深入理解微服务中的负载均衡算法与配置策略
cnblogs 2024-08-14 10:09:00 阅读 55
今天,我们主要补充了上一章关于微服务通信的内容,并深入探讨了负载均衡算法的重要性。我们首先详细讨论了Ribbon默认使用的负载均衡算法。尽管在本地测试时可能会观察到轮询的效果,但简单依赖这种表面的观察是不够的。在真实的生产环境中,特别是在跨多个数据中心部署时,负载均衡策略的选择需要更加深入的理解和分析。
上一期我们详细探讨了微服务之间的通信,特别是介绍了如何集成Ribbon。简单来说,通过使用resttemplate类进行RPC调用时,我们内部增加了一个拦截器来实现负载均衡。然而,我们并未深入讨论具体的负载均衡算法。因此,本章节的重点是介绍如何从多个副本中选择合适的节点进行服务调用。这将帮助大家更好地理解在微服务架构中如何有效地实现负载均衡。
好的,今天我们依旧会涉及源码,但希望大家能把注意力集中在理念层面,而不是深究每个具体的过程调用。无需纠结于代码的具体行数,因为重要的是理解整体架构和流程,这样才能更好地掌握主题的实质。
负载均衡算法
我们首先来探讨一下默认情况下Ribbon使用的负载均衡算法。有些人可能会说它使用轮询算法,因为在本地测试时,我们经常会看到轮询的效果。然而,简单地依赖这种表面的观察来回答面试题是有风险的。实际上,忽略了深入理解源代码可能会导致严重的误解。
尽管实践是增长知识的一部分,但是在真实的生产环境中,尤其是跨多个数据中心部署的情况下,我们无法简单地将问题简化为本地集群的测试环境。
获取服务器ip
我们接着上一篇内容,讨论如何选择服务器的步骤如下复述:
<code> public <T> T execute(String serviceId, LoadBalancerRequest<T> request, Object hint)
throws IOException {
ILoadBalancer loadBalancer = getLoadBalancer(serviceId);
Server server = getServer(loadBalancer, hint);
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
}
RibbonServer ribbonServer = new RibbonServer(serviceId, server,
isSecure(server, serviceId),
serverIntrospector(serviceId).getMetadata(server));
return execute(serviceId, ribbonServer, request);
}
获取负载均衡器——ZoneAwareLoadBalancer
我们来看看getServer方法,突然间出现这么多负载均衡器,应该怎么处理呢?这时候最好的方法就是查看自动配置,看看哪些被注入进来了。
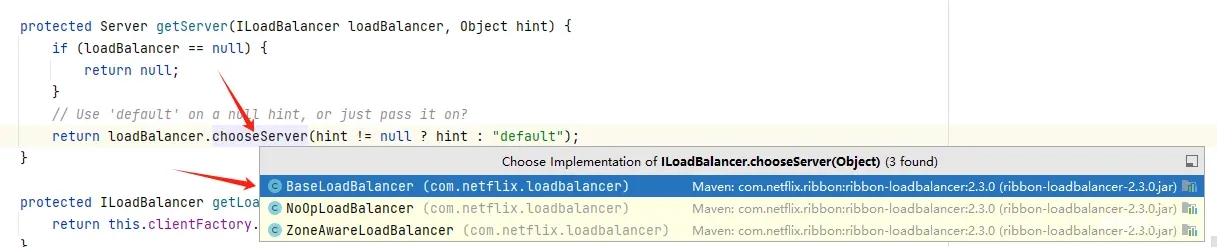
中间步骤大家就不用再找了,我已经事先找好了,就在这里:
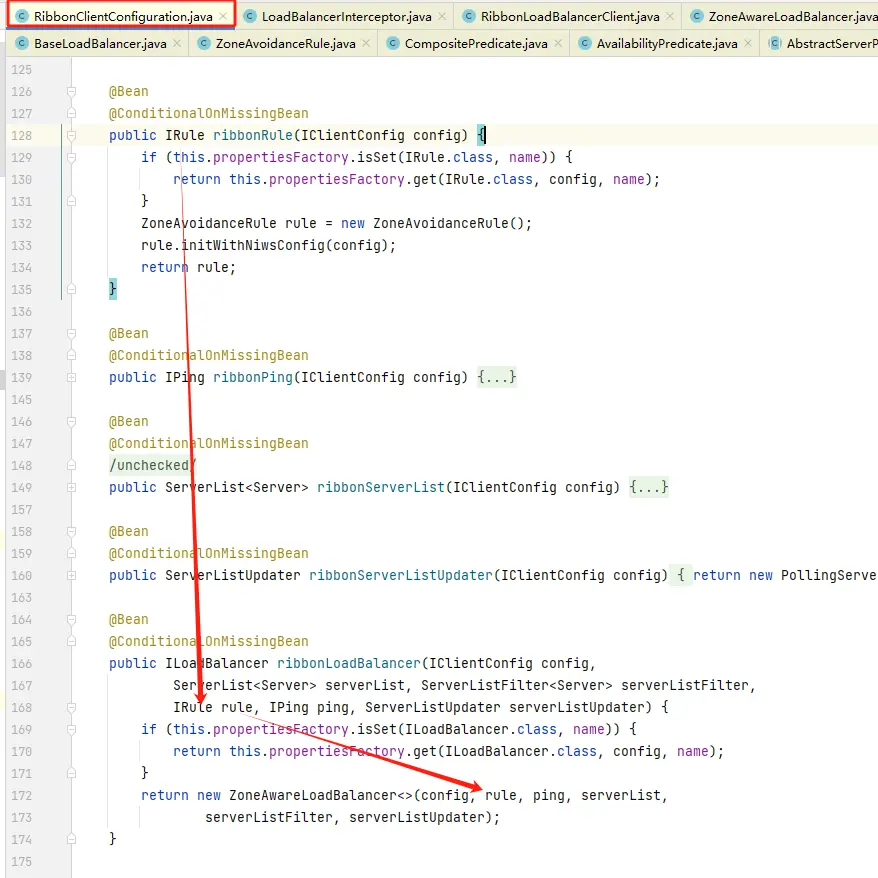
这张图包含两个关键信息:首先是注入了一个IRule规则,其次是将该IRule规则应用到了ZoneAwareLoadBalancer负载均衡器中。好的,现在我们清楚了接下来的步骤。接下来我们继续查看
<code> public Server chooseServer(Object key) {
if (!ENABLED.get() || getLoadBalancerStats().getAvailableZones().size() <= 1) {
logger.debug("Zone aware logic disabled or there is only one zone");
return super.chooseServer(key);
}
Server server = null;
try {
//省略多余代码
Set<String> availableZones = ZoneAvoidanceRule.getAvailableZones(zoneSnapshot, triggeringLoad.get(), triggeringBlackoutPercentage.get());
logger.debug("Available zones: {}", availableZones);
if (availableZones != null && availableZones.size() < zoneSnapshot.keySet().size()) {
String zone = ZoneAvoidanceRule.randomChooseZone(zoneSnapshot, availableZones);
