数据分析神器Pandas快速入门1序列(Series)简介
pythontesting 2024-06-27 11:39:00 阅读 91
1序列简介
1.1 Pandas简介
Pandas(https://pandas.pydata.org/ Panel Data and Series )是一个开源的库,主要是为了方便和直观地处理关系型或标记型数据。它提供了各种数据结构和操作,用于处理数字数据和时间序列。它建立在NumPy库之上的。
Pandas是Python数据分析领域的必备库之一,它提供了一系列易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。
Pandas最初是由Wes McKinney在2008年开发的,当时他在AQR资本管理公司工作。他说服了AQR允许他开放Pandas的源代码。另一位AQR员工Chang She在2012年加入,成为该库的第二个主要贡献者。随着时间的推移,许多版本的pandas已经发布。截至2024年6月26日,Pandas的最新版本是2.2.2,于2024年6月20日发布。
Pandas的主要功能包括:
- 数据导入和导出:Pandas可以轻松地从各种数据源中导入数据,如CSV文件、Excel文件、SQL数据库等,并可以将数据导出到各种格式中。
- 数据清理:Pandas提供了一系列数据清理工具,可以处理缺失值、重复值、异常值等。
- 数据分析:Pandas提供了一系列数据分析工具,可以进行数据统计、分组分析、时间序列分析等。
- 数据可视化:Pandas提供了一系列数据可视化工具,可以快速生成各种图表和图形。
Pandas的核心数据结构是:
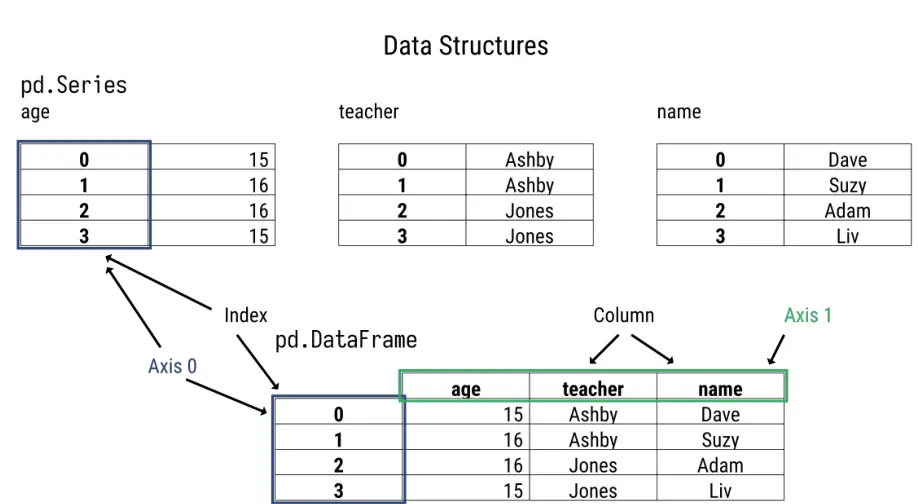
- Series(序列):类似于一维数组或列表,是由一组数据以及与之相关的数据标签(索引)构成。
- DataFrame(数据帧):类似于二维表格,由多个Series组成,具有行和列索引。
Series和DataFrame都有共同的特征。例如,它们都有索引,我们需要通过研究索引来了解pandas是如何工作的。DataFrame实际上是Series的行或列的集合,因此我们必须先对Series进行全面研究。

1.2 Pandas的优势
- 处理和分析数据的速度和效率。
- 可以加载来自不同文件对象的数据。
- 易于处理浮点和非浮点数据中的缺失数据(以NaN表示)。
- 规模可变性:可以从DataFrame和更高维度的对象中插入和删除列。
- 数据集的合并和连接。
- 对数据集进行灵活的重塑和透视
- 提供时间序列功能。
- 强大的分组功能,用于对数据集进行分割-应用-合并的操作。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
1.3 Series简介

