headers=headers)
html = resp.text
tree = etree.HTML(html)
# 导演
dir = tree.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')[0]
# 电影类型
type_ = re.findall(r'property="v:genre">(.*?)</span>',html)
type_ = '/'.join(type_)
# 国家
country = re.findall(r'地区:</span> (.*?)<br',html)[0]
# 上映时间
time = tree.xpath('//*[@id="content"]/h1/span[2]/text()')[0]
time = time[1:5]
# 评分
rate = tree.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0]
# 评论人数
people = tree.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/div/div[2]/a/span/text()')[0]
print(name,dir,type_,country,time,rate,people) # 打印结果
csvwriter.writerow((name,dir,type_,country,time,rate,people)) # 保存到文件中
if __name__ == '__main__':
# 创建文件用于保存数据
with open('03-movie-xpath.csv','a',encoding='utf-8',newline='')as f:
csvwriter = csv.writer(f)
# 写入表头标题
csvwriter.writerow(('电影名称','导演','电影类型','国家','上映年份','评分','评论人数'))
for i in range(10): # 爬取10页
main(i,f) # 调用主函数
sleep(3 + random.random())

Beautiful Soup4版:
import random
import urllib.request
from bs4 import BeautifulSoup
import codecs
from time import sleep
def main(url, headers):
# 发送请求
page = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(page)
contents = page.read()
# 用BeautifulSoup解析网页
soup = BeautifulSoup(contents, "html.parser")
infofile.write("")
print('爬取豆瓣电影250: \n')
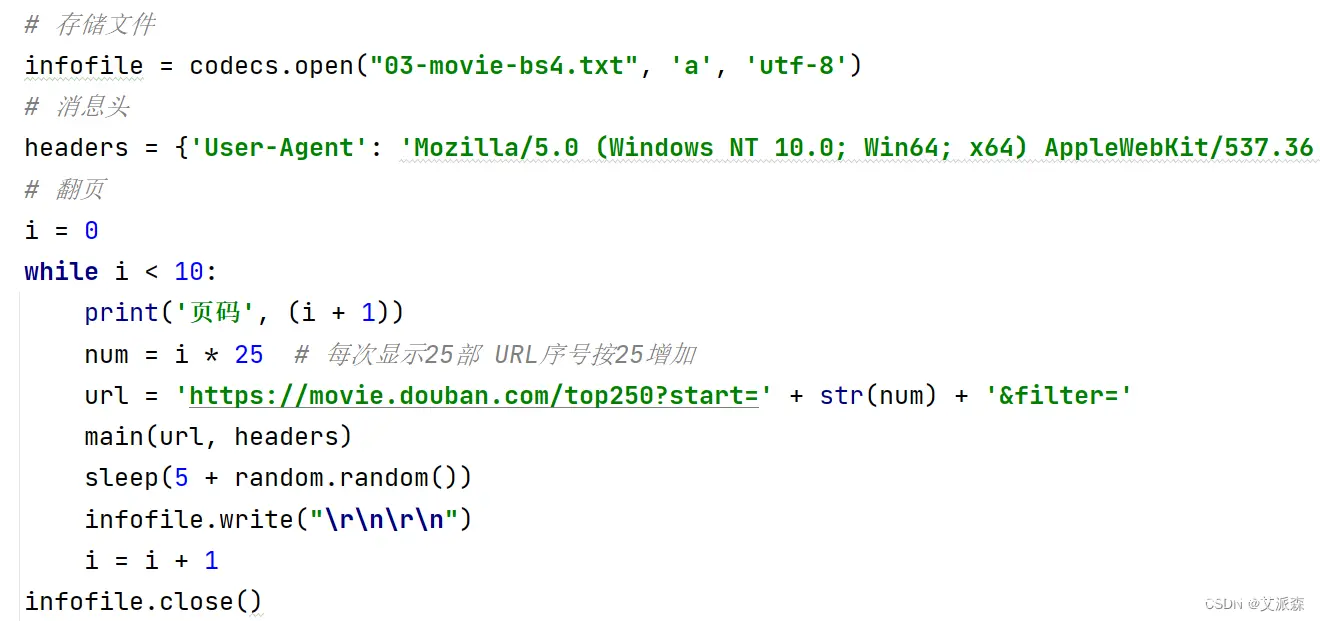
for tag in soup.find_all(attrs={"class": "item"}):
# 爬取序号
num = tag.find('em').get_text()
print(num)
infofile.write(num + "\r\n")
# 电影名称
name = tag.find_all(attrs={"class": "title"})
zwname = name[0].get_text()
print('[中文名称]', zwname)
infofile.write("[中文名称]" + zwname + "\r\n")
# 网页链接
url_movie = tag.find(attrs={"class": "hd"}).a
urls = url_movie.attrs['href']
print('[网页链接]', urls)
infofile.write("[网页链接]" + urls + "\r\n")
# 爬取评分和评论数
info = tag.find(attrs={"class": "star"}).get_text()
info = info.replace('\n', ' ')
info = info.lstrip()
print('[评分评论]', info)
# 获取评语
info = tag.find(attrs={"class": "inq"})
if (info): # 避免没有影评调用get_text()报错
