辅助分类器生成对抗网络( Auxiliary Classifier Generative Adversarial Network,ACGAN)(附带pytorch代码)
cnblogs 2024-07-24 09:43:00 阅读 60

ACGAN相对于CGAN使的判别器不仅可以判别真假,也可以判别类别 。通过对生成数据类别的判断,判别器可以更好地传递loss函数使得生成器能够更加准确地找到label对应的噪声分布。
1 ACGAN基本原理
1.2 ACGAN模型解释
ACGAN相对于CGAN使的判别器不仅可以判别真假,也可以判别类别 。通过对生成数据类别的判断,判别器可以更好地传递loss函数使得生成器能够更加准确地找到label对应的噪声分布,通过下图告诉了我们ACGAN与CGAN的异同之处 :
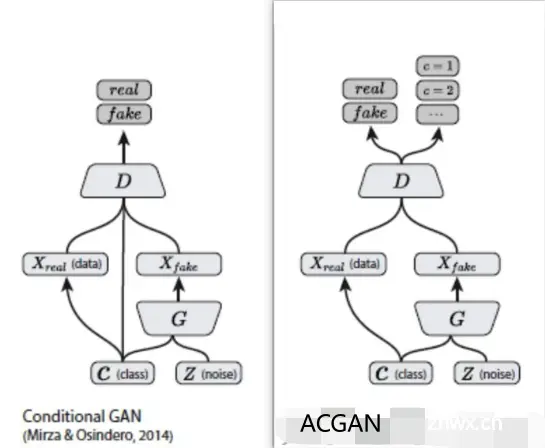
对于CGAN和ACGAN,生成器输入均为潜在矢量及其标签,输出是属于输入类标签的伪造数据。对于CGAN,判别器的输入是数据(包含假的或真实的数据)及其标签, 输出是图像属于真实数据的概率。对于ACGAN,判别器的输入是数据,而输出是该图像属于真实数据的概率以及其类别概率。
在ACGAN中,对于生成器来说有两个输入,一个是标签的分类数据c,另一个是随机数据z,得到生成数据为
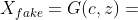
;对于判别器,产生跨域标签和源数据的概率分布

1.2 ACGAN损失函数
对于判别器而言,即希望分类正确,有希望能正确分辨数据的真假;对于生成器而言,也希望分类正确,但希望判别器不能正确分辨真假。因此在训练判别器的时候,我们希望LSE+LCS最大化;在训练生成器的时候,我们希望LCS-LSE最大化。
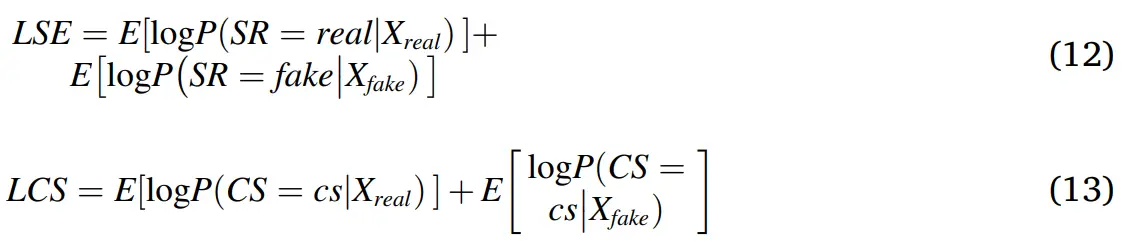
- <code>logP(SR = real | Xreal)表示鉴别器将真实样本源正确分类为真实样本的对数似然;
logP(SR = fake | Xfake)表示鉴别器正确地将假样本的来源分类为假样本的对数似然E[.]表示所有样本的平均值logP(CS = CS | Xreal)表示鉴别器正确分类真实样本的对数似然logP(CS = CS | Xfake)表示鉴别器正确分类具有正确类别标签的假样本的对数似然
判别器的损失函数 = LSE + LCS;生成器的损失函数 = LCS - LSE
- LSE测量鉴别器正确区分样本是真还是假的程度。这有助于鉴别器熟练地识别来源(真实的或生成的)。
- LCS确保生成的样本不仅看起来真实,而且携带正确的类信息。它引导生成器在不同的类中产生多样化和现实的样本。
2 ACGAN pytorch代码实现
完整代码链接:https://github.com/znxlwm/pytorch-generative-model-collections/tree/master
(但是这个代码我训练的时候损失函数也对应的上,得到的图片是黑乎乎的一片,也不知道是什么原因,如果知道的师傅可以麻烦告知一下吗?(感谢))
这个代码在训练ACGAN模型的时候加载数据集的时候会出现问题,因为我使用的是minist数据集,所以应该改为单通道的:

<code>import utils, torch, time, os, pickle
import numpy as np
import torch.nn as nn
import torch.optim as optim
from dataloader import dataloader
class generator(nn.Module):
# Network Architecture is exactly same as in infoGAN (https://arxiv.org/abs/1606.03657)
# Architecture : FC1024_BR-FC7x7x128_BR-(64)4dc2s_BR-(1)4dc2s_S
def __init__(self, input_dim=100, output_dim=1, input_size=32, class_num=10):
super(generator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.input_size = input_size
self.class_num = class_num
self.fc = nn.Sequential(
nn.Linear(self.input_dim + self.class_num, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 128 * (self.input_size // 4) * (self.input_size // 4)),
nn.BatchNorm1d(128 * (self.input_size // 4) * (self.input_size // 4)),
nn.ReLU(),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1),
nn.Tanh(),
)
utils.initialize_weights(self)
def forward(self, input, label):
x = torch.cat([input, label], 1)
x = self.fc(x)
x = x.view(-1, 128, (self.input_size // 4), (self.input_size // 4))
x = self.deconv(x)
return x
class discriminator(nn.Module):
