C语言:底层剖析——函数栈帧的创建和销毁
✿༺小陈在拼命༻✿ 2024-06-11 12:35:03 阅读 83

一、究竟什么是函数栈帧
C语言的使用是面向过程的, 面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。所以C语言的程序都是以函数作为基本单位的,如果能够深入理解函数,无疑对于c语言会有更深刻地理解,修炼自己的内功,那么函数是如何调用的?函数返回值是如何返回的?函数的形参是如何传递的…………等等的问题,其实都和函数栈帧有关系!
函数栈帧(stack frame):就是函数调用过程中在程序的调用栈(call stack)所开辟的空间,这些空间是用来存放:
1、函数参数和函数返回值
2、临时变量(包括函数的非静态的局部变量以及编译器自动生产的其他临时变量)
3、保存上下文信息(包括在函数调用前后需要保持不变的寄存器)。
二、理解函数栈帧能解决什么问题呢?
函数栈帧的创建和销毁,是函数调用的底层逻辑,通过学习这方面的内容可以解决以下问题:
1、局部变量是如何创建的?
2、为什么局部变量不初始化内容是随机的?
3、函数调用时形参是如何传递的,传递和调用的顺序又是怎样的?
4、为什么说形参是实参的一份临时拷贝,改变形参的值不会影响实参?
5、函数的返回值是如何带回去的?
三、函数栈帧的创建和销毁
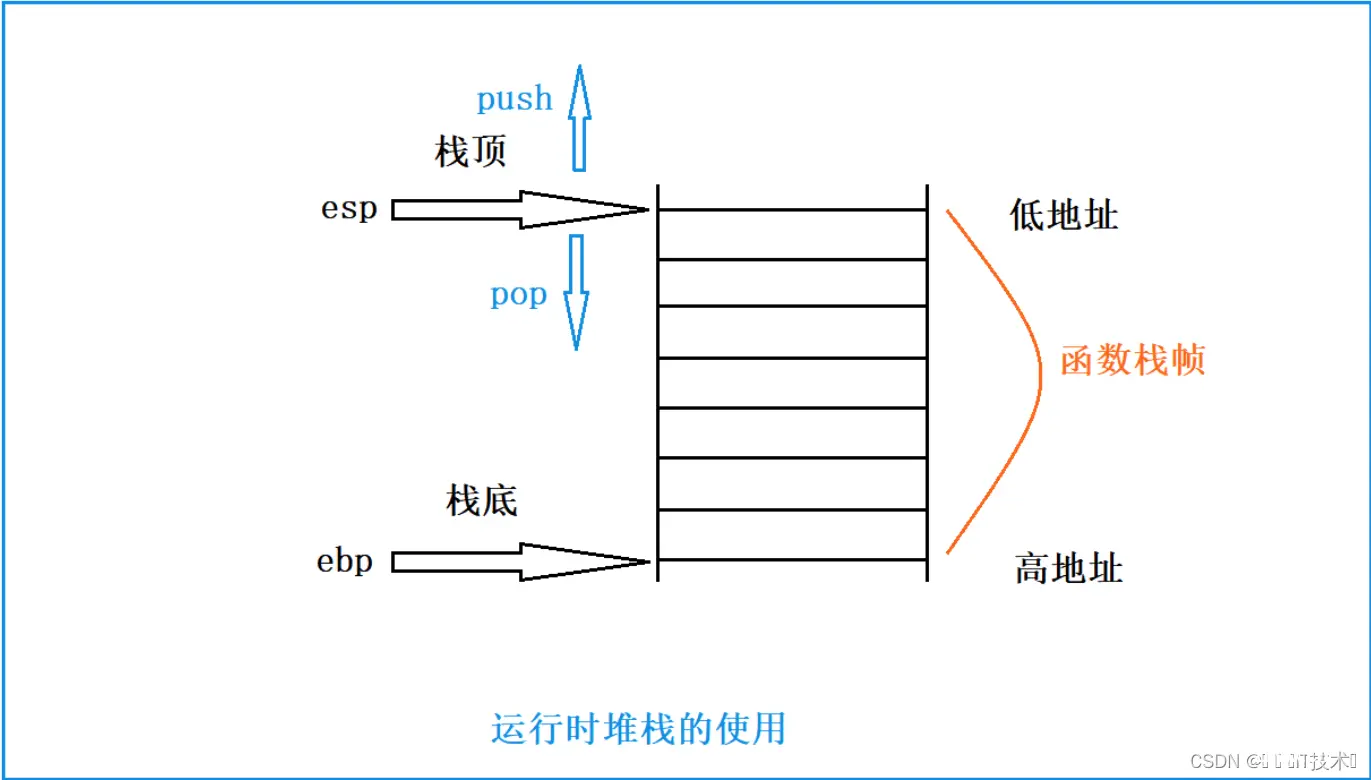
3.1 什么是栈?
