【飞桨AI实战】交通灯检测:手把手带你入门PaddleDetection,从训练到部署
AI码上来 2024-08-06 16:31:02 阅读 51
前言
本次分享将带领大家从0到1完成一个目标检测任务的模型训练评估和推理部署全流程,项目将采用以PaddleDetection为核心的飞浆深度学习框架进行开发,并总结开发过程中踩过的一些坑,希望能为有类似项目需求的同学提供一点帮助。
项目背景和目标
背景:
目标检测是计算机视觉的一个基础任务。本次选用的案例来自智慧交通中的交通灯检测,由于自动驾驶场景中对实时性有更高要求,本次采用YOLO系列神经网络进行模型训练和部署。
目标:
基于paddlepaddle深度学习框架完成一个目标检测任务;完成模型的训练、评估、预测和部署等深度学习任务全过程。
百度AI Studio平台
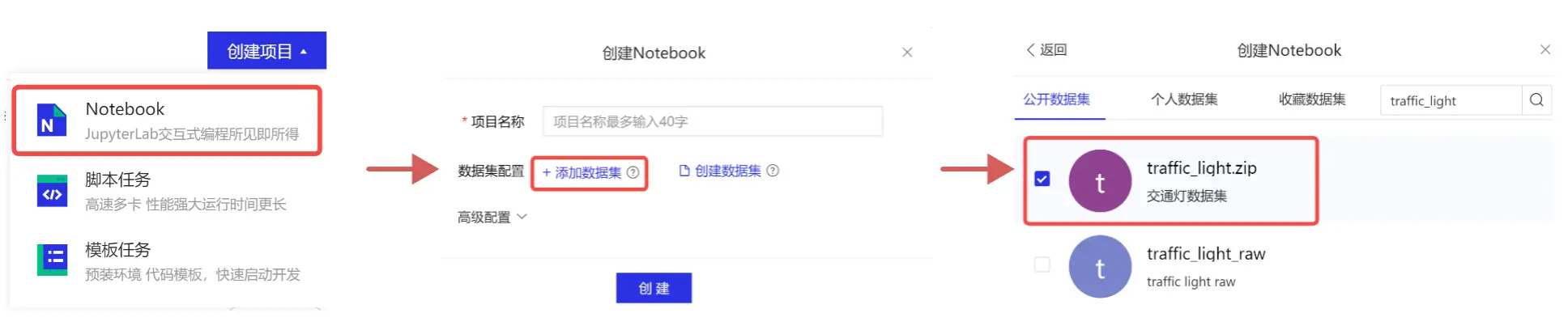
本次实验将采用AI Studio实训平台中的免费GPU资源,在平台注册账号后,点击创建项目-选择NoteBook任务,然后添加数据集,如下图所示,完成项目创建。启动环境可以自行选择CPU资源 or GPU资源,创建任务每天有8点免费算力,推荐大家使用GPU资源进行模型训练,这样会大幅减少模型训练时长。
数据集介绍
本次实验使用的数据集是BOSCH开源的交通灯数据集,基于视觉的交通信号灯检测和跟踪是城市环境中实现全自动驾驶的关键一步,数据集总共有5093张图片,手动划分为训练集、验证集和测试集,其中训练集2832张,验证集1684,测试集577张。包含多种交通灯类型,包括RedLeft、Red、RedRight、GreenLeft、Green、GreenRight、Yellow和off等。

飞浆深度学习开发框架介绍
PaddlePaddle百度提供的开源深度学习框架,其中文名是“飞桨”,致力于为开发者和企业提供最好的深度学习研发体验,国产框架中绝对的榜一大哥!其核心优势是生态完善,目前集成了各种开发套件,覆盖了数据处理、模型训练、模型验证、模型部署等各个阶段的工具。下面简要介绍一下本项目用到的几个核心组件:
PaddleDetection:一个目标检测任务的工具集,集成了丰富的主流检测算法和百度自研的最新模型,提供覆盖检测任务全流程的API。PaddleSlim:一个模型压缩库,集成了主流的模型压缩算法,包括量化、裁剪等。PaddleServing:将模型部署成一个在线预测服务的库,支持服务端和客户端之间的高并发和高效通信。PaddleLite:将模型转换成可以端侧推理的库,比如将模型部署到手机端进行推理。
从零开发
1 PaddleDetection完成模型训练
1.1 安装PaddleDetection
在项目中打开终端,然后运行如下命令:
<code># (可选)conda安装虚拟环境,环境会持久保存在项目中
conda create -p envs/py38 python=3.8
source activate envs/py38
# 安装paddlepaddle,根据云端环境选择cpu版本和gpu版本
pip install --upgrade paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install --upgrade paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
# 克隆PaddleDetection仓库
git clone https://github.com/PaddlePaddle/PaddleDetection.git
# 安装其他依赖
cd PaddleDetection
pip install -r requirements.txt
# 编译安装paddledet
python setup.py install
# 测试是否安装成功
python ppdet/modeling/tests/test_architectures.py
# 推理一张图像试试
python tools/infer.py -c configs/ppyolo/ppyolo_r50vd_dcn_1x_coco.yml -o use_gpu=true weights=https://paddledet.bj.bcebos.com/models/ppyolo_r50vd_dcn_1x_coco.pdparams --infer_img=demo/000000014439.jpg
1.2 数据准备
我们需要制作符合PaddleDetection框架要求的数据集格式:参考PrepareDetDataSet.md,这里选择VOC格式。
step1: 解压数据集
cd data
unzip data119115/traffic_light.zip
step2: 制作标签文件
python generate_voc_dataset.py
# 其中generate_dataset.py中的代码如下:
import os
import numpy as np
import xml.etree.ElementTree as ET
root_dir = '/home/aistudio/data/traffic_light'
train_anno_dir = os.path.join(root_dir, 'train/annotations/xmls')
train_image_dir = os.path.join(root_dir, 'train/images')
