GRU实现时间序列预测(PyTorch版)
CSDN 2024-06-15 12:01:16 阅读 85

💥项目专栏:【深度学习时间序列预测案例】零基础入门经典深度学习时间序列预测项目实战(附代码+数据集+原理介绍)
文章目录
前言一、基于PyTorch搭建GRU模型实现风速时间序列预测二、时序数据集的制作三、数据归一化四、数据集加载器五、搭建GRU模型六、定义模型、损失函数、优化器七、模型训练八、可视化结果完整源码
前言
👑 最近很多订阅了🔥《深度学习100例》🔥的用户私信咨询基于深度学习实现时间序列的相关问题,为了能更清晰的说明,所以建立了本专栏专门记录基于深度学习的时间序列预测方法,帮助广大零基础用户达到轻松入门。
👑 本专栏适用人群:🚨🚨🚨深度学习初学者,刚刚接触时间序列的用户群体,专栏将具体讲解如何快速搭建深度学习模型用自己的数据集实现时间序列预测,快速让新手小白能够对基于深度学习方法进行时间序列预测有个基本的框架认识。
👑 本专栏整理了《深度学习时间序列预测案例》,内包含了各种不同的基于深度学习模型的时间序列预测方法,例如LSTM、GRU、CNN(一维卷积、二维卷积)、LSTM-CNN、BiLSTM、Self-Attention、LSTM-Attention、Transformer等经典模型,💥💥💥包含项目原理以及源码,每一个项目实例都附带有完整的代码+数据集。
正在更新中~ ✨
🚨 我的项目环境:
平台:Windows10语言环境:python3.7编译器:PyCharmPyTorch版本:1.11.0
💥 项目专栏:【深度学习时间序列预测案例】零基础入门经典深度学习时间序列预测项目实战(附代码+数据集+原理介绍)
一、基于PyTorch搭建GRU模型实现风速时间序列预测
高精度、可靠的风速预报是气象学家面临的挑战。由对流风暴引起的强风,造成相当大的破坏(大规模森林破坏、停电、建筑物/房屋损坏等)。雷暴、龙卷风以及大冰雹、强风等对流事件是有可能扰乱日常生活的自然灾害,特别是在有利于对流启动的复杂地形上。即使是普通的对流事件也会产生强风,造成致命和昂贵的损失。因此,风速预测是一项重要的工作。
本篇文章我们采用了经典的循环神经网络 GRU 来对我们的时序数据建模处理,作为该专栏的第一篇文章,本篇将💎 详细介绍项目的每个实现部分以及细节处理,帮助新手小白快速建立起如何处理时序数据的框架。
二、时序数据集的制作
对于实现时间序列预测,我们使用的原始数据集往往不能够直接送入模型,需要进行预处理,这里说的预处理并不是处理空值、归一化这种处理方式,而是基于原始数据构建模型需要的时序数据集。
为了介绍什么是时序数据集,我们举个例子:
假设我们的原始数据如下:
第一列为时间刻度,代表每个样本的时间,第二列则为建模数据,由于数据集中只有一列特征,所以 WIND 既是输入的特征,又是模型的输出(预测值),由于是时序预测,那么我们就需要基于以前时间发生的数据来预测未来的数据。
DATEWIND1961-01-0113.671961-01-0211.501961-01-0311.251961-01-048.631961-01-0511.92
如果我们设置 timestep 为2的话(timestep就是时间窗口,用户滑动制作时序数据),那么我们将会产生如下的时序样本:
T1T2 target13.6711.5011.2511.5011.258.6311.258.6311.92
其中 T1 代表前2天的数据,T2代表前1天的数据,该数据维度为【3,2】,代表3个时序样本,2天数据(也就是timestep的值),这里发现时序数据集相对于原始数据集少了2个,这是因为前2个样本没有以前数据的参照,只有从第3个样本开始,他才有前两天的数据,所以我们的时序数据集的个数应该是 len(data)-timestep 个。
这个时序数据集的意思就是利用前2天的风速去预测未来1天的风速,所以我们需要基于原始数据来提取出这种的数据集,进而送入模型进行训练,我们可以根据我们的业务需求来调整 timestep 的大小,有些任务可能定为24,这个意思就是利用前24个样本去预测未来的样本,这种一般时间周期为24小时,这个数据集是针对单特征输入的,也就是整个数据中只有一个特征 WIND,这里说的一个特征是原始特征,也就是每天(每个样本)的特征维度。
如果每天的特征存在多个,这就是多变量输入,其实制作方法是一样的,只不过相对于单特征多了一个维度,举例:
DATEWINDTEMPERATURERAIN1961-01-0113.67121341961-01-0211.50182341961-01-0311.25131571961-01-048.63271921961-01-0511.925260
这个数据集中每天的特征维度为3,分别是 风速、温度、降雨,也就是用三个维度的向量来表示每个样本数据,假设我们的 timestep 还是2的话,我们的时序数据集如下:
T1T2 target[13.67,12,134][11.50,18,234]11.25[11.50,18,234][11.25,13,157]8.63[11.25,13,157][8.63,27,192]11.92
与上面一维的数据一样,只不过多变量的数据维度会多一维,原来T1、T2对应每个位置是一个标量(一个数字),现在是用一个向量表示(将每天的样本特征封装到一个列表里),此时的数据维度为【3,2,3】。