栈(stack)是现代计算机程序里最为重要的概念之一,几乎每一个程序都使用了栈,没有栈就没有函数,没有局部变量,也就没有我们如今看到的所有的计算机语言。
在经典的计算机科学中,栈被定义为一种特殊的容器,用户可以将数据压入栈中(入栈,push),也可 以将已经压入栈中的数据弹出(出栈,pop),但是栈这个容器必须遵守一条规则:先入栈的数据后出 栈(First In Last Out, FIFO)。就像叠成一叠的术,先叠上去的书在最下面,因此要最后才能取出。
在计算机系统中,栈则是一个具有以上属性的动态内存区域。程序可以将数据压入栈中,也可以将数据 从栈顶弹出。压栈操作使得栈增大,而弹出操作使得栈减小。
在经典的操作系统中,栈总是向下增长(由高地址向低地址)的。
在我们常见的i386或者x86-64下,栈顶由成为 esp 的寄存器进行定位的。 栈底有ebp的寄存器进行定位,而这次主要会在x86环境下进行演示。
值得注意的是:在不同的编译器中,函数调用过程中栈帧的创建是略有差异的,具体细节取决于编译器的实现,这次主要会在vs2022编译器上进行演示。
3.2 认识相关的寄存器和汇编指令
相关寄存器:
eax:通用寄存器,保留临时数据,常用于返回值
ebx:通用寄存器,保留临时数据
ebp:栈底寄存器
esp:栈顶寄存器
eip:指令寄存器,保存当前指令的下一条指令的地址
相关汇编命令:
mov:数据转移指令
push:数据入栈,同时esp栈顶寄存器也要发生改变
pop:数据弹出至指定位置,同时esp栈顶寄存器也要发生改变
sub:减法命令
add:加法命令
call:函数调用,1. 压入返回地址 2. 转入目标函数 jump:通过修改eip,转入目标函数,进行调用
ret:恢复返回地址,压入eip,类似pop eip命令
3.3 函数栈帧的创建与销毁解析
3.3.1 预备知识
1、每一次函数调用,都需要为本次函数调用开辟空间,就是函数栈帧的空间。
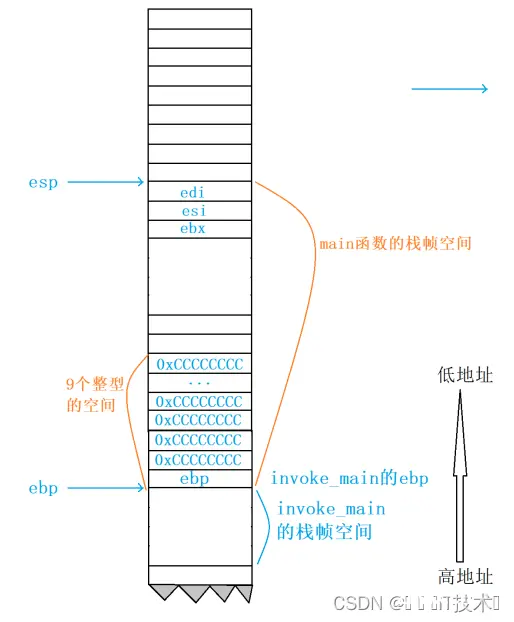
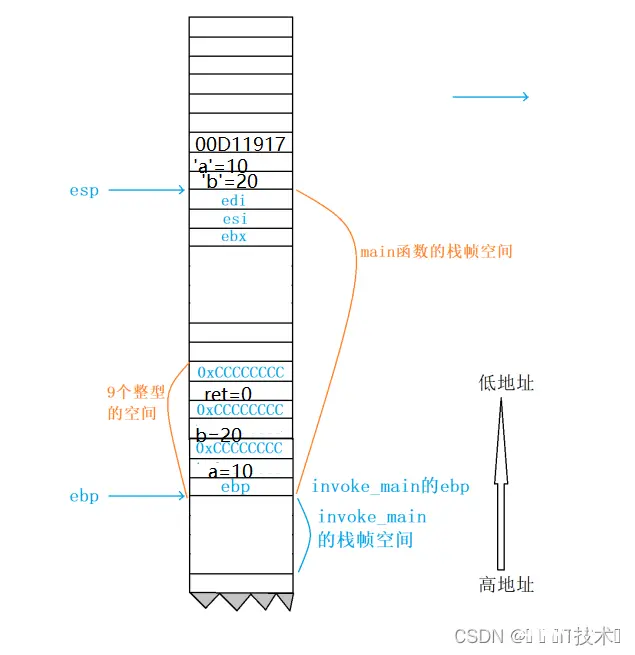
2、这块空间的维护是使用了两个寄存器:esp和ebp(也可以理解成两个指针),ebp记录的是栈底的地址,esp记录的是栈顶的地址,而这两个地址就是用来维护函数栈帧的。
3、栈区的使用一般都是从高地址到低地址。
3.3.2 函数调用堆栈