valid_anno_dir = os.path.join(root_dir, 'var/annotations/xmls')
valid_image_dir = os.path.join(root_dir, 'var/images')
test_image_dir = os.path.join(root_dir, 'test/images')
# get class names
class_names = set()
anno_files = os.listdir(train_anno_dir) + os.listdir(valid_anno_dir)
for anno in anno_files:
fpath = os.path.join(train_anno_dir, anno)
if not os.path.exists(fpath):
fpath = os.path.join(valid_anno_dir, anno)
tree = ET.parse(fpath)
objs = tree.findall('object')
for i, obj in enumerate(objs):
cname = obj.find('name').text
class_names.add(cname)
print(class_names, len(class_names))
with open(os.path.join(root_dir, 'label_list.txt'), 'w') as f:
f.writelines(f'{cname}\n' for cname in class_names)
# get train data
image_files = os.listdir(train_image_dir)
with open(os.path.join(root_dir, 'train.txt'), 'w') as f:
for ifile in image_files:
afile = ifile.replace('.png', '.xml')
f.write(f'train/images/{ifile} train/annotations/xmls/{afile}\n')
print('train ready')
# get valid data
image_files = os.listdir(valid_image_dir)
with open(os.path.join(root_dir, 'valid.txt'), 'w') as f:
for ifile in image_files:
afile = ifile.replace('.png', '.xml')
f.write(f'var/images/{ifile} var/annotations/xmls/{afile}\n')
print('valid ready')
# get test data
image_files = os.listdir(test_image_dir)
with open(os.path.join(root_dir, 'test.txt'), 'w') as f:
for ifile in image_files:
f.write(f'test/images/{ifile}\n')
print('test ready')
step3: 新建数据集配置文件
# 新建数据集配置文件
在`PaddleDetection/configs/datasets`中新建traffic_light_voc.yml
其中写入:
metric: VOC
map_type: integral
num_classes: 12
TrainDataset:
name: VOCDataSet
dataset_dir: /home/aistudio/data/traffic_light
anno_path: train.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
EvalDataset:
name: VOCDataSet
dataset_dir: /home/aistudio/data/traffic_light
anno_path: valid.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
TestDataset:
name: ImageFolder
anno_path: /home/aistudio/data/traffic_light/label_list.txt
如上,我们便完成了数据的准备工作,接下来将完成模型在该数据集上的训练。
1.3 模型训练:
这里我们以选用PaddleDetection自带的yoloV3为例,有关该模型的介绍可参考官方文档。
准备训练配置文件:
配置文件具体含义说明可参考:GETTING_STARTED_cn.md
# 复制一份训练配置文件,并改名为yolov3_mobilenet_v1_trafficlight.yml
cp configs/yolov3/yolov3_mobilenet_v1_roadsign.yml configs/yolov3/yolov3_mobilenet_v1_trafficlight.yml
# 修改其中的数据集配置为我们刚新建的数据集配置文件:
_BASE_: [
'../datasets/traffic_light_voc.yml',
...