# Network Architecture is exactly same as in infoGAN (https://arxiv.org/abs/1606.03657)
# Architecture : (64)4c2s-(128)4c2s_BL-FC1024_BL-FC1_S
def __init__(self, input_dim=1, output_dim=1, input_size=32, class_num=10):
super(discriminator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.input_size = input_size
self.class_num = class_num
self.conv = nn.Sequential(
nn.Conv2d(self.input_dim, 64, 4, 2, 1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
)
self.fc1 = nn.Sequential(
nn.Linear(128 * (self.input_size // 4) * (self.input_size // 4), 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
)
self.dc = nn.Sequential(
nn.Linear(1024, self.output_dim),
nn.Sigmoid(),
)
self.cl = nn.Sequential(
nn.Linear(1024, self.class_num),
)
utils.initialize_weights(self)
def forward(self, input):
x = self.conv(input)
x = x.view(-1, 128 * (self.input_size // 4) * (self.input_size // 4))
x = self.fc1(x)
d = self.dc(x)
c = self.cl(x)
return d, c
class ACGAN(object):
def __init__(self, args):
# parameters
self.epoch = args.epoch
self.sample_num = 100
self.batch_size = args.batch_size
self.save_dir = args.save_dir
self.result_dir = args.result_dir
self.dataset = args.dataset
self.log_dir = args.log_dir
self.gpu_mode = args.gpu_mode
self.model_name = args.gan_type
self.input_size = args.input_size # 输入图像的尺寸
self.z_dim = 62 # 潜在向量维度
self.class_num = 10
self.sample_num = self.class_num ** 2 # 总样本的数量
# load dataset
self.data_loader = dataloader(self.dataset, self.input_size, self.batch_size) # 加载数据集
data = self.data_loader.__iter__().__next__()[0] # 获得第一个批次的数据,data 的形状通常是 (batch_size, channels, height, width)
# networks init
self.G = generator(input_dim=self.z_dim, output_dim=data.shape[1], input_size=self.input_size)
self.D = discriminator(input_dim=data.shape[1], output_dim=1, input_size=self.input_size)
self.G_optimizer = optim.Adam(self.G.parameters(), lr=args.lrG, betas=(args.beta1, args.beta2))
self.D_optimizer = optim.Adam(self.D.parameters(), lr=args.lrD, betas=(args.beta1, args.beta2))
# 查看是否启用了gpu模式
if self.gpu_mode:
self.G.cuda()
self.D.cuda()
self.BCE_loss = nn.BCELoss().cuda() # 将交叉熵损失加载到GPU
self.CE_loss = nn.CrossEntropyLoss().cuda() # 将二元交叉熵损失加载到GPU
else:
self.BCE_loss = nn.BCELoss()
self.CE_loss = nn.CrossEntropyLoss()
print('---------- Networks architecture -------------')
utils.print_network(self.G)
utils.print_network(self.D)
print('-----------------------------------------------')
# fixed noise & condition
# 为每个类别生成潜在向量(latent vector)z,并确保同一类别的所有样本共享相同的潜在向量
self.sample_z_ = torch.zeros((self.sample_num, self.z_dim))
for i in range(self.class_num):
self.sample_z_[i*self.class_num] = torch.rand(1, self.z_dim) # 为每一个类别随机生成潜在变量
