【一次成功】清华大学和智谱AI公司的ChatGLM-4-9B-Chat-1M大模型本地化部署教程
追寻上飞 2024-08-05 11:01:07 阅读 87
【一次成功】清华大学和智谱AI公司的ChatGLM-4-9B-Chat-1M大模型本地化部署教程
一、环境准备二、ChatGLM-4-9B-Chat-1M简介三、模型下载2.1 安装Git LFS2.2 初始化仓库2.3 同步Git文件2.4 拉取文件2.5 下载完毕
四、python和源码安装与下载4.1 安装python4.2 下载源码4.3 安装依赖4.4 python项目目录
五、运行5.1 修改运行文件5.2 运行文件5.3 执行结果
一、环境准备
操作系统:Windows 10 Intel® Core™ i7-14700KF 3.40 GHz 32GPython:v3.12.2pip:24.0

二、ChatGLM-4-9B-Chat-1M简介
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。 在语义、数学、推理、代码和知识等多方面的数据集测评中,GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出较高的性能。 除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。 本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。还推出了支持 1M 上下文长度(约 200 万中文字符)的模型。
三、模型下载
2.1 安装Git LFS
因为模型的问件较大,下载的话需要用到大文件插件,点击官网进行下载安装。
2.2 初始化仓库
<code>git lfs install
2.3 同步Git文件
从阿里云的魔搭社区仓库文件中同步。
git clone https://www.modelscope.cn/ZhipuAI/glm-4-9b-chat-1m.git GLM-4-9B-Chat-1M
2.4 拉取文件
git lfs pull
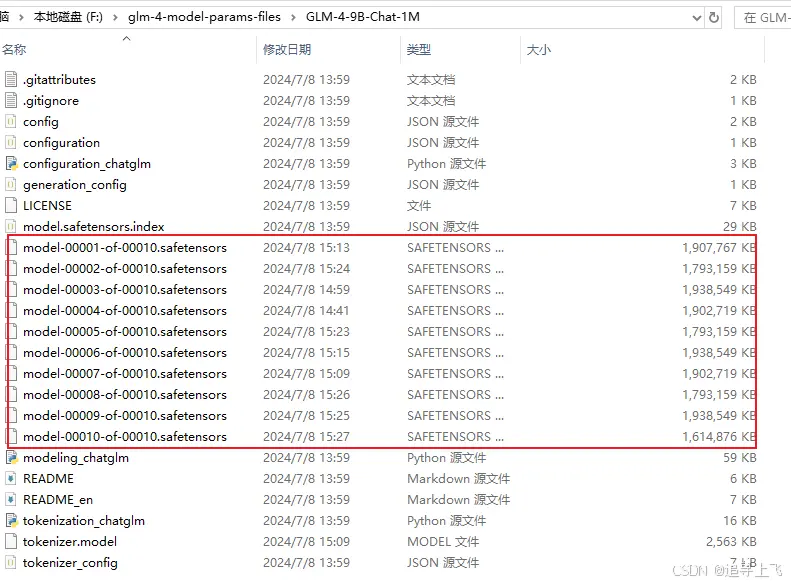
2.5 下载完毕
共计10个模型文件,每个约1.8G。
四、python和源码安装与下载
这里笔者走了两次弯路,
python版本太高,下载了最新版本的文件,安装不了依赖,前提是没有按照requirements文件版本进行安装;依赖直接下载,没有按照requirements文件进行下载,运行脚本时报以下错误,尝试解决未果,还是归结到环境。
<code>The attention mask is not set and cannot be inferred from input because pad
4.1 安装python
从华为云镜像文件源下载。

4.2 下载源码
官方源码地址为:
<code>https://github.com/THUDM/GLM-4.git
4.3 安装依赖
运行此命令从清华大学镜像源下载依赖。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
requirements.txt文件在源码目录下。
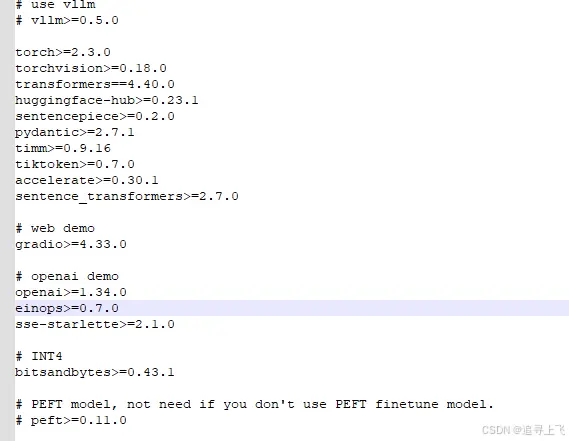
<code># 依赖项解释
## vllm
- **版本要求:** >=0.5.0
- **作用:** `vllm` 可能是指一个与机器学习相关的库,特别是用于语言模型。具体的细节和功能取决于库的实现。
## torch
- **版本要求:** >=2.3.0
- **作用:** `torch` 是 PyTorch 库,一个流行的开源机器学习库,用于 Python,提供广泛的 API 用于数值计算和神经网络。
## torchvision
- **版本要求:** >=0.18.0
- **作用:** `torchvision` 是 PyTorch 的视觉库,提供图像处理工具、数据集和预训练模型,主要用于计算机视觉任务。
## transformers
- **版本要求:** ==4.40.0
- **作用:** `transformers` 是 Hugging Face 提供的库,提供用于使用各种预训练模型(如 BERT、GPT-2 等)的 API,主要用于自然语言处理。
## huggingface-hub
- **版本要求:** >=0.23.1
- **作用:** `huggingface-hub` 是 Hugging Face 仓库的 Python 客户端,允许用户下载和使用模型、数据集和其他资源。
## sentencepiece
- **版本要求:** >=0.2.0
- **作用:** `sentencepiece` 是一个文本处理库,提供了一个无监督的文本分词器,用于文本分割和tokenization。