以下是本次演示的全部代码
#include <stdio.h>int Add(int x, int y){int z = 0;z = x + y;return z;}int main(){int a = 10;int b = 20;int ret = 0;ret = Add(a, b);printf("%d\n", ret);return 0;}
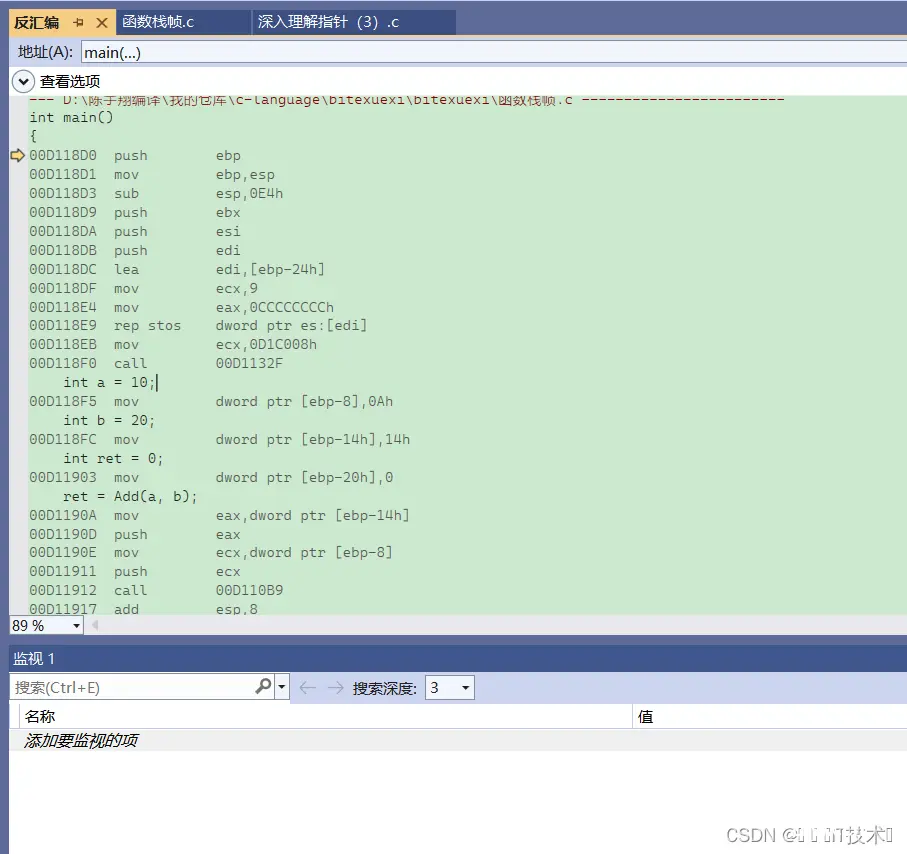
这段代码,如果我们在VS2019编译器上调试,打开调用堆栈(调试->窗口->调用堆栈)
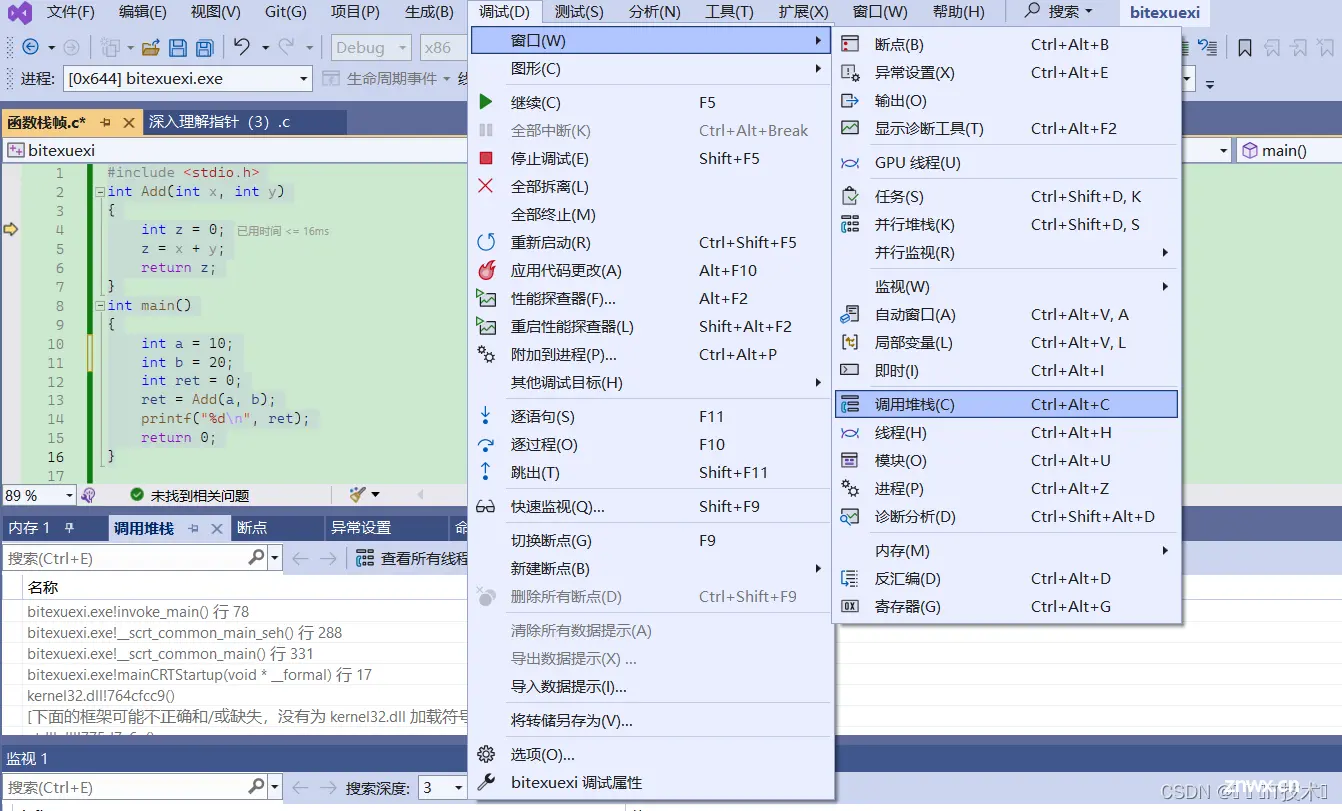
调试进入Add函数后,我们就可以观察到函数的调用堆栈 (右击勾选【显示外部代码】),如下图:
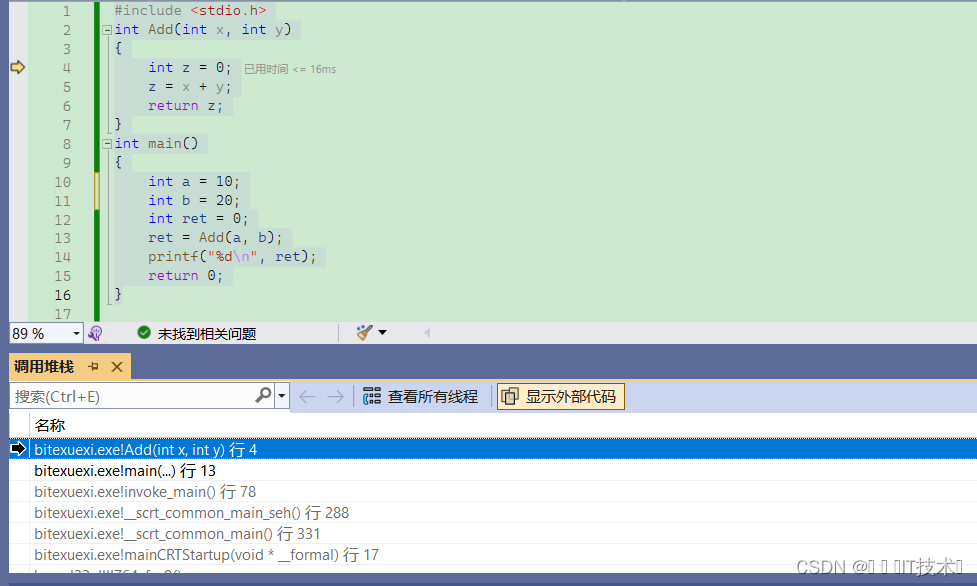
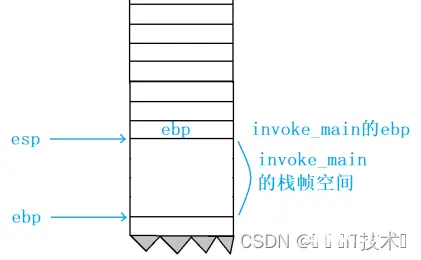
函数调用堆栈是用来反馈函数调用逻辑的,我们可以通过上图发现,Add函数是由main函数调用的,而在main函数之前,是由invoke_main函数来调用main函数的!!