for j in range(1, self.class_num):
self.sample_z_[i*self.class_num + j] = self.sample_z_[i*self.class_num] # 同一类别的样本共享相同的潜在变量
# 为每个样本创造标签向量
temp = torch.zeros((self.class_num, 1)) # 10*1
for i in range(self.class_num):
temp[i, 0] = i
temp_y = torch.zeros((self.sample_num, 1))
for i in range(self.class_num):
temp_y[i*self.class_num: (i+1)*self.class_num] = temp # 给每个样本赋予相同的标签
# 编码one-hot
self.sample_y_ = torch.zeros((self.sample_num, self.class_num)).scatter_(1, temp_y.type(torch.LongTensor), 1)
if self.gpu_mode:
self.sample_z_, self.sample_y_ = self.sample_z_.cuda(), self.sample_y_.cuda()
# 用于训练模型
def train(self):
self.train_hist = {}
self.train_hist['D_loss'] = []
self.train_hist['G_loss'] = []
self.train_hist['per_epoch_time'] = []
self.train_hist['total_time'] = []
self.y_real_, self.y_fake_ = torch.ones(self.batch_size, 1), torch.zeros(self.batch_size, 1)
if self.gpu_mode:
self.y_real_, self.y_fake_ = self.y_real_.cuda(), self.y_fake_.cuda()
self.D.train()
print('training start!!')
start_time = time.time()
for epoch in range(self.epoch):
self.G.train()
epoch_start_time = time.time()
for iter, (x_, y_) in enumerate(self.data_loader):
if iter == self.data_loader.dataset.__len__() // self.batch_size:
break
z_ = torch.rand((self.batch_size, self.z_dim))
y_vec_ = torch.zeros((self.batch_size, self.class_num)).scatter_(1, y_.type(torch.LongTensor).unsqueeze(1), 1)
if self.gpu_mode:
x_, z_, y_vec_ = x_.cuda(), z_.cuda(), y_vec_.cuda()
# update D network
self.D_optimizer.zero_grad() # 梯度清0
D_real, C_real = self.D(x_) # 获取判别器的预测结果
D_real_loss = self.BCE_loss(D_real, self.y_real_)
C_real_loss = self.CE_loss(C_real, torch.max(y_vec_, 1)[1])
G_ = self.G(z_, y_vec_) # 生成伪造数据
D_fake, C_fake = self.D(G_)
D_fake_loss = self.BCE_loss(D_fake, self.y_fake_)
C_fake_loss = self.CE_loss(C_fake, torch.max(y_vec_, 1)[1])
D_loss = D_real_loss + C_real_loss + D_fake_loss + C_fake_loss
self.train_hist['D_loss'].append(D_loss.item())
D_loss.backward()
self.D_optimizer.step() # 更新判别器权重
# update G network
self.G_optimizer.zero_grad()
G_ = self.G(z_, y_vec_)
D_fake, C_fake = self.D(G_)
G_loss = self.BCE_loss(D_fake, self.y_real_)
C_fake_loss = self.CE_loss(C_fake, torch.max(y_vec_, 1)[1])
G_loss += C_fake_loss
self.train_hist['G_loss'].append(G_loss.item())
G_loss.backward()
self.G_optimizer.step()
# 打印训练信息
if ((iter + 1) % 100) == 0:
print("Epoch: [%2d] [%4d/%4d] D_loss: %.8f, G_loss: %.8f" %
((epoch + 1), (iter + 1), self.data_loader.dataset.__len__() // self.batch_size, D_loss.item(), G_loss.item()))
# 每一轮训练结束-------------
self.train_hist['per_epoch_time'].append(time.time() - epoch_start_time)
