Java中的Stack(栈)(如果想知道Java中有关Stack的知识点,那么只看这一篇就足够了!)
秋刀鱼不做梦 2024-07-16 15:05:02 阅读 100
前言:栈(Stack)是一种基础且重要的数据结构,以其后进先出(LIFO, Last In First Out)的特性广泛应用于计算机科学和编程中。
✨✨✨这里是秋刀鱼不做梦的BLOG
✨✨✨想要了解更多内容可以访问我的主页秋刀鱼不做梦-CSDN博客

先让我们看一下本文大致的讲解内容:
目录
1.栈的初识
2.栈的自我实现
(1)数组实现:
(2)链表实现
3.栈中常用API
4.栈的应用场景
5.总结
1.栈的初识
在开始学习使用栈之前,先让我们来了解一下什么是栈:
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
栈的主要特性包括:
后进先出(LIFO):最新压入栈的数据最先被弹出。栈顶操作:所有的插入(push)和删除(pop)操作都只能在栈顶进行。
如果使用我们日常生活中的案例来解释的话,就如同子弹弹夹,先装入的子弹后被打出,后装入的子弹,先被打出:
将其转换为编程语言图像(如图):
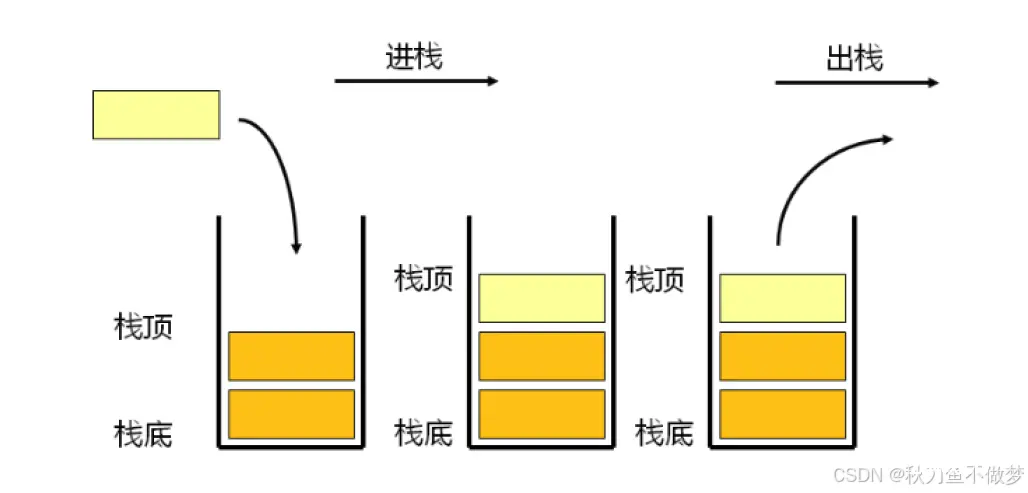
其中:
——压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
——出栈:栈的删除操作叫做出栈。出数据在栈顶。
通过上述的讲解,这样我们就大致的了解了什么是栈(Stack)了!
2.栈的自我实现
学习完了什么是栈之后,然我们试试能不能使用已有的知识体系来实现栈,在Java中自我实现栈的方式大致有两种:使用数组实现与使用链表实现。
(1)数组实现:
<code>public class ArrayStack {
public int[] stack; // 用于存储栈元素的数组
public int top; // 栈顶索引
public ArrayStack(int size) {
stack = new int[size]; // 初始化数组大小
top = -1; // 初始化栈顶索引为-1,表示栈为空
}
// 将元素压入栈顶
public void push(int value) {
if (top == stack.length - 1) {
throw new StackOverflowError("Stack is full"); // 如果栈已满,抛出异常
}
stack[++top] = value; // 将元素压入栈顶,并更新栈顶索引
}
// 弹出栈顶元素
public int pop() {
if (top == -1) {
throw new EmptyStackException(); // 如果栈为空,抛出异常
}
return stack[top--]; // 返回栈顶元素,并更新栈顶索引
}
// 返回栈顶元素但不弹出
public int peek() {
if (top == -1) {
throw new EmptyStackException(); // 如果栈为空,抛出异常
}
return stack[top]; // 返回栈顶元素
}
// 检查栈是否为空
public boolean isEmpty() {
return top == -1; // 如果栈顶索引为-1,表示栈为空
}
}
现在我们再回顾一下上述代码的逻辑:
1. 首先先定义了一个基于数组实现的栈类 ArrayStack。它包含一个用于存储栈元素的数组 stack 和一个指示栈顶位置的变量 top。
2. 然后使用构造方法 ArrayStack(int size) 来初始化栈的大小,并将 top 设置为 -1。
3. push(int value) 方法将元素压入栈顶,如果栈满则抛出 StackOverflowError。pop() 方法弹出栈顶元素,如果栈为空则抛出 EmptyStackException。peek() 方法返回栈顶元素但不弹出,如果栈为空则抛出 EmptyStackException。isEmpty() 方法检查栈是否为空。
(2)链表实现
public class DoublyLinkedListStack {
public Node head; // 链表头节点
public Node tail; // 链表尾节点
// 定义节点类
private static class Node {
int value; // 节点值
Node next; // 指向下一个节点的指针
Node prev; // 指向上一个节点的指针
Node(int value) {
this.value = value; // 初始化节点值
this.next = null; // 初始化下一个节点指针为空
this.prev = null; // 初始化前一个节点指针为空
}
}
public DoublyLinkedListStack() {
head = null; // 初始化头节点为空
tail = null; // 初始化尾节点为空
}
// 将元素压入栈顶
public void push(int value) {
Node newNode = new Node(value); // 创建新节点
if (tail == null) {
head = tail = newNode; // 如果链表为空,头尾节点都指向新节点
} else {
tail.next = newNode; // 将新节点连接到链表尾部
newNode.prev = tail; // 新节点的前驱指向当前尾节点
tail = newNode; // 更新尾节点为新节点
}
}
// 弹出栈顶元素
public int pop() {
if (tail == null) {
throw new EmptyStackException(); // 如果栈为空,抛出异常
}
int value = tail.value; // 获取尾节点的值
if (tail.prev == null) {
head = tail = null; // 如果只有一个元素,清空链表
} else {
tail = tail.prev; // 更新尾节点为前驱节点
tail.next = null; // 断开新尾节点的next指针
}
return value; // 返回弹出的值
}
// 返回栈顶元素但不弹出
public int peek() {
if (tail == null) {
throw new EmptyStackException(); // 如果栈为空,抛出异常
}
return tail.value; // 返回尾节点的值
}
// 检查栈是否为空
public boolean isEmpty() {
return tail == null; // 如果尾节点为空,栈为空
}
}
现在我们再回顾一下上述代码的逻辑:
首先我们先定义了一个基于双向链表实现的栈类 DoublyLinkedListStack。它包含头节点和尾节点,使用内部的 Node 类表示每个节点。然后我们实现了一下主要的方法包括:
push(int value):将新元素压入栈顶。
pop():弹出栈顶元素,如果栈为空则抛出异常。
peek():返回栈顶元素但不弹出,若栈为空则抛出异常。
isEmpty():检查栈是否为空,返回布尔值。
这样我们就用现有的知识体现来实现了栈(Stack)了!