logger.debug("Zone chosen: {}", zone);
if (zone != null) {
BaseLoadBalancer zoneLoadBalancer = getLoadBalancer(zone);
server = zoneLoadBalancer.chooseServer(key);
}
}
} catch (Exception e) {
logger.error("Error choosing server using zone aware logic for load balancer={}", name, e);
}
//省略多余代码
}
如果是在我们本地环境,通常会执行第一个if分支;但如果是在生产环境并配置了多个区域,那么会执行下面的分支。让我们一起来看看。
无配置区域情况
让我们来看看第一种情况,即如果没有区域或者只有一个区域,负载均衡规则是如何应用的。我们将查看父类负载均衡器BaseLoadBalancer的代码。
public class BaseLoadBalancer extends AbstractLoadBalancer implements
PrimeConnections.PrimeConnectionListener, IClientConfigAware {
private final static IRule DEFAULT_RULE = new RoundRobinRule();
protected IRule rule = DEFAULT_RULE;
public Server chooseServer(Object key) {
if (counter == null) {
counter = createCounter();
}
counter.increment();
if (rule == null) {
return null;
} else {
try {
return rule.choose(key);
} catch (Exception e) {
logger.warn("LoadBalancer [{}]: Error choosing server for key {}", name, key, e);
return null;
}
}
}
void initWithConfig(IClientConfig clientConfig, IRule rule, IPing ping, LoadBalancerStats stats) {
// 省略部分代码
setRule(rule);
// 省略部分代码
}
}
这里可以看到是有默认的IRule规则的——RoundRobinRule,但是别冲动,因为我们Spring自动托管的IRule规则还没用上,不可能这么简单的走轮训。我们可以看到这里是有设置的地方的。我也抓出来了。
最后让我们再来看看我们的ZoneAwareLoadBalancer生成构造器,因为在注入时我们是会带入规则的。以下是相关的代码示例:
public ZoneAwareLoadBalancer(IClientConfig clientConfig, IRule rule,
IPing ping, ServerList<T> serverList, ServerListFilter<T> filter,
ServerListUpdater serverListUpdater) {
super(clientConfig, rule, ping, serverList, filter, serverListUpdater);
}
在这里,当super父类构造器执行完毕后,最终会调用BaseLoadBalancer类的initWithConfig方法。我没有一一追踪下去,但最后ZoneAvoidanceRule的负载均衡代码也相当复杂。不过,你可以将其理解为在没有区域的情况下类似于轮询。
配置多区域情况
在这个阶段,程序将会执行第二个分支,实际上,主要的代码如下所示:
String zone = ZoneAvoidanceRule.randomChooseZone(zoneSnapshot, availableZones);
if (zone != null) {
BaseLoadBalancer zoneLoadBalancer = getLoadBalancer(zone);
server = zoneLoadBalancer.chooseServer(key);
}
目的仍然是选择一个服务器,但是限定在当前区域内。关于这部分的详细讨论略去,因为接下来的方法都是关于ZoneAvoidanceRule的负载均衡算法代码。
如何配置其他算法