with torch.no_grad(): # 结束进行梯度运算
self.visualize_results((epoch+1))
# 每一epoch训练结束-------------
self.train_hist['total_time'].append(time.time() - start_time)
print("Avg one epoch time: %.2f, total %d epochs time: %.2f" % (np.mean(self.train_hist['per_epoch_time']),
self.epoch, self.train_hist['total_time'][0]))
print("Training finish!... save training results")
self.save() # 保存训练历史
utils.generate_animation(self.result_dir + '/' + self.dataset + '/' + self.model_name + '/' + self.model_name,
self.epoch)
utils.loss_plot(self.train_hist, os.path.join(self.save_dir, self.dataset, self.model_name), self.model_name)
# 用于可视化生成的图像
def visualize_results(self, epoch, fix=True):
self.G.eval()
if not os.path.exists(self.result_dir + '/' + self.dataset + '/' + self.model_name):
os.makedirs(self.result_dir + '/' + self.dataset + '/' + self.model_name)
image_frame_dim = int(np.floor(np.sqrt(self.sample_num)))
if fix:
""" fixed noise """
samples = self.G(self.sample_z_, self.sample_y_)
else:
""" random noise """
sample_y_ = torch.zeros(self.batch_size, self.class_num).scatter_(1, torch.randint(0, self.class_num - 1, (self.batch_size, 1)).type(torch.LongTensor), 1)
sample_z_ = torch.rand((self.batch_size, self.z_dim))
if self.gpu_mode:
sample_z_, sample_y_ = sample_z_.cuda(), sample_y_.cuda()
samples = self.G(sample_z_, sample_y_)
if self.gpu_mode:
samples = samples.cpu().data.numpy().transpose(0, 2, 3, 1)
else:
samples = samples.data.numpy().transpose(0, 2, 3, 1)
samples = (samples + 1) / 2
utils.save_images(samples[:image_frame_dim * image_frame_dim, :, :, :], [image_frame_dim, image_frame_dim],
self.result_dir + '/' + self.dataset + '/' + self.model_name + '/' + self.model_name + '_epoch%03d' % epoch + '.png')
# 用于保存模型和训练历史
def save(self):
save_dir = os.path.join(self.save_dir, self.dataset, self.model_name)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
torch.save(self.G.state_dict(), os.path.join(save_dir, self.model_name + '_G.pkl'))
torch.save(self.D.state_dict(), os.path.join(save_dir, self.model_name + '_D.pkl'))
with open(os.path.join(save_dir, self.model_name + '_history.pkl'), 'wb') as f:
pickle.dump(self.train_hist, f)
# 用于加载模型和训练历史
def load(self):
save_dir = os.path.join(self.save_dir, self.dataset, self.model_name)
self.G.load_state_dict(torch.load(os.path.join(save_dir, self.model_name + '_G.pkl')))
self.D.load_state_dict(torch.load(os.path.join(save_dir, self.model_name + '_D.pkl')))
由于上一个代码训练有问题,因此我训练的是以下代码:
完整代码链接:https://github.com/ChenKaiXuSan/ACGAN-PyTorch
模型结构:
# %%
'''
acgan structure.
