智谱AI通用大模型:本地部署ChatGLM3-6B开源大模型
m0_37559973 2024-06-15 12:01:03 阅读 92
目录
一、ChatGLM3介绍
二、环境配置和检查
2.1 操作系统
2.2 硬件环境
2.3 软件环境
三、本地源码部署
3.1 克隆源码
3.2 下载模型文件
3.3 安装依赖
3.4 代码调用
四、运行Demo
4.1 设置本地模型环境变量
4.2 Gradio 网页版 Demo
4.3 Streamlit 网页版 Demo
4.4 命令行交互Demo
一、ChatGLM3介绍
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。
| 模型
| 介绍
| 代码链接
| 模型下载
|
|---|---|---|---|
| ChatGLM3-6B
| 第三代 ChatGLM 对话模型。ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。 | ChatGLM3 | Huggingface
魔搭社区
|
| ChatGLM3-6B-base
| 第三代ChatGLM基座模型。ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。 | Huggingface
魔搭社区
| |
| ChatGLM3-6B-32k
| 第三代ChatGLM长上下文对话模型。在ChatGLM3-6B的基础上进一步强化了对于长文本的理解能力,能够更好的处理最多32K长度的上下文。 | Huggingface
魔搭社区
| |
| ChatGLM3-6B-128k
| ChatGLM3-6B-128K在ChatGLM3-6B的基础上进一步强化了对于长文本的理解能力,能够更好的处理最多128K长度的上下文。具体地,我们对位置编码进行了更新,并设计了更有针对性的长文本训练方法,在对话阶段使用 128K 的上下文长度训练。在实际的使用中,如果您面临的上下文长度基本在 8K 以内,我们推荐使用ChatGLM3-6B;如果您需要处理超过 8K 的上下文长度,我们推荐使用ChatGLM3-6B-128K。 | Huggingface
魔搭社区
|
智谱AI所有的开源模型对学术研究完全开放,部分模型(ChatGLM系列)在填写问卷进行登记后亦允许免费商业使用。
二、环境配置和检查
2.1 操作系统
ChatGLM3-6B理论上可以在任何主流的操作系统中运行。ChatGLM开发组已经为主流操作系统做了一定的适配。
但是,我们更推荐开发者在 Linux环境下运行我们的代码,以下说明也主要针对Linux系统。
2.2 硬件环境
最低要求:
为了能够流畅运行 Int4 版本的 ChatGLM3-6B,我们在这里给出了最低的配置要求:
内存:>= 8GB
显存: >= 5GB(1060 6GB,2060 6GB)
为了能够流畅运行 FP16 版本的,ChatGLM3-6B,我们在这里给出了最低的配置要求:
内存:>= 16GB
显存: >= 13GB(4080 16GB)
如果使用CPU加载,可以忽略显存的要求,但是速度非常慢。
2.3 软件环境
Python环境
请开发者按照仓库中的requirements.txt来安装对应的依赖,并需要注意:
python 版本推荐3.10 - 3.11transformers 库版本推荐为 4.36.2torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能
三、本地源码部署
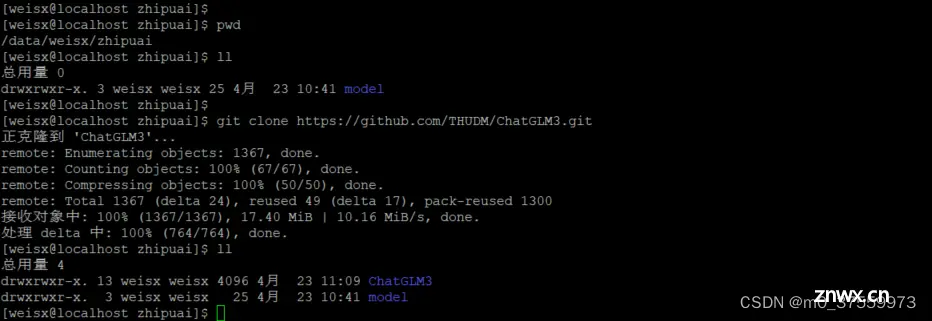
3.1 克隆源码
git clone https://github.com/THUDM/ChatGLM3.git
3.2 下载模型文件
可以Hugging Face Hub 下载模型,如果从 HuggingFace 下载比较慢,也可以从 ModelScope 中下载:
#从ModelScope下载模型
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
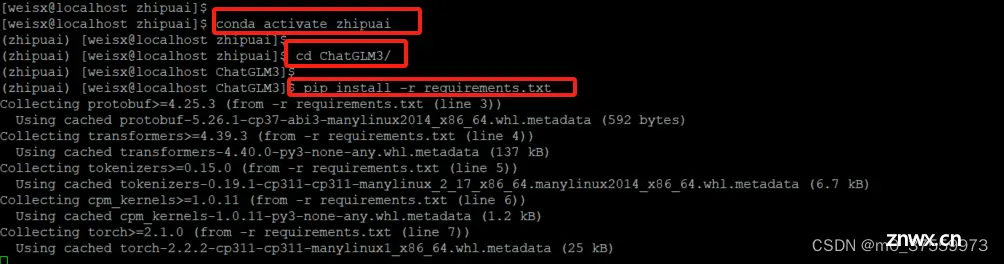
3.3 安装依赖
通过Conda安装一个新的python环境,在虚拟环境中安装依赖:
#1.0 新建python3.11环境
conda create --name zhipuai python=3.11
#1.1 激活zhipuai环境
conda activate zhipuai
#2. 进入 ChatGLM3 源码目录
cd ChatGLM3
#3. 默认安装不指定镜像[pip install -r requirements.txt]安装过程可能会出现依赖或者其它奇怪的错误,建议指定镜像源下载
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
在安装依赖过程中有可能出现某些依赖安装不了,可以去国内主流的资源镜像平台(如清华大学镜像)下载对应的whl文件,然后通过pip install 安装离线文件,安装好之后,重新执行pip install -r requirements.txt 安装依赖。
3.4 代码调用
GPU 部署
model = AutoModel.from_pretrained("model/chatglm3-6b", trust_remote_code=True, device='cuda')
模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
model = AutoModel.from_pretrained("model/chatglm3-6b", trust_remote_code=True).quantize(4).cuda()