]
开启训练
# 这里需要使用云端GPU环境,cpu环境训练跑不起来
python tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_trafficlight.yml --eval
# 由于训练时间较长,将任务放到后台运行,避免关闭终端导致任务终止
nohup python tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_trafficlight.yml --eval > output.log &
训练成功后,可以在终端查看训练过程,loss下降说明没问题

1.4 模型评估和测试
默认训练生成的模型保存在当前output文件夹下
<code>python tools/eval.py -c configs/yolov3/yolov3_mobilenet_v1_trafficlight.yml -o weights=output/best_model.pdparams
单张图像测试
python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v1_trafficlight.yml --infer_img=../data/traffic_light/train/images/100296.png -o weights=output/best_model.pdparams
1.5 模型导出
目的:将训练得到的最好模型转成部署需要的inference model
python tools/export_model.py -c configs/yolov3/yolov3_mobilenet_v1_trafficlight.yml --output_dir=output/inference_model -o weights=output/best_model
运行成功后结果如下图所示:

2 PaddleSlim完成模型压缩
为什么:训练得到的模型往往参数量较大,影响推理耗时。
怎么做:基于PaddleSlim进行模型压缩,推荐使用剪裁和蒸馏联合训练,或者使用剪裁、量化训练和离线量化,进行检测模型压缩。下面以裁剪为例,说明如何对yolov3_mobilenet进行模型压缩。
2.1 安装PaddleSlim
<code># 注意这里要用最新版的paddlepaddle=2.6.0,否则出现版本不匹配的问题
## https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html这里可以看到paddle最新版本已经不支持python3.7
pip install paddleslim -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2 重新训练
# 需要指定--slim_config
python tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_trafficlight.yml --slim_config configs/slim/prune/yolov3_prune_l1_norm.yml -o pretrain_weights=output/best_model.pdparams --eval

2.3 评估测试
<code># 评估
python tools/eval.py -c configs/yolov3/yolov3_mobilenet_v1_trafficlight.yml --slim_config configs/slim/prune/yolov3_prune_l1_norm.yml -o weights=output/best_model.pdparams
# 测试
python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v1_trafficlight.yml --slim_config configs/slim/prune/yolov3_prune_l1_norm.yml --infer_img=../data/traffic_light/train/images/100296.png -o weights=output/best_model.pdparams

由于我这里仅为了跑通流程,所以目前mAP比较低,大家可以增加训练轮数。
2.4 模型导出
python tools/export_model.py -c configs/yolov3/yolov3_mobilenet_v1_trafficlight.yml --slim_config configs/slim/prune/yolov3_prune_l1_norm.yml --output_dir=output/inference_model -o weights=output/best_model
# 报错解决
`RuntimeError: Can't call main_program when full_graph=False. Use paddle.jit.to_static(full_graph=True) instead.`
# 需要对PaddleDetection/ppdet/engine/trainer.py进行修改
if prune_input:
# static_model = paddle.jit.to_static(
# self.model, input_spec=input_spec)
static_model = paddle.jit.to_static(
self.model, input_spec=input_spec, full_graph=True)
3 模型推理部署
3.1 基于python预测引擎推理
直接调用PaddleDetection中的python接口
## 采用未裁剪模型
python deploy/python/infer.py --model_dir=./output/inference_model/yolov3_mobilenet_v1_trafficlight --image_file=../data/traffic_light/train/images/100296.png
## 采用裁剪后模型
python deploy/python/infer.py --model_dir=./output/inference_model/yolov3_prune_l1_norm --image_file=../data/traffic_light/train/images/100296.png
结果展示:可以发现裁剪后模型的耗时更低,但有漏检,这是因为裁剪模型尚未得到充分训练。


3.2 PaddleServing服务端部署
这个部分的目的是将我们的模型部署成一个服务,客户端就可以通过http或rpc进行,飞浆已对上述需求所需要的功能实现进行了封装,需要调用PaddleServing库,详情可参考:deploy和deploy/serving
step1: 安装PaddleServing包
<code>pip install paddle-serving-client==0.7.0
pip install paddle-serving-app==0.7.0
## 若为CPU部署环境:
pip install paddle-serving-server==0.7.0
## 若为GPU部署环境:
pip install paddle-serving-server-gpu==0.7.0.post102
## 上述安装包如果找不到,需要下载到本地安装,在官网查找对应的版本
https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/Latest_Packages_CN.md
step2: 导出PaddleServing格式的模型
# 需要设置export_serving_model=True
python tools/export_model.py -c configs/yolov3/yolov3_mobilenet_v1_trafficlight.yml --output_dir=output/inference_model -o weights=output/best_model --export_serving_model=True
# 成功后会在output/inference_model/yolov3_mobilenet_v1_trafficlight文件夹下多出serving_client和serving_server文件夹
# 注意:需要修改serving_client和serving_server文件夹中"multiclass_nms3_0.tmp_0"对应的is_lod_tensor: true
fetch_var {
name: "multiclass_nms3_0.tmp_0"
alias_name: "multiclass_nms3_0.tmp_0"
is_lod_tensor: true
fetch_type: 1
shape: 6
}
step3: 启动服务
# 用cpu
python -m paddle_serving_server.serve --model serving_server --port 9393
# 用gpu
python -m paddle_serving_server.serve --model serving_server --port 9393 --gpu_ids 0
注意,这里可能出现报错:
ImportError: libnvinfer.so.7: cannot open shared object file: No such file or directory。
原因分析:这是因为没有安装tensorrt。怎么解决:可参考这篇博文:报错解决ImportError: libnvinfer.so.7
step4: 测试服务
python ../../../deploy/serving/test_client.py ~/data/traffic_light/label_list.txt ~/data/traffic_light/train/images/100296.png
注意,这里可能出现报错:
ImportError: libcrypto.so.10: cannot open shared object file: No such file or directory ImportError: libssl.so.10: cannot open shared object file: No such file or directory,
原因分析:这是因为ssl版本的问题怎么解决:可参考这篇博文:报错解决ImportError: libcrypto.so.10
还可能出现报错:
'ImageDraw' object has no attribute 'textsize'
原因分析:因为最新版的pillow==10.0.0中textsize 已被弃用,正确的属性是 textlength怎么解决:安装旧版本: pip install Pillow==9.5.0
再重新测试,成功后在当前目录的output下生成预测图片和结果

3.3 PaddleLite端侧部署
这个部分的目的是将我们的模型部署到移动端(比如手机),这样就不用依赖云端服务器来进行推理了,飞浆已对上述需求所需要的功能实现进行了封装,主要体现在PaddleLite这个组件上,细节可参考官方教程PaddleLite端侧部署。
端侧部署相对稍微复杂一些,主要可以分为以下几个步骤进行:
3.3.1 模型优化
考虑到端侧对推理耗时要求比较高,故需要采用paddlelite对inference模型做进一步优化。
# 在output/inference_model/yolov3_mobilenet_v1_trafficlight/文件夹下新建lite
mkdir lite
# 生成lite模型-FP32
paddle_lite_opt --valid_targets=arm --model_file=model.pdmodel --param_file=model.pdiparams --optimize_out=lite/model
# 生成lite模型-FP16
paddle_lite_opt --valid_targets=arm --model_file=model.pdmodel --param_file=model.pdiparams --optimize_out=lite/model --enable_fp16=true
# 将inference模型配置转化为json格式
python ../../../deploy/lite/convert_yml_to_json.py infer_cfg.yml
# 以上两步会生成lite/model.nb infer_cfg.json
3.3.2 准备交叉编译环境
这一步是为了在Linux系统中编译生成在Android手机上的可执行文件。
cd ~
# 下载 linux-x86_64 版本的 Android NDK, 并添加系统环境变量
wget https://dl.google.com/android/repository/android-ndk-r17c-linux-x86_64.zip
unzip android-ndk-r17c-linux-x86_64.zip
export NDK_ROOT=/home/aistudio/android-ndk-r17c # 注意路径
# 下载paddlelite的交叉编译库-注意这里的版本2.13要和上面的paddlelite==2.13对应上, 模型FP32/16版本需要与库相对应
wget https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.13-rc/inference_lite_lib.android.armv8.clang.c++_shared.with_extra.with_cv.arm82_fp16.tar.gz
# 如果国内下载太慢,加上镜像https://mirror.ghproxy.com/
wget https://mirror.ghproxy.com/https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.13-rc/inference_lite_lib.android.armv8.clang.c++_shared.with_extra.with_cv.arm82_fp16.tar.gz
tar -xf inference_lite_lib.android.armv8.clang.c++_shared.with_extra.with_cv.arm82_fp16.tar.gz
# 新建一个文件夹用于编译
mkdir inference_lite_lib.android.armv8.clang.c++_shared.with_extra.with_cv.arm82_fp16/demo/cxx/lite
3.3.3 执行编译
这一步会得到手机端的可执行文件main,下面以华为Mate30为例,其cpu是armv8架构,如果选用其他手机,需要查看其处理器架构是armv8还是armv7。
cd ~/PaddleDetection/deploy/lite
cp -r Makefile src/ include/ *runtime_config.json ~/inference_lite_lib.android.armv8.clang.c++_shared.with_extra.with_cv.arm82_fp16/demo/cxx/lite
cd inference_lite_lib.android.armv8.clang.c++_shared.with_extra.with_cv.arm82_fp16/demo/cxx/lite
# 执行编译命令
export NDK_ROOT=/home/aistudio/android-ndk-r17c # 注意路径
make
## 编译成功后,会在当前目录生成 main 可执行文件,该文件用于手机端推理
3.3.4 准备手机端推理的数据
mkdir deploy # 新建文件夹用于存放所有数据
