MATLAB中unique函数最全使用方法
CSDN 2024-08-25 16:35:01 阅读 100
MATLAB中unique函数最全使用方法
一. unique函数初级应用
MATLAB中的unique函数用于查找并移除数组中的重复元素,并返回经过排序的唯一元素列表。以下是一些基本的应用示例。
1. 对向量进行去重
A = [1 2 2 3 3 3 4 4 4 4 5 5 5 5 5];
B = unique(A);
disp(B); % 结果:1 2 3 4 5
2. 对矩阵进行去重
如果你有一个矩阵,unique函数会将其视为一个长向量并进行操作。
A = [1 2 2; 3 3 3; 4 4 4];
B = unique(A);
disp(B); % 结果:1 2 3 4
3. 按行去重
如果你希望按照行对矩阵进行去重,可以添加'rows'选项。
A = [1 2 3; 1 2 3; 4 5 6];
B = unique(A, 'rows');
disp(B); % 结果:[1 2 3; 4 5 6]
4. 获取去重操作的索引
unique函数可以返回额外的输出参数,表示原数组中元素在去重数组中的位置,以及去重数组中元素在原数组中的位置。
A = [1 2 2 3 3 3];
[B, I, J] = unique(A);
disp(B); % 结果:1 2 3
disp(I); % 结果:1 2 4
disp(J); % 结果:1 2 2 3 3 3
在这个例子中,I表示原数组中的元素在去重数组中首次出现的位置,J表示去重数组中的元素在原数组中出现的位置。
二. unique函数中级应用
在MATLAB中,unique函数不仅可以用于查找数组中唯一的元素,还可以用于执行更复杂的操作,例如处理字符串、单元数组或表格数据,以及控制排序行为。以下是unique函数的一些中级应用示例:
1. 处理字符串数组
unique也可以用于字符串数组。
A = ["apple", "banana", "apple", "cherry", "banana"];
B = unique(A);
disp(B); % 结果:"apple" "banana" "cherry"
2. 处理单元数组
如果你的数据中包含多种类型(例如,数字和字符串混合),可以使用单元数组,并使用unique函数处理。
A = {1, 2, 'apple', 2, 'apple', 3, 'banana'};
B = unique(A);
disp(B); % 结果:{1, 2, 3, 'apple', 'banana'}
3. 处理表格数据
unique函数还可以用于表格数据的去重。
T = table([1; 2; 1], ["apple"; "banana"; "apple"]);
U = unique(T);
disp(U); % 结果:1×2 table: 1 apple; 2 banana
4. 控制排序行为
默认情况下,unique函数返回的结果是排序的。如果你不需要排序,可以添加'stable'选项。
A = [3, 1, 2, 3, 2, 1];
B = unique(A, 'stable');
disp(B); % 结果:3 1 2
三. unique函数高级应用
在MATLAB中,unique函数的神级应用可能涉及到一些高级的数据处理和数据分析任务。下面是一个示例,涉及到处理复杂的数据结构和使用额外的输出参数。
处理结构数组
假设你有一个结构数组,其中包含多个字段,你想找到所有字段值的唯一组合。
% 创建结构数组
A(1).field1 = 'apple';
A(1).field2 = 1;
A(2).field1 = 'banana';
A(2).field2 = 2;
A(3).field1 = 'apple';