the network model architecture from the paper [ACGAN](https://arxiv.org/abs/1610.09585)
'''
import torch
import torch.nn as nn
import numpy as np
from torch.nn.modules.activation import Sigmoid
# %%
class Generator(nn.Module):
'''
pure Generator structure
'''
def __init__(self, image_size=64, z_dim=100, conv_dim=64, channels = 1, n_classes=10):
super(Generator, self).__init__()
self.imsize = image_size
self.channels = channels
self.z_dim = z_dim
self.n_classes = n_classes
self.label_embedding = nn.Embedding(self.n_classes, self.z_dim)
self.linear = nn.Linear(self.z_dim, 768)
self.deconv1 = nn.Sequential(
nn.ConvTranspose2d(768, 384, 4, 1, 0, bias=False),
nn.BatchNorm2d(384),
nn.ReLU(True)
)
self.deconv2 = nn.Sequential(
nn.ConvTranspose2d(384, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True)
)
self.deconv3 = nn.Sequential(
nn.ConvTranspose2d(256, 192, 4, 2, 1, bias=False),
nn.BatchNorm2d(192),
nn.ReLU(True),
)
self.deconv4 = nn.Sequential(
nn.ConvTranspose2d(192, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True)
)
self.last = nn.Sequential(
nn.ConvTranspose2d(64, self.channels, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, z, labels):
label_emb = self.label_embedding(labels)
gen_input = torch.mul(label_emb, z)
out = self.linear(gen_input)
out = out.view(-1, 768, 1, 1)
out = self.deconv1(out)
out = self.deconv2(out)
out = self.deconv3(out)
out = self.deconv4(out)
out = self.last(out) # (*, c, 64, 64)
return out
# %%
class Discriminator(nn.Module):
'''
pure discriminator structure
'''
def __init__(self, image_size = 64, conv_dim = 64, channels = 1, n_classes = 10):
super(Discriminator, self).__init__()
self.imsize = image_size
self.channels = channels
self.n_classes = n_classes
# (*, c, 64, 64)
self.conv1 = nn.Sequential(
nn.Conv2d(self.channels, 16, 3, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.5, inplace=False)
)
# (*, 64, 32, 32)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 3, 1, 1, bias=False),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.5, inplace=False)
)
# (*, 128, 16, 16)
self.conv3 = nn.Sequential(
nn.Conv2d(32, 64, 3, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.5, inplace=False)
)
# (*, 256, 8, 8)
self.conv4 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.5, inplace=False)
)
self.conv5 = nn.Sequential(
nn.Conv2d(128, 256, 3, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.5, inplace=False)
)
self.conv6 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.5, inplace=False)
)
# output layers
# (*, 512, 8, 8)
# dis fc
self.last_adv = nn.Sequential(
nn.Linear(8*8*512, 1),
# nn.Sigmoid()
)
# aux classifier fc
self.last_aux = nn.Sequential(
nn.Linear(8*8*512, self.n_classes),
nn.Softmax(dim=1)
)
def forward(self, input):
out = self.conv1(input)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.conv6(out)
flat = out.view(input.size(0), -1)
fc_dis = self.last_adv(flat)
fc_aux = self.last_aux(flat)
return fc_dis.squeeze(), fc_aux
数据加载:
# %%
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import torch
import torchvision.transforms as transform
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
# %%
def getdDataset(opt):
if opt.dataset == 'mnist':
dst = datasets.MNIST(
# 相对路径,以调用的文件位置为准——因为我不是每次都想下载数据,因为很多数据是重复的
root='D:\\ProfessionStudy\\AI\\data',code>
train=True,
download=True,
transform=transform.Compose(
[transform.Resize(opt.img_size), transform.ToTensor(), transform.Normalize([0.5], [0.5])]
)
)
elif opt.dataset == 'fashion':
dst = datasets.FashionMNIST(
root='D:\\ProfessionStudy\\AI\\data',code>
train=True,
download=True,
# split='mnist',code>
transform=transform.Compose(
[transform.Resize(opt.img_size), transform.ToTensor(), transform.Normalize([0.5], [0.5])]
)
)
elif opt.dataset == 'cifar10':
dst = datasets.CIFAR10(
root='D:\\ProfessionStudy\\AI\\data',code>
train=True,
download=True,
transform=transform.Compose(
[transform.Resize(opt.img_size), transform.ToTensor(), transform.Normalize([0.5], [0.5])]
)
)
dataloader = DataLoader(
dst,
batch_size=opt.batch_size,
shuffle=True,
)
return dataloader
# %%
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
import numpy as np
if __name__ == "__main__":
class opt:
dataroot = '../../data'
dataset = 'mnist'
img_size = 32
batch_size = 10
dataloader = getdDataset(opt)
for i, (imgs, labels) in enumerate(dataloader):
print(i, imgs.shape, labels.shape)
print(labels)
img = imgs[0]
img = img.numpy()
img = make_grid(imgs, normalize=True).numpy()
img = np.transpose(img, (1, 2, 0))
plt.imshow(img)
plt.show()
plt.close()
break
# %%
训练过程:
# %%
"""
wgan with different loss function, used the pure dcgan structure.