cp main *runtime_config.json deploy/
mkdir deploy/model_det # 新建文件夹用于存放模型
cp ~/PaddleDetection/output/inference_model/yolov3_mobilenet_v1_trafficlight/lite/* deploy/model_det/
# 准备一张测试图片
cp ~/data/traffic_light/train/images/100296.png deploy/
# 将C++预测动态库so文件复制到deploy文件夹中
cp ../../../cxx/lib/libpaddle_light_api_shared.so deploy/
# 最终得到的文件目录如下
deploy/
├── 100296.png
├── det_runtime_config.json
├── keypoint_runtime_config.json
├── libpaddle_light_api_shared.so
├── main
└── model_det
├── infer_cfg.json
└── model.nb
# 注意:det_runtime_config.json 包含了目标检测的超参数,请按需进行修改
3.3.5 和手机联调
将可执行文件、模型文件和测试图片推送到手机上,进行联调。
# 第一步:windows安装adb
谷歌的安卓平台下载ADB软件包进行安装:链接
安装好后adb.exe 一般保存在C:\Users\用户名xx\AppData\Local\Android\Sdk\platform-tools
需要将其加到系统环境变量中:
-- 以win11为例,系统-系统信息-高级系统设置-环境变量
-- 新建AndroidHome=C:\Users\用户名xx\AppData\Local\Android\Sdk
-- Path-新建:%AndroidHome%\platform-tools
# 第二步:手机连接电脑
华为Mate30手机为例:
- 开启开发者模式:设置-关于手机-点击“版本号”多次直到提示“您已进入开发者模式”
- 打开USB调试:设置-系统与更新-开发人员选项-USB调试-选择USB配置(多媒体传输)
# 第三步:文件传输到手机
- 将所需文件下载到D:\Downloads\lite
- 在D:\Downloads\lite下打开终端:
adb devices # 显示设备
adb shell ls # 查看手机系统目录
# 使用adb push命令将文件夹中所有文件传输到手机上:
adb shell mkdir -p /data/local/tmp/
adb push deploy /data/local/tmp/
adb shell # 进入手机目录
cd /data/local/tmp/deploy
export LD_LIBRARY_PATH=/data/local/tmp/deploy:$LD_LIBRARY_PATH
# 修改权限为可执行
chmod 777 main
# 以检测为例,执行程序
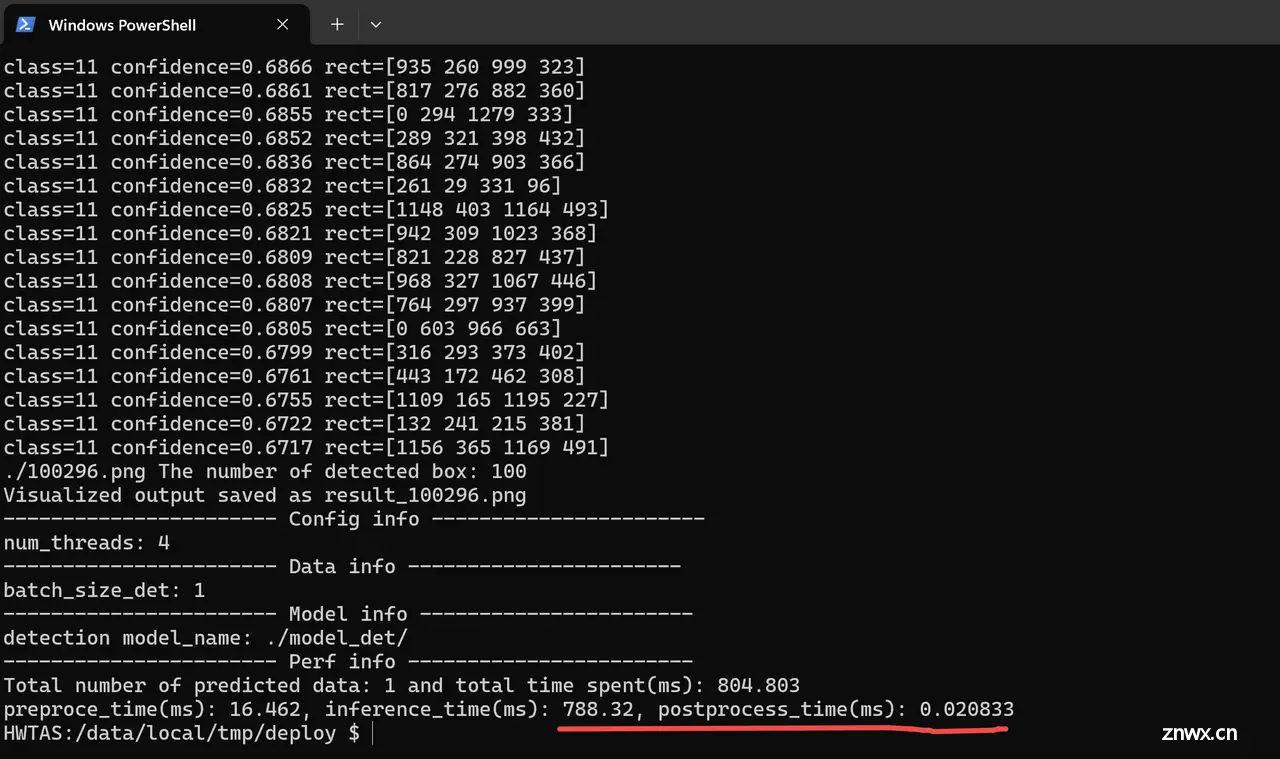
./main det_runtime_config.json
# 测试成功后,可将文件夹删除 rm -r /data/local/tmp/deploy
预测成功,看到如下结果:
3.4 ONNX模型推理
什么是ONNX:ONNX(Open Neural Network Exchange)是一个标准化工具,将不同训练框架训练的模型转换到统一的ONNX格式。ONNX模型中包含了神经网络模型的权重、结构信息以及网络中各层的输入输出等数据。
如何将paddle训练的模型转换成ONNX模型进行推理,两步走:
step1: ONNX模型导出
<code># 将部署模型转为ONNX格式
pip install paddle2onnx
# cd到inference模型路径
cd ~/PaddleDetection/output/inference_model/yolov3_mobilenet_v1_trafficlight
# YOLOv3
paddle2onnx --model_dir ./ --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file yolov3.onnx
## 导出后在当前目录生成yolov3.onnx

step2: onnxruntime进行推理
<code>pip install onnxruntime
# 执行推理
python ../../../deploy/third_engine/onnx/infer.py --infer_cfg infer_cfg.yml --onnx_file yolov3.onnx --image_file ~/data/traffic_light/train/images/100296.png

总结
本文通过一个计算机视觉领域中最基础的任务之目标检测,带领大家熟悉百度Paddle深度学习框架中的各种组件。案例选自智慧交通场景,有现实场景应用需求,本系列的后续文章将沿袭这一思路,继续分享更多采用Paddle深度学习框架服务更多产业应用的案例。
本文由mdnice多平台发布
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。