数据分析神器Pandas快速入门2序列(Series)进阶、运算符&汇聚
pythontesting 2024-06-28 15:09:00 阅读 56
2.1 序列进阶
我们将从美国燃油经济性网站提取数据。该网站拥有自1984年以来在美国销售的汽车品牌和型号的效率数据。
read_csv函数不仅可以接受URL,还可以接受ZIP文件。因为这个ZIP文件只包含一个文件,所以我们可以使用这个函数。如果它是一个包含多个文件的 ZIP 文件,我们就需要解压数据,取出我们感兴趣的文件。
我们要研究的数据集中的第一列是city08和highway08,它们分别提供了在城市和高速公路上行驶时每加仑英里数的信息:
>>> import pandas as pd
>>> url = 'https://github.com/mattharrison/datasets/raw/master/data/vehicles.csv.zip'
>>> df = pd.read_csv(url)
<stdin>:1: DtypeWarning: Columns (68,70,71,72,73,74,76,79) have mixed types. Specify dtype option on import or set low_memory=False.
>>> city_mpg = df.city08
>>> highway_mpg = df.highway08
>>> city_mpg
0 19
1 9
2 23
3 10
4 17
..
41139 19
41140 20
41141 18
41142 18
41143 16
Name: city08, Length: 41144, dtype: int64
>>> highway_mpg
0 25
1 14
2 33
3 12
4 23
..
41139 26
41140 28
41141 24
41142 24
41143 21
Name: highway08, Length: 41144, dtype: int64
2.1.1 序列属性
pandas库提供了很多功能。内置的dir函数将列出对象的属性。让我们来看看一个序列有多少个属性:
>>> len(dir(city_mpg))
420
序列有400多个属性。Python的列表或字典只有大约40个属性。
方法:
- Dunder 方法(.add、.iter 等)提供许多数值操作、循环、属性访问和索引访问。对于数字运算,这些方法返回系列。
- 许多数值运算的相应运算符方法允许我们调整运算行为(除了 .add 方法外,还有 .add 方法)。
- 聚合方法和属性可将数列中的值缩小或聚合为单个标量值。例如,.mean、.max 和 .sum 方法以及 .is_monotonic 属性。
- 转换方法。其中一些以.to_开头,可将数据导出为其他格式。
- 操作方法,如 .sort_values 和 .drop_duplicates 方法,可返回具有相同索引的系列对象。
- 索引和访问方法及属性,如 .loc 和 .iloc。这些方法和属性可返回系列或标量。
- 字符串操作.str
- 日期处理.dt
- 绘图方法.plot
- 分类操作.cat
- 转换方法如.unstack 和 .reset_index、.agg、.transform。
- 属性如 .index 和 .dtype。
- 我们将忽略的大量私有属性(约 130 个)。
2.2 运算符
计算两个序列平均值的一种方法:
>>> (city_mpg + highway_mpg)/2
0 22.0
1 11.5
2 28.0
3 11.0
4 20.0
...
41139 22.5
41140 24.0
41141 21.0
41142 21.0
41143 18.5
Length: 41144, dtype: float64
2.2.1 索引对齐
