PDF解析,还能做得更好
合合技术团队 2024-08-17 17:31:02 阅读 68

随着大模型文档智能应用逐渐步入正轨,文档解析类产品成为其中重要的一环。
文档解析工具能够“唤醒”沉睡在PDF文件中的知识,将其转化为机器能够识别、读取的信息,将可用数据从txt、csv格式扩展到大批量的电子档、扫描档文件,为数据处理、大模型训练、RAG系统开发提供优质的“燃料”。
近期,文档解析的赛道越发火热,大量企业、开发者入局,为AI应用者提供更多可选产品。最近我们也在文章《以后再也不用肉眼测评解析产品了》(+link)中探讨了面对多种选项,我们应如何挑选适合自己业务场景的产品。
然而,作为解析产品的开发者之一,我们认为:PDF解析,还能做得更好,为用户提供更可靠、优质的服务。 今天,我们将从开发者的视角,与大家分享目前解析产品能进一步提升的一些不足之处,也欢迎大家在评论区分享使用感受、提出指正意见。
在与大模型应用接轨的解析领域,开发人员与用户是并肩作战的开拓者,所有意见对我们而言都至关重要!
使用过Markdown Tester的朋友可能已经注意到,目前测评的国内外几款相对主流解析产品,包括GPT-4o,都还称不上是“六边形战士”。
其中颇为薄弱的一项,就是公式。
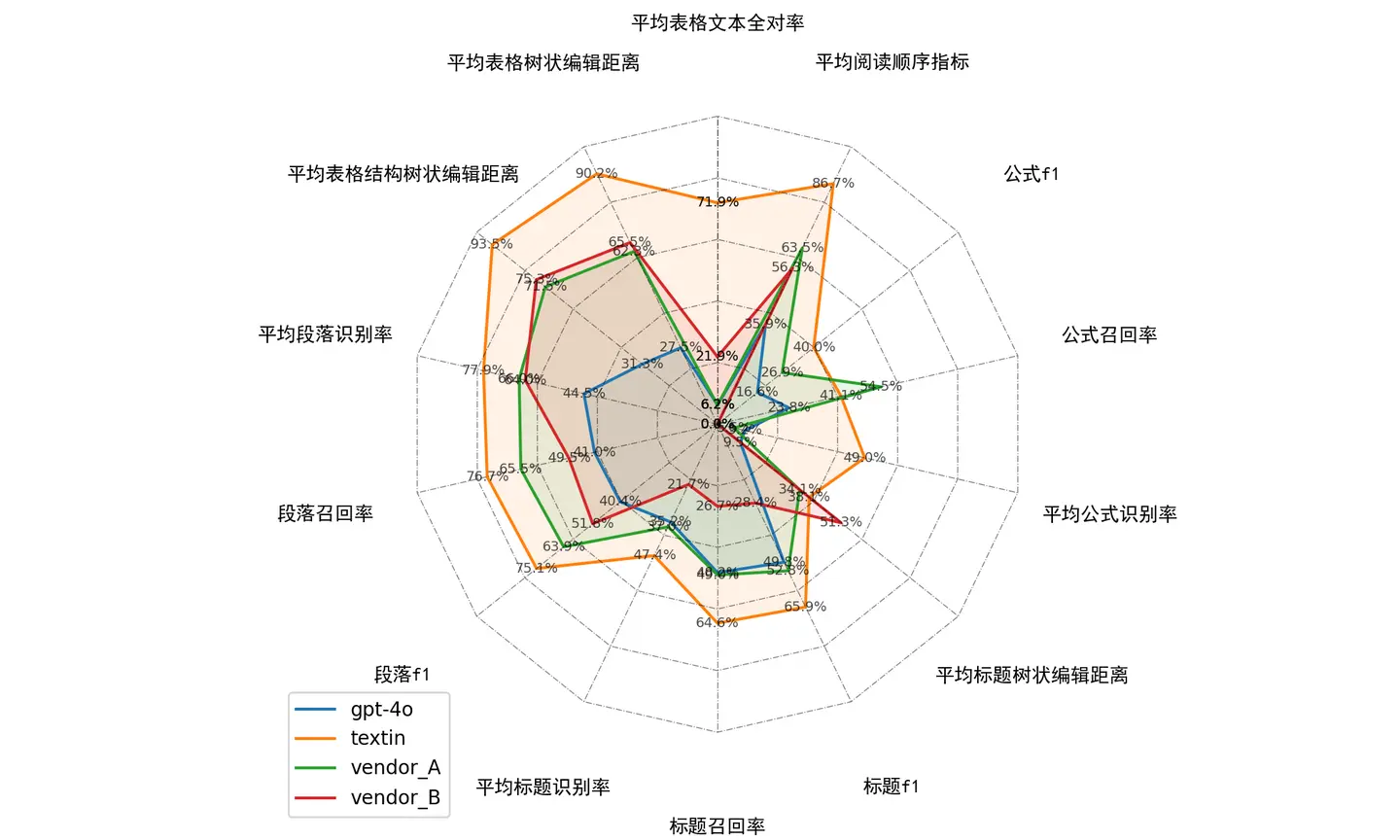
而准确的公式识别在许多场景下,都显得相当重要。
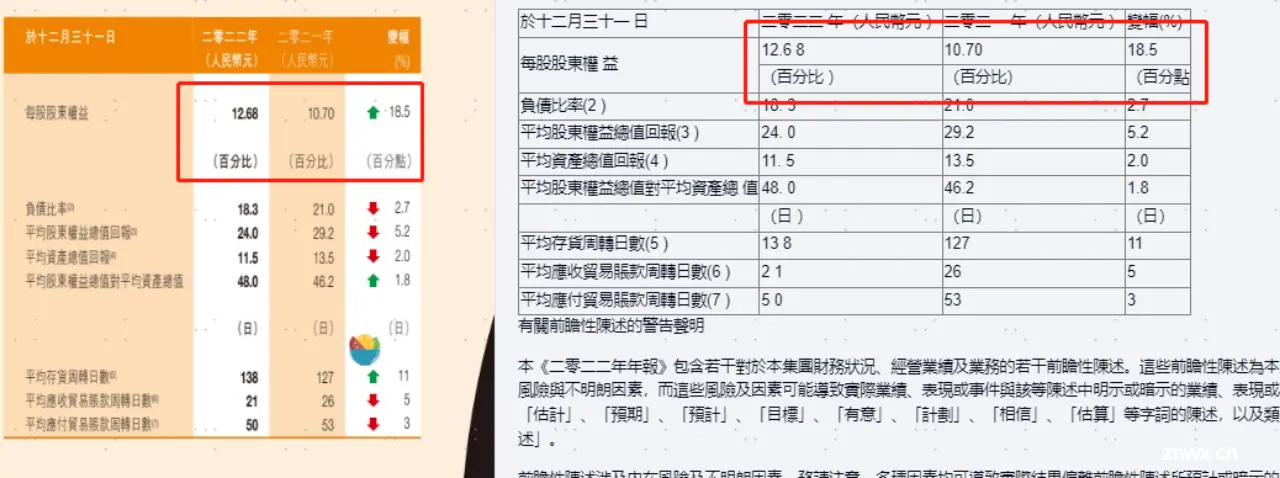