A(3).field2 = 1;
% 将结构数组转换为表格
T = struct2table(A);
% 使用'rows'选项找到唯一的行
U = unique(T, 'rows');
disp(U); % 结果:2x2 table: 'apple' 1; 'banana' 2
使用额外的输出参数进行分组分析
假设你有一组数据,你想根据某个变量的值对数据进行分组,并对每组数据进行分析。你可以使用unique函数的额外输出参数来实现这个任务。
% 创建数据
group = ['A', 'A', 'B', 'B', 'B', 'C', 'C'];
data = [10, 20, 30, 40, 50, 60, 70];
% 找到唯一的组和组索引
[groups, ~, groupIndex] = unique(group);
% 对每组数据进行分析(例如,计算平均值)
for i = 1:length(groups)
groupData = data(groupIndex == i);
groupMean = mean(groupData);
disp(['Group ' groups(i) ': Mean = ' num2str(groupMean)]);
end
这个示例将显示每个组的平均值。unique函数在这里帮助我们找到了唯一的组,并为每个数据点提供了相应的组索引,这使得按组进行数据分析变得非常方便。
在处理大规模数据时,unique函数可能需要消耗大量的计算资源。为了提高性能,你可以考虑使用'sorted'选项,这样unique函数可以利用数据已经排序的事实来提高速度。
% 假设你的数据已经排序
sortedData = sort(data);
% 使用'sorted'选项找出唯一的用户ID
uniqueUsers = unique(sortedData, 'sorted');
disp(['Number of unique users: ' num2str(length(uniqueUsers))]);
在这个示例中,使用'sorted'选项可以大大提高unique函数的性能,尤其是在处理大规模数据集时。
四.代码和程序结果
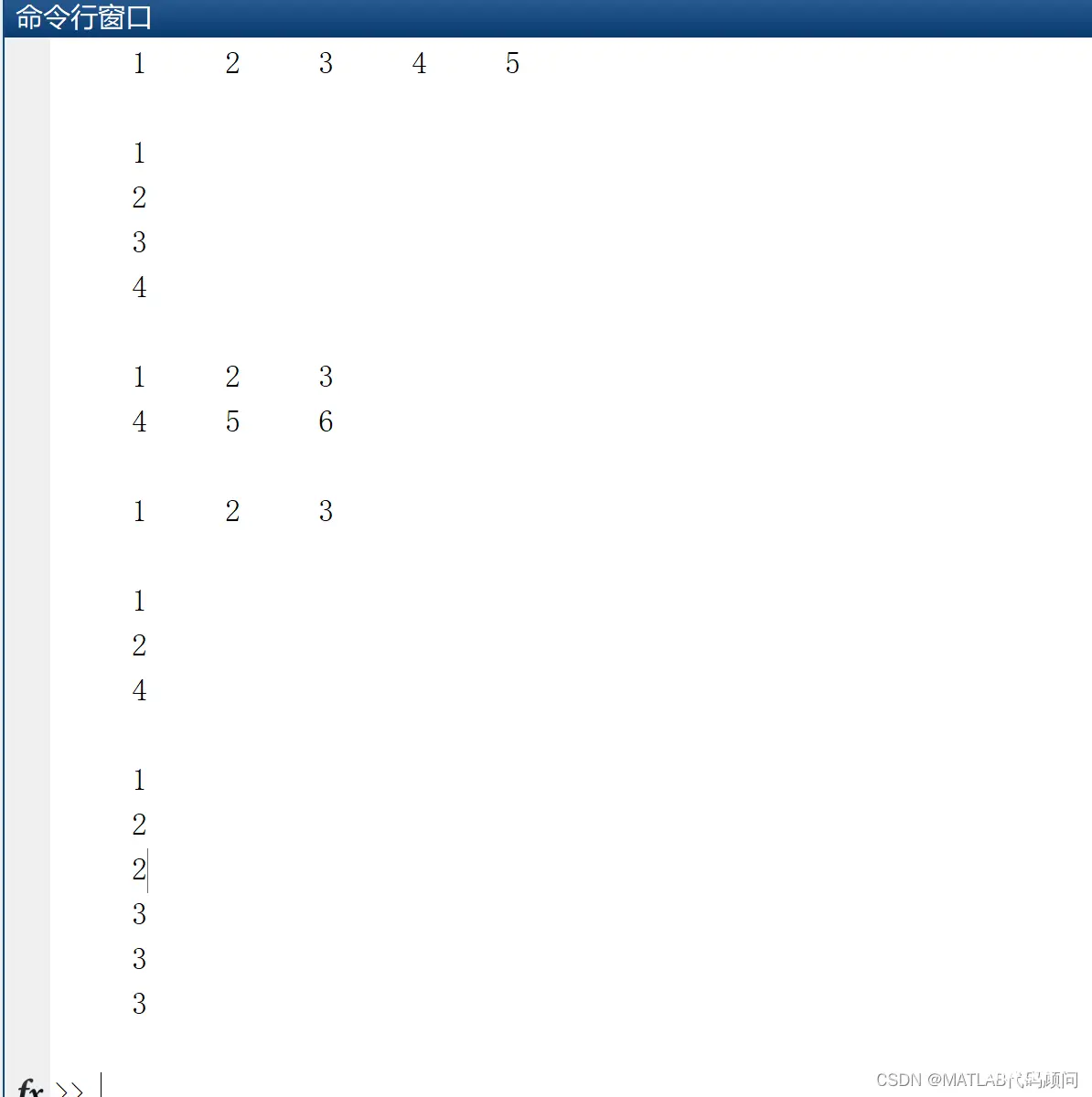
clear all;clc;close all;
% 1. 对向量进行去重
A = [1 2 2 3 3 3 4 4 4 4 5 5 5 5 5];
B = unique(A);
disp(B); % 结果:1 2 3 4 5
% 2. 对矩阵进行去重
% 如果你有一个矩阵,unique函数会将其视为一个长向量并进行操作。
A = [1 2 2; 3 3 3; 4 4 4];
B = unique(A);
disp(B); % 结果:1 2 3 4
% 3. 按行去重
% 如果你希望按照行对矩阵进行去重,可以添加'rows'选项。
A = [1 2 3; 1 2 3; 4 5 6];
B = unique(A, 'rows');
disp(B); % 结果:[1 2 3; 4 5 6]
% 4. 获取去重操作的索引
% unique函数可以返回额外的输出参数,表示原数组中元素在去重数组中的位置,以及去重数组中元素在原数组中的位置。
A = [1 2 2 3 3 3];
[B, I, J] = unique(A);
disp(B); % 结果:1 2 3
disp(I); % 结果:1 2 4
disp(J); % 结果:1 2 2 3 3 3
% 在这个例子中,I表示原数组中的元素在去重数组中首次出现的位置,J表示去重数组中的元素在原数组中出现的位置。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。