elasticsearch 聚合 : 指标聚合、桶聚合、管道聚合解析使用总结
码到三十五 2024-07-02 09:07:03 阅读 68
❃博主首页 :
<码到三十五>
☠博主专栏 :
<mysql高手>
<elasticsearch高手>
<源码解读>
<java核心>
<面试攻关>
♝博主的话 :
<搬的每块砖,皆为峰峦之基;公众号搜索(码到三十五)关注这个爱发技术干货的coder,一起筑基>
目录
一、聚合查询概述二、聚合查询类型Metric Aggregations(指标聚合)Bucket Aggregations(桶聚合)Pipeline Aggregations(管道聚合)
三、聚合查询应用四、doc_values 与 fielddataexact value字段分词字段doc_values与fielddata的性能权衡Doc ValuesFielddata
五、multi-fields(多字段)六、聚合查询示例Terms 分桶聚合Date Histogram 直方图聚合Range 范围聚合Nested 嵌套聚合Pipeline 管道聚合Derivative(导数聚合)Cumulative Sum(累计和聚合)Moving Average(移动平均聚合)Bucket Script(桶脚本聚合)Filters 过滤器聚合
七、聚合排序八、优化建议
一、聚合查询概述
Elasticsearch中的聚合查询是一种功能强大的数据分析工具,它能够提供从索引中提取和计算有关数据的复杂统计信息的能力。聚合查询不仅可以帮助用户理解和分析数据中的趋势和模式,还能在业务决策中发挥关键作用。聚合查询支持多种类型,包括指标聚合、桶聚合和管道聚合,每一种都有其特定的应用场景和使用方法。
二、聚合查询类型

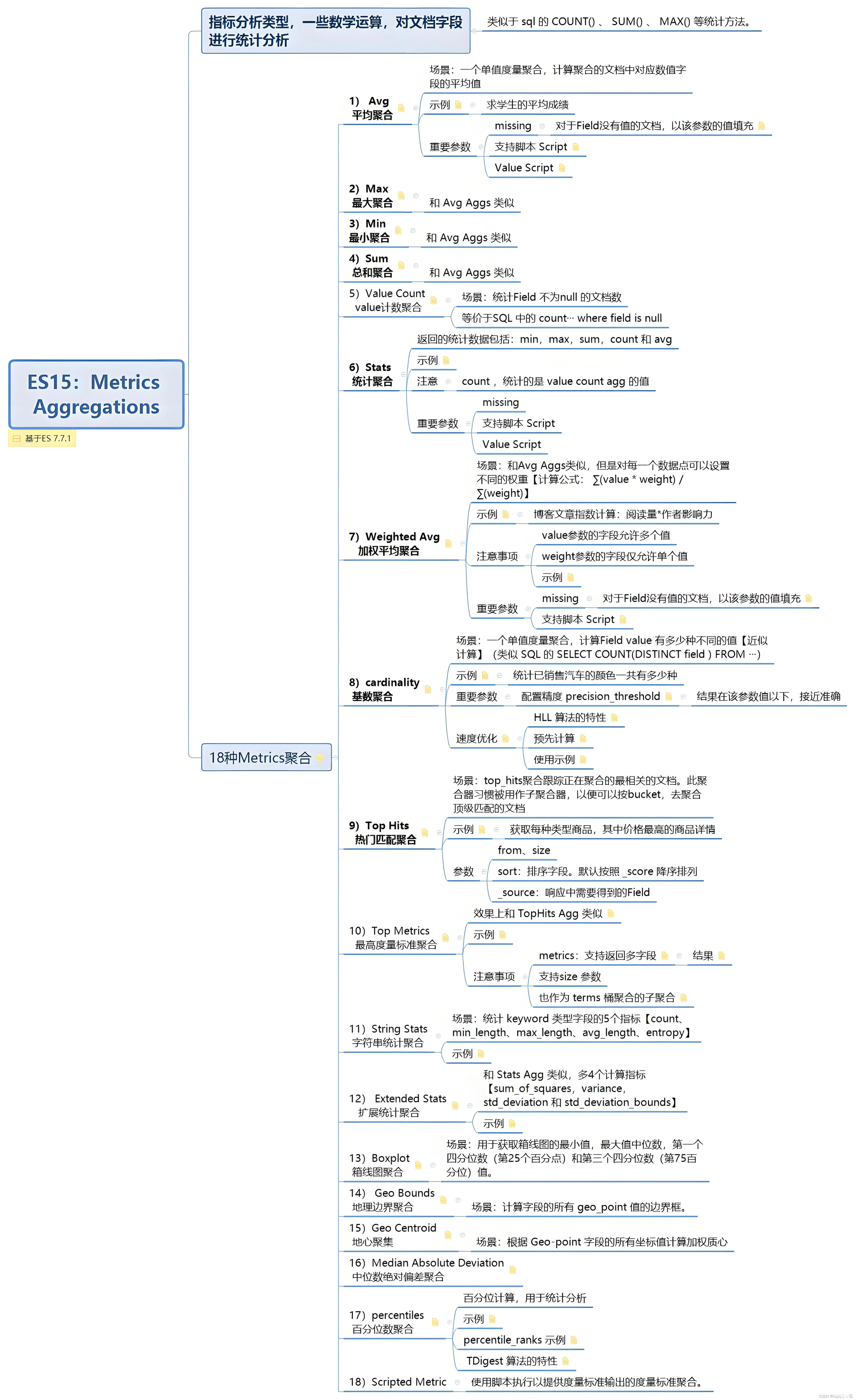
Metric Aggregations(指标聚合)
概述:指标聚合返回基于字段值的度量结果,如总和、平均值、最小值、最大值等。这些度量结果可以直接用于分析数据中的特定指标。
常用类型:
Sum:计算字段的总和。
Avg:计算字段的平均值。
Min/Max:查找字段的最小值和最大值。
Stats:提供包括count、sum、min、max和avg在内的多种统计信息。
应用场景举例:销售数据的总销售额和平均订单金额分析、用户行为的平均访问时长和最大访问深度分析等。
Bucket Aggregations(桶聚合)
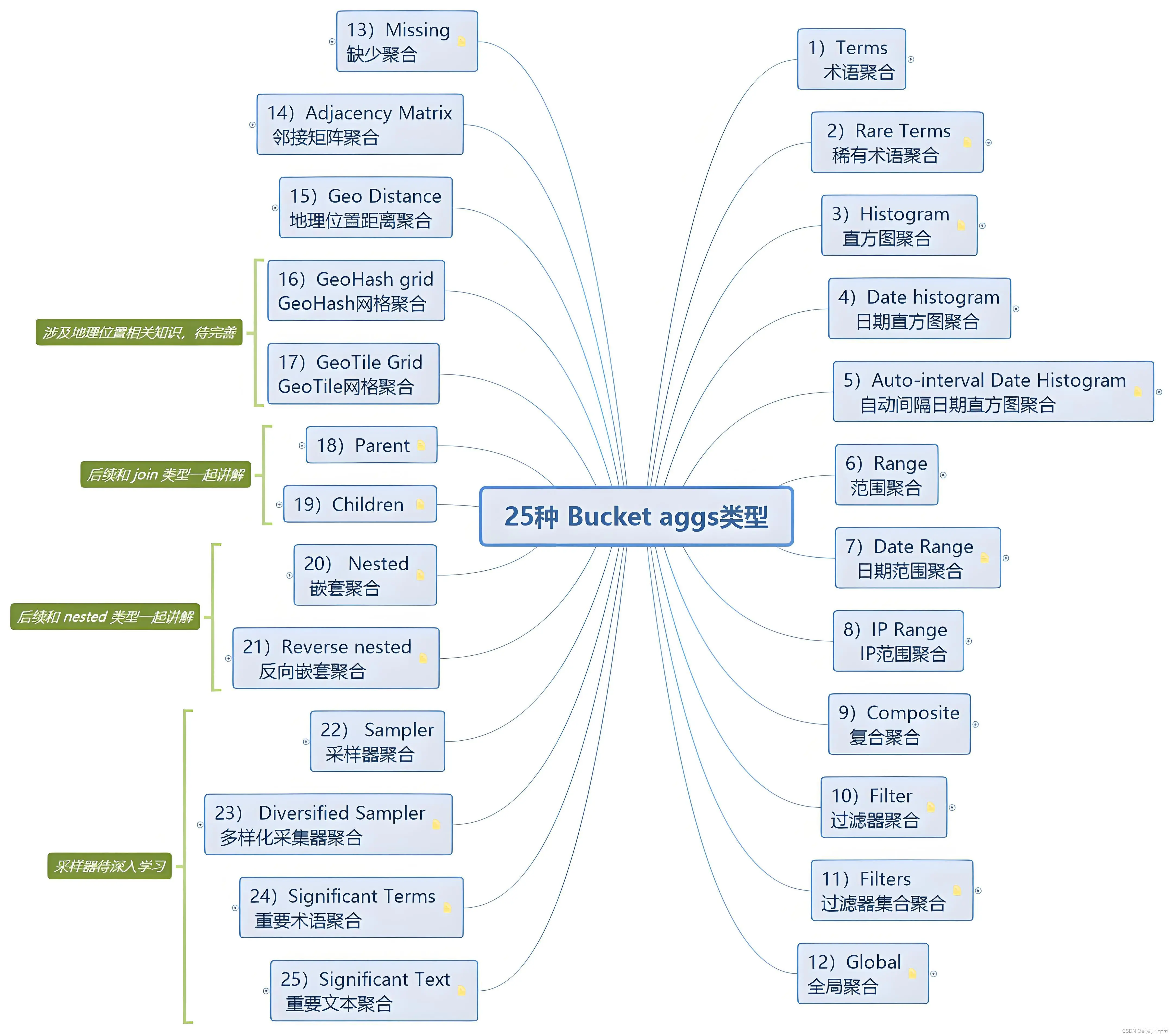
概述:桶聚合类似于SQL中的GROUP BY操作,它将文档分组到不同的桶中,并对每个桶中的文档进行聚合计算。桶聚合可以基于字段值、时间间隔或数值范围进行分组。
常用类型:
Terms:根据字段的值将文档分配到不同的桶中,常用于分析文本字段的不同取值及其分布情况。
Date Histogram:根据日期字段的值,将文档按时间间隔(如天、周、月等)分组到桶中,适用于时间序列数据的分析。
Range:根据定义的范围将文档分配到不同的桶中,适用于分析数值字段在特定范围内的文档数量。
应用场景举例:按作者分组的博客文章数量统计、按月份统计的销售记录分析、按价格区间统计的产品数量等。
Pipeline Aggregations(管道聚合)
概述:管道聚合以其他聚合的结果作为输入,并对其进行进一步的处理或计算。这种聚合类型允许用户对聚合结果进行复杂的转换和分析。
常用类型:
Avg Bucket:计算每个桶的平均值,通常用于对分组数据进行平均值分析。
Sum Bucket:计算每个桶的总和,适用于对分组数据进行求和操作。
Max/Min Bucket:找出所有桶中的最大值或最小值,有助于识别分组数据中的极端情况。
应用场景举例:在按月份统计的销售记录中找出平均销售额最高的月份、分析不同价格区间产品的销售额总和等。

三、聚合查询应用
与查询语句结合:聚合查询通常与查询语句结合使用,可以在满足特定条件的文档集合上进行聚合操作。通过查询语句过滤出符合条件的文档集合,然后对这些文档进行聚合分析,可以得到更加准确和有用的结果。嵌套聚合:Elasticsearch支持嵌套聚合,即在一个聚合内部可以包含其他聚合。通过嵌套聚合,用户可以构建复杂的查询和分析逻辑,满足各种复杂的数据分析和统计需求。
四、doc_values 与 fielddata
在 Elasticsearch 中,聚合操作主要依赖于 doc_values 或 fielddata 来进行。用于聚合的字段可以是精确值字段(如keyword类型)或分词字段(如text类型)。这两类字段在聚合查询时的处理方式有所不同。
exact value字段
精确值字段通常用于存储不需要分词和全文搜索的数据,如用户ID、产品类别等。对于这类字段,Elasticsearch默认使用doc_values数据结构来支持高效的聚合、排序和统计操作。doc_values以列式存储格式在磁盘上保存字段值,并在需要时加载到JVM堆内存中进行计算。由于doc_values直接在磁盘上操作,因此性能通常很高,且适用于大规模数据集。
分词字段
分词字段(如text类型)通常用于存储需要分词和全文搜索的文本数据。对于这类字段,Elasticsearch默认不启用fielddata,因为fielddata会将字段值加载到堆内存中,导致在处理大数据集时容易引发内存溢出(OOM)问题。然而,有时我们确实需要在分词字段上执行聚合操作(例如,按产品名称分组统计销售数据)。在这种情况下,有几种解决方案可供选择:
使用.keyword子字段:在定义字段映射时,可以为text字段添加一个.keyword子字段。这个子字段不会被分词器处理,而是作为一个完整的字符串存储。通过使用该子字段进行聚合操作,可以获得更准确的结果,同时避免启用fielddata带来的性能问题。
更新映射启用fielddata:如果你确实需要在text字段上启用fielddata(虽然不推荐),可以通过更新字段映射来实现。但请注意,这样做可能会导致内存消耗过大,特别是在处理大数据集时。因此,在启用fielddata之前,请务必评估其对系统性能的影响,并考虑其他可能的解决方案。
doc_values与fielddata的性能权衡
在Elasticsearch中,聚合操作主要依赖于doc_values或fielddata来访问文档中的字段值。了解这两种数据结构的差异和适用场景,有助于优化聚合查询的性能。
Doc Values
优势:适用于精确值字段和数字类型字段,提供高效的聚合、排序和统计操作。由于直接在磁盘上操作,性能通常很高。适用场景:大多数精确值字段默认启用doc_values,无需额外配置。
Fielddata
优势:支持复杂的文本分析和聚合操作,允许对分词字段进行聚合查询。劣势:需要占用大量堆内存资源,处理大数据集时容易引发OOM问题。默认情况下,Elasticsearch禁用了对text字段的fielddata访问。适用场景:在确实需要在text字段上执行聚合查询,且系统资源允许的情况下,可以考虑启用fielddata。但请务必谨慎评估其对性能的影响。
