使用飞桨AI Studio平台训练数据,并进行图像识别分析得牡丹花测试
Y小夜 2024-10-15 10:01:03 阅读 93
🎼个人主页:【Y小夜】
😎作者简介:一位双非学校的大二学生,编程爱好者,
专注于基础和实战分享,欢迎私信咨询!
🎆入门专栏:🎇【MySQL,Java基础,Rust】
🎈热门专栏:🎊【Python,Javaweb,Vue框架】
感谢您的点赞、关注、评论、收藏、是对我最大的认可和支持!❤️

目录
🎊飞桨平台
🎊整理数据
✨建一个文件夹
✨在test文件夹中建立images文件夹
✨写自动标注
✨写训练集
✨写测试集
✨将test文件打包
🎊上传数据
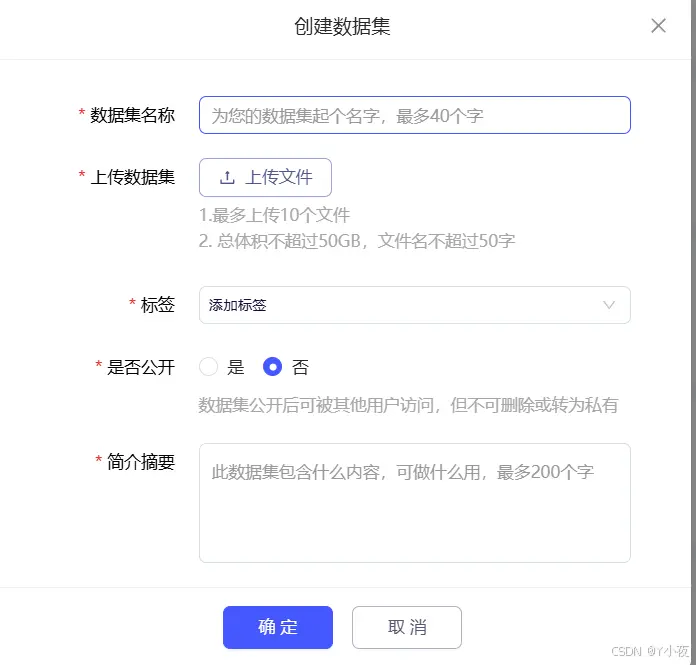
✨点击侧边栏的数据——>创建数据集
✨填写信息
✨数据集显示完毕
🎊训练数据
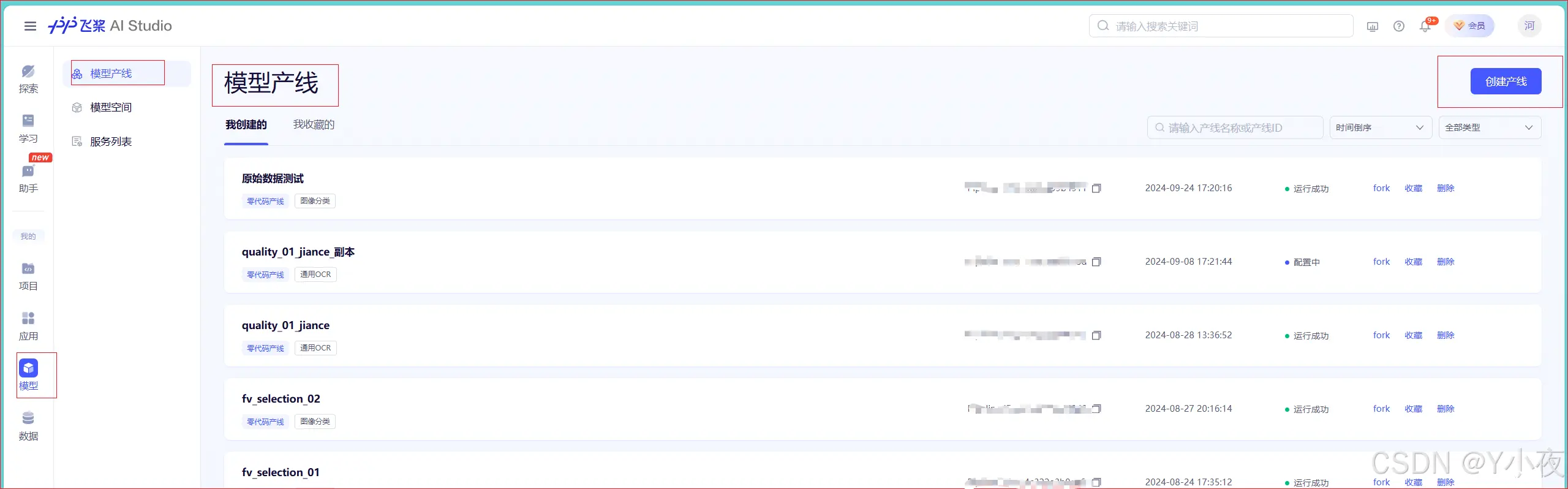
✨模型——>模型产线——>创建产线
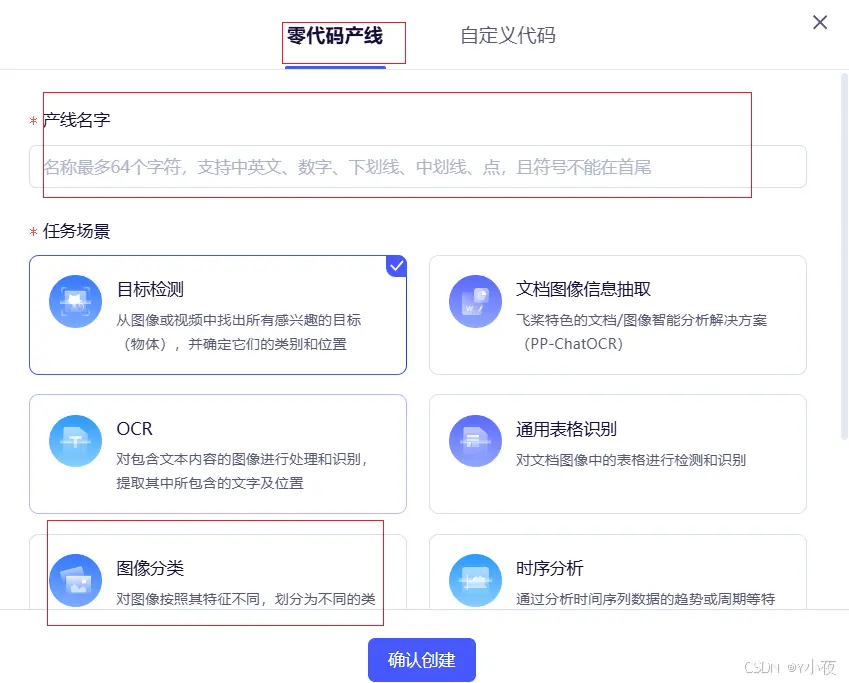
✨选择产线
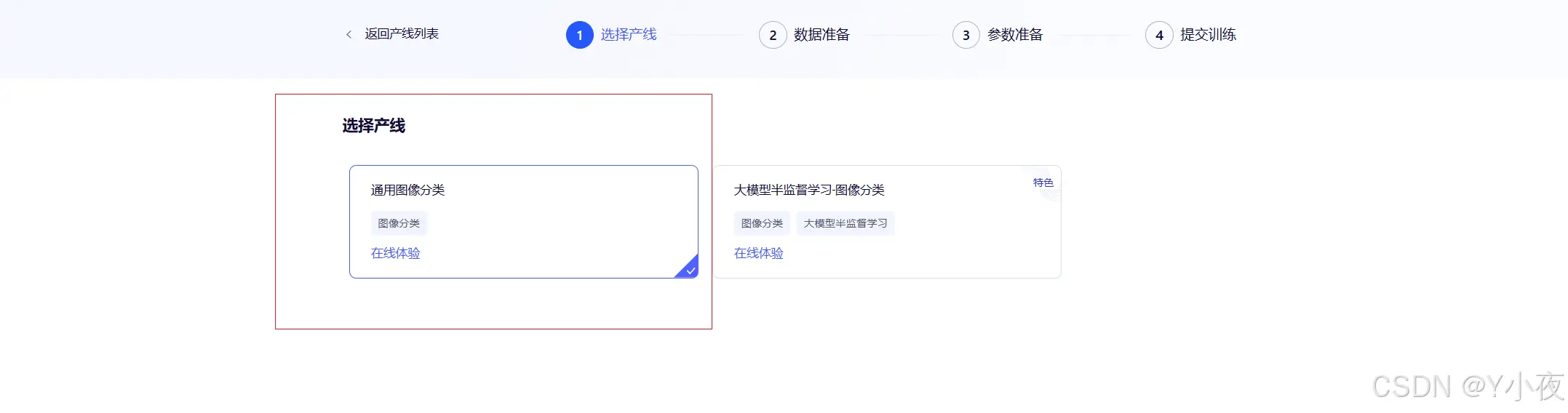
✨选择产线类型
✨然后进行训练
✨显示正在运行之中
🎊特别注意事项
✨进行评估
✨进行部署
🎊进行测试
🎊飞桨平台