content = info.get_text()
print('[影评]', content)
infofile.write(u"[影评]" + content + "\r\n")
print('')
if __name__ == '__main__':
# 存储文件
infofile = codecs.open("03-movie-bs4.txt", 'a', 'utf-8')
# 消息头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
# 翻页
i = 0
while i < 10:
print('页码', (i + 1))
num = i * 25 # 每次显示25部 URL序号按25增加
url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
main(url, headers)
sleep(5 + random.random())
infofile.write("\r\n\r\n")
i = i + 1
infofile.close()

4.实现某东商城某商品评论数据的爬取(评论数据不少于100条,包括评论内容、时间和评分)。
先分析:
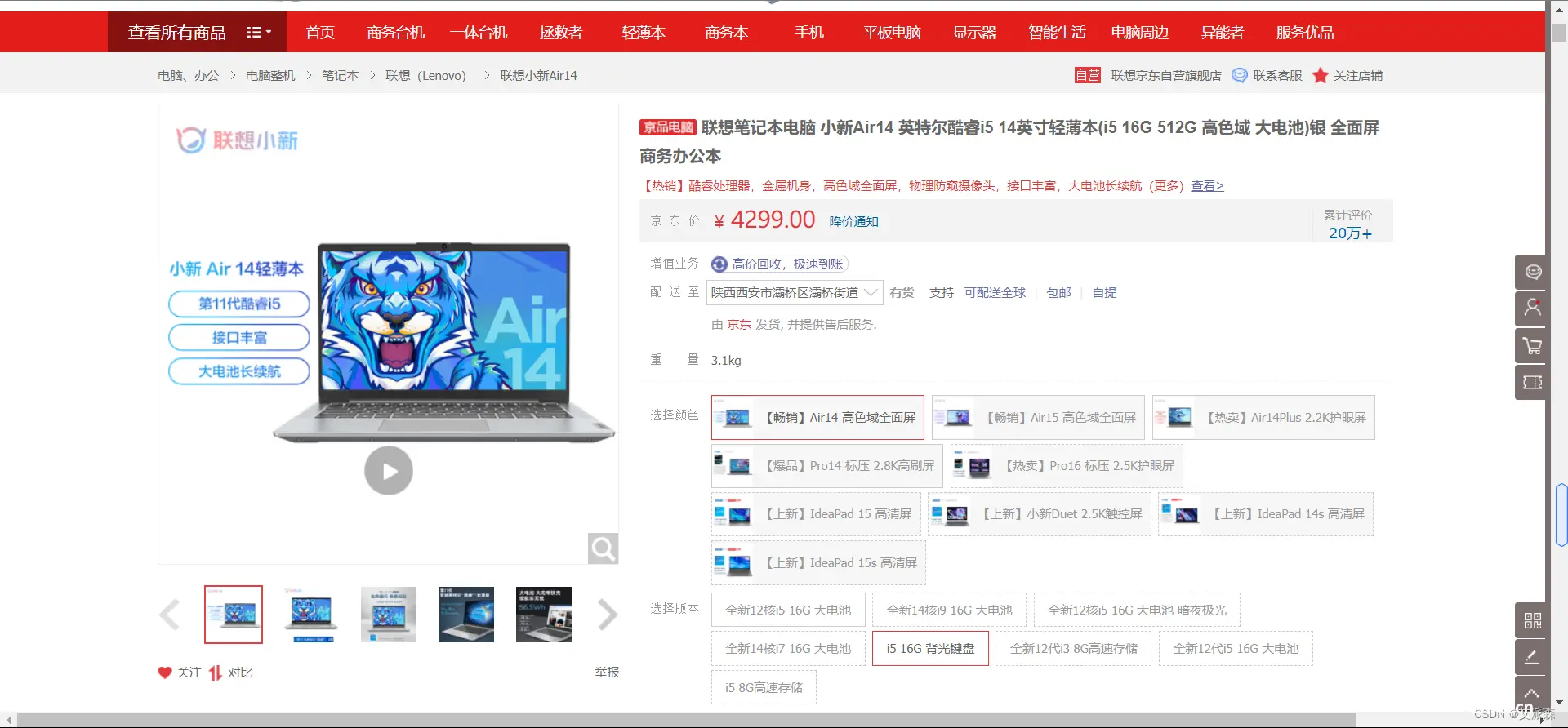
本次选取的某东官网的一款联想笔记本电脑,数据为动态加载的,通过开发者工具抓包分析即可。
源代码及结果截图:
import requests
import csv
from time import sleep
import random
def main(page,f):
url = 'https://club.jd.com/comment/productPageComments.action'
params = {
'productId': 100011483893,
'score': 0,
'sortType': 5,
'page': page,
'pageSize': 10,
'isShadowSku': 0,
'fold': 1
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.35 Safari/537.36',
'referer': 'https://item.jd.com/'
}
resp = requests.get(url,params=params,headers=headers).json()
comments = resp['comments']
for comment in comments:
content = comment['content']
content = content.replace('\n','')
comment_time = comment['creationTime']
score = comment['score']
print(score,comment_time,content)
csvwriter.writerow((score,comment_time,content))
print(f'第{page+1}页爬取完毕')
if __name__ == '__main__':
with open('04.csv','a',encoding='utf-8',newline='')as f:
csvwriter = csv.writer(f)
csvwriter.writerow(('评分','评论时间','评论内容'))
for page in range(15):
main(page,f)
sleep(5+random.random())
5. 实现多种方法模拟登录某乎,并爬取与一个与江汉大学有关问题和答案。
首先使用selenium打开某乎登录页面,接着使用手机进行二维码扫描登录

进入页面后,打开开发者工具,找到元素,,定位输入框,输入汉江大学,然后点击搜索按钮
以第二条帖子为例,进行元素分析 。
源代码及结果截图:
from time import sleep
from selenium.webdriver.chrome.service import Service
from selenium.webdriver import Chrome,ChromeOptions
from selenium.webdriver.common.by import By
import warnings
def main():
#忽略警告
warnings.filterwarnings("ignore")