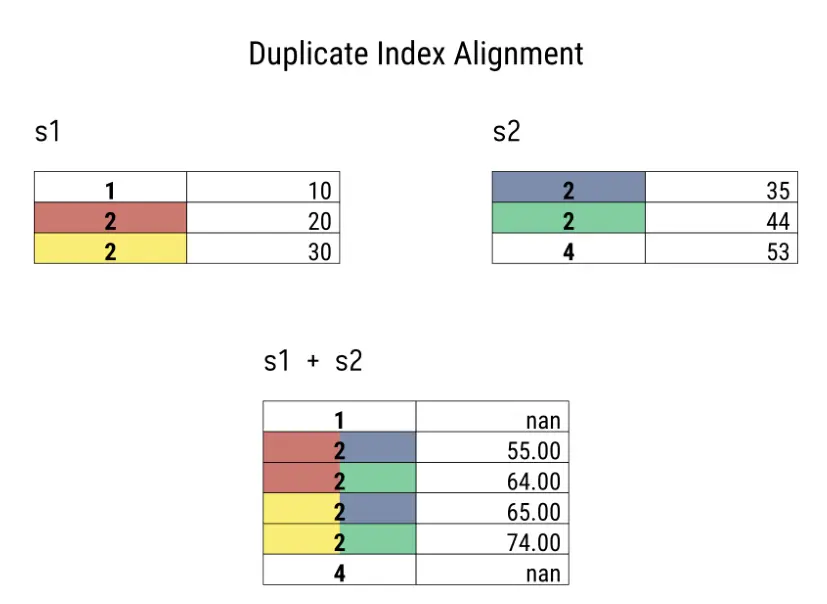
值得注意的是,您可以在一个数列上使用另一个数列进行大多数数学运算,也可以使用标量(就像我们在除法运算中所做的)。对两个数列进行操作时,pandas 会在执行操作前对齐索引。对齐会将左序列中的每个索引项与右序列索引中的每个同名索引项进行匹配。在上述情况中,具有相同索引名称的值会相加,然后除以2。
由于索引对齐,因此需要确保索引
- 唯一(无重复)
- 两个系列都是共同的 如果不存在这些情况,就会出现值缺失或结果组合爆炸的情况。
>>> s1 = pd.Series([10, 20, 30], index=[1,2,2])
>>> s2 = pd.Series([35, 44, 53], index=[2,2,4], name='s2')
>>> s1
1 10
2 20
2 30
dtype: int64
>>> s2
2 35
2 44
4 53
Name: s2, dtype: int64
>>> s1 + s2
1 NaN
2 55.0
2 64.0
2 65.0
2 74.0
4 NaN
dtype: float64
>>> s1.add(s2)
1 NaN
2 55.0
2 64.0
2 65.0
2 74.0
4 NaN
dtype: float64
对标量进行数学运算时,pandas会将运算结果广播给所有值。在上述情况中,这些值是相加的。这样就可以轻松编写数学运算。这也使代码易于阅读。
广播还有另一个好处。对于许多数学运算,CPU会对其进行优化并快速执行。这就是所谓的矢量化。(数字pandas系列是一个内存块,现代 CPU 利用一种称为单指令/多数据(SIMD)的技术将数学运算应用于内存块)。
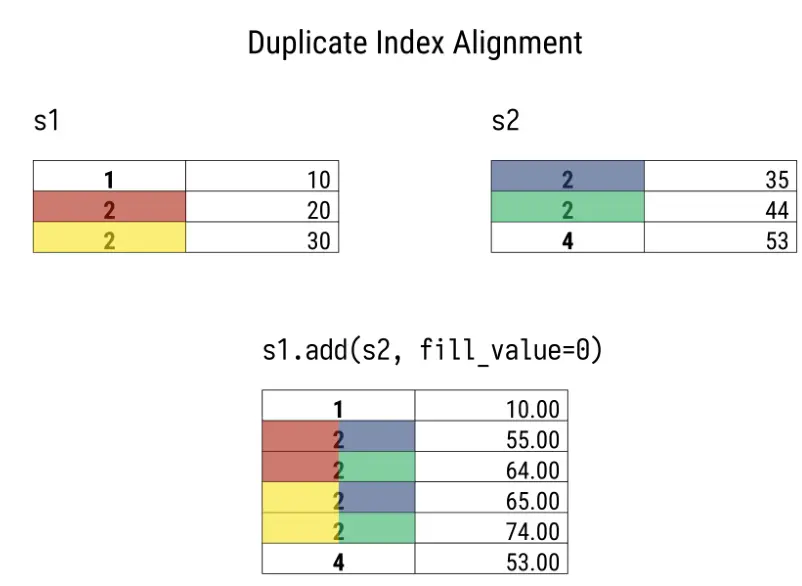
.add等操作方法的一个优点是可以指定填充值。在执行操作前,索引项仍将对齐。
可用的操作包括
+、-、/、//(地板除)、%(模)、@(矩阵乘法)、**(幂)、<、<=、==、!=、>=、>、&(二进制和)、^(二进制 xor)、|(二进制或)。
序列也有.iter 方法,您可以循环遍历数列中的项目。不过,我建议避免在系列中使用 for 循环。你正在去掉 pandas 的一个优点--矢量化和C级操作。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
2.2.2 运算
在运算符方法中,可以用参数fill_value代替NaN。
>>> s1.add(s2, fill_value=0)
1 10.0
2 55.0
2 64.0
2 65.0
2 74.0
4 53.0
dtype: float64
方法使得链式操作更加容易。因为大多数 pandas 方法都不会就地改变数据,而是返回一个新对象,所以我们可以不断地对返回的对象进行方法调用。在本书中,我们会看到很多这样的例子。链式处理使代码易于阅读和理解。我们也可以使用运算符进行链式运算,但需要用括号将运算包起来。
下面,我们使用运算符计算城市和高速公路里程的平均值:
>>> s1.add(s2, fill_value=0)
1 10.0
2 55.0
2 64.0
2 65.0
2 74.0
4 53.0
dtype: float64
>>> ((city_mpg +
... highway_mpg)
... / 2
... )
0 22.0
1 11.5
2 28.0
3 11.0
4 20.0
...
41139 22.5
41140 24.0
41141 21.0
41142 21.0
41143 18.5
Length: 41144, dtype: float64
>>> (city_mpg
... .add(highway_mpg)
... .div(2)
... )
0 22.0
1 11.5
2 28.0
3 11.0
4 20.0
...