## pydantic
- **版本要求:** >=2.7.1
- **作用:** `pydantic` 是一个数据验证和设置管理工具,用于 Python 3.6+ 的类型提示,用于验证和序列化数据。
## timm
- **版本要求:** >=0.9.16
- **作用:** `timm` 是一个深度学习图像模型的 Python 库,提供了多种预训练模型和模型实用程序。
## tiktoken
- **版本要求:** >=0.7.0
- **作用:** `tiktoken` 是一个用于分割和计数 tokens 的库,常用于处理自然语言数据,特别是在使用特定模型时。
## accelerate
- **版本要求:** >=0.30.1
- **作用:** `accelerate` 是一个轻量级的库,用于加速 PyTorch 模型的训练,提供简单的 API 来优化训练过程。
## sentence_transformers
- **版本要求:** >=2.7.0
- **作用:** `sentence_transformers` 是一个用于计算句子、文档等的向量表示的 Python 库,提供了多种预训练模型。
## gradio
- **版本要求:** >=4.33.0
- **作用:** `gradio` 是一个用于创建简单 UI 的库,用于演示和测试机器学习模型,可以快速创建交互式界面。
## openai
- **版本要求:** >=1.34.0
- **作用:** `openai` 是 OpenAI API 的 Python 客户端,用于访问 OpenAI 的各种模型和服务,如 GPT-3。
## einops
- **版本要求:** >=0.7.0
- **作用:** `einops` 是一个用于张量操作的库,提供了一种简洁和可读的方式来重写、重塑和组合张量。
## sse-starlette
- **版本要求:** >=2.1.0
- **作用:** `sse-starlette` 是一个用于在 Python 3.6+ 中实现服务器发送事件(SSE)的库,用于构建实时 web 应用。
## bitsandbytes
- **版本要求:** >=0.43.1
- **作用:** `bitsandbytes` 是一个库,用于在 PyTorch 中实现更高效的内存使用和计算,特别是在使用低精度计算时。
## peft
- **版本要求:** >=0.11.0
- **作用:** `peft` 是 Parameter-Efficient Fine-Tuning 的缩写,是一个库,用于实现参数高效的微调方法,用于自然语言处理模型。如果你不使用 PEFT 微调模型,则不需要这个依赖项。
4.4 python项目目录
my_project/
|-- .git/ # Git版本控制目录(如果使用Git)
|-- .gitignore # Git忽略文件,用于指定不被Git跟踪的文件和目录
|-- .env # 环境变量文件,用于存储项目配置和环境变量
|-- .env.example # 环境变量示例文件,用于提供给开发者参考
|-- .editorconfig # 编辑器配置文件,用于统一不同编辑器的代码风格
|-- README.md # 项目说明文件,使用Markdown格式
|-- LICENSE # 项目许可证文件
|-- requirements.txt # Python项目依赖文件,列出所有依赖的包和版本
|-- setup.py # 项目安装脚本,用于安装项目及其依赖
|-- pytest.ini # Pytest测试配置文件(如果使用Pytest)
|-- tests/ # 测试目录,包含所有的测试代码
| |-- __init__.py
| |-- test_example.py
|-- src/ # 源代码目录(推荐使用src来避免与第三方包混淆)
| |-- my_project/ # 项目包目录
| |-- __init__.py
| |-- main.py # 主程序入口
| |-- utils.py # 工具函数和类
| |-- models/ # 模型目录
| |-- __init__.py
| |-- my_model.py
| |-- data/ # 数据处理目录
| |-- __init__.py
| |-- dataset.py
| |-- controllers/ # 控制器目录(如果使用MVC架构)
| |-- __init__.py
| |-- controller.py
| |-- views/ # 视图目录(如果使用MVC架构或模板渲染)
| |-- __init__.py
| |-- templates/
| |-- base.html
| |-- index.html
|-- docs/ # 项目文档目录
| |-- index.rst
| |-- ...