这样我们可以确定,invoke_main函数也有自己的栈帧,main函数和add函数也有自己的栈帧,每个栈帧都有自己的edp和esp来维护栈帧空间!
3.3.3 准备环境
为了让我们研究函数栈帧的过程足够清晰,不要太多干扰,我们可以关闭下面的选项(将支持仅我的代码调试 设为 “否”),让汇编代码中排除一些编译器附加的代码。
3.3.4 转到反汇编
注:VS编译器每次调试都会为程序重新分配内存,每次调试略有差异。
3.3.5 函数栈帧的创建
3.3.5.1main函数栈帧的开辟
我们从main函数转换的反汇编代码进行演示,一行行拆解代码
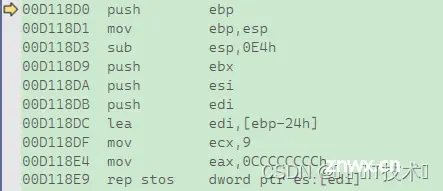
这一块内容为main函数创建变量之前的代码,该代码的实现的就是main()函数的栈帧创建
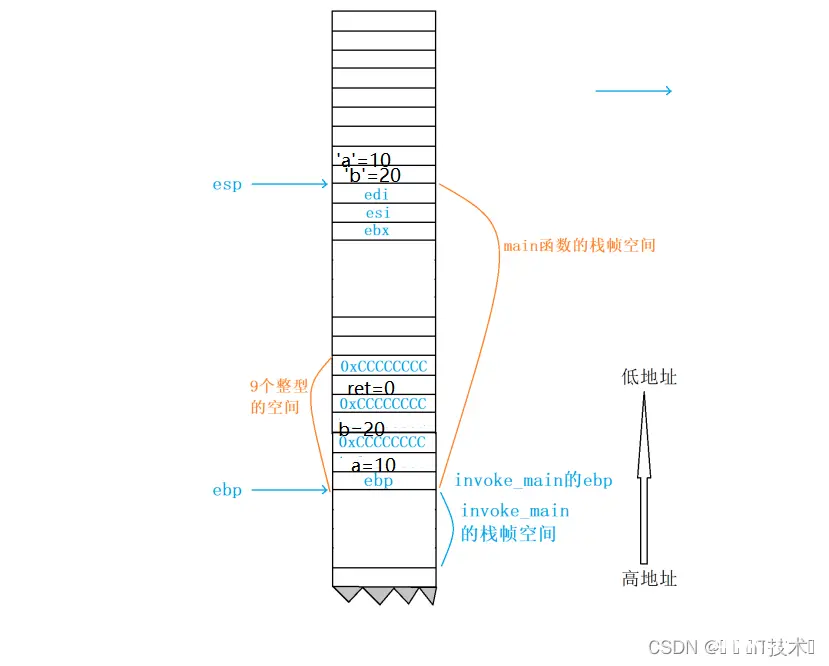
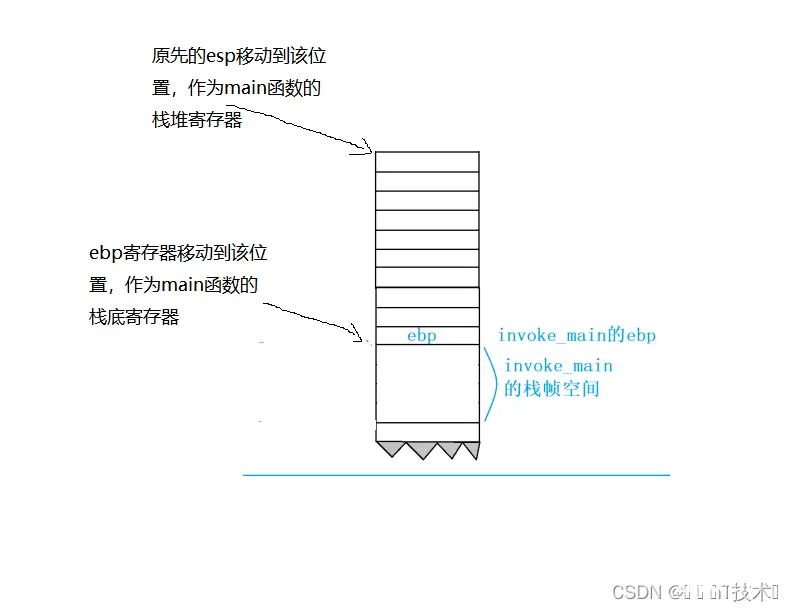
1、push ebp
在main函数创建之前,esp和ebp维护的是invoke_main函数,第一步,就是将ebp(栈底寄存器)的值进行压栈(esp-4),此时的ebp存放的是invoke_main函数栈帧的ebp。

2.mov ebp,esp
move指令会把esp的值存放带ebp中,相当于产生了main函数的ebp,这个值就是invoke_main函数栈帧的esp。
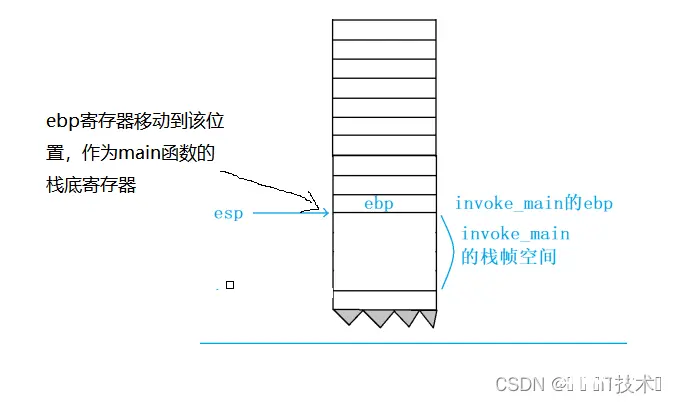
3.sub esp,0E4h
sub指令会让esp的地址减去一个16进制的0xe4,产生新的esp,此时的esp是main函数栈帧的esp,此时结合上一条指令的ebp和当前的esp,他们之间维护了一块新的栈空间,就是为main函数开辟的,将利用这一段空间存储main函数的局部变量、临时数据等等。

4. push ebx 将寄存器ebx的值压栈,esp-4
push esi 将寄存器ebx的值压栈,esp-4
push edi 将寄存器ebx的值压栈,esp-4
这三个指令保存了三个寄存器的值在栈区,这三个寄存器的函数随后执行中可能会被修改,所以于谦保存寄存器原有的值,以便于在退出函数能及时恢复。
5. lea edi,[ebp-24h] 先把ebp-24h的地址,放在edi中
mov ecx,9 把9放在ecx中
mov eax,0CCCCCCCCh 把0xCCCCCCCC放在eax中
rep stos dword ptr es:[edi] 将从edp-0x2h到ebp这一段的内存的每个字节都初始化为0xCC
这四个指令是用来对新开辟的main函数的栈帧进行初始化。