第一个维度的值代表时序数据集的样本数第二个维度代表窗口大小timestep第三个维度代表每天的特征数
如果熟悉NLP的朋友,应该很容易理解,第二个维度相当于 seq_len ,也就是序列长度(一句话词的个数),第三个维度相当于 feature_size ,也就是每个词的向量编码长度。
例如我爱你中国这句话就有5个词,所以 seq_len=5,如果我们用一个嵌入向量来表示每个词(假设为10)即 feature_size=10,这时我们就可以用一个【5,10】的矩阵来表示这句话,5个词,每个词向量的大小为10,如果我们有多句话,就可以在第一个位置添加一个维度,代表样本数。
此处的时序数据和NLP文本方式同理,对于新手小白可能不好理解,不过没有关系。
接下来就到了到底如何基于原始数据获得时序数据集呢,接下来基于本项目给出代码示例:
# 形成训练数据,例如12345789 12-3、23-4、34-5def split_data(data, timestep, input_size): dataX = [] # 保存X dataY = [] # 保存Y # 将整个窗口的数据保存到X中,将未来一天保存到Y中 for index in range(len(data) - timestep): dataX.append(data[index: index + timestep][:, 0]) dataY.append(data[index + timestep][0]) dataX = np.array(dataX) dataY = np.array(dataY) # 获取训练集大小 train_size = int(np.round(0.8 * dataX.shape[0])) # 划分训练集、测试集 x_train = dataX[: train_size, :].reshape(-1, timestep, input_size) y_train = dataY[: train_size].reshape(-1, 1) x_test = dataX[train_size:, :].reshape(-1, timestep, input_size) y_test = dataY[train_size:].reshape(-1, 1) return [x_train, y_train, x_test, y_test]
本项目使用的数据集是风速预测数据集,特征共有8列,但本专栏只是初探,所以只使用了 WIND 这一列特征,也就单输入,关于数据集的介绍可以查看本专栏的该篇文章 深度学习时间序列预测项目案例数据集介绍 。
有兴趣的小伙伴可以去Github上去下载第三方库采用掉包来处理数据,本代码是采用自己实现方式。
三、数据归一化
数据的 归一化和标准化 是特征缩放(feature scaling)的方法,是数据预处理的关键步骤。不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据归一化/标准化处理,以解决数据指标之间的可比性。原始数据经过数据归一化/标准化处理后,各指标处于同一数量级,适合进行综合对比评价。
常见的归一化方式有:Min-Max、Z-Score、L2范数归一化等等,对于本项目使用的是 MIn-Max 归一化,他会将所有的数据缩放到 0-1 区间,对于该操作可以手动实现,代码如下:
(df - df.min()) / (df.max() - df.min())
也可以使用 sklearn 中提供的 MinMaxScaler() 函数实现,代码如下:
scaler = MinMaxScaler()data = scaler_model.fit_transform(np.array(df))
有兴趣的小伙伴可以多多尝试不同的归一化方式,可以参照这篇文章进行尝试 归一化 (Normalization)、标准化 (Standardization)和中心化/零均值化 (Zero-centered) 。
四、数据集加载器
上面已经处理好了数据,获得了模型的输入数据,但是对于PyTorch的输入需要是Tensor类型数据,所以此时需要将上面获得的numpy.array类型数据转成Tensor类型数据。
x_train, y_train, x_test, y_test = split_data(data, config.timestep, config.input_size)# 将数据转为tensorx_train_tensor = torch.from_numpy(x_train).to(torch.float32)y_train_tensor = torch.from_numpy(y_train).to(torch.float32)x_test_tensor = torch.from_numpy(x_test).to(torch.float32)y_test_tensor = torch.from_numpy(y_test).to(torch.float32)
现在数据集已经全部转成了Tensor类型数据,此时已经可以直接喂入模型进行使用,但是我们常常使用数据加载器,数据集如果小直接使用Tensor也都OK,但是如果我们的数据集过大,如果不适用数据加载器直接加载到内存中会导致内存爆炸,所以要分批次一点点加载数据。