"""
import os
import time
import torch
import datetime
import torch.nn as nn
import torchvision
from torchvision.utils import save_image
from models.acgan import Generator, Discriminator
from utils.utils import *
# %%
class Trainer_acgan(object):
def __init__(self, data_loader, config):
super(Trainer_acgan, self).__init__()
# data loader
self.data_loader = data_loader
# exact model and loss
self.model = config.model
# model hyper-parameters
self.imsize = config.img_size
self.g_num = config.g_num
self.z_dim = config.z_dim
self.channels = config.channels
self.n_classes = config.n_classes
self.g_conv_dim = config.g_conv_dim
self.d_conv_dim = config.d_conv_dim
self.epochs = config.epochs
self.batch_size = config.batch_size
self.num_workers = config.num_workers
self.g_lr = config.g_lr
self.d_lr = config.d_lr
self.beta1 = config.beta1
self.beta2 = config.beta2
self.pretrained_model = config.pretrained_model
self.dataset = config.dataset
self.use_tensorboard = config.use_tensorboard
# path
self.image_path = config.dataroot
self.log_path = config.log_path
self.sample_path = config.sample_path
self.log_step = config.log_step
self.sample_step = config.sample_step
self.version = config.version
# path with version
self.log_path = os.path.join(config.log_path, self.version)
self.sample_path = os.path.join(config.sample_path, self.version)
if self.use_tensorboard:
self.build_tensorboard()
self.build_model()
def train(self):
'''
Training
'''
# fixed input for debugging 用于每个epoch训练完成生成器后,用来测试其性能的
fixed_z = tensor2var(torch.randn(self.batch_size, self.z_dim)) # (*, 100)
fixed_labels = tensor2var(torch.randint(0, self.n_classes, (self.batch_size,), dtype=torch.long))
# fixed_labels = to_LongTensor(np.array([num for _ in range(self.n_classes) for num in range(self.n_classes)]))
for epoch in range(self.epochs):
# start time
start_time = time.time()
for i, (real_images, labels) in enumerate(self.data_loader):
# configure input
real_images = tensor2var(real_images)
labels = tensor2var(labels)
# adversarial ground truths;valid 和 fake 是用于计算判别器损失的对抗性标签。
valid = tensor2var(torch.full((real_images.size(0),), 0.9)) # (*, )
fake = tensor2var(torch.full((real_images.size(0),), 0.0)) #(*, )
# ==================== Train D 训练判别器 ==================
self.D.train()
self.G.train()
self.D.zero_grad()
# 计算真实数据损失
dis_out_real, aux_out_real = self.D(real_images)
d_loss_real = self.adversarial_loss_sigmoid(dis_out_real, valid) + self.aux_loss(aux_out_real, labels)
# noise z for generator
# 随机初始化假数据和标签
z = tensor2var(torch.randn(real_images.size(0), self.z_dim)) # *, 100
gen_labels = tensor2var(torch.randint(0, self.n_classes, (real_images.size(0),), dtype=torch.long))
# 生成假数据和标签
fake_images = self.G(z, gen_labels) # (*, c, 64, 64)
dis_out_fake, aux_out_fake = self.D(fake_images) # (*,)
# 计算假数据的损失
d_loss_fake = self.adversarial_loss_sigmoid(dis_out_fake, fake) + self.aux_loss(aux_out_fake, gen_labels)
# total d loss
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
# update D
self.d_optimizer.step()
# calculate dis accuracy
d_acc = compute_acc(aux_out_real, aux_out_fake, labels, gen_labels)
# train the generator every 5 steps 每五步训练一次生成器
if i % self.g_num == 0:
# =================== Train G and gumbel =====================
self.G.zero_grad()
# create random noise
fake_images = self.G(z, gen_labels)