# 创建一个驱动
service = Service('chromedriver.exe')
options = ChromeOptions()
# 伪造浏览器
options.add_experimental_option('excludeSwitches', ['enable-automation','enable-logging'])
options.add_experimental_option('useAutomationExtension', False)
# 创建一个浏览器
driver = Chrome(service=service,options=options)
# 绕过检测
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => false
})
"""
})
# 打开知乎登录页面
driver.get('https://www.zhihu.com/')
sleep(30)
# 点击搜索框
driver.find_element(By.ID,'Popover1-toggle').click()
# 输入内容
driver.find_element(By.ID,'Popover1-toggle').send_keys('汉江大学')
sleep(2)
# 点击搜索图标
driver.find_element(By.XPATH,'//*[@id="root"]/div/div[2]/header/div[2]/div[1]/div/form/div/div/label/button').click()
# 等待页面加载完
driver.implicitly_wait(20)
# 获取标题
title = driver.find_element(By.XPATH,'//*[@id="SearchMain"]/div/div/div/div/div[2]/div/div/div/h2/div/a/span').text
# 点击阅读全文
driver.find_element(By.XPATH,'//*[@id="SearchMain"]/div/div/div/div/div[2]/div/div/div/div/span/div/button').click()
sleep(2)
# 获取帖子内容
content = driver.find_element(By.XPATH,'//*[@id="SearchMain"]/div/div/div/div/div[2]/div/div/div/div/span[1]/div/span/p').text
# 点击评论
driver.find_element(By.XPATH,'//*[@id="SearchMain"]/div/div/div/div/div[2]/div/div/div/div/div[3]/div/div/button[1]').click()
sleep(2)
# 点击获取更多评论
driver.find_element(By.XPATH,'//*[@id="SearchMain"]/div/div/div/div/div[2]/div/div/div/div[2]/div/div/div[2]/div[2]/div/div[3]/button').click()
sleep(2)
# 获取评论数据的节点
divs = driver.find_elements(By.XPATH,'/html/body/div[6]/div/div/div[2]/div/div/div/div[2]/div[3]/div')
try:
for div in divs:
# 评论内容
comment = div.find_element(By.XPATH,'./div/div/div[2]').text
f.write(comment) # 写入文件
f.write('\n')
print(comment)
except:
driver.close()
if __name__ == '__main__':
# 创建文件存储数据
with open('05.txt','a',encoding='utf-8')as f:
main()

6. 综合利用所学知识,爬取某个某博用户前5页的微博内容。
这里我们选取了人民日报的微博内容进行爬取,具体页面我就不放这了,怕违规。
源代码及结果截图:
import requests
import csv
from time import sleep
import random
def main(page):