# 形成训练数据集train_data = TensorDataset(x_train_tensor, y_train_tensor)test_data = TensorDataset(x_test_tensor, y_test_tensor)# 将数据加载成迭代器train_loader = torch.utils.data.DataLoader(train_data, config.batch_size, False)test_loader = torch.utils.data.DataLoader(test_data, config.batch_size, False)
五、搭建GRU模型
接下来就到了该项目的重中之重,构建我们的深度学习模型,本项目使用的模型是经典的循环神经网络GRU,由于此专栏注重实战讲解,所以关于GRU模型的原理词处就不赘述了,有兴趣的小伙伴可以去百度进行了解,这里你只需要知道GRU是一个深度学习模型,能够处理时序数据,获取时间维度上的关联信息。
该图为PyTorch官方文档给出的GRU模型解释:

为了能够使用GRU搭建模型处理我们的时序数据,我们需要GRU模型的输入和输出是什么,对于初学者了解这个很重要,它能够快速帮助我们在自己的数据集上调试运行。
该图为GRU模型的参数:

input_size:每个时间点的特征维度,就是对应上面我们说的每天的特征维度是3还是1hidden_size:GRU内部隐层的维度大小num_layers:GRU的层数,默认为1bias:是否在隐层中添加偏置bias,默认为Truebatch_first:如果设置为True,GRU的输入第一个维度为批次大小,也就是【batch_size,seq_len,feature_size】,如果为False,则模型的输入Tensor的维度为【seq_len,batch_size,feature_size】,默认为Falsedropout:是否采用dropoutbidirectional:是否采用双向GRU模型,默认单向为False
该图为GRU模型的输入:

GRU的模型输入Tensor的维度为【batch_size,seq_len,feature_size】,其实也可以是【seq_len,batch_size,feature_size】,但是我们常常将批次大小作为第一个维度传入,容易理解,本项目采用的输入维度为第一种方式,批次为先。
此处有小伙伴会存在一个问题,模型的输入还有一个 h_0 作为输入,如果了解GRU原理的同学就可以知道这个输入变量是干嘛的,就是模型初始的隐层状态,对于这个变量可传可不传,如果不传则默认为0,有兴趣了解这个参数到底传入还是不传入可以参考这篇文章 对LSTM中每个batch都初始化隐含层的理解 ,本项目传入的隐层状态是传入的,但是传入的参数是以0进行填充,和默认不传入一致,只是为了让小伙伴了解这个参数是怎么传入的。
if hidden is None:h_0 = x.data.new(self.num_layers, batch_size, self.hidden_size).fill_(0).float()else: h_0 = hiddenoutput, h_0 = self.gru(x, h_0)
该图为GRU模型的输出:

GRU模型的输出有两个,一个输出的是模型的最终输出,也就是我们想要的输出,另外一个输出是模型的隐藏状态,对于本项目来说我们并不需要他。
对于这两个输出的维度一定要知道,首先是我们需要的输出 output,该输出的维度为【batch_size,seq_len,D * hidden_size】,此处的D就是我们是否采用双向GRU,如果设置 bidirectional=True,则D=2,否则D=1,hidden_size 就是GRU中间隐层的维度大小。
对于h_n的输出我们简答了解一下就好,因为我们不会对他进行处理。
为了能够理解GRU的输入和输出,举个例子说明:
model = nn.GRU(input_size=3, hidden_size=10, num_layers=2, batch_first=True)x = torch.randn(32, 5, 3)output, h_0 = model(x)
我们定义了输入向量,该向量的维度为【32,5,3】,分别代表【批次大小,时间片,特征大小】,用语言叙述就是32个样本,然后用5天的数据去未来1天的数据,每天的特征维度为3。
print(output.shape)>>>torch.Size([32, 5, 10])print(h_0.shape)>>>torch.Size([2, 32, 10])
我们可以看到 output 的输出维度为【batch_size,seq_len,D * hidden_size】,由于我们的GRU是单向的,所以D=1。
如果设置为双向:
model = nn.GRU(input_size=3, hidden_size=10, num_layers=2, batch_first=True, bidirectional=True)x = torch.randn(32, 5, 3)output, h_0 = model(x)print(output.shape)>>>torch.Size([32, 5, 20])
接下来就到了使用PyTorch搭建GRU模型,代码如下:
# 定义GRU网络class GRU(nn.Module): def __init__(self, feature_size, hidden_size, num_layers, output_size): super(GRU, self).__init__() self.hidden_size = hidden_size # 隐层大小 self.num_layers = num_layers # gru层数 # feature_size为特征维度,就是每个时间点对应的特征数量,这里为1 self.gru = nn.GRU(feature_size, hidden_size, num_layers, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x, hidden=None): batch_size = x.shape[0] # 获取批次大小 # 初始化隐层状态 if hidden is None: h_0 = x.data.new(self.num_layers, batch_size, self.hidden_size).fill_(0).float() else: h_0 = hidden # GRU运算 output, h_0 = self.gru(x, h_0) # 获取GRU输出的维度信息 batch_size, timestep, hidden_size = output.shape # 将output变成 batch_size * timestep, hidden_dim output = output.reshape(-1, hidden_size) # 全连接层 output = self.fc(output) # 形状为batch_size * timestep, 1 # 转换维度,用于输出 output = output.reshape(timestep, batch_size, -1) # 我们只需要返回最后一个时间片的数据即可 return output[-1]
本项目的模型采用的是GRU+全连接层,有小伙伴可能有一个问题就是搭建模型的过程中有句代码就是 output = output.reshape(timestep, batch_size, -1),它的目的就是将我们的输出数据的第一个维度变成时间片。
如果我们设置 timestep=5,那么我们的 output 的输出就为【5,32,1】,作为模型输出我们只需要最后一个时间片的数据作为输出即可,因为GRU是处理时序数据的,最后一个时间片包含了前面所有时间片的信息(T1,T2…)。
感兴趣的小伙伴可以尝试不返回最后一个时间片的数据作为输出,可以将每个时间片的数据池化再进行输出(例如将每个时间片的数据取平均、取最大等操作),也就是将5个【32,1】维度的张量取平均再进行输出,不过这样会提高运算时间,至于模型效果会不会提高,需要自己在自己的数据集上面尝试,希望小伙伴初学时可以多多尝试。
六、定义模型、损失函数、优化器
为了训练数据,首先定义GRU模型,然后再定义对应的损失函数,由于我们这里是风速预测,显然是个回归问题,所以采用回归问题常用的 MESLoss(),如果可以的话,可以自定义损失函数,针对自己的项目需求定义对应的损失函数。
对于优化器来讲,使用的也是目前常用的 Adam 优化器,对于新手来讲也可以多多尝试其它的优化器,比如 SGD、RMSprop等,对于优化器的选择,可以参考这篇文章 Pytorch 30种优化器总结 。
model = GRU(config.feature_size, config.hidden_size, config.num_layers, config.output_size) # 定义GRU网络loss_function = nn.MSELoss() # 定义损失函数optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate) # 定义优化器
在定义优化器的同时,我们需要将模型的参数传入,可以通过 model.parameters() 获得,如果模型中有些层不需要训练,我们可以将参数冻结,这时使用优化器训练模型时,该层参数就不会被修改,实现该目的可以使用以下函数:
# 冻结模型参数for param in model.parameters(): param.requires_grad = False
另外多说一点,有些复杂的模型需要定义多个优化器,也就是模型中不同的层或者参数需要使用不同的优化策略进行优化,例如本项目中我们的模型包含了GRU层和全连接层,我们可以定义 optimizer_gru = torch.optim.Adam() 和 optimizer_fc = torch.optim.RMSprop(),这时两个层可以使用不同的学习率或者权重衰减方式进行训练,但这是后话, 对于新手不需要搞这么复杂,用一个优化器训练模型即可,如果有能力可以自己尝试以下,使用多个优化器来训练自己的模型。
另外一点,如果我们需要进行权重衰减,可以在定义优化器的同时传入 weight_decay ,有兴趣的同学可以参考这篇文章进行了解 权重衰退 。
七、模型训练
下面代码是相对标准的模型训练框架,涵盖训练集和测试集的验证,该部分用户可以自己DIY设计,比如统计相关的指标信息(整体损失、epoch损失等)或者打印信息等,这些都可以按照自己的喜好进行调整。
对于模型验证部分,添不添加都OK,但是一般我们是会加上的,因为防止过拟合,让模型有更好的泛化性、鲁棒性,模型训练完成需要在测试集上进行验证,如果损失下降,则保留此轮训练的模型。
