人工智能开发实战机器学习算法解析
天涯幺妹 2024-09-10 17:01:02 阅读 89
内容提要
线性回归逻辑回归KNN其它机器学习算法
一、线性回归
1、什么是线性回归
线性回归是利用数理统计中的回归分析来确定两种或两种以上变量间相互依赖定量关系的一种统计分析方法,其运用领域十分广泛。
简单来说,线性回归就是要完成一个函数,该函数有输入和输出,当输入一些参数时,该函数就能得到一个结果作为输出,这个输出就是对输入的预测,且这个预测的结果是连续的。
线性回归是在N维的空间找到一条直线、一个平面或者一个超平面,使其能够拟合提供的数据,从而可以预测新的数据。在线性回归中,公式为y=Wx+b,W是权重,b是偏置。
2、线性回归案例
随机生成一些数据x作为时间投入,y作为考试成绩,找到一条直线,让这条直线尽可能地拟合图中的数据点,复习过程中时间投入与考试成绩的图像如图1所示。
在这个回归任务中,需要找到“最佳拟合线”使得误差最小化。拟合后的线如图2所示。
希望拟合后的线上每一个y和 的差距都尽可能小,即这条线上所有样本点x(p)对应的真值和预测值之差的和是最小的,真值与预测值的差距反映在二维空间上,表现为两者距离的长短,从而将求最优化的拟合线问题转换为求最短距离问题。
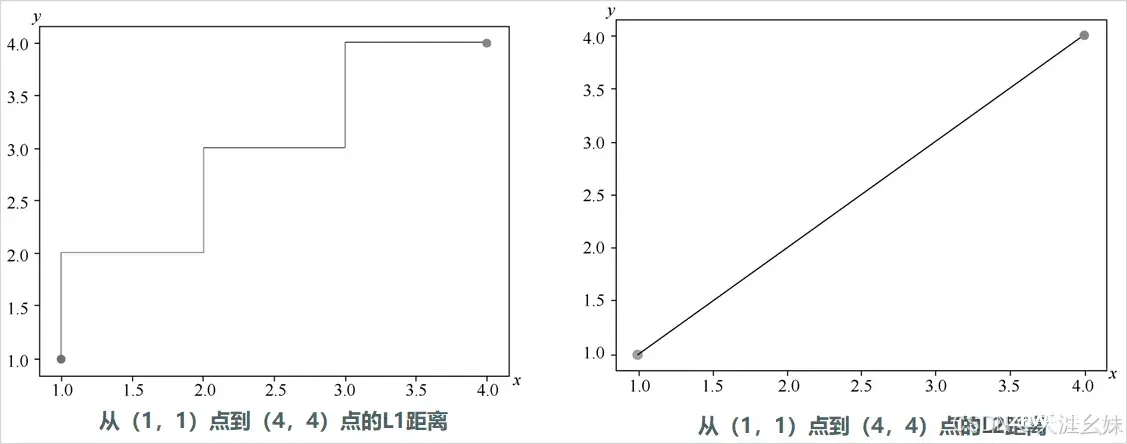
计算距离常用的方法有L1距离和L2距离等。
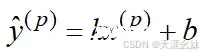
L1距离公式为
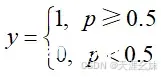
,(x1,y1)是起点的坐标,(x2,y2)是终点的坐标。
L2距离公式为
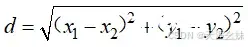
,(x1,y1)是起点的坐标,(x2,y2)是终点的坐标。
提示:在寻找复习时间和考试成绩最佳拟合曲线时,也可以用L1距离或者L2距离来做,这里使用L2距离完成拟合。
此时目标就确立了,即所有的样本点x(p)对应的拟合线上预测值 与真实值y的距离之和要尽可能小,也就是说
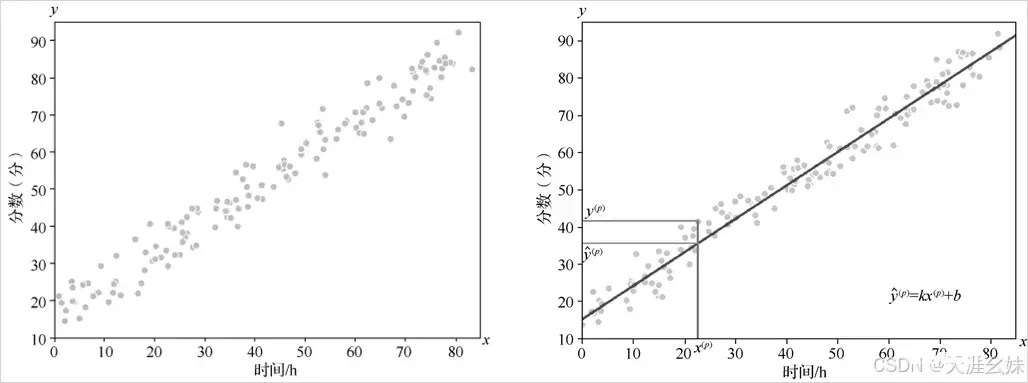
要尽可能小,结合

,使得
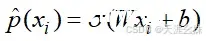
尽可能小,由于x和y是已知的,所以需要找到k和b。
在机器学习中,斜率k一般称为权重W,截距b称为偏置b,y(p)是真值,
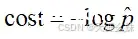
是预测值。这个过程就是使用最小二乘法解决问题的思路。
在机器学习中,需要通过分析问题确定问题的损失函数,通过最优化损失函数获得机器学习的模型。在本问题中,选择

为损失函数,由于x和y都是已知的,所以需要找到参数k和b,使得损失函数的值最小。
3、数学方法解决线性回归问题
案例见上,步骤如下:
先导入必要的库。
希望拟合后的线上每一个y和 的差距都尽可能小,即这条线上所有样本点x(p)对应的真值和预测值之差的和是最小的,真值与预测值的差距反映在二维空间上,表现为两者距离的长短,从而将求最优化的拟合线问题转换为求最短距离问题。
计算距离常用的方法有L1距离和L2距离等。
二、逻辑回归
1、什么是逻辑回归
在线性回归中,输入和输出呈一定的关系且输出为连续的,即 y=f(x)。如果输出的y不表示为一个值,而是一个概率p,则公式更改为p=f(x),从线性回归输出一个具体的值到输出概率的过程需要一个中间公式,这个中间公式为
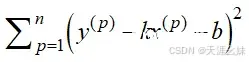
。当没有中间公式的转换时,就是一个回归问题;加了中间公式之后,就是一个分类问题。