3.栈中常用API
学习完了自我实现栈(Stack)之后,现在让我们看看Java中自带的Stack如何使用吧:
栈中常用的方法主要包括以下几种:
push(E item):将元素压入栈顶。pop():移除并返回栈顶元素。peek():返回栈顶元素但不移除。isEmpty():检查栈是否为空。
现在让我们使用一个实例来进行讲解:
import java.util.Stack;
public class StackExample {
public static void main(String[] args) {
//创建一个栈
Stack<Integer> stack = new Stack<>();
// 压入栈顶
stack.push(1);
stack.push(2);
stack.push(3);
// 查看栈顶元素
System.out.println("栈顶元素: " + stack.peek());
// 弹出栈顶元素
System.out.println("弹出栈顶元素: " + stack.pop());
// 查看栈顶元素
System.out.println("栈顶元素: " + stack.peek());
// 检查栈是否为空
System.out.println("栈是否为空: " + stack.isEmpty());
}
}
——这样我们就大致的了解了在Java中如何去操作一个创建出来的栈了!
4.栈的应用场景
学习完栈之后,读者可能会发出疑问,栈到底有什么用处呢?栈在实际应用中有许多场景,下面列举几个典型的应用:
表达式求值:如中缀表达式转后缀表达式的计算。函数调用:栈用于保存函数调用过程中的局部变量和返回地址。括号匹配:用于检查括号是否成对匹配。浏览器的前进后退:使用栈保存历史页面,以便用户前进和后退。深度优先搜索(DFS):在图或树的遍历中使用。
这里我们只举出第一个(表达式求值)来讲解(其他读者如果有兴趣进一步学习,可以自行查找学习!)
表达式求值即为:中缀表达式转换为后缀表达式(也称逆波兰表达式),以下为百度的解释:

其作用主要体现在以下几个方面:
简化计算:后缀表达式不需要括号,操作符和操作数的顺序明确,计算时更简单。
便于计算机处理:计算机处理后缀表达式更高效,避免了运算优先级的复杂性。
支持堆栈算法:后缀表达式可以直接使用栈来进行求值,适合实现逆波兰表示法。
提高表达式解析速度:在编译器和解释器中,后缀表达式有助于快速解析和执行表达式。
了解完了什么是逆波兰表达式之后,我们使用一道例题来进行讲解:
题目链接:----->. - 力扣(LeetCode)
解题的大致思路为:
<code>import java.util.Stack;
public class PostfixEvaluation {
public static int evaluate(String expression) {
Stack<Integer> stack = new Stack<>(); // 创建一个栈用于存储操作数
// 遍历后缀表达式中的每个字符
for (char c : expression.toCharArray()) {
if (Character.isDigit(c)) {
// 如果是数字,将其压入栈中
stack.push(c - '0');
} else {
// 如果是操作符,从栈中弹出两个操作数
int b = stack.pop(); // 弹出栈顶元素作为右操作数
int a = stack.pop(); // 弹出下一个元素作为左操作数
// 根据操作符进行计算,并将结果压入栈中
switch (c) {
case '+':
stack.push(a + b);
break;
case '-':
stack.push(a - b);
break;
case '*':
stack.push(a * b);
break;
case '/':
stack.push(a / b);
break;
}
}
}
return stack.pop(); // 返回栈顶元素,即最终结果
}
public static void main(String[] args) {
String expression = "231*+9-"; // 后缀表达式示例
System.out.println("后缀表达式求值结果: " + evaluate(expression)); // 输出结果
}
}
这样我们就大致的理解了栈的用处了!
5.总结
栈是一种基础且重要的数据结构,它的后进先出特性在许多应用场景中发挥了重要作用。在Java中,栈可以通过数组和链表实现,java.util.Stack类也提供了现成的栈实现。
通过理解栈的基本概念和常用方法,以及掌握如何使用双向链表自我实现栈,我们可以在实际编程中更加灵活地运用这一数据结构。栈在表达式求值、函数调用、括号匹配、浏览器前进后退和深度优先搜索等方面都有广泛的应用,熟练掌握栈的使用将极大提高我们的编程能力。
以上就是本篇文章的全部内容了~~~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。