41139 22.5
41140 24.0
41141 21.0
41142 21.0
41143 18.5
Length: 41144, dtype: float64


2.3 汇聚(聚合)
汇聚是老板希望报告的数字。如果你在一家汉堡店工作,老板走进来询问餐厅的生意如何,你不会回答:"莎莉点了一个汉堡和薯条。乔点了芝士汉堡和奶昔。汤姆点了......"。
你的老板并不关心这些细节。他们关心的是
- 来了多少人(数)
- 点了多少食物(数量)
- 总收入是多少(总和)
- 什么时候来的人(偏差)
- 平均购买金额是多少(平均值)
通过聚合,您可以将详细数据折叠为单一数值。
>>> city_mpg.mean()
18.369045304297103
>>> city_mpg.is_unique
False
>>> city_mpg.is_monotonic_increasing
False
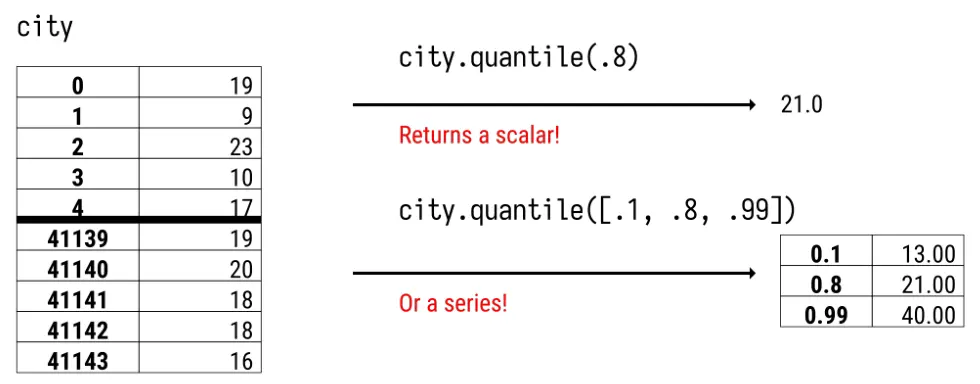
>>> city_mpg.quantile()
17.0
>>> city_mpg.quantile(.9)
24.0
>>> city_mpg.quantile([.1, .5, .9])
0.1 13.0
0.5 17.0
0.9 24.0
Name: city08, dtype: float64
如果要计算序列的平均值,我们可以使用聚合方法.mean,还有一些聚合属性。这些属性以.is_开头,不需要调用,它们的值为True或False。
quantile方法是Pandas库中用于计算分位数的常用方法。它可以用于计算DataFrame或Series中每个列或行的分位数。默认情况下,它返回50%的量化值。您可以指定另一个量级,也可以输入一个量级列表。在后一种情况下,调用.quantile的结果不再返回标量,而是返回Series对象。
属性的计数和平均值 这里是 pandas 计算集合的一个巧妙技巧。如果你想要符合某些条件的值的计数,可以使用 .sum 方法。例如,如果我们想要里程数大于20的汽车的数量和百分比,可以使用下面的代码:
# 里程数大于20的汽车的数量
>>> city_mpg.gt(20).sum()
10272
# 里程数大于20的汽车的比例,Python将True视为1,将False视为0
>>> city_mpg.gt(20).mul(100).mean()
24.965973167412017
>>> city_mpg.agg('mean')
18.369045304297103
- count()方法
用于计算非缺失值的数量。对于数值型数据,count()方法会计算非缺失的数字个数;对于非数值型数据,count()方法会计算非空的值的数量。
- sum()方法
用于计算数值的总和。对于非数值型数据,sum()方法会直接返回缺失值。
2.3.1 agg
agg()方法是Pandas库中用于对DataFrame或Series进行聚合操作的强大工具。它可以应用各种函数对数据进行计算,并返回聚合结果。
agg()方法可以应用以下几种聚合操作:
- 求和:sum()
- 求平均值:mean()
- 求中位数:median()
- 求众数:mode()
- 求标准差:std()
- 求最大值:max()
- 求最小值:min()
- 计算百分位数:quantile()
- 自定义聚合函数:使用lambda表达式或自定义函数
>>> city_mpg.agg('mean')
18.369045304297103
不过,使用 city_mpg.mean() 更简单。.agg 的亮点在于能够执行多重聚合。在这种情况下,它会返回序列。您可以输入聚合方法、NumPy简化函数、Python聚合函数的名称,或者定义您自己的聚合函数。下面是一个调用所有这些还原类型的示例:
>>> import numpy as np
>>> def second_to_last(s):
... return s.iloc[-2]
...
>>> city_mpg.agg(['mean', np.var, max, second_to_last])
mean 18.369045
var 62.503036
max 150.000000
second_to_last 18.000000
Name: city08, dtype: float64
以下是.agg 方法接受的字符串。您也可以传入其他字符串,但它们将返回非聚合结果。向 .agg 传递字符串时,pandas 会将其映射到系列中的方法:




声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。