飞桨致力于人工智能的技术创新和大规模产业化,系统地建立了产业级深度学习开发、训练和部署全流程技术体系。主要领先技术如下:
开发便捷的深度学习框架。飞桨深度学习框架基于编程一致的深度学习计算抽象以及对应的前后端设计,拥有易学易用的前端编程界面和统一高效的内部核心架构,对普通开发者而言更容易上手并具备领先的训练性能。飞桨自然完备兼容命令式和声明式两种编程范式,是业内首个实现动静统一的深度学习框架,开发者默认使用动态图编程调试,一行代码即可转静态图训练部署。飞桨框架还提供了低代码开发的高层 API, 并且高层 API 和基础 API 采用了一体化设计,两者可以互相配合使用,做到高低融合,兼顾开发的便捷性和灵活性。
超大规模深度学习模型训练技术。飞桨突破了超大规模深度学习模型训练技术,率先实现了千亿稀疏特征、万亿参数、数百节点并行训练的能力,解决了超大规模深度学习模型的在线学习和部署难题。此外, 飞桨还覆盖支持包括模型并行、流水线并行在内的广泛并行模式和加速策略,推出业内首个通用异构参数服务器架构、4D 混合并行策略和端到端自适应分布式训练技术,引领大规模分布式训练技术的发展趋势。
多端多平台部署的高性能推理引擎。飞桨对推理部署提供全方位支持,可以将模型便捷地部署到云端、边缘端和设备端等不同平台上,结合训推一体的优势,让开发者拥有一次训练、随处部署的体验;