序列是一维标签数组,能够容纳任何类型的数据(整数、字符串、浮点、python对象等。轴的标签统称为索引。序列只不过是excel表格中的一个行或列。标签不需要是唯一的,但必须是哈希类型。序列同时支持整数和基于标签的索引,并提供了大量的方法来执行索引操作。
序列通过从现有的存储中加载数据集来创建,可以是SQL数据库、CSV文件、Excel文件,也可从列表、字典和标量值中创建。
>>> import pandas as pd
>>> songs = pd.Series([145, 142, 38, 13], name='counts')
>>> songs
0 145
1 142
2 38
3 13
Name: counts, dtype: int64
当解释器打印序列时,pandas会根据当前终端的大小对其进行格式化。数列是一维的。然而看起来像是二维的。最左边的一列是索引,包含索引的条目。索引不是值的一部分。索引的通用名称是轴,索引的值-0、1、2、3 称为轴标签。数据145、142、38和13也称为序列值。pandas中的二维结构--DataFrame--有两个坐标轴,一个用于行,另一个用于列。
输出中最右边的一列包含数列的值-145、142、38 和 13。在本例中,它们是整数(控制台表示为 dtype: int64,dtype 表示数据类型,int64 表示 64 位整数),但一般来说,数列的值可以是字符串、浮点数、布尔值或任意 Python 对象。为了获得最佳速度(并充分利用矢量化操作),这些值应具有相同的类型,但这并不是必须的。

查看序列(或数据帧)的索引:
>>> songs.index
RangeIndex(start=0, stop=4, step=1)
索引的默认值是0开始递增的整数。
索引也可以是基于字符串的,在这种情况下,pandas会指出索引的数据类型是object(而不是字符串):
>>> songs2 = pd.Series ([145, 142, 38, 13], name='counts ', index=['Paul', 'John ', 'George ', 'Ringo '])
>>> songs2
Paul 145
John 142
George 38
Ringo 13
Name: counts , dtype: int64
>>> songs2.index
Index(['Paul', 'John ', 'George ', 'Ringo '], dtype='object')
打印Series时看到的 dtype 是值的类型,而不是索引的类型。尽管这看起来是二维的,但索引并不是值的一部分:当我们检查索引属性时,会发现其 dtype是object。
序列的实际数据(或值)不一定是数字或同质的。我们可以在序列中插入Python对象:
>>> class Foo:
... pass
...
>>> ringo = pd.Series(
... ['Richard', 'Starkey', 13, Foo()],
... name='ringo')
>>>
>>> ringo
0 Richard
1 Starkey
2 13
3 <__main__.Foo object at 0x7f60bbf26590>
Name: ringo, dtype: object
上例Series 的dtype-datatype是object(指Python对象)
object数据类型也用于具有字符串值的系列。此外object数据类型还用于具有异构或混合类型的值。如果序列中只有数值数据,就不希望将其存储为Python对象,而应该存储为int64或float64,这样就可以进行矢量化数值运算。
如果你有时间数据,并且是对象类型,那么你可能用字符串来表示日期。使用字符串而不是日期类型是不好的,因为不能进行日期操作。
1.3.1 NaN
当pandas确定一个数列包含数值,但找不到一个数字来表示条目时,它将使用 NaN。该值代表"非数字(Not A Number)",通常在算术运算中被忽略。(类似于 SQL 中的 NULL)。
>>> import numpy as np
>>> nan_series = pd.Series([2, np.nan], index=['Ono', 'Clapton'])
>>> nan_series
Ono 2.0
Clapton NaN
dtype: float64
>>> nan_series.count()
1
>>> nan_series.size
2
此序列的类型是float64,而不是int64!因为float64支持NaN,而int64不支持。如果从CSV文件加载数据,数值列的空值将变为NaN。稍后,.fillna 和 .dropna 等方法将解释如何处理 NaN。在本书中,None、NaN、nan、
int64类型不支持缺失数据。许多人认为这是pandas的缺陷。从pandas0.24开始,有了对另一种整数类型的可选支持,这种类型可以保存缺失值,如下所示
>>> nan_series2 = pd.Series([2, None],
... index=['Ono', 'Clapton'],
... dtype='Int64')
>>> nan_series2
Ono 2
Clapton <NA>
dtype: Int64
>>> nan_series.astype('Int64')
Ono 2
Clapton <NA>
dtype: Int64
1.3.2 Series与NumPy array
Series与NumPy array数组类似。两者都有索引操作和一些共同的方法:
>>> import numpy as np
>>> numpy_ser = np.array([145, 142, 38, 13])
>>> songs3[1]
142
>>> numpy_ser[1]
142
>>> songs3.mean()
84.5
>>> numpy_ser.mean()
84.5
它们都有布尔数组的概念。布尔数组是与您在处理的数列具有相同索引且具有布尔值的数列,它可以用作过滤项的掩码。普通的Python列表不支持此操作,比如将列表插入索引操作中。
>>> mask = songs3 > songs3.median()
>>> mask
Paul True
John True
George False
Ringo False
Name: counts , dtype: bool
>>> songs3[mask]
Paul 145
John 142
Name: counts , dtype: int64
>>> numpy_ser[numpy_ser > np.median(numpy_ser)]
array([145, 142])
一旦有了掩码,我们就可以将其用作过滤器。我们只需将掩码传递到索引操作中即可。如果掩码在给定索引中的值为 True,则保留该值。否则,该值将被删除。上面的掩码表示值高于系列中值的位置。
NumPy也有布尔数组过滤功能,但缺少数组的median方法。相反NumPy命名空间中提供了median函数。