线性回归中有公式

,在逻辑回归中,x可以为任意数(或多维数组),但是输出的概率值域为[0,1]。将线性回归的公式更改为
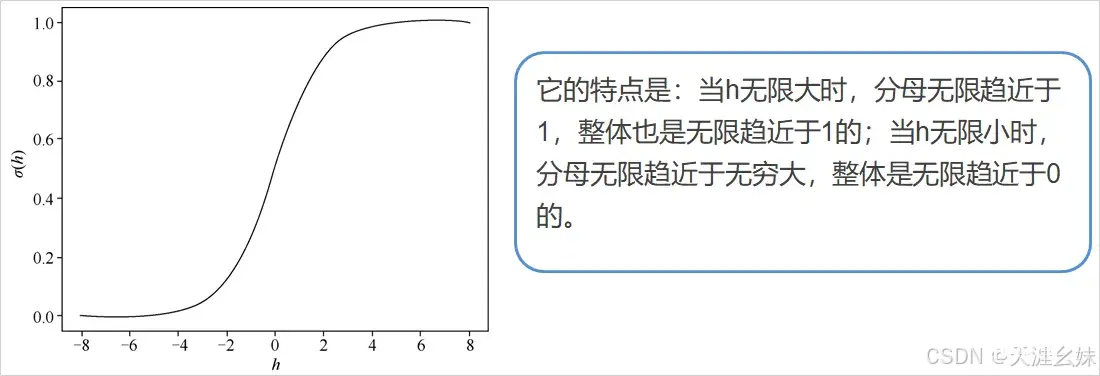
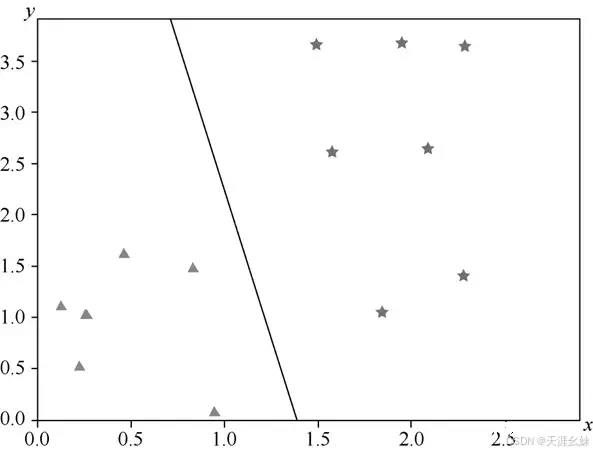
,将 作为新的特征可得到概率, 往往使用sigmoid()函数,称为激活函数,sigmoid()函数的形式为
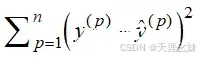
,sigmoid()函数图像如图所示。
将sigmoid()函数在坐标轴上绘制出来后,拥有坐标轴的sigmoid()函数图像如图所示。
2、逻辑回归案例
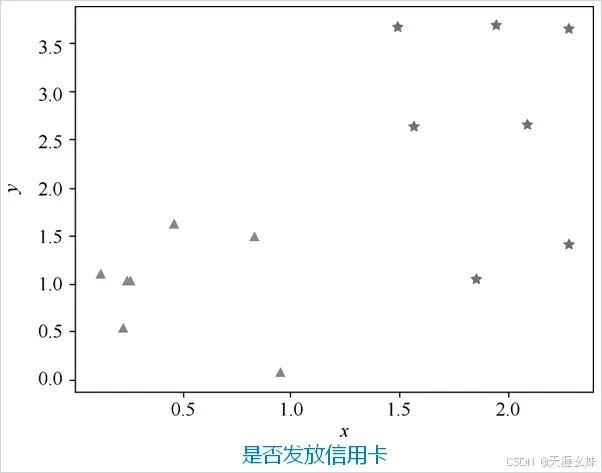
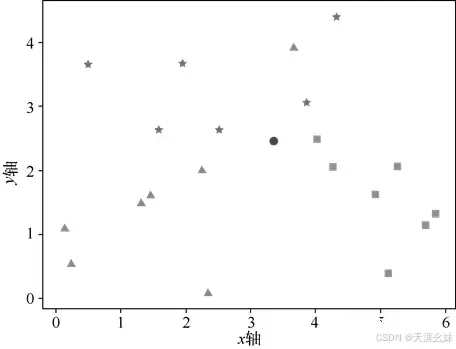
银行基于一个人的信用度决定是否为其发放信用卡,这里假设横坐标x是信用度,纵坐标y是工作稳定性。设置一些点,三角形代表银行不发给他信用卡,五角星代表银行发给他信用卡,如图所示。
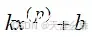
3、数学方法解决逻辑回归问题
在线性回归中,结果是线性的,期望y和 的差距尽可能小,可以使用距离求解。
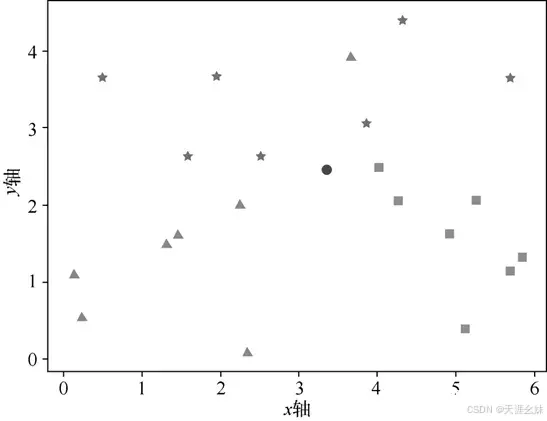
但是在逻辑回归中,得到的结果是概率,没办法直接求距离,这时候需要做一些处理,使用损失函数 ,其中x是逻辑回归的结果。
对于该公式
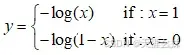
,损失函数的图像如图所示。

说明:
损失函数是两个函数,在编程的时候会造成困难,所以将其合并为一个函数:
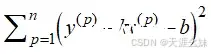
当y=1时,

当y=0时,

这里有一个样本,当有n个样本时,损失函数为
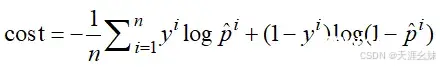
其中
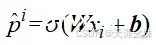
按照解决线性回归问题的思路,应该算出它的数学公式解,
但是这个式子是没有数学公式解的,所以这里使用梯度下降的方法解决该逻辑回归问题。
4、利用TensorFlow解决逻辑回归问题
使用梯度下降法实现逻辑回归,绘制一条线将是否发给用户信用卡两类数据分开,在machine_learning项目下新建Logistic_regression.py。
(1)导入必要的库
<code>import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
(2)训练逻辑回归
# 创造数据
raw_data_X = [[1.85, 1.05],[1.57, 2.63], [2.28, 1.42],
[2.28, 3.64], [1.94, 3.68],[2.09, 2.66], [1.49, 3.66],
[0.12, 1.12], [0.25, 1.04],[0.23, 0.54], [0.83, 1.49],
[0.95, 0.09], [0.46, 1.63], [0.26, 1.03], ]
raw_data_Y = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1];
data = np.array(raw_data_X)
label = np.array(raw_data_Y)
data = np.hstack(data).reshape(-1,2)