飞桨从硬件接入、调度执行、高性能计算和模型压缩四个维度持续对推理功能深度优化,整体性能领先;在硬件接入方面,飞桨拥有硬件统一适配方案,携手各大硬件厂商软硬一体协同优化,大幅降低硬件厂商的对接成本,并带来领先的开发体验,特别是对国产硬件做到了广泛的适配。
产业级开源模型库。飞桨建设了大规模官方模型库,算法总数超过 700 个,包含领先的预训练模型、深度学习开发者经过产业实践长期打磨的主流模型以及在国际竞赛中的夺冠模型;提供面向语义理解、图像分类、目标检测、图像分割、文字识别(OCR)、语音合成等场景的多个端到端开发套件,满足企业低成本开发和快速集成的需求,助力快速产业应用。飞桨模型库是基于丰富产业实践打造的产业级模型库,服务企业遍布能源、金融、工业、农业等多个行业。其中产业级知识增强的文心大模型,已经形成涵盖基础大模型、任务大模型和行业大模型的三级体系。
🎊整理数据
✨建一个文件夹
这个文件夹用于存储图片,以及标签

✨在test文件夹中建立images文件夹
用于存储a训练集和测试集的图片
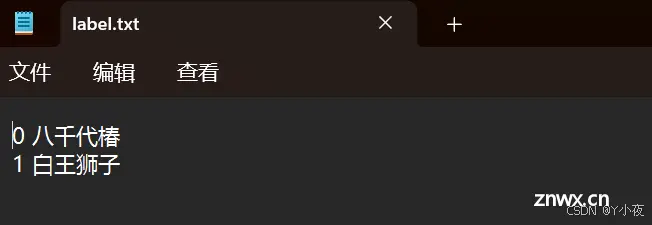
✨写自动标注

✨写训练集


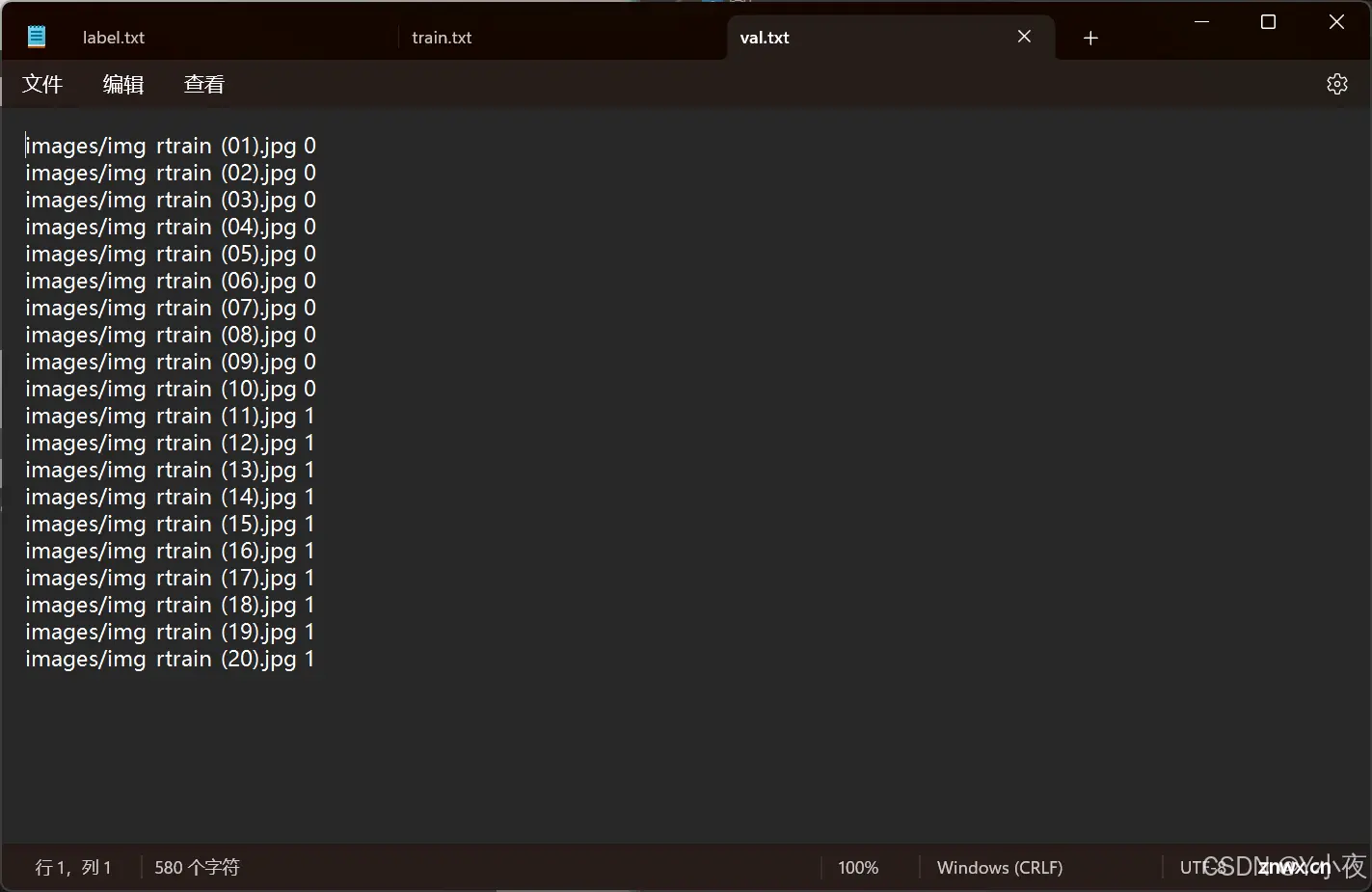
✨写测试集
✨将test文件打包
将test文件压缩成压缩包