总结:我们可以发现,1-3步骤完成了main函数的栈帧空间开辟,4步骤完成了在使用寄存器之前对原先寄存器的值进行存储,5步骤完成了对main函数栈帧的初始化
3.5.5.2 main函数中局部变量变量的创建

move dword ptr [ebp-8],0Ah 将10存储到ebp-8的地址处, ebp-8的位置其实就是a变量
move dword ptr [ebp-14h],14h 将20存储到ebp-14h的地址处,ebp-14h的位置 其实是b变量
move dword ptr [ebp-20h],0 将0存储到ebp-20h的地址处, ebp-20h的位 置其实是ret变量
3.5.5.3 Add函数的传参以及调用
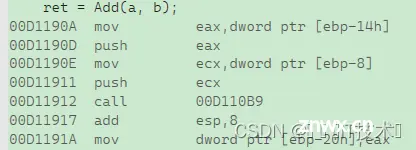
此图为Add函数传参以及调用的内容
3.5.5.3.1 传参
mov eax,dword ptr [ebp-14h] 将[ebp-14h] 处的b(20)放到eax中
push eax 将eax的值压栈,esp-4
mov ecx,dword ptr [ebp-8] 将[ebp-8h] 处的a(10)放到ecx中
push ecx 将ecx的值压栈,esp-4
此操作我们可以发现,其实参数的传递在Add函数调用之前就已经完成了,实在main函数中开辟了一小段临时空间将实参的值进行存储。
3.5.5.3.2 函数调用开始
00D11912 call 00D110B9 调用00D110B9(编译器计算好开辟Add函数的地址) 处的函数(Add)同时记录call指令的下一个指令的地址00D11917 (为了在Add函数调用结束后可以快速回到main函数)
3.5.5.3.3 函数调用结束后的返回过程以及形参的销毁
00D11917 add esp,8 esp直接+8,相当于跳过了main函数中压栈的 a'和b'(销毁形参)
mov dword ptr [ebp-20h],eax 将eax中值,存档到ebp-0x20的地址处, 其实就是存储到main函数中ret变量中,而此时eax中就是Add函数中计算的x和y的和,可以看出来,本次函数的返回值是由eax寄存器带回来的。程序是在函数调用返回之后,在eax中去读取返回值的。
3.5.5.4Add函数的栈帧开辟
此图为Add函数的栈帧开辟
在Add函数中创建栈帧的方法和在main函数中是相似的,在栈帧空间的大小上略有差异而已。
1. 将main函数的 ebp 压栈
2. 计算新的 ebp 和 esp
3. 将 ebx , esi , edi 寄存器的值保存
4. 计算求和,在计算求和的时候,我们是通过 ebp 中的地址进行偏移访问到了函数调用前压栈进去的 参数,这就是形参访问。
5. 将求出的和放在 eax 寄存器尊准备带回
这里不做过多解释,可以参照main函数的栈帧创建形式去分析!