|-- examples/ # 示例代码目录
| |-- example.py
|-- scripts/ # 脚本目录,包含可执行脚本
| |-- run.sh
|-- config/ # 配置文件目录
| |-- settings.py
|-- logs/ # 日志文件目录
|-- .vscode/ # VS Code工作区配置目录(如果使用VS Code)
|-- Dockerfile # Docker镜像构建文件
|-- docker-compose.yml # Docker容器编排文件
五、运行
5.1 修改运行文件
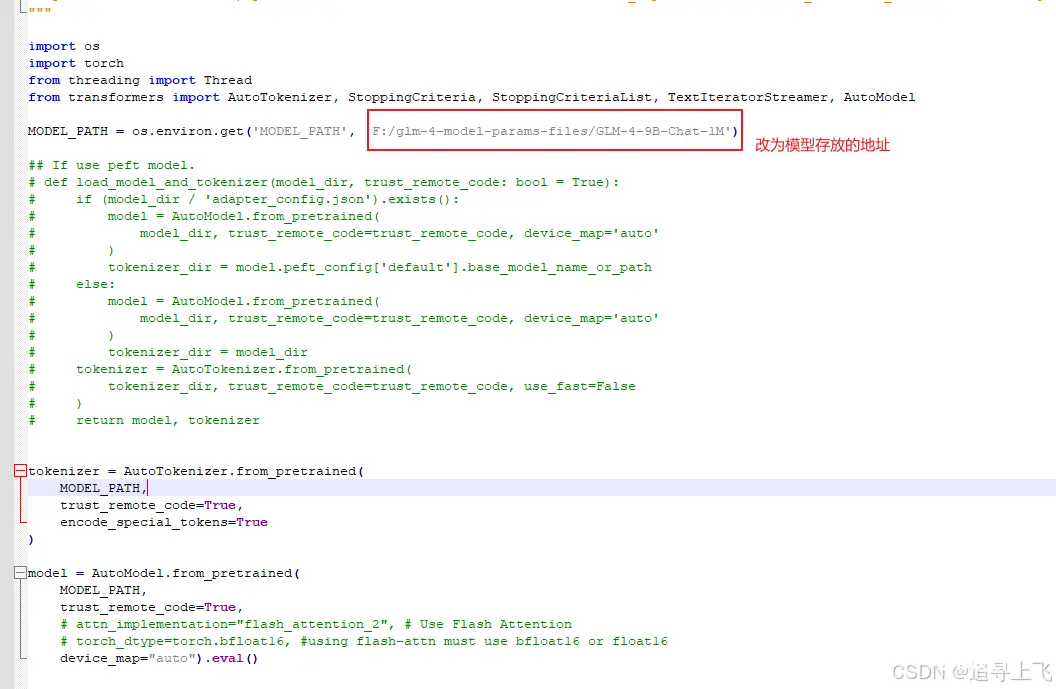
修改trans_cli_demo.py文件
更改的内容为:
5.2 运行文件
<code> python.exe .\trans_cli_demo.py
5.3 执行结果
每个字的推理速度差不多是30s。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。