label = np.hstack(label).reshape(-1,1)
label1 = label.reshape(1,-1)[0]
plt.scatter(data[label1 == 0, 0], data[label1 == 0, 1], marker="*")code>
plt.scatter(data[label1 == 1, 0], data[label1 == 1, 1], marker="^")code>
plt.show()
x = tf.placeholder(tf.float32,shape=(None,2))
y_ = tf.placeholder(tf.float32,shape=(None,1))
# tf.random_normal()函数用于从服从指定正态分布的数值中取出指定个数的值
# tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
weight = tf.Variable(tf.random_normal([2,1]), dtype=tf.float32)
bias = tf.Variable(tf.constant(0.1, shape=[1]))
# tf.nn.sigmoid()是激活函数
y_hat = tf.nn.sigmoid(tf.matmul(x, weight) + bias)
# 不适用该损失函数
# cost = tf.reduce_sum(tf.square(y_ - y_hat))
# 损失函数
cost = - tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y_hat, 1e-10, 1.0)) + (1 - y_) * tf.log(tf.clip_by_value((1 - y_hat), 1e-10, 1.0)))
# 梯度下降
optimizer = tf.train.AdamOptimizer(0.001)
train = optimizer.minimize(cost)
#开始训练
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
plt.ion()
for i in range(8000):
sess.run(train,feed_dict={x:data,y_:label})
#画出训练后的分割函数
#mgrid()函数产生两个300×400的数组:0~3每隔0.1取一个数,共300×400个
xx, yy = np.mgrid[0:3:.1,0:4:.1]
if (i % 20) == 0:
# np.c_用于合并两个数组
# ravel()函数将多维数组降为一维,仍返回array数组,元素以列排列
grid = np.c_[xx.ravel(), yy.ravel()]
probs = sess.run(y_hat, feed_dict={x:grid})
# print(probs)
效果如图:
三、KNN
1、什么是KNN
KNN(k-Nearest Neighbor)K-最近邻方法是一种惰性学习算法,它是基于实例的,并没有经过大量的训练来学习模型或者特征,而是仅仅记住了需要训练的相关实例。KNN是监督学习的一种。
KNN是给定测试实例。基于某种距离度量找出训练集中与其最靠近的k个实例点,然后基于这k个最近邻的信息来进行预测,简而言之,需要预测的实例与哪一类离得更近,就属于哪一类。
2、KNN案例
在某二维平面内有3种不同的图形,即五角星、三角形、正方形,它们的形状和它们的位置(即在x、y轴的坐标)有关系,现在出现了一个新的点,要将其归为以上3类中的某一类,可采用KNN完成。