当我们需要处理技术类论文、专业书籍时,复杂公式是绕不开的重难点。在涉及大量教科书、教辅、试卷的教育应用场景下情况同样如此。在OCR与文档解析工具得到普遍使用之前,公式的手动输入和校对需要消耗许多人力成本,而公式的多变大小及版式也给机器识别造成了挑战。 以下图为例——

尽管公式中大部分信息被正确识别,在指数方面,解析工具反馈的结果仍有误差。这也是目前教育类应用的用户朋友仍需手动调整的原因。
对于复杂公式的训练提升,是我们重视的优化方向之一。
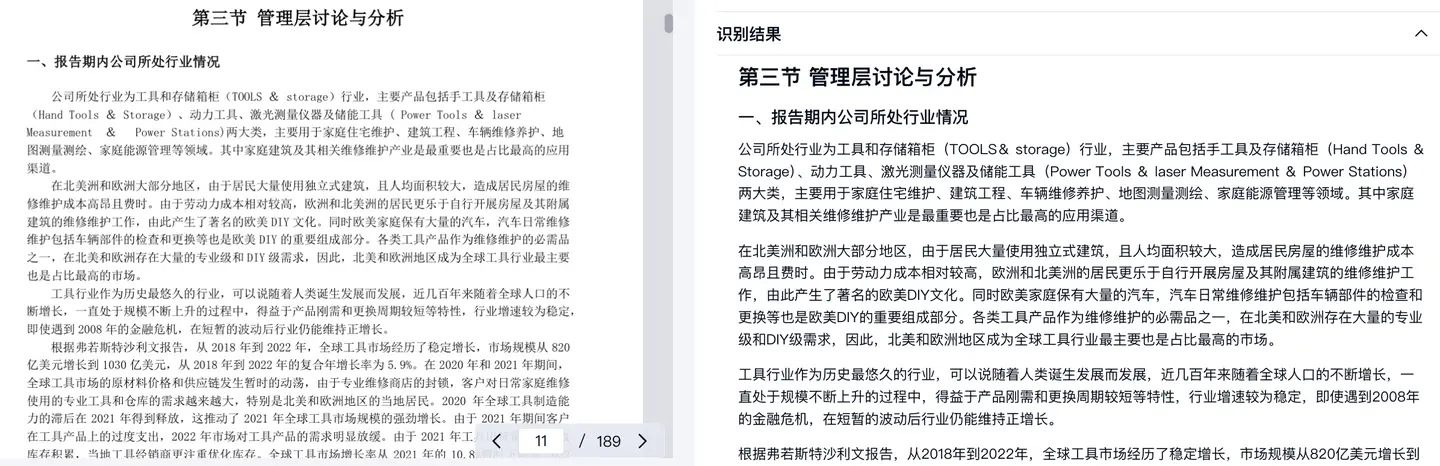
在财经、学术、企业知识库等各类RAG场景下,比公式出镜率更高的,就是此前我们已经介绍过的表格识别《聊聊文档解析测评里的表格指标》(+link)。如下图案例所显示,表格形式的复杂性、多样性无法穷举,面对无线表、合并单元格、不规则行距、跨段、跨页等难题,表格识别的加强是文档解析类产品的长期命题。
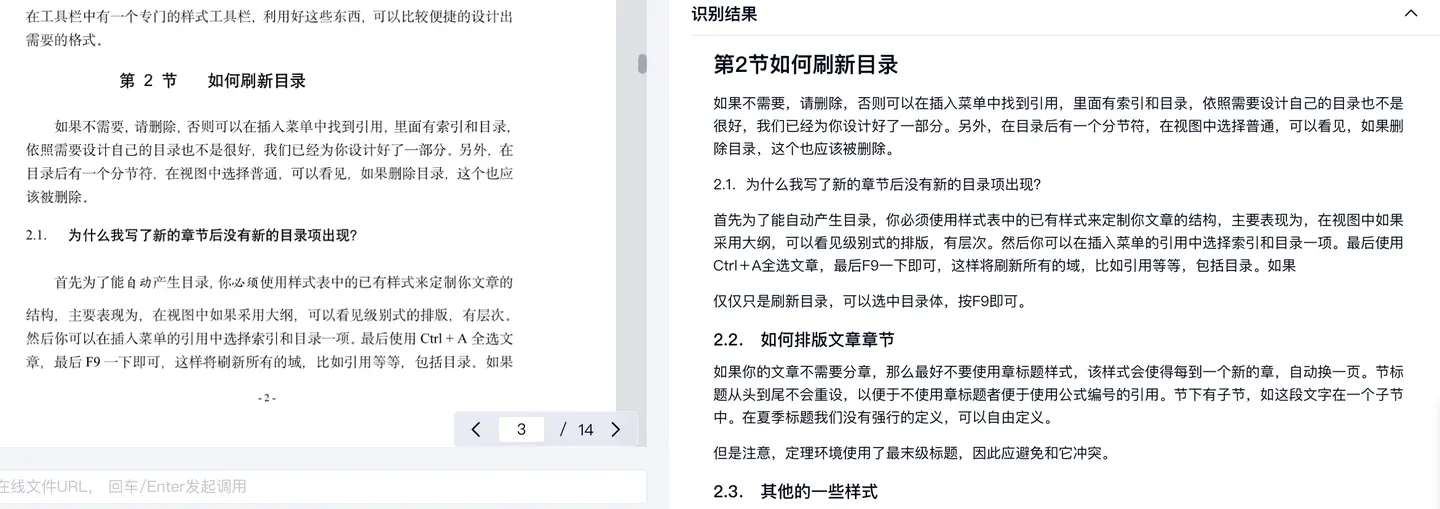
针对RAG,TextIn团队还在关注一个提及率不算特别高的问题:标题检测与目录树。在RAG系统开发过程中,面对长文档切片的需要,业内已形成普遍共识:
如果文档有清晰准确的标题及层级,即可改换按长度分chunk的传统方式,而是利用子标题、段落做基于语义理解的分片。这有利于提升系统后续的检索召回能力,以及问答任务中总体的回复表现。
目前,在文档解析过程中,由于不同类型的长文档标题格式各异,同时部分标题在语义上相对模糊,要准确、稳定地完成一级、二级、三级与其他子标题的识别仍属难点。以TextIn团队在开发中处理的实际场景为例,对年报、财报、研报等类型文件,标题层级识别与目录树建构已经能达到较好的效果,但在解析格式一致性更弱的文档类型时,表现还需要进一步优化。