url = f'https://weibo.com/ajax/statuses/mymblog?uid=2803301701&page={page}&feature=0&since_id=4824543023860882kp{page}'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
'cookie':'SINAGLOBAL=6330339198688.262.1661412257300; ULV=1661412257303:1:1:1:6330339198688.262.1661412257300:; PC_TOKEN=8b935a3a6e; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWoQDW1G.Vsux_WIbm9NsCq5JpX5KMhUgL.FoMNShMN1K5ESKq2dJLoIpjLxKnL1h.LB.-LxKqLBoBLB.-LxKqLBKeLB--t; ALF=1697345086; SSOLoginState=1665809086; SCF=Auy-TaGDNaCT06C4RU3M3kQ0-QgmTXuo9D79pM7HVAjce1K3W92R1-fHAP3gXR6orrHK_FSwDsodoGTj7nX_1Hw.; SUB=_2A25OTkruDeRhGeFJ71UW-S7OzjqIHXVtOjsmrDV8PUNbmtANLVKmkW9Nf9yGtaKedmyOsDKGh84ivtfHMGwvRNtZ; XSRF-TOKEN=LK4bhZJ7sEohF6dtSwhZnTS4; WBPSESS=PfYjpkhjwcpEXrS7xtxJwmpyQoHWuGAMhQkKHvr_seQNjwPPx0HJgSgqWTZiNRgDxypgeqzSMsbVyaDvo7ng6uTdC9Brt07zYoh6wXXhQjMtzAXot-tZzLRlW_69Am82CXWOFfcvM4AzsWlAI-6ZNA=='
}
resp = requests.get(url,headers=headers)
data_list = resp.json()['data']['list']
for item in data_list:
created_time = item['created_at'] # 发布时间
author = item['user']['screen_name'] # 作者
title = item['text_raw'] # 帖子标题
reposts_count = item['reposts_count'] # 转发数
comments_count = item['comments_count'] # 评论数
attitudes_count = item['attitudes_count'] # 点赞数
csvwriter.writerow((created_time,author,title,reposts_count,comments_count,attitudes_count))
print(created_time,author,title,reposts_count,comments_count,attitudes_count)
print(f'第{page}页爬取完毕')
if __name__ == '__main__':
# 创建保存数据的csv文件
with open('06-2.csv','a',encoding='utf-8',newline='')as f:
csvwriter = csv.writer(f)
# 添加文件表头
csvwriter.writerow(('发布时间','发布作者','帖子标题','转发数','评论数','点赞数'))
for page in range(1,6): # 爬取前5页数据
main(page)
sleep(5+random.random())
7.自选一个热点或者你感兴趣的主题,爬取数据并进行简要数据分析(例如,通过爬取电影的名称、类型、总票房等数据统计分析不同类型电影的平均票房,十年间每年票房冠军的票房走势等;通过爬取中国各省份地区人口数量,统计分析我国人口分布等)。
本次选取的网址是艺恩娱数,目标是爬取里面的票房榜数据,通过开发者工具抓包分析找到数据接口,然后开始编写代码进行数据抓取。
源代码及结果截图:
import requests
import csv
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