# compute loss with fake images
dis_out_fake, aux_out_fake = self.D(fake_images) # batch x n
g_loss_fake = self.adversarial_loss_sigmoid(dis_out_fake, valid) + self.aux_loss(aux_out_fake, gen_labels)
g_loss_fake.backward()
# update G
self.g_optimizer.step()
# 每个epoch训练完成-------------------------------------------------------------------------------------------
# log to the tensorboard
self.logger.add_scalar('d_loss', d_loss.data, epoch)
self.logger.add_scalar('g_loss_fake', g_loss_fake.data, epoch)
# end one epoch
# print out log info
if (epoch) % self.log_step == 0:
elapsed = time.time() - start_time
elapsed = str(datetime.timedelta(seconds=elapsed))
print("Elapsed [{}], G_step [{}/{}], D_step[{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, Acc: {:.4f}"
.format(elapsed, epoch, self.epochs, epoch,
self.epochs, d_loss.item(), g_loss_fake.item(), d_acc))
# sample images
if (epoch) % self.sample_step == 0:
self.G.eval()
# save real image
save_sample(self.sample_path + '/real_images/', real_images, epoch)
with torch.no_grad():
fake_images = self.G(fixed_z, fixed_labels)
# save fake image
save_sample(self.sample_path + '/fake_images/', fake_images, epoch)
# sample sample one images
save_sample_one_image(self.sample_path, real_images, fake_images, epoch)
# 所有epoch训练完成-----------------------------------------------------------------------------------------------
# 建立训练模型
def build_model(self):
self.G = Generator(image_size = self.imsize, z_dim = self.z_dim, conv_dim = self.g_conv_dim, channels = self.channels).cuda()
self.D = Discriminator(image_size = self.imsize, conv_dim = self.d_conv_dim, channels = self.channels).cuda()
# apply the weights_init to randomly initialize all weights
# to mean=0, stdev=0.2
self.G.apply(weights_init)
self.D.apply(weights_init)
# optimizer
self.g_optimizer = torch.optim.Adam(self.G.parameters(), self.g_lr, [self.beta1, self.beta2])
self.d_optimizer = torch.optim.Adam(self.D.parameters(), self.d_lr, [self.beta1, self.beta2])
# for orignal gan loss function
self.adversarial_loss_sigmoid = nn.BCEWithLogitsLoss().cuda()
self.aux_loss = nn.CrossEntropyLoss().cuda()
# print networks
print(self.G)
print(self.D)
# 日志记录
def build_tensorboard(self):
from torch.utils.tensorboard import SummaryWriter
self.logger = SummaryWriter(self.log_path)
def save_image_tensorboard(self, images, text, step):
if step % 100 == 0:
img_grid = torchvision.utils.make_grid(images, nrow=8)
self.logger.add_image(text + str(step), img_grid, step)
self.logger.close()
额外知识
什么是对数似然函数?
概率:在给定参数值的情况下,概率用于描述未来出现某种情况的观测数据的可信度。
似然:在给定观测数据的情况下,似然用于描述参数值的可信度。
极大似然估计:在给定观测数据的情况下,某个参数值有多个取值可能,但是如果存在某个参数值,使其对应的似然值最大,那就说明这个值就是该参数最可信的参数值。
对数似然函数
极大似然估计的求解方法,往往是对参数θ求导,然后找到导函数为0时对应的参数值,根据函数的单调性,找到极大似然估计时对应的参数θ。
但是在实际问题中,对于大批量的样本(大量的观测结果),其概率值是由很多项相乘组成的式子,对于参数θ的求导,是一个很复杂的问题,于是我们一个直观的想法,就是把它转成对数函数,累乘就变成了累加,即似然函数也就变成了对数似然函数。
对数似然函数的的主要作用,就是用来定义某个机器学习模型的损失函数,线性回归或者逻辑回归中都可以用到,然后我们再根据梯度下降/上升法求解损失函数的最优解,取得最优解时对应的参数θ,就是我们机器学习模型想要学习的参数 。
参考:
ACGAN(Auxiliary Classifier GAN)详解与实现(tensorflow2.x实现)-CSDN博客
一天一GAN-day4-ACGAN - 知乎 (zhihu.com)
GAN生成对抗网络-ACGAN原理与基本实现-条件生成对抗网络05 - gemoumou - 博客园 (cnblogs.com)
[生成对抗网络GAN入门指南](9)ACGAN: Conditional Image Synthesis with Auxiliary Classifier GANs-CSDN博客
【For非数学专业】通俗理解似然函数、概率、极大似然估计和对数似然_对数似然估计-CSDN博客
https://github.com/znxlwm/pytorch-generative-model-collections/tree/master
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。