总之, 对于精确值字段,利用doc_values可以获得高效且准确的聚合结果;对于分词字段,通过添加.keyword子字段或使用其他解决方案来避免启用fielddata带来的性能问题。通过合理配置字段映射和选择聚合查询策略,可以充分发挥Elasticsearch在数据分析领域的强大功能。
五、multi-fields(多字段)
描述:在Elasticsearch中,一个字段可以被定义为multi-fields类型,这意味着同一份数据可以被索引为不同类型的字段。通过为text字段添加keyword子字段,用户可以在保留全文搜索功能的同时,为精确值搜索、排序和聚合操作提供支持。使用建议:对于需要进行聚合操作的text字段,强烈建议在索引设计阶段添加keyword子字段,并使用该子字段进行聚合操作。这样可以避免在text字段上启用Fielddata带来的性能问题,并提高聚合查询的效率和准确性。
六、聚合查询示例
Terms 分桶聚合
示例场景:统计每个作者写了多少篇文章,并按文章数量降序排序。
查询语句:
POST /blog/_search
{
"size": 0,
"aggs": {
"articles_per_author": {
"terms": {
"field": "author.keyword",
"size": 10,
"order": { "_count": "desc" }
}
}
}
}
Date Histogram 直方图聚合
示例场景:分析每月的销售记录数量。
查询语句:
POST /sales/_search
{
"size": 0,
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "sale_date",
"calendar_interval": "month",
"format": "yyyy-MM"
}
}
}
}
Range 范围聚合
示例场景:分析不同价格区间的产品数量。
查询语句:
post /products/_search
{
"size": 0,
"aggs": {
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{ "to": 100 },
{ "from": 100, "to": 500 },
{ "from": 500 }
]
}
}
}
}
Nested 嵌套聚合
示例场景:分析每个订单中不同产品的平均价格。
假设数据:一个订单可以有多个产品,每个产品都有一个价格。
查询语句:
POST /orders/_search
{
"size": 0,
"aggs": {
"orders": {
"nested": {
"path": "products"
},
"aggs": {
"avg_price_per_order": {
"avg": {
"field": "products.price"
}
}
}
}
}
}
Pipeline 管道聚合
示例场景:在按月份统计的销售记录中找出销售额最高的月份,并计算该月的平均销售额。
查询语句:
POST /sales/_search
{
"size": 0,
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "sale_date",