二维平面示意图如图:

那么如何使用KNN将新的点进行分类呢?需要给KNN制订步骤:
(1)计算距离
(2)取出距离最近的点,找到新的点与哪一类更接近,观察分类结果
KNN最简单的思想是:
找到与预测数据最相近的k个数据,然后对预测数据进行投票,票数最高的标签作为预测数据的标签。
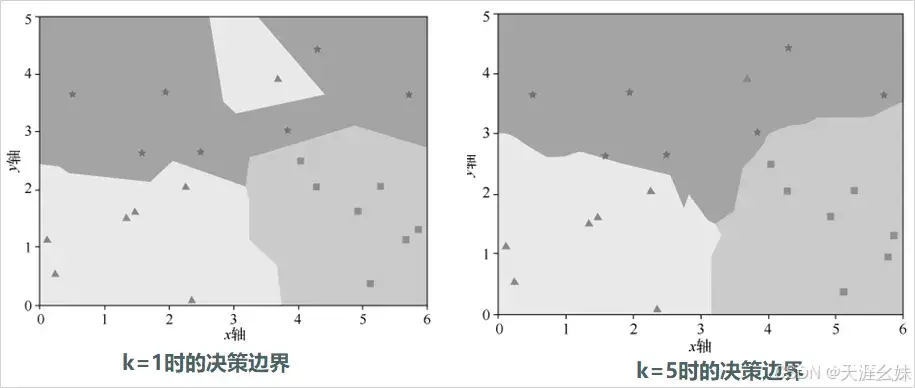
当k=1时,K近邻算法就变成了近邻算法。
比较不同的k值对分类效果的影响,使用L2距离的分类器画出五角星、三角形、正方形3种分类的决策边界,决策边界一侧的所有点属于一个类,另一侧的所有点属于另一个类,在二维平面内表示,不同颜色代表一类。
k=1时的决策边界,k=5时的决策边界如图所示。
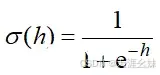
3、数学方法解决KNN问题
(1)导入必要的库
<code>import matplotlib.pyplot as plt
from collections import Counter
from math import sqrt
import numpy as np
NumPy库负责转换数据类型,Matplotlib库的pyplot库负责画出图像,Math库的sqrt()函数负责求开方,Collections的Counter()函数负责标签的计数。
(2)在二维平面上创造一些数据
raw_data_X = [[3.85, 3.05],
[1.57, 2.63],
[4.28, 4.42],
[5.68, 3.64],
[1.94, 3.68],
[2.49, 2.66],
[0.49, 3.66],
[0.12, 1.12],
[2.25, 2.04],
[0.23, 0.54],
[1.33, 1.49],
[2.35, 0.09],
[1.46, 1.63],
[3.66, 3.93],
[5.11, 0.39],
[5.69, 1.14],
[4.03, 2.49],
[4.92, 1.62],
[5.26, 2.05],
[4.26, 2.05],
[5.84, 1.31]
]
raw_data_Y = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2]
说明:
数据分为3类,横坐标范围为0~8,纵坐标范围为0~5。数据可以自己写或者使用随机数生成。创建两个列表,raw_data_X是坐标数据,raw_data_Y是标签。
(3)将列表转换为NumPy
x_train = np.array(raw_data_X)
y_train = np.array(raw_data_Y)
(4)新建一个测试点
x_test = np.array([3.35, 2.46])
(5)绘制散点图
plt.xlabel('x轴')
plt.ylabel('y轴')
plt.scatter(x_train[y_train == 0,0], x_train[y_train == 0,1], marker = "*")
plt.scatter(x_train[y_train == 1,0], x_train[y_train == 1,1], marker = "^")
plt.scatter(x_train[y_train == 2,0], x_train[y_train == 2,1], marker = "s")
plt.scatter(x_test [0], x_test [1], marker = "o")
plt.show()
(6)创建训练函数
<code>def train(X, y):
Xtr = X
Ytr = y
return Xtr, Ytr