3.5.5.5Add函数内部的实现

此图为Add函数内部的实现
mov dword ptr [ebp-8],0 将0放在ebp-8的地址处,其实就是创建z
mov eax,dword ptr [ebp+8] 将ebp+8地址处的数字(局部变量‘a’=10)存储到eax寄存器中
add eax,dword ptr [ebp+0Ch] 将ebp+12地址处的数字(局部变量‘b’=20)加到eax寄存器中
movdword ptr [ebp-8],eax 将eax的结果(10+20=30)保存到ebp-8的地址处,其实就是放到z中
mov eax,dword ptr [ebp-8] 将ebp-8地址处的值放在eax中,其实就是 把z的值存储到eax寄存器中,这里是想通过eax寄存器带回计算的结果,做函数的返回值。
通过以上步骤我们可以发现,当形参需要参与计算时,会通过指针偏移量找到传入实参的值(10和20),这是在函数调用之前就存储好的。并且计算过程是由寄存器完成的,同时寄存器也存储了返回值,避免了返回值变量的空间销毁后找不到返回值。
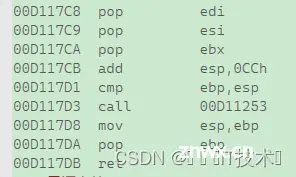
3.5.5.6Add函数的栈帧销毁
此图为Add函数的栈帧销毁
pop edi 在栈顶弹出一个值,存放到edi中,esp+4
pop esi 在栈顶弹出一个值,存放到esi中,esp+4
pop ebx 在栈顶弹出一个值,存放到ebx中,esp+4
mov esp,ebp 再将Add函数的ebp的值赋值给esp,相当于回收了Add函数的栈帧空间
pop ebp 弹出栈顶的值存放到ebp,栈顶此时的值恰好就是main函数的ebp, esp+4,此时恢复了main函数的栈帧维护,esp指向main函数栈帧的栈顶,ebp指向了main函数栈帧的栈 底。
ret ret指令的执行,首先是从栈顶弹出一个值,此时栈顶的值就是call指令下一条指令的地址,此时esp+4,然后直接跳转到call指令下一条指令的地址处,继续往下执行
四、深入理解为什么需要压栈
4.1 为什么在Add函数创建栈帧的时候第一步要在main函数的esp-4的位置压栈压入ebp的值?
因为esp(栈顶寄存器)和ebp(栈底寄存器)用来维护函数的栈帧,他会根据调用函数的不同去向不同的位置,由于栈区的使用习惯时从高地址指向低地址,那么当Add函数执行完后想要回到main函数,此时Add的ebp恰好就可以是main函数的esp,但是main函数的ebp此时已经不知道在哪里了,为了避免这种情况,创建Add函数栈帧的时候,esp和ebp在变化维护的栈帧空间之前,会记录原来空间的栈底地址也就是main函数的ebp地址,这样当Add函数调用完成销毁的过程中,栈顶弹出栈的时候就可以将main函数的ebp弹出来并将Add函数的ebp更新为main函数的ebp。
4.2 为什么main函数在调用一个需要传入参数的函数Add时,需要先将参数的值存储起来?
因为我需要把main函数中的实参传递给Add函数进行计算,那在esp和ebp转移之前,提前将传入参数的值临时拷贝在一小段空间里,这样当Add函数需要时,可以通过指针偏移量去找到这些数,我们叫做形参,形参是实参的一份临时拷贝,所以修改形参不会影响实参。
4.3 main函数在调用Add函数前,为什么在call指令执行时,需要存储call指令的下一个地址?