# 模型训练for epoch in range(config.epochs): model.train() running_loss = 0 train_bar = tqdm(train_loader) # 形成进度条 for data in train_bar: x_train, y_train = data # 解包迭代器中的X和Y optimizer.zero_grad() y_train_pred = model(x_train) loss = loss_function(y_train_pred, y_train.reshape(-1, 1)) loss.backward() optimizer.step() running_loss += loss.item() train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, config.epochs, loss) # 模型验证 model.eval() test_loss = 0 with torch.no_grad(): test_bar = tqdm(test_loader) for data in test_bar: x_test, y_test = data y_test_pred = model(x_test) test_loss = loss_function(y_test_pred, y_test.reshape(-1, 1)) if test_loss < config.best_loss: config.best_loss = test_loss torch.save(model.state_dict(), save_path)print('Finished Training')
上述代码理解相对简单,就不多赘述了,有同学会好奇 train_bar = tqdm(train_loader) 这句代码是做什么的,对于模型训练来将不是必须的,他只是用来形成进度条的,帮助用户了解当前模型的训练进度,效果如下:
train epoch[1/10] loss:0.017: 100%|██████████████████████████████████████████████████| 141/141 [00:01<00:00, 83.10it/s]100%|█████████████████████████████████████████████████████████████████████████████████| 36/36 [00:00<00:00, 360.01it/s]train epoch[2/10] loss:0.014: 100%|██████████████████████████████████████████████████| 141/141 [00:02<00:00, 62.06it/s]100%|█████████████████████████████████████████████████████████████████████████████████| 36/36 [00:00<00:00, 404.49it/s]train epoch[3/10] loss:0.014: 100%|██████████████████████████████████████████████████| 141/141 [00:01<00:00, 80.92it/s]100%|█████████████████████████████████████████████████████████████████████████████████| 36/36 [00:00<00:00, 276.92it/s]train epoch[4/10] loss:0.014: 100%|██████████████████████████████████████████████████| 141/141 [00:01<00:00, 84.16it/s]100%|█████████████████████████████████████████████████████████████████████████████████| 36/36 [00:00<00:00, 375.53it/s]train epoch[5/10] loss:0.014: 100%|██████████████████████████████████████████████████| 141/141 [00:01<00:00, 77.95it/s]100%|█████████████████████████████████████████████████████████████████████████████████| 36/36 [00:00<00:00, 399.98it/s]train epoch[6/10] loss:0.014: 100%|██████████████████████████████████████████████████| 141/141 [00:01<00:00, 81.74it/s]100%|█████████████████████████████████████████████████████████████████████████████████| 36/36 [00:00<00:00, 404.50it/s]train