1.3.3 分类数据
在加载数据时,可以指出数据是分类的。如果数据仅限于几个值,我们可能希望使用分类数据。分类值有以下几个好处
- 比字符串占用更少内存
- 提高性能
- 可以排序
- 可以对类别执行操作
- 对值执行成员资格
分类并不局限于字符串;我们还可以将数字或日期时间值转换为分类数据。要创建类别,我们可以在 Series 构造函数中传递 dtype="类别category"。或者,我们也可以在序列上调用.astype("category") 方法。
>>> s = pd.Series(['m', 'l', 'xs', 's', 'xl'], dtype='category')
>>> s
0 m
1 l
2 xs
3 s
4 xl
dtype: category
Categories (5, object): ['l', 'm', 's', 'xl', 'xs']
>>> s.cat.ordered
False
如果该系列表示尺码,则会有自然排序,即小号小于中号。默认情况下,类别没有排序。要将非分类系列转换为有序类别,我们可以使用 CategoricalDtype构造函数和适当的参数创建一个类型。然后,我们将此类型传入 .astype 方法:
>>> s2 = pd.Series(['m', 'l', 'xs', 's', 'xl'])
>>> size_type = pd.api.types.CategoricalDtype(
... categories=['s','m','l'], ordered=True)
>>> s3 = s2.astype(size_type)
>>> s3
0 m
1 l
2 NaN
3 s
4 NaN
dtype: category
Categories (3, object): ['s' < 'm' < 'l']
在本例中,我们将类别限定为"s"、"m"和"l",但数据中的值不在这些类别中。将数据转换为类别类型后,这些额外的值将被替换为 NaN。如果我们有有序的类别,就可以对它们进行比较:
>>> s3 > 's'
0 True
1 True
2 False
3 False
4 False
dtype: bool
前面的示例从现有的非分类数据中创建了一个新的系列。我们也可以为分类数据添加排序信息。我们需确保指定类别的所有成员否则pandas将抛出 ValueError。
>>> s.cat.reorder_categories(['xs','s','m','l', 'xl'],
... ordered=True)
0 m
1 l
2 xs
3 s
4 xl
dtype: category
Categories (5, object): ['xs' < 's' < 'm' < 'l' < 'xl']
>>> s3.str.upper()
0 M
1 L
2 NaN
3 S
4 NaN
dtype: object
字符串和日期时间序列有str和dt属性,允许我们执行该类型特有的常用操作。如果我们将这些类型转换为分类类型,仍可使用 str 或 dt 属性:

1.3.3序列小结:
序列是一种一维数据结构。它可以保存数值数据、时间数据、字符串或任意的Python对象。如果您处理的是数值数据,使用 pandas而不是Python list会让您受益匪浅。Pandas速度更快,内存消耗更少,而且内置的方法对操作数据非常有用。此外,索引抽象允许通过位置或标签访问值。系列也可以有空值,与NumPy数组有一些相似之处。它是pandas的主要工作工具;掌握它将带来丰厚的回报。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。