Python基于深度学习机器学习卷积神经网络实现垃圾分类垃圾识别系统(GoogLeNet,Resnet,DenseNet,MobileNet,EfficientNet,Shufflent)
CSDN 2024-06-17 09:35:01 阅读 67
文章目录
1 前言+ 2 卷积神经网络(CNN)详解+
2.1 CNN架构概述+
2.1.1 卷积层+ 2.1.2 池化层+ 2.1.3 全连接层
2.2 CNN训练过程+ 2.3 CNN在垃圾图片分类中的应用
3 代码详解+
3.1 导入必要的库+ 3.2 加载数据集+ 3.3 可视化随机样本+ 3.4 数据预处理与生成器+ 3.5 构建、编译和训练CNN模型+
3.5.1 构建CNN模型+ 3.5.2 编译模型+ 3.5.3 训练模型
3.6 结果可视化与分析+
3.6.1 获取测试数据+ 3.6.2 模型预测+ 3.6.3 可视化预测结果
4 结语

1 前言
设计项目案例演示地址: 链接
毕业设计代做一对一指导项目方向涵盖:
基于Python,MATLAB设计,OpenCV,,CNN,机器学习,R-CNN,GCN,LSTM,SVM,BP神经网络,数字识别,贝叶斯,逻辑回归,卷积神经网络等算法的中文文本分类.车牌识别,知识图谱,数字图像处理,手势识别,边缘检测,图像增强,图像分类,图像分割,色彩增强,低照度。缺陷检测,病害识别,图像缺陷检测,裂缝识别,交通标志识别,夜间车牌识别,人数统计,火焰烟雾火,车道线识别,人脸识别等系
欢迎阅读本篇关于利用卷积神经网络(Convolutional Neural Network,CNN)实现垃圾图片分类的 Python 小项目。在这个项目中,我们将通过使用 CNN,对垃圾图片进行高效分类。本数据集包含六种不同类型的垃圾(可能与上海地区的分类标准有所不同),分别为玻璃、纸、硬纸板、塑料、金属以及一般垃圾。
在接下来的内容中,我们将深入探讨如何利用深度学习的 CNN 模型,通过训练网络来识别和区分这些不同类型的垃圾。通过阅读本文,您将了解到项目的整体流程,从数据准备和模型构建,到训练和评估,最终实现一个能够准确分类垃圾图片的小应用。
让我们一起开始这个令人兴奋的学习之旅吧!
2 卷积神经网络(CNN)详解
在本章中,我们将深入探讨卷积神经网络(CNN),这是一种在图像处理和计算机视觉任务中表现出色的深度学习架构。CNN 的设计灵感来自生物学中视觉皮层对视觉信息的处理方式,通过逐层提取特征,使网络能够有效地理解图像中的模式和结构。
2.1 CNN架构概述
卷积神经网络由多层组成,其中主要的层类型包括卷积层、池化层和全连接层。每一层都具有特定的功能,共同构建了网络的表达能力。下面我们来详细了解这些层的作用:
2.1.1 卷积层
卷积层是CNN的核心组件,用于提取图像中的局部特征。通过卷积操作,网络能够捕捉像边缘、纹理等低级特征。卷积操作基于滤波器(也称为卷积核或内核),滤波器在图像上滑动并执行卷积运算,生成特征映射。
2.1.2 池化层
池化层用于减小特征映射的空间尺寸,从而降低后续计算的复杂性。最常见的池化操作是最大池化,它在每个池化窗口中选取最大值作为代表性特征。池化操作有助于网络对位置变化的容忍性,并且可以降低过拟合风险。
2.1.3 全连接层
全连接层将前面层的特征映射转化为最终的分类结果。每个神经元在前一层的特征上进行权重计算,生成最终的输出。全连接层的设计使得网络能够在高维特征空间中进行决策和分类。
2.2 CNN训练过程
CNN的训练过程通常包括以下关键步骤:
前向传播(Forward Propagation):输入图像通过卷积和池化层,逐渐提取特征并减小尺寸,最终传递给全连接层。+ 损失计算(Loss Computation):根据网络输出和真实标签计算损失,衡量预测与实际之间的差异。+ 反向传播(Backward Propagation):通过反向传播算法,计算损失相对于网络权重的梯度,以便进行参数更新。+ 参数更新(Parameter Update):使用优化算法(如梯度下降)根据梯度信息更新网络的权重和偏差,使损失逐渐减小。+ 迭代训练:重复执行前向传播、损失计算、反向传播和参数更新,直到损失收敛或达到预定的训练轮数。
2.3 CNN在垃圾图片分类中的应用
在我们的项目中,我们将使用CNN来训练一个模型,使其能够从垃圾图片中学习并提取有关不同垃圾类型的特征。通过逐步堆叠卷积和池化层,网络将能够逐渐抽象出更高级别的特征,最终实现准确的分类。
3 代码详解
在本章中,我们将深入研究实现垃圾图片分类的代码。我们将使用 Keras 库来构建卷积神经网络(CNN),对图像数据进行预处理,以及训练模型。让我们一步步解析这些关键代码块。
3.1 导入必要的库
首先,我们需要导入一些必要的库,以便在项目中使用它们。以下代码段展示了导入库的过程:
import numpy as npimport matplotlib.pyplot as pltfrom keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array, array_to_imgfrom keras.layers import Conv2D, Flatten, MaxPooling2D, Densefrom keras.models import Sequentialimport glob, os, random
3.2 加载数据集
接下来,我们需要加载垃圾图片数据集,并准备用于训练的图像数据。下面的代码片段演示了这一过程:
base_path = '../input/trash_div7612/dataset-resized'#填写你下载文件的地址img_list = glob.glob(os.path.join(base_path, '*/*.jpg'))print(len(img_list))
在这里,我们使用 glob 函数来获取指定文件夹下所有 .jpg 格式的图片路径,并打印出图片数量。 输出结果:
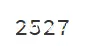
我们总共有2527张图片
3.3 可视化随机样本
我们可以从加载的图像列表中随机选择一些样本,并将其可视化,以便更好地理解数据。以下代码展示了如何实现这一功能:
for i, img_path in enumerate(random.sample(img_list, 6)): img = load_img(img_path) img = img_to_array(img, dtype=np.uint8) plt.subplot(2, 3, i+1) plt.imshow(img.squeeze())
输出结果:

在这里,我们使用了 random.sample 函数来随机选择 6 张图片进行可视化。使用 load_img 函数将图像加载为对象,然后将其转换为 NumPy 数组,并使用 plt.imshow 函数来显示图像。
3.4 数据预处理与生成器
在深度学习中,数据预处理和生成器是训练模型不可或缺的一部分。它们有助于有效地处理和加载大量的图像数据,同时可以在训练过程中进行数据增强,提高模型的鲁棒性。以下是如何使用 Keras 中的 ImageDataGenerator 和生成器来处理数据:
首先,我们定义了训练和测试数据的数据生成器,它们将对图像数据进行预处理,并将其分成训练集和验证集。我们还对图像进行了一系列的预处理操作,如缩放、剪切、翻转等:
train_datagen = ImageDataGenerator( rescale=1./255, shear_range=0.1, zoom_range=0.1, width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True, vertical_flip=True, validation_split=0.1)test_datagen = ImageDataGenerator( rescale=1./255, validation_split=0.1)train_generator = train_datagen.flow_from_directory( base_path, target_size=(300, 300), batch_size=16, class_mode='categorical', subset='training', seed=0)validation_generator = test_datagen.flow_from_directory( base_path, target_size=(300, 300), batch_size=16, class_mode='categorical', subset='validation', seed=0)
在这里,我们使用 ImageDataGenerator 对象来创建生成器,将数据预处理步骤包括在内。train_generator 用于训练集,而 validation_generator 则用于验证集。我们还指定了图像的目标大小、批次大小以及类别模式等。
最后,我们输出了类别索引的字典,这将有助于我们理解每个类别对应的标签:
labels = (train_generator.class_indices)labels = dict((v,k) for k,v in labels.items())print(labels)
这段代码将输出一个字典,其中键是类别的数字索引,值是对应的类别名称。 输出结果:

3.5 构建、编译和训练CNN模型
现在我们将深入了解如何构建、编译和训练卷积神经网络(CNN)模型,以实现垃圾图片的分类任务。以下是这个过程的详细解释:
3.5.1 构建CNN模型
首先,我们使用 Keras 库构建卷积神经网络(CNN)模型。该模型由多个卷积层、池化层和全连接层组成,从而能够逐步提取图像中的特征,并在全连接层中进行分类。以下是我们构建的模型结构:
model = Sequential([ Conv2D(filters=32, kernel_size=3, padding='same', activation='relu', input_shape=(300, 300, 3)), MaxPooling2D(pool_size=2), Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'), MaxPooling2D(pool_size=2), Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'), MaxPooling2D(pool_size=2), Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'), MaxPooling2D(pool_size=2), Flatten(), Dense(64, activation='relu'), Dense(6, activation='softmax')])
在这里,我们使用 Sequential 模型,将一系列的卷积层、池化层和全连接层逐一堆叠起来。我们的模型结构使用了多个卷积层和池化层,以及全连接层,以便能够从图像中抽取有关不同垃圾类别的特征。
3.5.2 编译模型
一旦我们构建了模型结构,我们需要编译模型,为模型选择损失函数和优化器,并指定评估指标。以下代码编译了我们的模型:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
在这里,我们使用交叉熵损失函数(categorical_crossentropy)作为我们的目标函数,用于多类别分类问题。优化器我们选择了 Adam,而评估指标我们选择了准确率(acc)。
3.5.3 训练模型
最后,我们使用生成器 train_generator 和 validation_generator 来训练模型。我们设置了训练轮数为 100 轮,以及适当的批次大小和步数。以下代码展示了如何训练我们的模型:
model.fit_generator(train_generator, epochs=100, steps_per_epoch=2276//32,validation_data=validation_generator, validation_steps=251//32)
在这里,steps_per_epoch 表示每个训练轮次中的批次数,validation_steps 表示每个验证轮次中的批次数。通过这些参数,我们可以有效地进行模型训练和验证。 部分输出结果:

3.6 结果可视化与分析
在这一章节,我们将深入探讨如何通过模型的预测结果进行结果可视化和分析。这有助于我们更好地理解模型在垃圾图片分类任务中的表现。以下是如何可视化测试结果的详细解释:
3.6.1 获取测试数据
首先,我们从验证数据生成器中获取一个批次的测试数据,包括图像数据和相应的真实标签:
test_x, test_y = validation_generator.__getitem__(1)
这里我们选择了一个批次的测试数据,即批次编号为 1 的测试数据。
3.6.2 模型预测
然后,我们使用训练好的模型对测试数据进行预测,得到预测结果:
preds = model.predict(test_x)
这将得到一组预测概率,每个预测表示对应图像属于不同垃圾类别的概率。
3.6.3 可视化预测结果
最后,我们通过循环将测试数据、真实标签和模型的预测结果进行可视化。以下代码展示了如何实现这一过程:
plt.figure(figsize=(16, 16))for i in range(16): plt.subplot(4, 4, i+1) plt.title('pred:%s / truth:%s' % (labels[np.argmax(preds[i])], labels[np.argmax(test_y[i])])) plt.imshow(test_x[i])
在这里,我们使用 plt.subplot 创建一个 4x4 的子图布局,然后将每个测试样本、其真实标签以及模型的预测结果显示在子图中。这有助于我们直观地比较模型的预测和真实标签。

设计项目案例演示地址: 链接
毕业设计代做一对一指导项目方向涵盖:
基于Python,MATLAB设计,OpenCV,,CNN,机器学习,R-CNN,GCN,LSTM,SVM,BP神经网络,数字识别,贝叶斯,逻辑回归,卷积神经网络等算法的中文文本分类.车牌识别,知识图谱,数字图像处理,手势识别,边缘检测,图像增强,图像分类,图像分割,色彩增强,低照度。缺陷检测,病害识别,图像缺陷检测,裂缝识别,交通标志识别,夜间车牌识别,人数统计,火焰烟雾火,车道线识别,人脸识别等系
4 结语
本文带领读者踏上了一段深度学习的垃圾分类之旅。通过利用卷积神经网络(CNN)这一强大工具,我们不仅能够从垃圾图片中提取有关不同类别的特征,还能将图像分类推向一个全新的高度。从数据准备、模型构建,再到训练和评估,我们深入探讨了每一步的细节。
在这个过程中,我们了解了CNN的架构、数据预处理的重要性以及模型的构建和训练。我们不仅能够观察到训练过程中损失和准确率的变化,还可以通过可视化模型的预测结果,更好地理解模型的表现。这不仅是技术的胜利,更是对创新思维的体现。
然而,深度学习的路途充满挑战。不同的数据集、模型架构和参数选择都可能影响着模型的效果。因此,我们还有许多优化的空间,不断学习和尝试,才能进一步提升模型的性能。
让我们带着对深度学习的热情,继续探索垃圾图片分类的更深层次,让技术的力量与环保的使命相互交融。未来的每一次进步,都会为我们的社会贡献出更清洁、更美好的明天。
所以,让我们继续前行,以技术的智慧和创新的灵感,开创出一个绿色、可持续的未来!
下一篇: python和pycharm从安装到激活全过程(保姆级教程)
本文标签
DenseNet MobileNet EfficientNet Python基于深度学习机器学习卷积神经网络实现垃圾分类垃圾识别系统(GoogLeNet Shufflent) Resnet
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。