在这种情况下,如果我想使用其他负载均衡算法而不是当前的算法,应该如何配置呢?实际上,可以查看注入的源代码,有两种方法可以实现这一点。首先,可以通过在配置类中添加一个配置项来指定所需的负载均衡算法。
if (this.propertiesFactory.isSet(IRule.class, name)) {
return this.propertiesFactory.get(IRule.class, config, name);
}
局部配置
在这里可以看到我们也是通过配置文件来进行配置的,不过配置文件的方式使我们能够进行局部微服务负载均衡的选择。让我们先来看一下源代码:
public PropertiesFactory() {
classToProperty.put(ILoadBalancer.class, "NFLoadBalancerClassName");
classToProperty.put(IPing.class, "NFLoadBalancerPingClassName");
classToProperty.put(IRule.class, "NFLoadBalancerRuleClassName");
classToProperty.put(ServerList.class, "NIWSServerListClassName");
classToProperty.put(ServerListFilter.class, "NIWSServerListFilterClassName");
}
public boolean isSet(Class clazz, String name) {
return StringUtils.hasText(getClassName(clazz, name));
}
在调用特定的微服务时,可以根据需要使用相应的负载均衡策略来配置 application.yml 文件。
#被调用的微服务名
mall‐order:
ribbon:
#指定使用Nacos提供的负载均衡策略(优先调用同一集群的实例,基于随机&权重)
NFLoadBalancerRuleClassName:com.alibaba.cloud.nacos.ribbon.NacosRule
全局配置
在全局情况下更为简单,可以观察到在自动注入时使用了 @ConditionalOnMissingBean 注解。如果我们在Spring中手动加载了相应的bean,那么这个注解就不会生效了。
@Bean
public IRule ribbonRule() {
// 指定使用Nacos提供的负载均衡策略(优先调用同一集群的实例,基于随机权重)
return new NacosRule();
}
相当简单了,那么这样的的话,其实我们也可以进行自定义一个策略的。毕竟照先有的抄下固定实现方法后,自己在实现方法内写上自己的业务逻辑不就完了。
自定义策略
看起来,对于实现其他的负载均衡算法策略,有几个关键点。首先,需要继承 AbstractLoadBalancerRule 父类,并且实现其抽象方法。接下来,我们可以开始编写我们的实现代码:
@Slf4j
public class XiaoYuRandomWithWeightRule extends AbstractLoadBalancerRule {
@Override
public Server choose(Object key) {
//这里实现自己的逻辑即可
return server;
}
@Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
}
}
OK,剩下的就按照局部配置或者全局配置下,让我们的规则生效即可。
在这里只讲述了算法规则的配置和自定义方法,实际上负载均衡器的操作也是类似的套路。这里就不重复演示了。
总结
今天,我们主要补充了上一章关于微服务通信的内容,并深入探讨了负载均衡算法的重要性。我们首先详细讨论了Ribbon默认使用的负载均衡算法。尽管在本地测试时可能会观察到轮询的效果,但简单依赖这种表面的观察是不够的。在真实的生产环境中,特别是在跨多个数据中心部署时,负载均衡策略的选择需要更加深入的理解和分析。
我们进一步分析了如何通过配置和自定义负载均衡规则来灵活应对各种场景。不论是局部配置还是全局配置,我们都能根据具体需求调整负载均衡的行为。同时,我们展示了如何通过自定义算法扩展Ribbon的负载均衡能力,以更好地适应特定业务场景的需求。
在接下来的章节中,我们将深入探讨OpenFeign组件。我们的重点将是如何使开发人员能够更多关注业务逻辑代码,而不是被迫处理与RPC调用相关的繁琐细节。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位掘金优秀作者、腾讯云内容共创官、阿里云专家博主、华为云云享专家。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。