"calendar_interval": "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "amount"
}
},
"top_sales_month": {
"top_hits": {
"sort": [
{ "total_sales": { "order": "desc" } }
],
"size": 1
}
},
"avg_sales_top_month": {
"avg_bucket": {
"buckets_path": "total_sales"
}
}
}
}
}
}
Derivative(导数聚合)
示例场景:分析销售数据的变化趋势,计算销售额的日增长率。
查询语句:
POST /sales/_search
{
"size": 0,
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "sale_date",
"calendar_interval": "day"
},
"aggs": {
"total_sales": {
"sum": {
"field": "amount"
}
},
"sales_derivative": {
"derivative": {
"buckets_path": "total_sales"
}
}
}
}
}
}
我们首先按天对销售数据进行分组,并计算每天的总销售额。然后,我们使用derivative管道聚合来计算销售额的日增长率。
Cumulative Sum(累计和聚合)
示例场景:计算销售数据的累计和,展示销售额的累计增长情况。
查询语句:
POST /sales/_search
{
"size": 0,
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "sale_date",
"calendar_interval": "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "amount"
}
},
"cumulative_sales": {
"cumulative_sum": {
"buckets_path": "total_sales"
}
}
}
}
}
}
我们按月对销售数据进行分组,并计算每月的总销售额。然后,我们使用cumulative_sum管道聚合来计算销售额的累计和。
Moving Average(移动平均聚合)
示例场景:分析销售数据的移动平均线,以平滑数据波动并识别趋势。
查询语句:
POST /sales/_search
{
"size": 0,
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "sale_date",
"calendar_interval": "day"
},
"aggs": {
"total_sales": {
"sum": {
"field": "amount"
}
},
"moving_avg_sales": {
"moving_avg": {
"buckets_path": "total_sales",
"window": 7 // 计算7天的移动平均
}
}
}
}
}
}
我们按天对销售数据进行分组,并计算每天的总销售额。然后,我们使用moving_avg管道聚合来计算7天的移动平均销售额。
Bucket Script(桶脚本聚合)
示例场景:计算每个销售桶中不同产品的销售额占比。