(7)创建预测函数
def predict_math (X, xtrain, ytrain):
# 求L2距离
distances = [sqrt(np.sum((X_train - X) ** 2)) for X_train in xtrain]
# 对数组进行排序,返回的是值的索引值
nearest = np.argsort(distances)
# 取出前3个离得最近的点的标签
k = 3
topK_y = [ytrain[i] for i in nearest[:k]]
# 计数,取到键值对。键:标签;值:个数
votes = Counter(topK_y)
# 在键值对中值最多的键
print(votes.most_common(1)[0][0])
(8)调用训练函数与预测函数,完成预测
xtrain, ytrain = train(x_train, y_train)
predict_math (x_test, xtrain, ytrain)
(9)修改预测函数
def predict_math(X, xtrain, ytrain):
# 求L2距离
distances = [sqrt(np.sum((X_train - X) ** 2)) for X_train in xtrain]
# 对数组进行排序,返回的是值的索引值
nearest = np.argsort(distances)
# 取出前3个离得最近的点的标签
k = 3
topK_y = [ytrain[i] for i in nearest[:k]]
# 计数,取到键值对。键:标签;值:个数
votes = Counter(topK_y)
# 在键值对中值最多的键
print(votes.most_common(1)[0][0])
# 得到最接近的3个点的索引值
k = 3
topK_X = nearest[:k]
for i in range(3):
# 绘制预测点与最接近的3个点连成的直线
plt.plot([X[0], xtrain[topK_X[i]][0]], [X[1], xtrain[topK_X[i]][1]])
# 绘制预测点与最接近的3个点之间的长度
plt.annotate("%s"%round(distances[topK_X[i]], 2), xy=((X[0] + xtrain[topK_X[i]][0]) / 2,(X[1] + xtrain[topK_X[i]][1]) / 2))
plt.xlabel('x轴')
plt.ylabel('y轴')
plt.scatter(x_train[y_train == 0, 0], x_train[y_train == 0, 1], marker="*")code>
plt.scatter(x_train[y_train == 1, 0], x_train[y_train == 1, 1], marker="^")code>
plt.scatter(x_train[y_train == 2, 0], x_train[y_train == 2, 1], marker="s")code>
plt.scatter(x_test[0], x_test[1], marker="o")code>
plt.show()
k=3时认为测试点属于第0个类别,即五角星的类别。此时直接输出不是非常直观,如图所示。
4、利用TensorFllow解决KNN问题
<code># 导库
import tensorflow as tf
# 完成预测
def predict_tf(X, xtrain, ytrain):
# 定义变量大小
xtr = tf.placeholder("float", [None, 2])