def main():
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',}
data = {
'r': '0.9936776079863086',
'top': '50',
'type': '0',
}
resp = requests.post('https://ys.endata.cn/enlib-api/api/home/getrank_mainland.do', headers=headers, data=data)
data_list = resp.json()['data']['table0']
for item in data_list:
rank = item['Irank'] # 排名
MovieName = item['MovieName'] # 电影名称
ReleaseTime = item['ReleaseTime'] # 上映时间
TotalPrice = item['BoxOffice'] # 总票房(万)
AvgPrice = item['AvgBoxOffice'] # 平均票价
AvgAudienceCount = item['AvgAudienceCount'] # 平均场次
# 写入csv文件
csvwriter.writerow((rank,MovieName,ReleaseTime,TotalPrice,AvgPrice,AvgAudienceCount))
print(rank,MovieName,ReleaseTime,TotalPrice,AvgPrice,AvgAudienceCount)
def data_analyze():
# 读取数据
data = pd.read_csv('07.csv')
# 从上映时间中提取出年份
data['年份'] = data['上映时间'].apply(lambda x: x.split('-')[0])
# 各年度上榜电影总票房占比
df1 = data.groupby('年份')['总票房(万)'].sum()
plt.figure(figsize=(6, 6))
plt.pie(df1, labels=df1.index.to_list(), autopct='%1.2f%%')
plt.title('各年度上榜电影总票房占比')
plt.show()
# 各个年份总票房趋势
df1 = data.groupby('年份')['总票房(万)'].sum()
plt.figure(figsize=(6, 6))
plt.plot(df1.index.to_list(), df1.values.tolist())
plt.title('各年度上榜电影总票房趋势')
plt.show()
# 平均票价最贵的前十名电影
print(data.sort_values(by='平均票价', ascending=False)[['年份', '电影名称', '平均票价']].head(10))
# 平均场次最高的前十名电影
print(data.sort_values(by='平均场次', ascending=False)[['年份', '电影名称', '平均场次']].head(10))
if __name__ == '__main__':
# 创建保存数据的csv文件
with open('07.csv', 'w', encoding='utf-8',newline='') as f:
csvwriter = csv.writer(f)
# 添加文件表头
csvwriter.writerow(('排名', '电影名称', '上映时间', '总票房(万)', '平均票价', '平均场次'))
main()
# 数据分析
data_analyze()
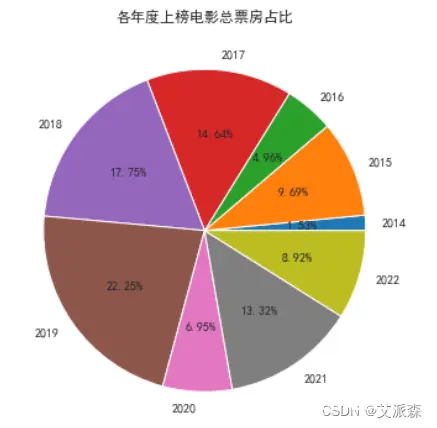
从年度上榜电影票房占比来看,2019年占比最高,说明2019年这一年的电影质量都很不错,上榜电影多而且票房高。
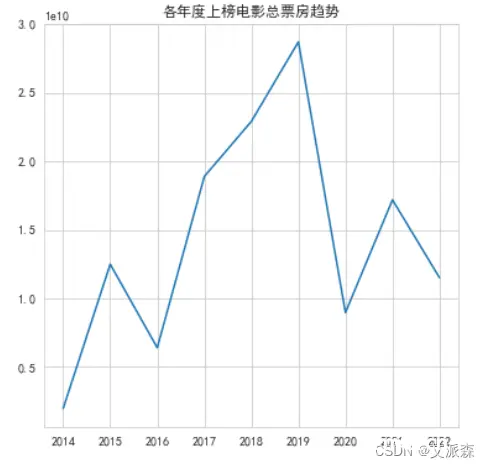
从趋势来看,从2016年到2019年,上榜电影总票房一直在增长,到2019年达到顶峰,说明这一年电影是非常的火爆,但是从2020年急剧下滑,最大的原因应该是这一年年初开始爆发疫情,导致贺岁档未初期上映,而且由于疫情影响,电影院一直处于关闭状态,所以这一年票房惨淡。
好了,本次案例分享到此结束,希望对刚入手爬虫的小伙伴有所帮助。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。