查询语句(假设每个销售桶中按产品分组):
POST /sales/_search
{
"size": 0,
"aggs": {
"sales_by_product": {
"terms": {
"field": "product.keyword"
},
"aggs": {
"total_sales": {
"sum": {
"field": "amount"
}
},
"sales_percentage": {
"bucket_script": {
"buckets_path": {
"thisSales": "total_sales",
"totalSales": "_sum" // 假设外层还有一个求和聚合来计算总销售额
},
"script": "params.thisSales / params.totalSales * 100"
}
}
}
},
"total_sales": {
"sum": {
"field": "amount"
}
}
}
}
bucket_script引用了两个buckets_path,其中_sum是Elasticsearch中的一个特殊变量,它引用了当前聚合上下文中所有桶的总和。这个示例假设外层还有一个求和聚合来计算所有产品的销售总额。然后,我们计算每个产品销售额占总销售额的百分比。
Filters 过滤器聚合
示例场景:分析不同分类产品的销售情况。
查询语句:
POST /products/_search
{
"size": 0,
"aggs": {
"sales_by_category": {
"filters": {
"filters": {
"electronics": { "term": { "category": "electronics" }},
"books": { "term": { "category": "books" }},
"other": { "match_all": { } }
}
},
"aggs": {
"total_sales": {
"sum": {
"field": "price"
}
}
}
}
}
}
我们使用了filters聚合来按产品分类过滤文档,并在每个过滤器内部使用sum聚合来计算总销售额。
七、聚合排序
基于count排序:通过聚合的_count字段对桶进行排序,可以展示销售量最高或最低的产品、访问量最大的网页等。基于key排序:对于Terms聚合,可以使用_key字段对桶的键(即分组字段的值)进行排序。这有助于按字母顺序或数值顺序展示分组数据。
八、优化建议
避免不必要的大聚合:对于大数据集,执行复杂的聚合操作可能会消耗大量计算资源并影响性能。因此,建议根据实际需求合理设计聚合查询,避免执行不必要的大聚合操作。缓存聚合结果:对于频繁执行的聚合查询,可以考虑使用Elasticsearch的缓存功能来缓存聚合结果。这样可以减少重复计算的开销并提高查询性能。合理设计索引和映射:根据查询需求和数据特点,合理设计索引和映射是优化聚合查询性能的关键。例如,选择适当的字段类型和属性、合理设置分片数和副本数等。监控和分析:定期监控和分析Elasticsearch的性能指标和日志可以帮助及时发现和解决潜在的性能问题。通过监控聚合查询的执行时间、内存使用情况等指标,可以评估聚合查询的性能并进行相应的优化调整。
关注以下公众号获取更多深度内容,纯干货 !

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。