因为在main函数的执行过程中,main函数是执行到一半的时候调用了Add函数,在调用(call指令)之前记录执行到一半的那个地址,方便Add函数结束之后,能够及时返回到自己main函数的栈帧之前的地方,同时形参的创建也是在函数调用之前实现的,所以回到该地址还同时可以弹出保存形参值的栈。对形参进行及时的销毁。
五、对 二 中的问题进行解释
通过对函数栈帧的创建和销毁学习后,对于这个函数的底层知识有了更深刻的理解。以此们可以解决目录二中提到的问题。
5.1 局部变量是如何创建的
函数开辟栈帧空间,并初始化空间之后,给局部变量分配了一部分内存,两个局部变量之间的空间距离可能离得远也可能离得近,具体要根据编译器来决定。
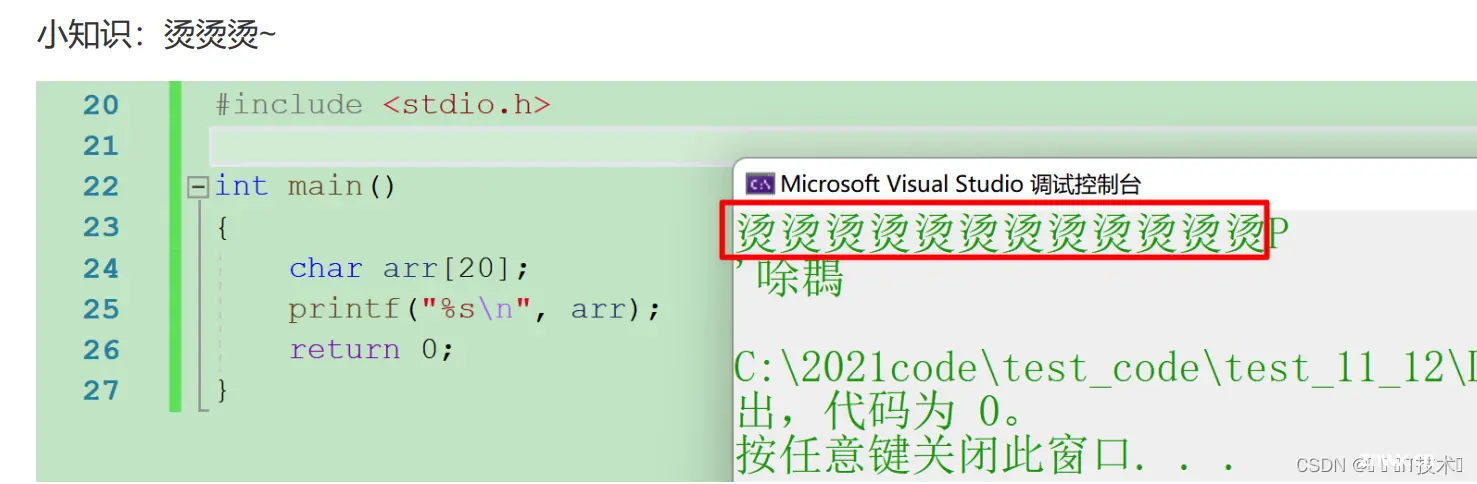
5.2 为什么局部变量不初始化内容是随机的
因为在函数开辟栈帧空间之后,我们对空间都进行了初始化,每一个字节都被初始化为0xCC,如果直接使用,会给随机值,同时由于0xCCCC的汉字编码就是烫,所以当0xCCCC被当作文本时打印出来的就是烫,这也说明了变量初始化的重要性!
5.3 函数调用时参数是如何传递的?传参的顺序是怎样的?
首先在函数调用之前,会将参数的值进行压栈,当调用的函数需要使用该值的之后,会通过指针偏移量去找到这块空间。传参的顺序是从右到左,调用的顺序是从左到右。
5.4 为什么说形参是实参的一份临时拷贝,改变形参的值不会影响实参?
因为形参是在函数调用之前,就在main函数内部通过压栈的方式保存了形参值,形参值虽然和实参的数值一样,但是并不是一块空间,可以说明改变形参的大小不会影响实参
5.5 函数的返回值是如何带回去的?
在函数开辟堆栈时,我们根据函数返回值的类型的大小,判断是否要产生临时量来将返回值带出去
<= 4B:一个寄存器带回
8B=< > =4B:通过两个寄存器带回
.>8B:通过产生临时量的方式处理返回值
大于8个字节时处理返回值的过程:返回值太大,寄存器无法带回去。
整个过程如下:
1.函数调用前根据函数的返回值类型,确定函数返回值的大小
2.提前在主调函数的栈帧上开辟一块内存,然后调用函数的时候将这块内存的地址压栈进去,等到所以的实参入栈以后就将这块内存的地址入栈
3.被调函数产生的数据将根据临时量的内存的地址直接拷贝回主调函数
注意:
只要不是内置类型,只要是自定义的类型,返回值的时候都会产生临时量。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。