对解析来说,尝试如实还原各层级标题是一项较为困难、但对下游工作助益相当大的工作。因此,文档目录树的识别是我们关注的解析重点之一,欢迎对此有较高精度需求的用户随时与我们探讨应用场景,试用最新版的解析效果!

最后,我们也想与大家分享一个我们接到的吐槽——文档解析产品的API使用专业性要求太高!尤其在JSON结构的Detail参数方面,例如,现在当我们在参数中读取某一元素的位置,得到的结果为:
坐标数组[283,96,343,96,343,116,283,116]
数组的实际理解方式是:在象限内,以左下坐标为起点的顺时针坐标位置。
但显然,它与“直观简单”相去甚远。
接下来,我们会不断以用户体验为中心,进行输出优化,争取让JSON坐标数组这种类型的“槽点”不再成为我们用户的困扰。
LLM时代,我们需要更多优质的语料。AI相关行业的小伙伴基本上都认同,我们“喂”给大模型的语料质量,决定了大模型反馈给我们的回答质量。
所以,尽管在这一年中,PDF解析工作同样进度条发展迅速,我们仍然认为:解析还能做得更好!
今天我们分享了一些当前的重难点与优化方向,欢迎各位开发者随时向我们提出其他需求,与我们共同交流当下的需求~
TextIn文档解析产品目前正在内测计划中,可持续关注我们公众好 合研社 ,申领内测福利立刻试用文档解析!
关于测评工具、产品或需求,都可以找我们沟通。我们欢迎所有探讨和交流!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。