🎊上传数据
✨点击侧边栏的数据——>创建数据集
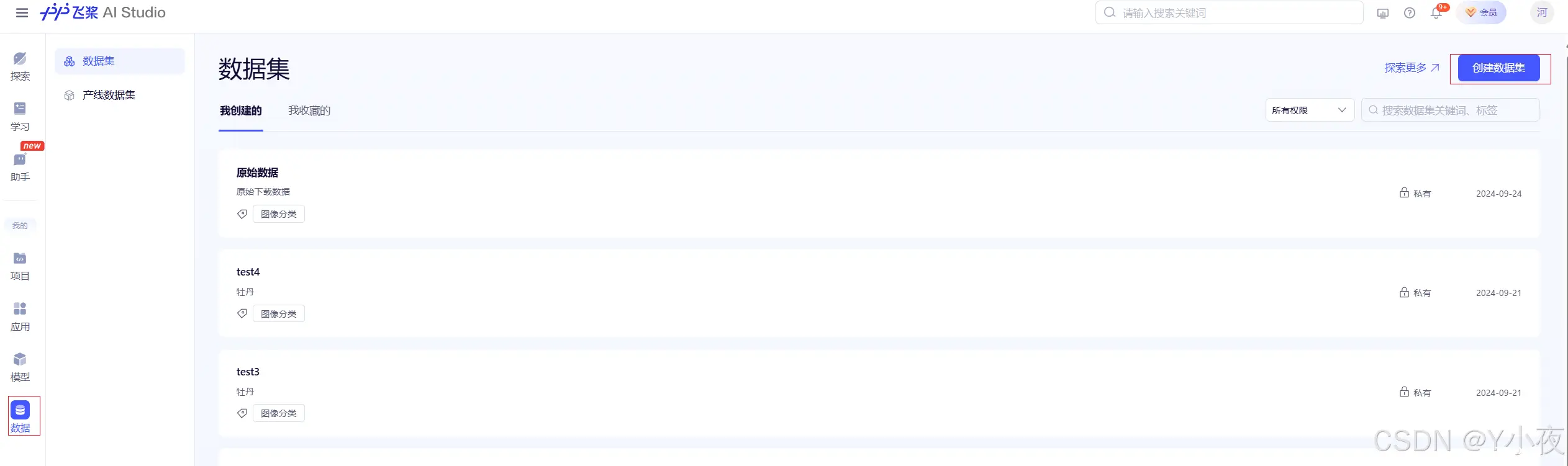
✨填写信息

✨数据集显示完毕

🎊训练数据
✨模型——>模型产线——>创建产线
✨选择产线
选择零代码产线,然后进行图像分类
✨选择产线类型
✨然后进行训练
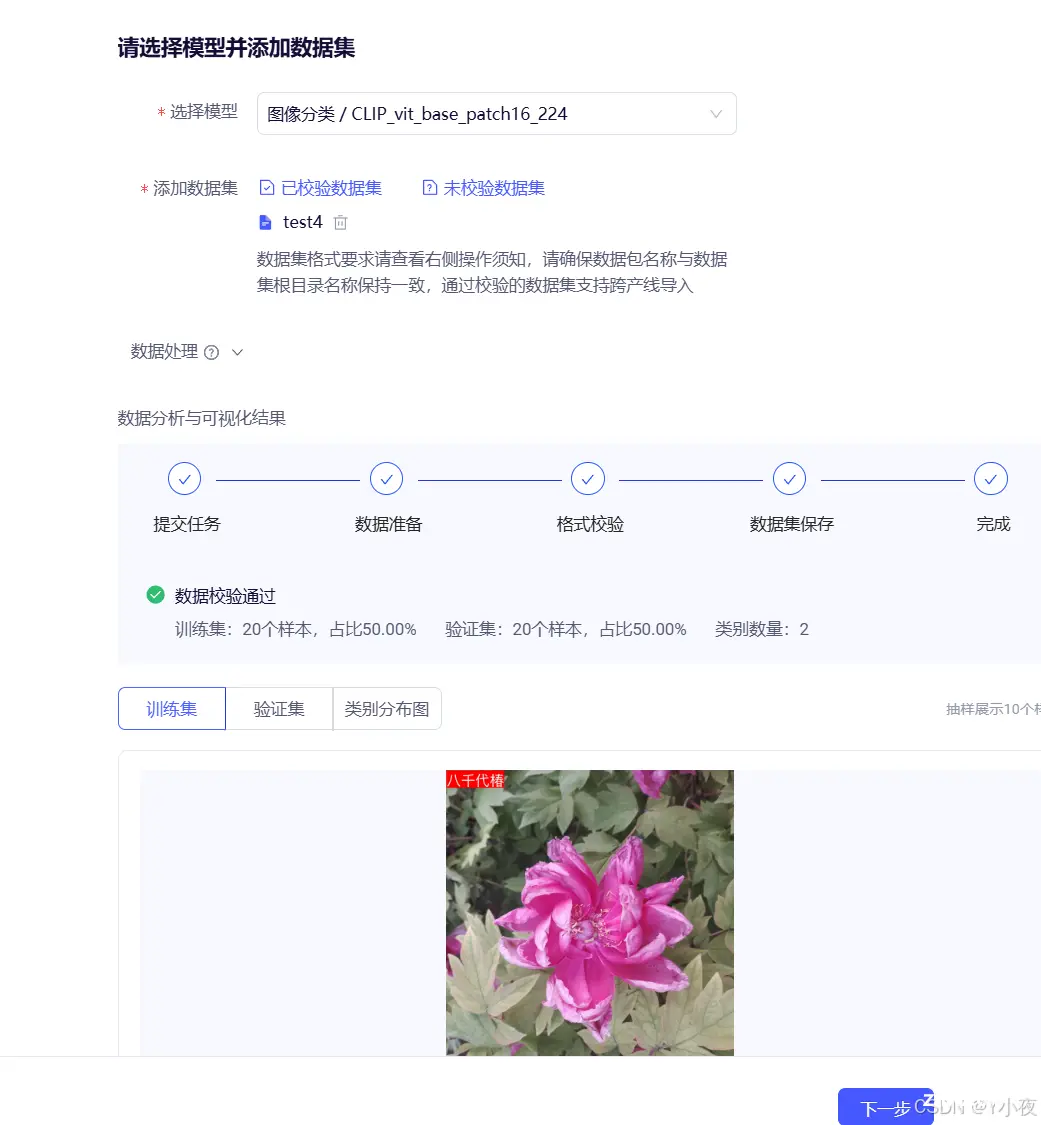

✨显示正在运行之中
等待运行完毕

🎊特别注意事项
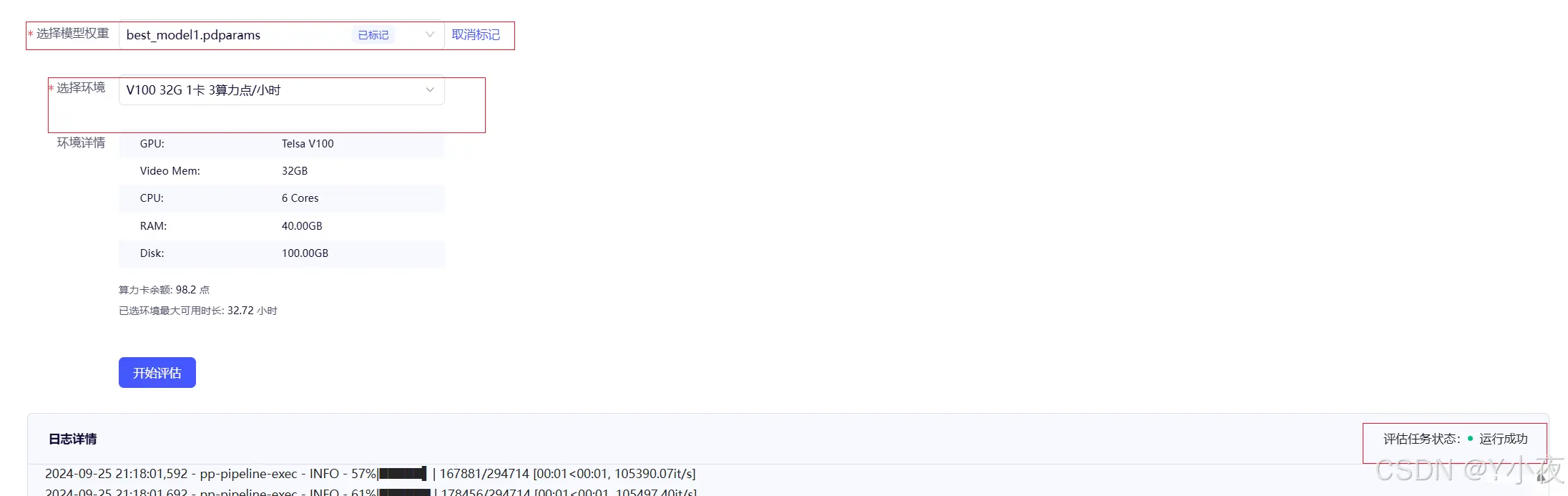
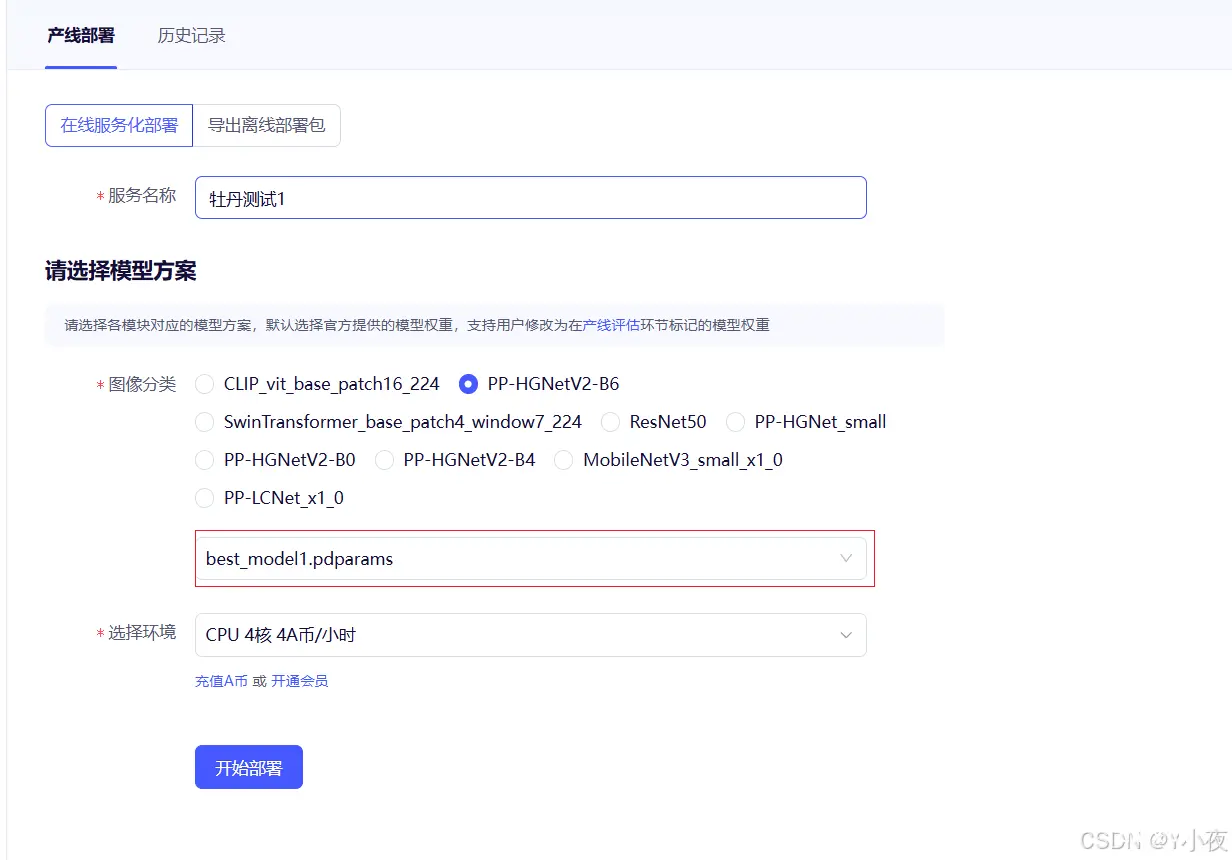