模型量化会带来一定的性能损失,经过测试,ChatGLM3-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。
CPU 部署
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("model/chatglm3-6b", trust_remote_code=True).float()
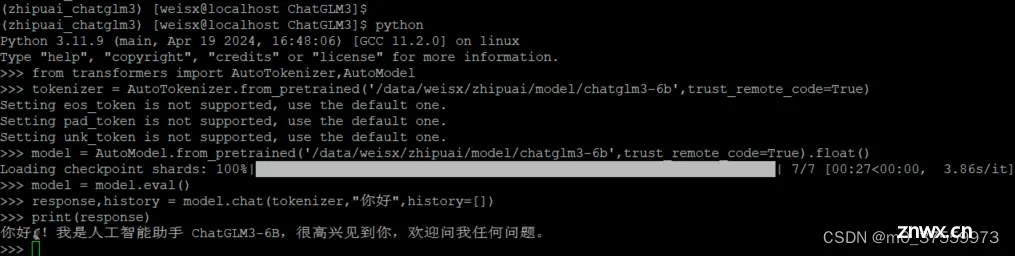
编写代码:
from transformers import AutoTokenizer,AutoModel#使用本地模型tokenizer = AutoTokenizer.from_pretrained('/data/weisx/zhipuai/model/chatglm3-6b',trust_remote_code=True)#使用CPUmodel = AutoModel.from_pretrained('/data/weisx/zhipuai/model/chatglm3-6b',trust_remote_code=True).float()model = model.eval()response,history = model.chat(tokenizer,"你好",history=[])print(response)
四、运行Demo
4.1 设置本地模型环境变量
export MODEL_PATH=/data/weisx/zhipuai/model/chatglm3-6b
4.2 Gradio 网页版 Demo
Gradio 是一个用于构建机器学习和数据科学项目的 Python 库,它允许用户通过简单的代码创建交互式网页,用户可以通过网页进行输入,并获取相应的输出。由于 Gradio 默认绑定的是本地地址(例如 127.0.0.1 或 localhost),而不是你的局域网或公网 IP 地址,所以 Gradio 创建的网页只能在本机访问,而不能在其他设备上访问。需要修改Gradio 启动参数,设置 share=True ,这样可以让你的应用通过本地网络访问,但不是所有环境都允许。