epoch[7/10] loss:0.014: 100%|██████████████████████████████████████████████████| 141/141 [00:01<00:00, 72.54it/s]100%|█████████████████████████████████████████████████████████████████████████████████| 36/36 [00:00<00:00, 370.81it/s]train epoch[8/10] loss:0.014: 100%|██████████████████████████████████████████████████| 141/141 [00:02<00:00, 68.67it/s]100%|█████████████████████████████████████████████████████████████████████████████████| 36/36 [00:00<00:00, 237.74it/s]train epoch[9/10] loss:0.014: 100%|██████████████████████████████████████████████████| 141/141 [00:02<00:00, 64.72it/s]100%|█████████████████████████████████████████████████████████████████████████████████| 36/36 [00:00<00:00, 303.73it/s]train epoch[10/10] loss:0.014: 100%|█████████████████████████████████████████████████| 141/141 [00:02<00:00, 66.28it/s]100%|█████████████████████████████████████████████████████████████████████████████████| 36/36 [00:00<00:00, 292.70it/s]Finished Training
对于模型损失的指标,用户可以手动保存,就是将每轮的损失值保存到列表中或者其它处理,也可以掉包来实现,在pytorch中有个 meter 库可以实现这个目的,有兴趣的同学可以参考这篇文章 pytorch中meter.ClassErrorMeter()使用方法 。
八、可视化结果
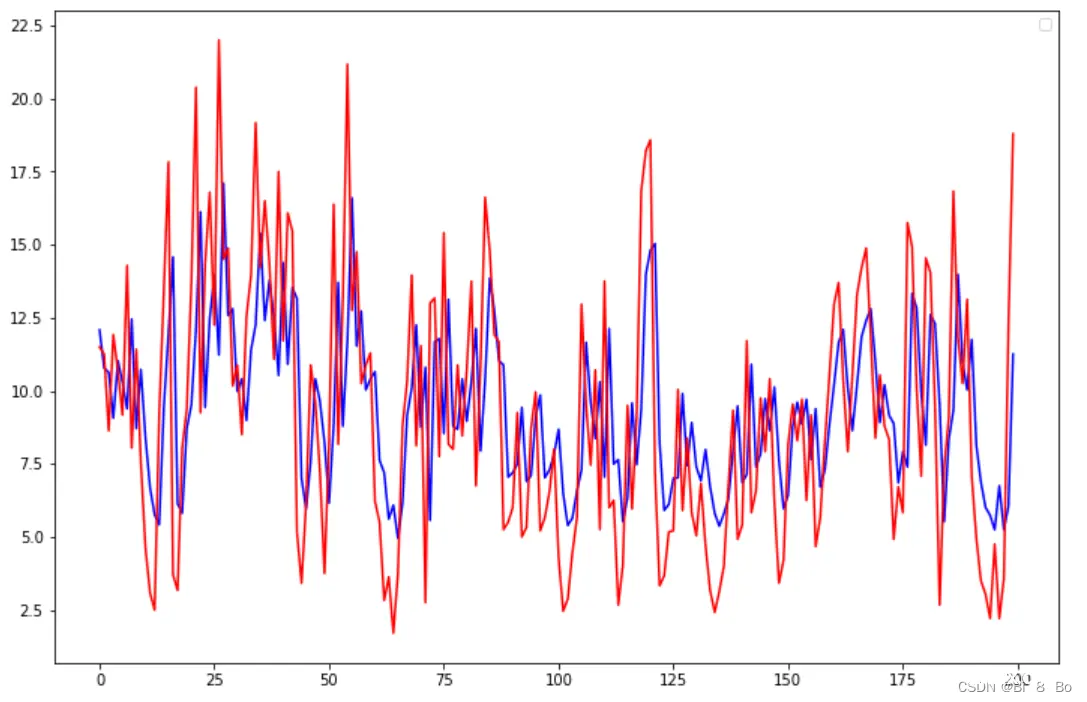
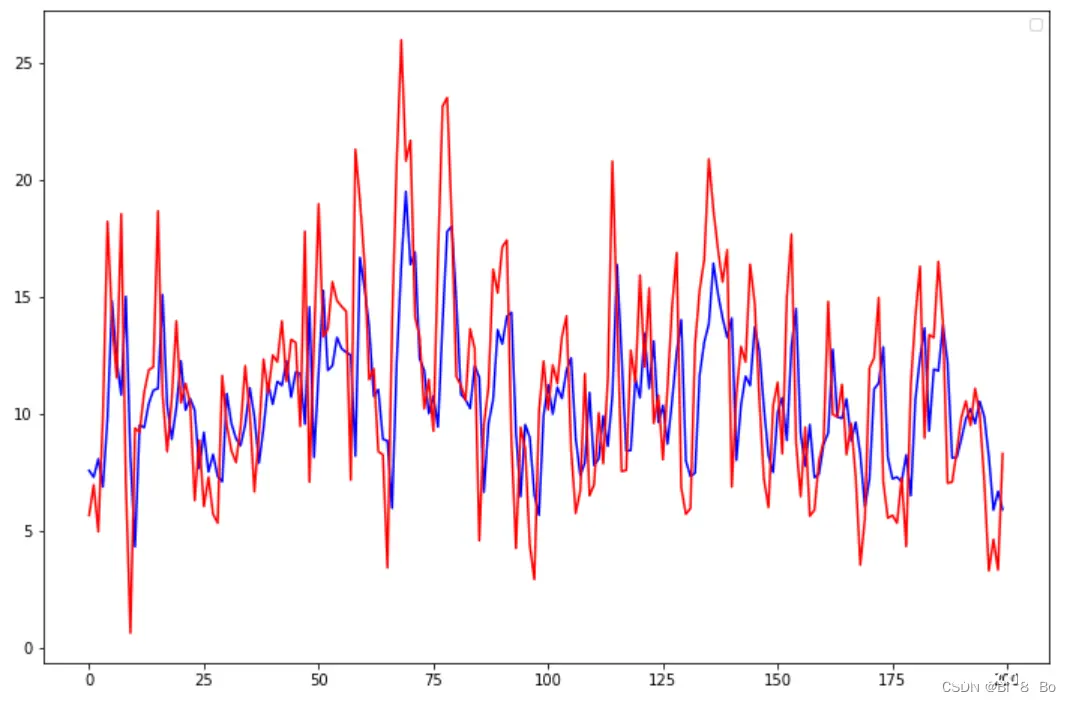
为了查看模型的训练效果,我们采用可视化的方式来对比真实值和预测值的差距,对于绘图,我们采用了经典的可视化库 matplotlib ,可视化代码如下:
# 绘制结果plot_size = 200 # 绘制前200个样本plt.figure(figsize=(12, 8))plt.plot(scaler.inverse_transform((model(x_train_tensor).detach().numpy()[: plot_size]).reshape(-1, 1)), "b")plt.plot(scaler.inverse_transform(y_train_tensor.detach().numpy().reshape(-1, 1)[: plot_size]), "r")plt.legend()plt.show()y_test_pred = model(x_test_tensor)plt.figure(figsize=(12, 8))plt.plot(scaler.inverse_transform(y_test_pred.detach().numpy()[: plot_size]), "b")plt.plot(scaler.inverse_transform(y_test_tensor.detach().numpy().reshape(-1, 1)[: plot_size]), "r")plt.legend()plt.show()
解释下上述代码,首先定义了 plot_size ,这个变量是用来绘制样本数的,因为我们的数据集中存在几千个样本,如果全部绘制,会导致曲线过于拥挤,为了更好的观察拟合效果,所以只绘制其中一小部分。
还有一处需要说明的是 scaler.inverse_transform() ,由于我们的数据集在训练之前进行了归一化,所以在绘制曲线时需要将预测结果进行反归一化,恢复到原来的量纲区间。
训练集效果:
测试集效果:
完整源码
注意🚨🚨🚨:由于是针对于新手小白入门的系列专栏,所以代码并没有采用开发大型项目的方式,而是python单文件实现,这样能够帮助新人一键复制调试运行,不需要理解复杂的项目构造,另外一点就是由于是帮助新人理解时间序列预测基本过程,所以源码仅包含了时间序列预测的基本框架结构,有些地方实现略有简陋,有能力的小伙伴可以根据自己的能力在此基础上进行修改,例如尝试更深层次的模型结构,尝试更多的参数,以及进行分文件编写(模型训练、模型测试、定义模型、绘制图像)达到项目开发流程。
import matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport torchimport torch.nn as nnimport tushare as tsfrom sklearn.preprocessing import StandardScaler, MinMaxScalerfrom torch.utils.data import TensorDatasetfrom tqdm import tqdmclass Config(): data_path = './data/wind_dataset.csv' timestep = 1 # 时间步长,就是利用多少时间窗口 batch_size = 32 # 批次大小 feature_size = 1 # 每个步长对应的特征数量,这里只使用1维,每天的风速 hidden_size = 256 # 隐层大小 output_size = 1 # 由于是单输出任务,最终输出层大小为1,预测未来1天风速 num_layers = 2 # gru的层数 epochs = 10 # 迭代轮数 best_loss = 0 # 记录损失 learning_rate = 0.0003 # 学习率 model_name = 'gru' # 模型名称 save_path = './{}.pth'.format(model_name) # 最优模型保存路径config = Config()# 1.加载时间序列数据df = pd.read_csv(config.data_path, index_col = 0)# 2.将数据进行标准化scaler = MinMaxScaler()scaler_model = MinMaxScaler()data = scaler_model.fit_transform(np.array(df))scaler.fit_transform(np.array(df['WIND']).reshape(-1, 1))# 形成训练数据,例如12345789 12-3456789def split_data(data, timestep, feature_size): dataX = [] # 保存X dataY = [] # 保存Y # 将整个窗口的数据保存到X中,将未来一天保存到Y中 for index in range(len(data) - timestep): dataX.append(data[index: index + timestep][:, 0]) dataY.append(data[index + timestep][0]) dataX = np.array(dataX) dataY = np.array(dataY) # 获取训练集大小 train_size = int(np.round(0.8 * dataX.shape[0])) # 划分训练集、测试集 x_train = dataX[: train_size, :].reshape(-1, timestep, feature_size) y_train = dataY[: train_size].reshape(-1, 1) x_test = dataX[train_size:, :].reshape(-1, timestep, feature_size) y_test = dataY[train_size:].reshape(-1, 1) return [x_train, y_train, x_test, y_test]# 3.获取训练数据 x_train: 170000,30,1 y_train:170000,7,1x_train, y_train, x_test, y_test = split_data(data, config.timestep, config.feature_size)# 4.将数据转为tensorx_train_tensor = torch.from_numpy(x_train).to(torch.float32)y_train_tensor = torch.from_numpy(y_train).to(torch.float32)x_test_tensor = torch.from_numpy(x_test).to(torch.float32)y_test_tensor = torch.from_numpy(y_test).to(torch.float32)# 5.形成训练数据集train_data = TensorDataset(x_train_tensor, y_train_tensor)test_data = TensorDataset(x_test_tensor, y_test_tensor)# 6.将数据加载成迭代器train_loader = torch.utils.data.DataLoader(train_data, config.batch_size, False)test_loader = torch.utils.data.DataLoader(test_data, config.batch_size, False)# 7.定义GRU网络class GRU(nn.Module): def __init__(self, feature_size, hidden_size, num_layers, output_size): super(GRU, self).