模型训练完后,在评估阶段要对权重进行标注,同时部署的时候选中标记权重才能使新训练的模型权重生效,否则默认调用的是预训练模型权重,分类标签和结果也是预训练模型的,而不是自己创建的。

✨进行评估
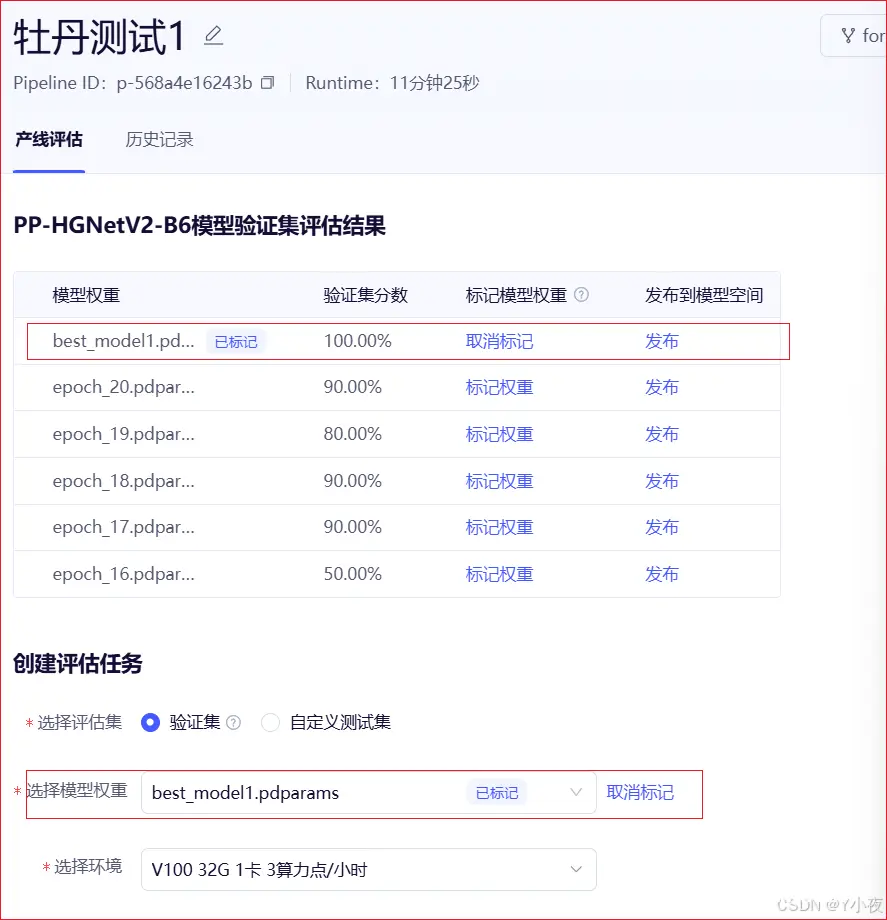
评估成功
✨进行部署
🎊进行测试
点击前往应用体验

上传测试图片、改变模型方案
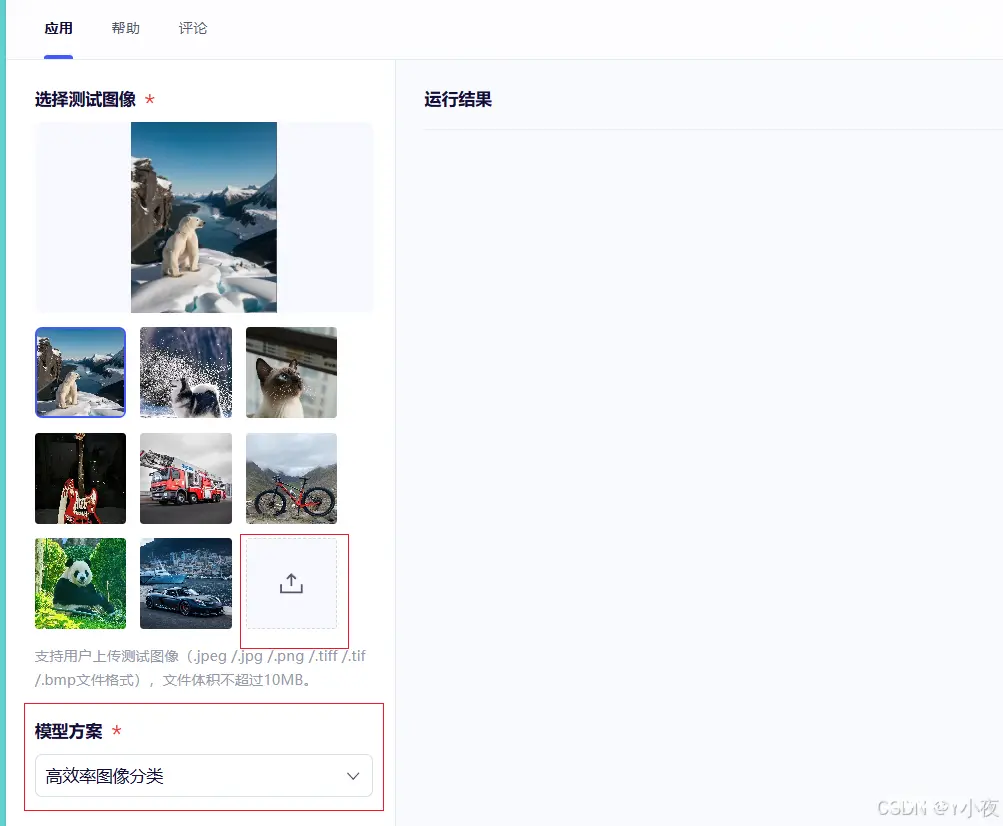
运行并识别成功

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。