demo.launch(server_name="192.168.110.152", server_port=7870, inbrowser=True, share=True)
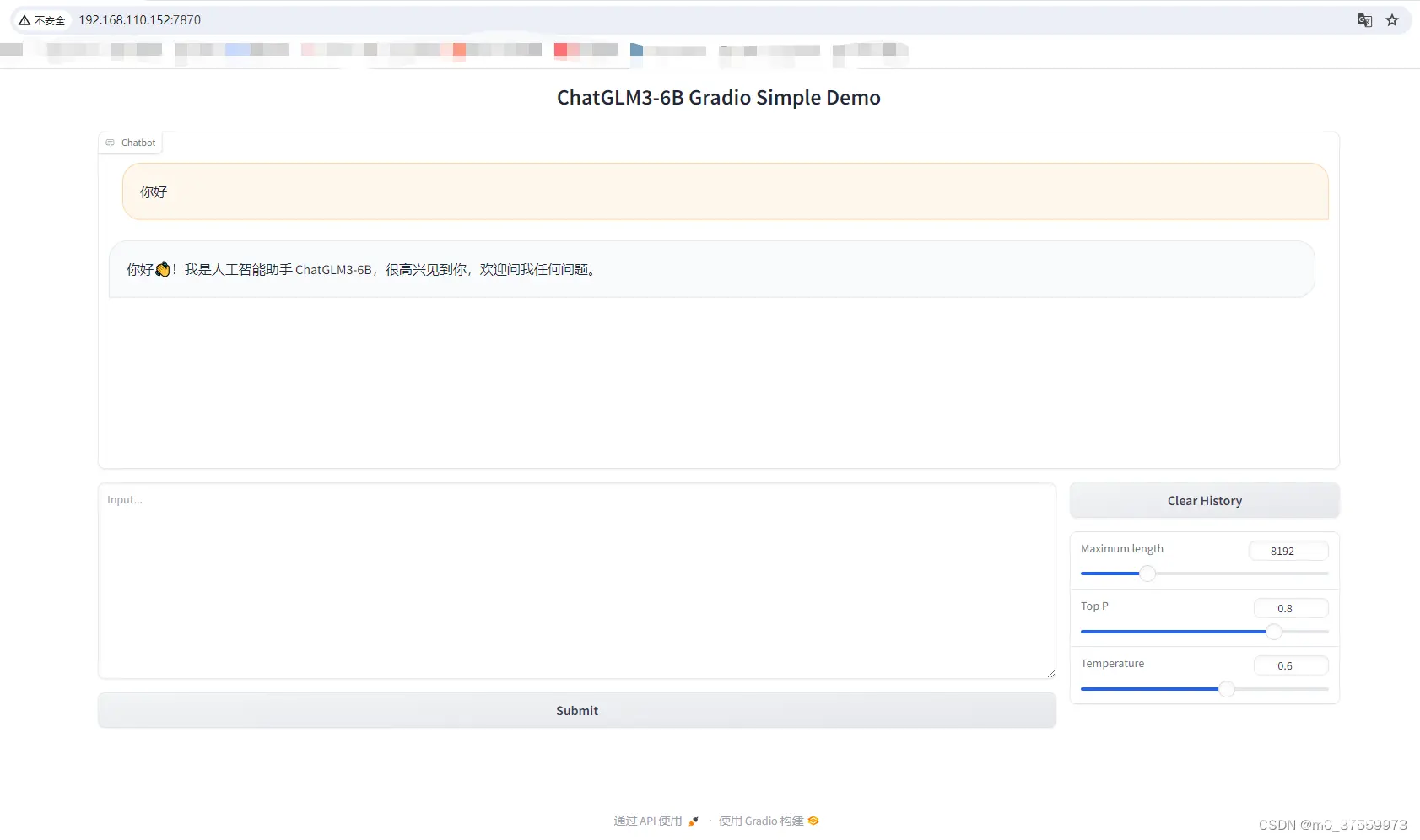
进入base_demo目录,启动Gradio :
python web_demo_gradio.py
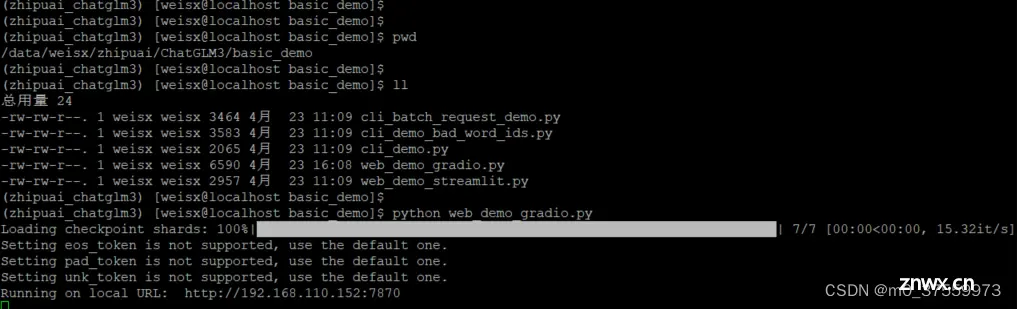
访问WEB:
http://192.168.110.152:7870/
4.3 Streamlit 网页版 Demo
Streamlit是一个基于Python的开源库,专为机器学习工程师和数据科学家设计,用于快速构建和共享机器学习和数据科学领域的Web应用程序。
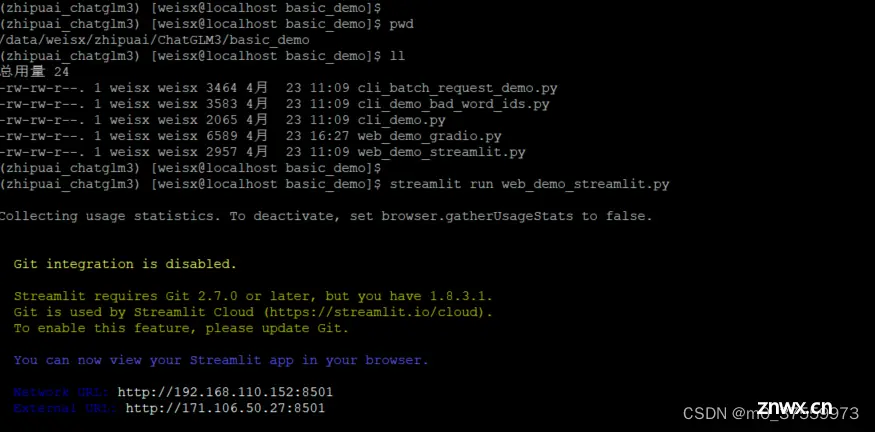
进入base_demo目录,启动 Streamlit:
streamlit run web_demo_streamlit.py
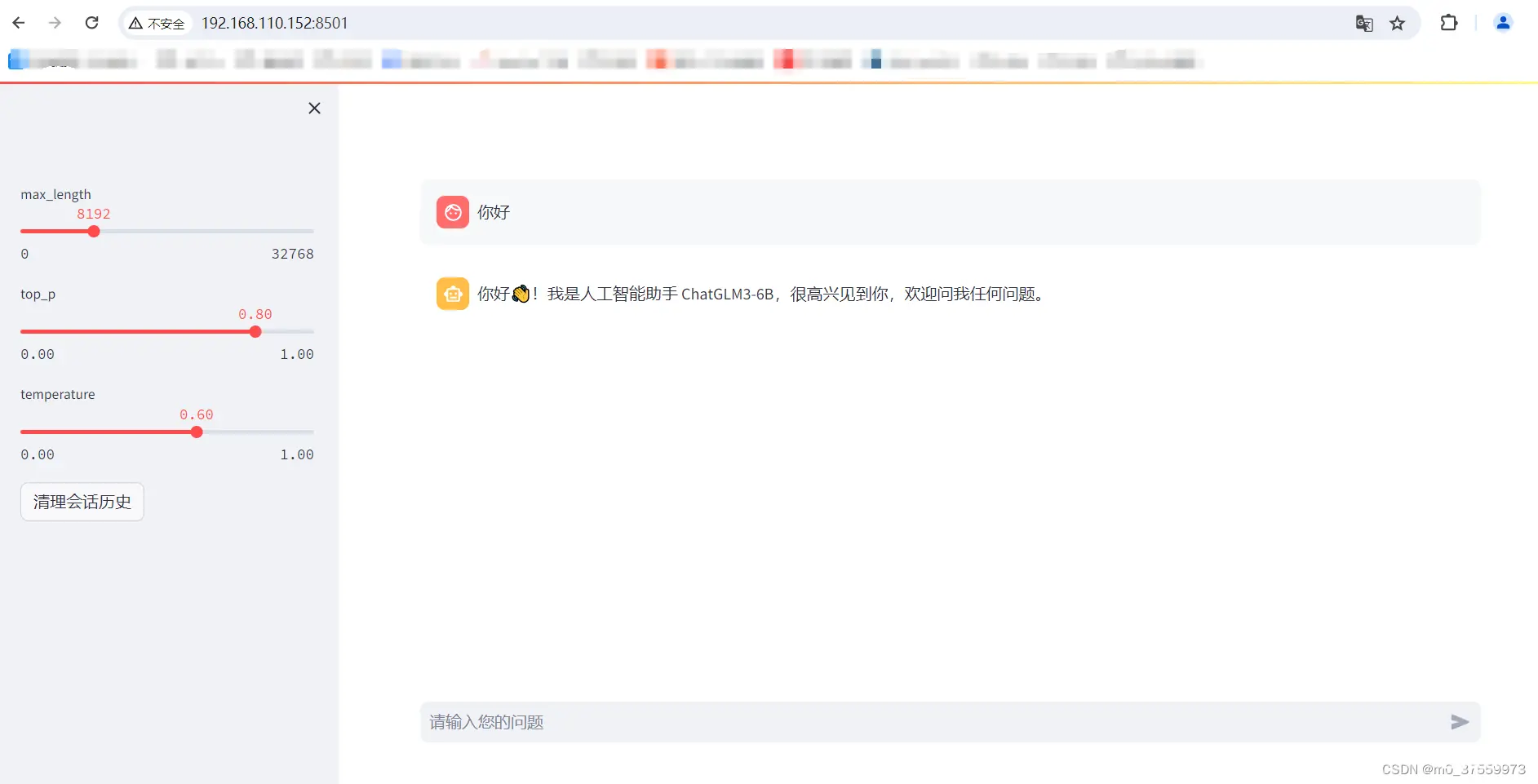
访问WEB:
http://192.168.110.152:8501/
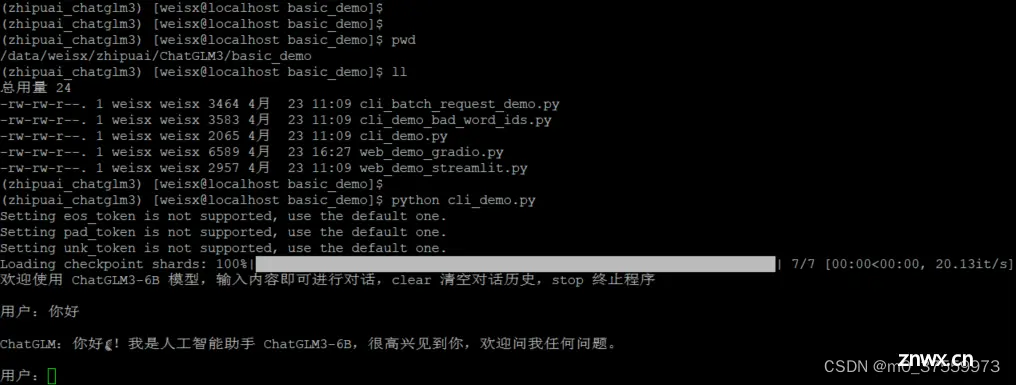
4.4 命令行交互Demo
进入base_demo目录,启动 命令行客户端:
python cli_demo.py
上一篇: 【人工智能】使用yolov7和youlov8以及re-detr模型实现安全帽检测
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。