__init__() self.hidden_size = hidden_size # 隐层大小 self.num_layers = num_layers # gru层数 # feature_size为特征维度,就是每个时间点对应的特征数量,这里为1 self.gru = nn.GRU(feature_size, hidden_size, num_layers, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x, hidden=None): batch_size = x.shape[0] # 获取批次大小 # 初始化隐层状态 if hidden is None: h_0 = x.data.new(self.num_layers, batch_size, self.hidden_size).fill_(0).float() else: h_0 = hidden # GRU运算 output, h_0 = self.gru(x, h_0) # 获取GRU输出的维度信息 batch_size, timestep, hidden_size = output.shape # 将output变成 batch_size * timestep, hidden_dim output = output.reshape(-1, hidden_size) # 全连接层 output = self.fc(output) # 形状为batch_size * timestep, 1 # 转换维度,用于输出 output = output.reshape(timestep, batch_size, -1) # 我们只需要返回最后一个时间片的数据即可 return output[-1]model = GRU(config.feature_size, config.hidden_size, config.num_layers, config.output_size) # 定义GRU网络loss_function = nn.MSELoss() # 定义损失函数optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate) # 定义优化器# 8.模型训练for epoch in range(config.epochs): model.train() running_loss = 0 train_bar = tqdm(train_loader) # 形成进度条 for data in train_bar: x_train, y_train = data # 解包迭代器中的X和Y optimizer.zero_grad() y_train_pred = model(x_train) loss = loss_function(y_train_pred, y_train.reshape(-1, 1)) loss.backward() optimizer.step() running_loss += loss.item() train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, config.epochs, loss) # 模型验证 model.eval() test_loss = 0 with torch.no_grad(): test_bar = tqdm(test_loader) for data in test_bar: x_test, y_test = data y_test_pred = model(x_test) test_loss = loss_function(y_test_pred, y_test.reshape(-1, 1)) if test_loss < config.best_loss: config.best_loss = test_loss torch.save(model.state_dict(), save_path)print('Finished Training')# 9.绘制结果plot_size = 200plt.figure(figsize=(12, 8))plt.plot(scaler.inverse_transform((model(x_train_tensor).detach().numpy()[: plot_size]).reshape(-1, 1)), "b")plt.plot(scaler.inverse_transform(y_train_tensor.detach().numpy().reshape(-1, 1)[: plot_size]), "r")plt.legend()plt.show()y_test_pred = model(x_test_tensor)plt.figure(figsize=(12, 8))plt.plot(scaler.inverse_transform(y_test_pred.detach().numpy()[: plot_size]), "b")plt.plot(scaler.inverse_transform(y_test_tensor.detach().numpy().reshape(-1, 1)[: plot_size]), "r")plt.legend()plt.show()
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。