xte = tf.placeholder("float", [2])
# 计算L2距离
# tf.negative()函数用于取相反数
# 调用reduce_sum(arg1, arg2)时,参数arg1即为和的数据,arg2可以取0和1
# 当arg2 = 0时,是纵向对矩阵求和,原来的矩阵有几列就得到几个值
# 当arg2 = 1时,是横向对矩阵求和;当省略arg2参数时,默认对矩阵所有元素进行求和
distance = tf.sqrt(tf.reduce_sum(tf.square(tf.add(xtr, tf.negative(xte))), reduction_indices=1))
with tf.Session() as sess:
# 添加用于初始化变量的节点
sess.run(tf.global_variables_initializer())
# 近邻算法:将测试集与训练集进行对比,返回误差最小的下标
nn_index = sess.run(distance, feed_dict={xtr: xtrain, xte: X})
# 对数组进行排序,返回的是值的下角标
nearest = np.argsort(nn_index)
# 取出前3个离得最近的点的标签
k = 3
topK_y = [ytrain[i] for i in nearest[:k]]
# 计数,取到键值对。键:标签;值:个数
votes = Counter(topK_y)
# 在键值对中值最多的键
print(votes.most_common(1)[0][0])
说明:
KNN的特点是思想比较简单,应用数学少,是一个几乎不需要训练过程的算法。
因为其训练过程只是将训练集数据存储起来,所以算法的训练不需要花费较多时间。这显然是一个缺点,虽然训练不需要花费较多时间,但是时间都花费在了测试上。
如果训练中有m个样本、n个特征,那么每预测一个新的数据都需要计算这一个数据和所有m个样本之间的距离,测试的时候,每计算一个距离就要使用O(n)的时间复杂度,计算m个样本之间的距离,就要使用O(m×n)的时间复杂度。
这与正常情况是不相符的,正常情况希望训练时间较长,但是测试时间要短。
四、其它机器学习算法
1、支持向量机
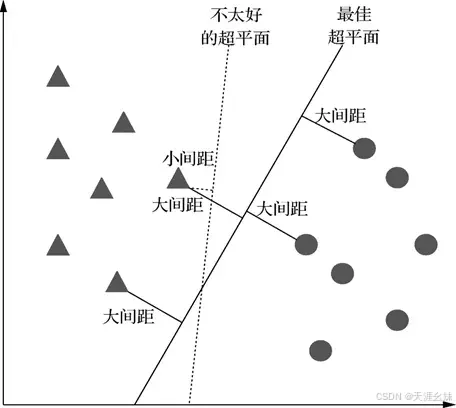
支持向量机(SVM)是一种有监督学习的算法,它可用于分类和回归分析,多用于分类问题中。
该算法会根据特征值构建一个n维空间,即n个数据特征,并把数据点投影到该空间内,之后寻找一个超平面,将空间内的数据分开,如图所示。
2、决策树
决策树是一种有监督学习的算法,主要用于分类问题中。
决策树可以理解为这样一棵树:这棵树上有很多的分支节点,每个分支代表一个选项,每个叶节点表示最终做出的决策。

3、随机森林
随机森林是有监督的集成学习模型,主要用于分类和回归。
随机森林建立了很多决策树并将其集成,以获得更准确、更稳定的预测。
4、K-Means
K-均值聚类(K-Means)是一种无监督学习算法。
聚类算法用于把族群或数据点分割成一系列的族,使得相同族中的数据点比其他族更相似。
K-均值聚类是把所有数据分成k个族,同一族中的所有项彼此尽量相似,不同族中的项尽量不同。每个族中有一个形心,形心为最能代表族的点。
更多精彩内容请关注本站!
上一篇: AI:254-YOLOv8改进 | 基于MobileNetV2的轻量化Backbone替换与性能评估
下一篇: ComfyUI - 自定义数据集 使用 LoRA 微调 图像生成 Flux 模型 (AI Toolkit)
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。