Datawhale-AI 夏令营 自然语言处理实战营 总结(Task01-Task02)
追逐着明 2024-08-05 11:01:03 阅读 58
一、进入实战营之前的基础
之前也参加过比较多的AI的那种运用工具生成AI的活动,但目前就一直停留在概念的层面。一大堆的数学推导与模型没有一个直观地感受。
二、Task01总结
任务:跑通baseline
借助的工具:魔搭社区
(魔搭平台可以有CPU和GPU的两种方式设置,跑模型一般用GPU,这个平台比较便捷)
总体的过程:进入魔搭社区之后,选择要创建的Notebook类型(CPU or GPU平台),之后把数据和样例代码创建在一个文件夹内,将样例数据和编写的推理代码运行一通就是了。
三、Task02总结
对赛题的理解:
1.赛题链接:2024 iFLYTEK A.I.开发者大赛-讯飞开放平台
2.赛题个人解读:
(1).赛题的任务:基于给定的中英文术语结合,实现对文章的翻译任务。
(2).赛题的评分标准:采用自动评价指标BLUE-4进行评价(连续4个单词对应的4个句子语义正确才算该点正确)
(3).赛题的相关背景知识:
自然语言处理基础:
A.Seq2Seq序列:全称 Sequence to Sequence ,指的是从一个序列到另外一个序列的方法。
内部细节:
编码器:将输入的模式转化成数字特征进行计算,以nlp为例,将输入的一句话通过某一种编码方式让其转化成数字。
解码器:通过数字转化为某种模式,顾名思义,转化成某种语言。
既然编码器和解码器均需要有某种特定的编码与解码的方法,那么有以下模型是在自然语言处理领域编码或解码所常用的:(sigmoid符号代指激活函数加成)
a.GRU(门控单元)
结构图如图

b.LSTM(长短记忆循环神经网络)等。
结构
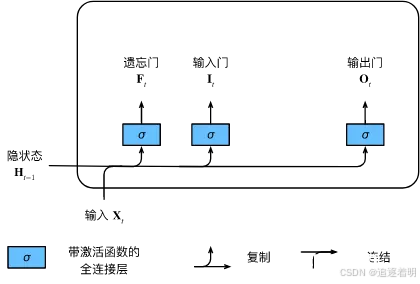
特点:采用了数学中的映射的思想,较为清楚直观。
缺点:通过代码实操发现,在翻译领域的BLEU评价指标基本得分很低,直接原因是翻译出来的语句较生硬,基本都是通过映射方式,语句块之间没有任何的逻辑联系。
B.(修改方案)加上注意力机制
定义:
(Baseline代码在夏令营文档中)
下面详细说明Baseline代码的思路与详细过程:
①导入相关的库,根据赛题的需求,我们结合nlp的相关特性,引入torch在自然语言处理方面的文字处理神经网络torchtext,jieba分词库。此外,由于该比赛有专业词库的数据提示,可以是我们的翻译在某种程度上会更好地结果,因此,我们考虑了spacy库的安装
②读取相关的训练数据,由于数据中不乏有脏数据,因此需要做一步数据的处理,使模型的训练效率更加的高
③构建词汇表,根据英文和中文数据的词汇内容,增加索引的内容,对于一些陌生的词汇,我们给予其“未知”的标签。(如果自己可以添加更多的训练样本那么可能模型会更加的好)
④构建模型:
Baseline中采用注意力机制与编码器译码器(Seq2Seq)结合的方式,设置注意力参数以及网络的结构。
⑤训练模型:
在训练过程中我们加入梯度下降(运用torch的自动求导寻找极值点)和反向传播(设置反向传播函数为)的过程,使得模型能够找到优化的结果,并且提高模型的精度。同时,对于模型给予评价(按照平均损失),检验迭代的次数。
⑥构建翻译函数
由于模型仅仅只是确定翻译的某个数学关系,而翻译的执行函数主要是通过张量来实现,因此,通过把构建的张量输入到模型可以得到反馈的结果。
⑦执行与调用
运行代码中产生的问题:
①在运行Baseline时,我们发现得分比原来的Task01原始的得分还要低。想到的解决方案如下:
调整增加训练的次数(结果显示"CUDA out of memory")
将分割改为一行一行地分割(准确率有所提升)
②在运行Baseline改编版时用时有所加长,这都是因为在对文章检索时会逐句搜索,分割的内容会更加细一些。
③个人认为优化的参数过多可能会导致过拟合从而使验证集上的评价效果会更差。
四、两部分的任务总结
由于本次是初步进行实验,因此,对于这一块代码的独立编写还不算是很熟,仅仅知道最起码的基本流程。
上一篇: AI 问答-供应链管理-相关概念:SCM、SRM、MDM、DMS、ERP、OBS、CRM、WMS...
下一篇: 【一次成功】清华大学和智谱AI公司的ChatGLM-4-9B-Chat-1M大模型本地化部署教程
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。